 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Approaches to Measuring the Similarity of Short Contexts : A Review of Applications and Methods
Paper and Code
Oct 18, 2010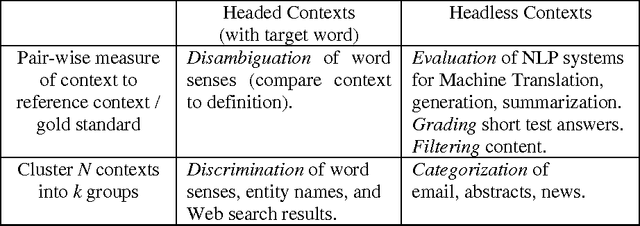
Measuring the similarity of short written contexts is a fundamental problem in Natural Language Processing. This article provides a unifying framework by which short context problems can be categorized both by their intended application and proposed solution. The goal is to show that various problems and methodologies that appear quite different on the surface are in fact very closely related. The axes by which these categorizations are made include the format of the contexts (headed versus headless), the way in which the contexts are to be measured (first-order versus second-order similarity), and the information used to represent the features in the contexts (micro versus macro views). The unifying thread that binds together many short context applications and methods is the fact that similarity decisions must be made between contexts that share few (if any) words in common.