 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Analysis of Feature Engineering for Predictive Modeling
Paper and Code
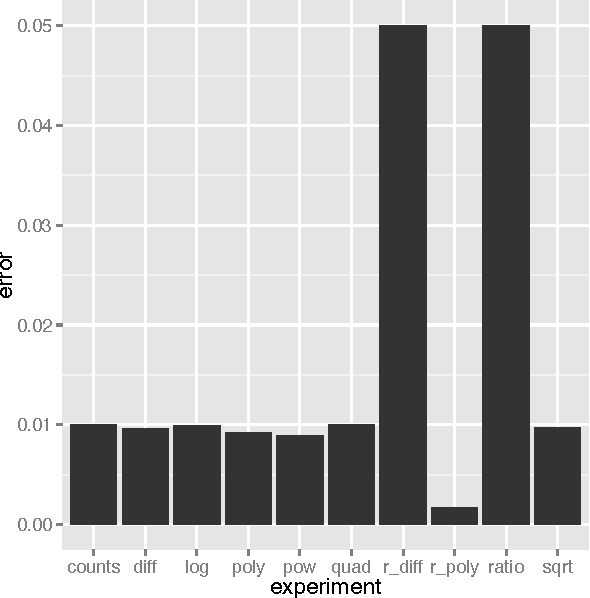
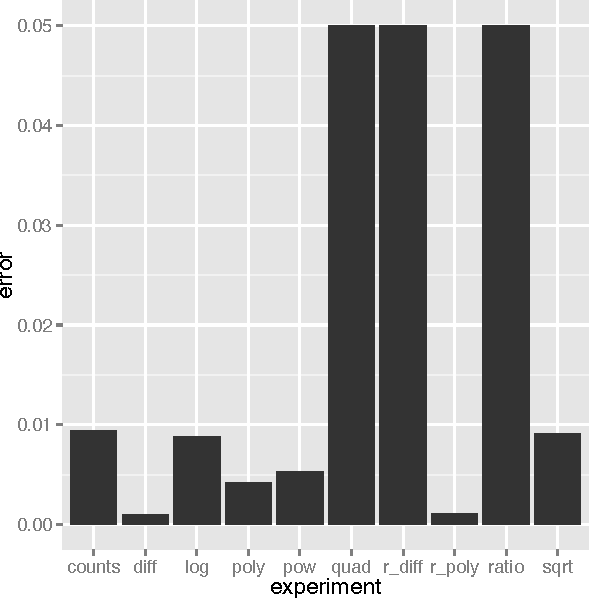
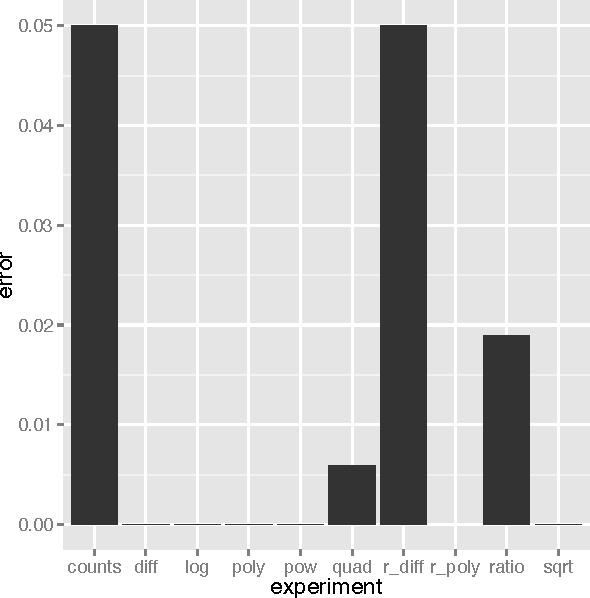
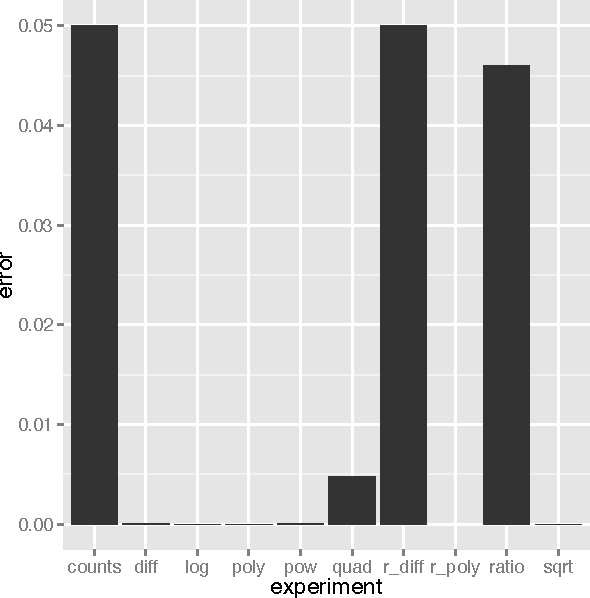
Machine learning models, such as neural networks, decision trees, random forests and gradient boosting machines accept a feature vector and provide a prediction. These models learn in a supervised fashion where a set of feature vectors with expected output is provided. It is very common practice to engineer new features from the provided feature set. Such engineered features will either augment, or replace portions of the existing feature vector. These engineered features are essentially calculated fields, based on the values of the other features. Engineering such features is primarily a manual, time-consuming task. Additionally, each type of model will respond differently to different types of engineered features. This paper reports on empirical research to demonstrate what types of engineered features are best suited to which machine learning model type. This is accomplished by generating several datasets that are designed to benefit from a particular type of engineered feature. The experiment demonstrates to what degree the machine learning model is capable of synthesizing the needed feature on its own. If a model is capable of synthesizing an engineered feature, it is not necessary to provide that feature. The research demonstrated that the studied models do indeed perform differently with various types of engineered features.