 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing the Cold-Start Problem for Personalized Combination Drug Screening
Paper and Code
Sep 09, 2025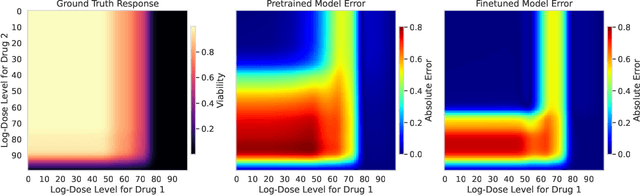
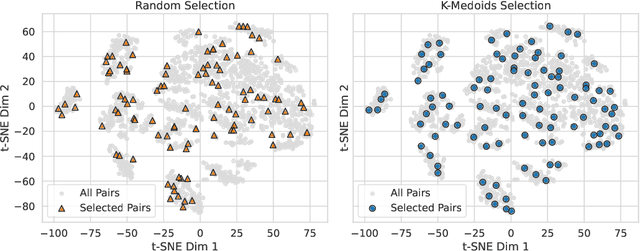
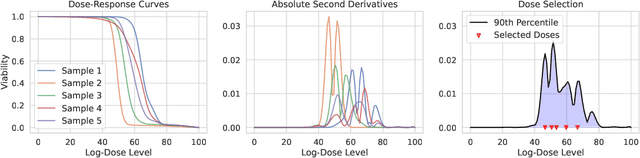
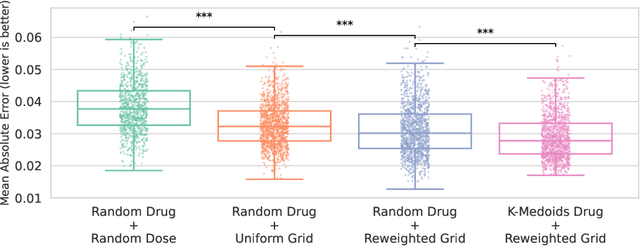
Personalizing combination therapies in oncology requires navigating an immense space of possible drug and dose combinations, a task that remains largely infeasible through exhaustive experimentation. Recent developments in patient-derived models have enabled high-throughput ex vivo screening, but the number of feasible experiments is limited. Further, a tight therapeutic window makes gathering molecular profiling information (e.g. RNA-seq) impractical as a means of guiding drug response prediction. This leads to a challenging cold-start problem: how do we select the most informative combinations to test early, when no prior information about the patient is available? We propose a strategy that leverages a pretrained deep learning model built on historical drug response data. The model provides both embeddings for drug combinations and dose-level importance scores, enabling a principled selection of initial experiments. We combine clustering of drug embeddings to ensure functional diversity with a dose-weighting mechanism that prioritizes doses based on their historical informativeness. Retrospective simulations on large-scale drug combination datasets show that our method substantially improves initial screening efficiency compared to baselines, offering a viable path for more effective early-phase decision-making in personalized combination drug screens.