Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariable importance in binary regression trees and forests
Paper and Code
Nov 15, 2007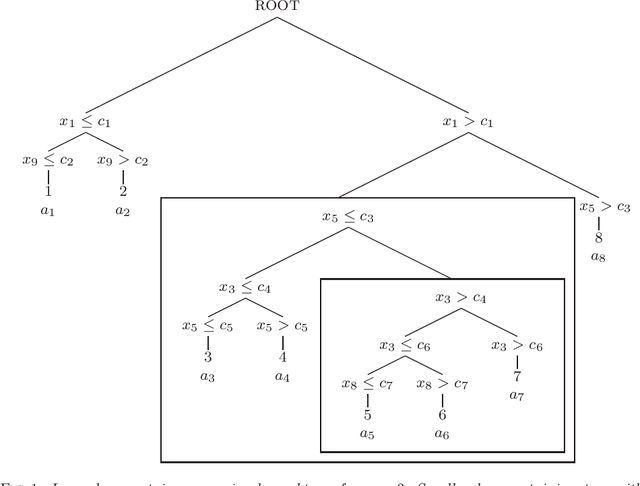
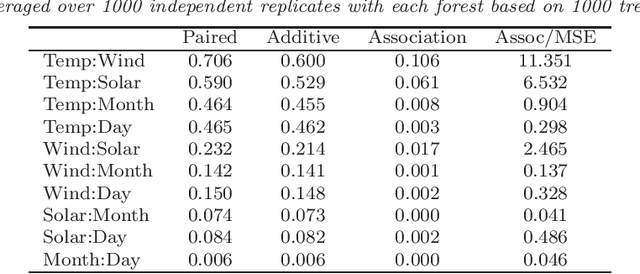
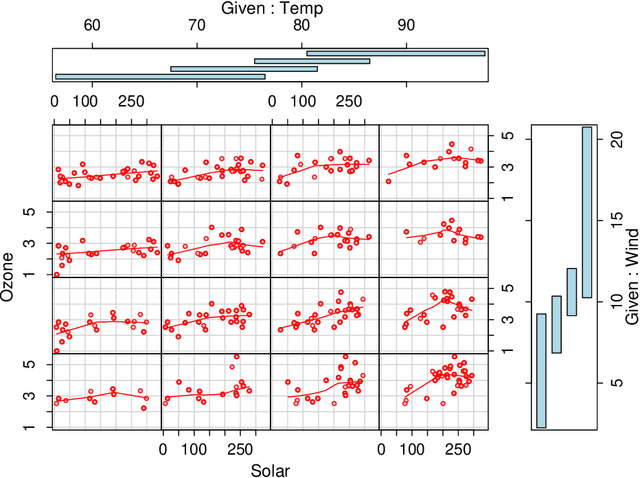
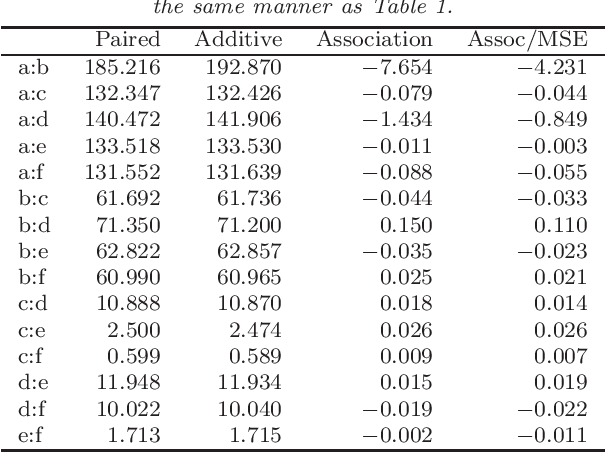
We characterize and study variable importance (VIMP) and pairwise variable associations in binary regression trees. A key component involves the node mean squared error for a quantity we refer to as a maximal subtree. The theory naturally extends from single trees to ensembles of trees and applies to methods like random forests. This is useful because while importance values from random forests are used to screen variables, for example they are used to filter high throughput genomic data in Bioinformatics, very little theory exists about their properties.
* Electronic Journal of Statistics 2007, Vol. 1, 519-537 * Published in at http://dx.doi.org/10.1214/07-EJS039 the Electronic
Journal of Statistics (http://www.i-journals.org/ejs/) by the Institute of
Mathematical Statistics (http://www.imstat.org)
View paper on