 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyllable Analysis to Build a Dictation System in Telugu language
Paper and Code
Jan 13, 2010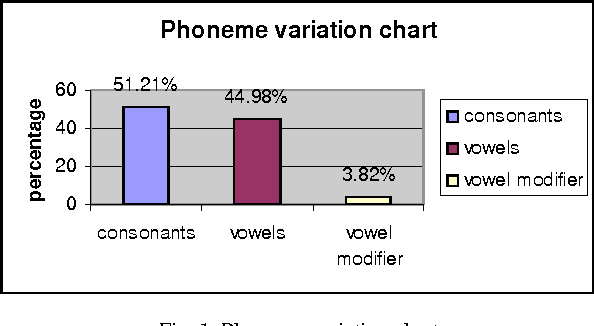
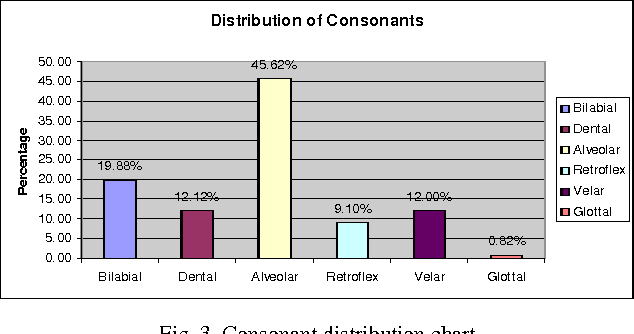
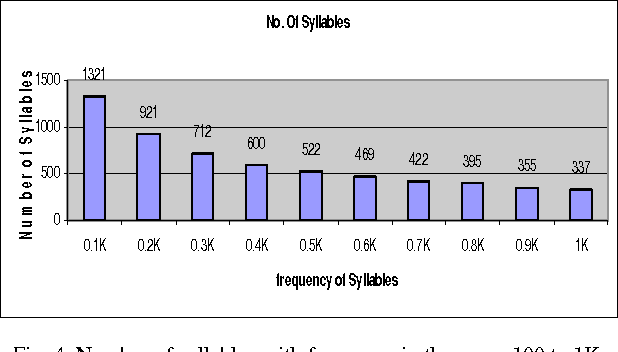
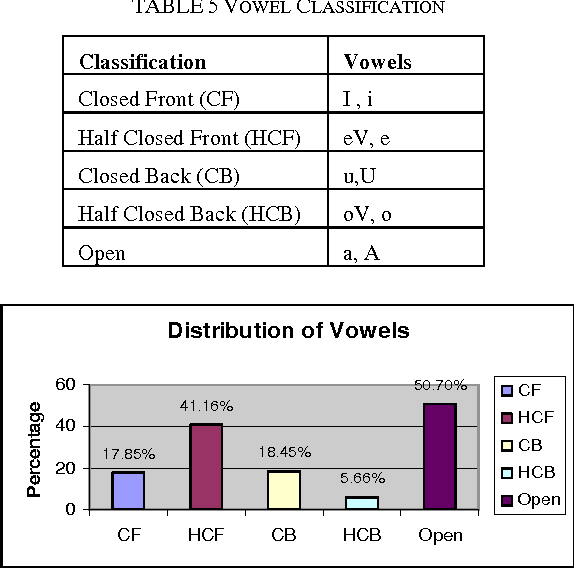
In recent decades, Speech interactive systems gained increasing importance. To develop Dictation System like Dragon for Indian languages it is most important to adapt the system to a speaker with minimum training. In this paper we focus on the importance of creating speech database at syllable units and identifying minimum text to be considered while training any speech recognition system. There are systems developed for continuous speech recognition in English and in few Indian languages like Hindi and Tamil. This paper gives the statistical details of syllables in Telugu and its use in minimizing the search space during recognition of speech. The minimum words that cover maximum syllables are identified. This words list can be used for preparing a small text which can be used for collecting speech sample while training the dictation system. The results are plotted for frequency of syllables and the number of syllables in each word. This approach is applied on the CIIL Mysore text corpus which is of 3 million words.