 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment and Safety of Diffusion Models via Reinforcement Learning and Reward Modeling: A Survey
Paper and Code
May 23, 2025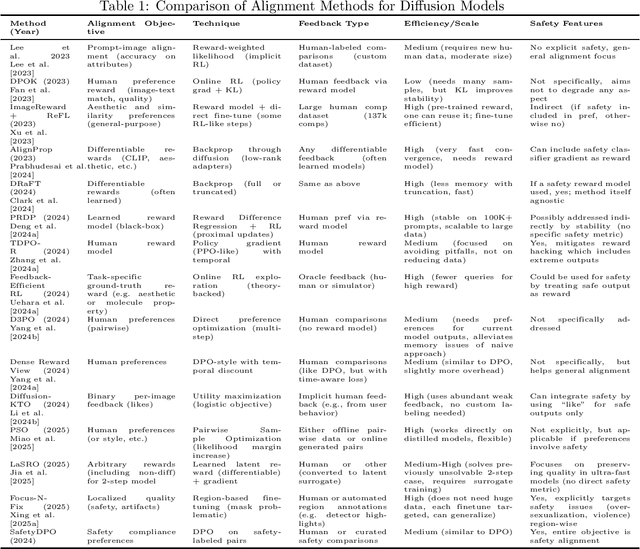
Diffusion models have emerged as leading generative models for images and other modalities, but aligning their outputs with human preferences and safety constraints remains a critical challenge. This thesis proposal investigates methods to align diffusion models using reinforcement learning (RL) and reward modeling. We survey recent advances in fine-tuning text-to-image diffusion models with human feedback, including reinforcement learning from human and AI feedback, direct preference optimization, and differentiable reward approaches. We classify these methods based on the type of feedback (human, automated, binary or ranked preferences), the fine-tuning technique (policy gradient, reward-weighted likelihood, direct backpropagation, etc.), and their efficiency and safety outcomes. We compare key algorithms and frameworks, highlighting how they improve alignment with user intent or safety standards, and discuss inter-relationships such as how newer methods build on or diverge from earlier ones. Based on the survey, we identify five promising research directions for the next two years: (1) multi-objective alignment with combined rewards, (2) efficient human feedback usage and active learning, (3) robust safety alignment against adversarial inputs, (4) continual and online alignment of diffusion models, and (5) interpretable and trustworthy reward modeling for generative images. Each direction is elaborated with its problem statement, challenges, related work, and a proposed research plan. The proposal is organized as a comprehensive document with literature review, comparative tables of methods, and detailed research plans, aiming to contribute new insights and techniques for safer and value-aligned diffusion-based generative AI.