 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Better Use of Audio-Visual Cues: Dense Video Captioning with Bi-modal Transformer
Paper and Code

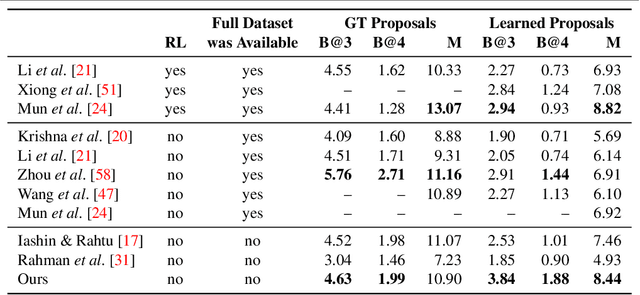
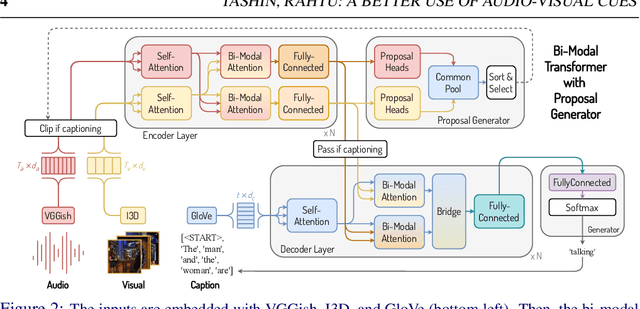
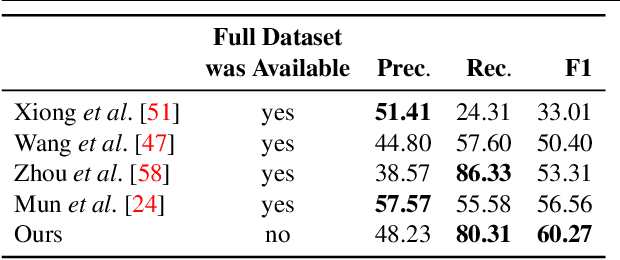
Dense video captioning aims to localize and describe important events in untrimmed videos. Existing methods mainly tackle this task by exploiting only visual features, while completely neglecting the audio track. Only a few prior works have utilized both modalities, yet they show poor results or demonstrate the importance on a dataset with a specific domain. In this paper, we introduce Bi-modal Transformer which generalizes the Transformer architecture for a bi-modal input. We show the effectiveness of the proposed model with audio and visual modalities on the dense video captioning task, yet the module is capable to input any two modalities in a sequence-to-sequence task. We show that the pre-training a bi-modal encoder along with a bi-modal decoder for captioning can be used as a feature extractor for a simple proposal generation module. The performance is demonstrated on a challenging ActivityNet Captions dataset where our model achieves outstanding performance.