Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reinforcement Learning Environment for Mathematical Reasoning via Program Synthesis
Paper and Code
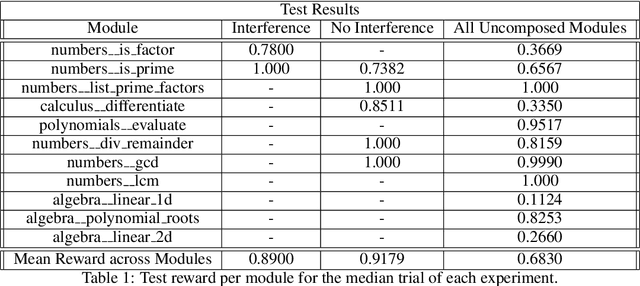
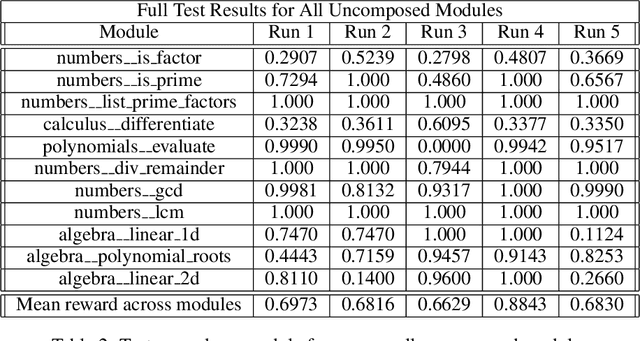
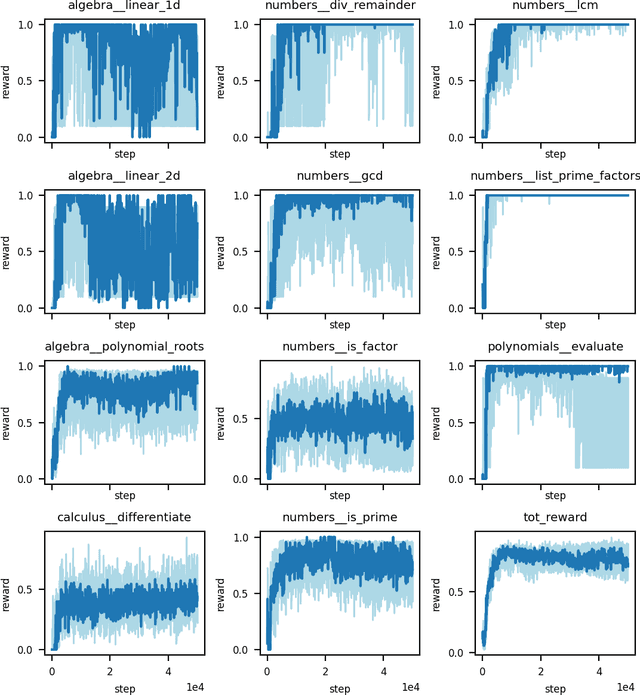
We convert the DeepMind Mathematics Dataset into a reinforcement learning environment by interpreting it as a program synthesis problem. Each action taken in the environment adds an operator or an input into a discrete compute graph. Graphs which compute correct answers yield positive reward, enabling the optimization of a policy to construct compute graphs conditioned on problem statements. Baseline models are trained using Double DQN on various subsets of problem types, demonstrating the capability to learn to correctly construct graphs despite the challenges of combinatorial explosion and noisy rewards.
View paper on
 OpenReview
OpenReview