 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation theoretic model validation for clustering
Paper and Code
Jun 02, 2010
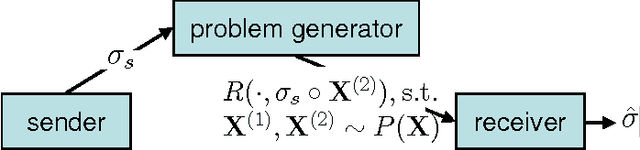
Model selection in clustering requires (i) to specify a suitable clustering principle and (ii) to control the model order complexity by choosing an appropriate number of clusters depending on the noise level in the data. We advocate an information theoretic perspective where the uncertainty in the measurements quantizes the set of data partitionings and, thereby, induces uncertainty in the solution space of clusterings. A clustering model, which can tolerate a higher level of fluctuations in the measurements than alternative models, is considered to be superior provided that the clustering solution is equally informative. This tradeoff between \emph{informativeness} and \emph{robustness} is used as a model selection criterion. The requirement that data partitionings should generalize from one data set to an equally probable second data set gives rise to a new notion of structure induced information.