 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZiyi Wang
AdaPoinTr: Diverse Point Cloud Completion with Adaptive Geometry-Aware Transformers
Jan 11, 2023
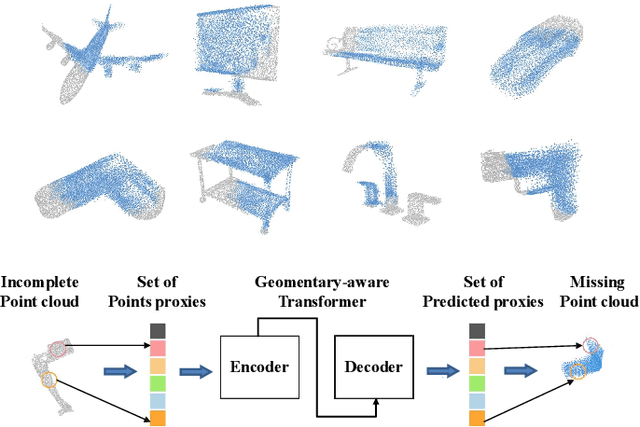
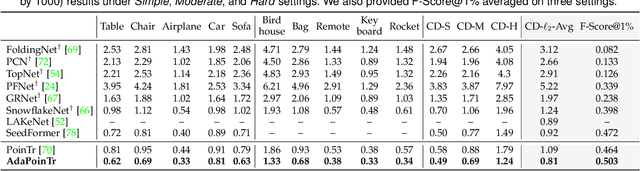
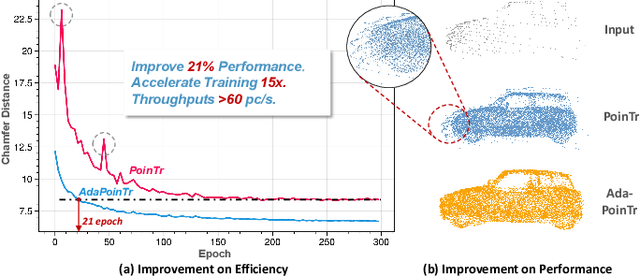
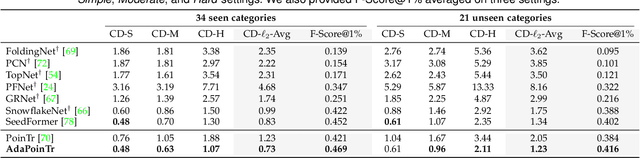
In this paper, we present a new method that reformulates point cloud completion as a set-to-set translation problem and design a new model, called PoinTr, which adopts a Transformer encoder-decoder architecture for point cloud completion. By representing the point cloud as a set of unordered groups of points with position embeddings, we convert the input data to a sequence of point proxies and employ the Transformers for generation. To facilitate Transformers to better leverage the inductive bias about 3D geometric structures of point clouds, we further devise a geometry-aware block that models the local geometric relationships explicitly. The migration of Transformers enables our model to better learn structural knowledge and preserve detailed information for point cloud completion. Taking a step towards more complicated and diverse situations, we further propose AdaPoinTr by developing an adaptive query generation mechanism and designing a novel denoising task during completing a point cloud. Coupling these two techniques enables us to train the model efficiently and effectively: we reduce training time (by 15x or more) and improve completion performance (over 20%). We also show our method can be extended to the scene-level point cloud completion scenario by designing a new geometry-enhanced semantic scene completion framework. Extensive experiments on the existing and newly-proposed datasets demonstrate the effectiveness of our method, which attains 6.53 CD on PCN, 0.81 CD on ShapeNet-55 and 0.392 MMD on real-world KITTI, surpassing other work by a large margin and establishing new state-of-the-arts on various benchmarks. Most notably, AdaPoinTr can achieve such promising performance with higher throughputs and fewer FLOPs compared with the previous best methods in practice. The code and datasets are available at https://github.com/yuxumin/PoinTr
Bootstrap Generalization Ability from Loss Landscape Perspective
Sep 18, 2022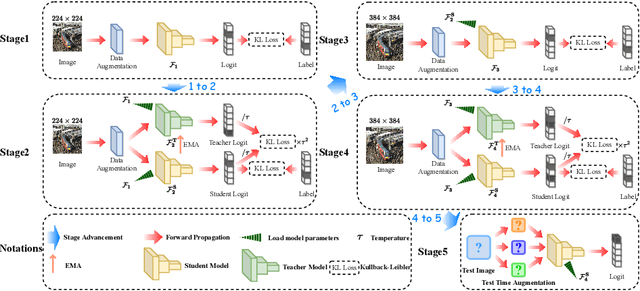

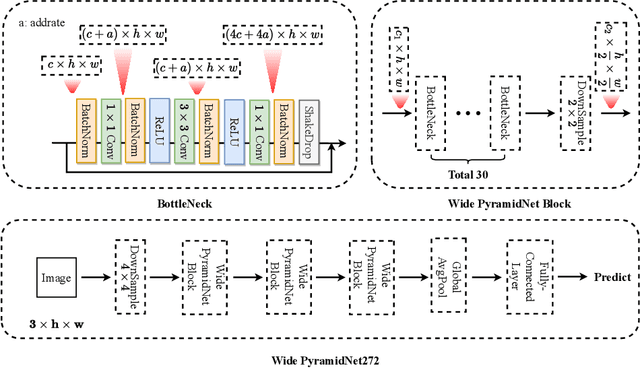
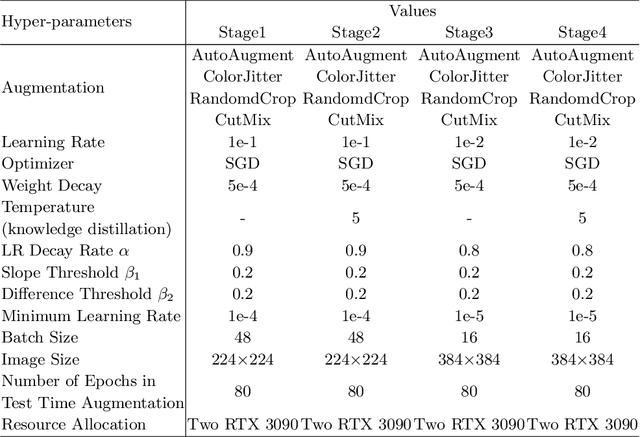
Domain generalization aims to learn a model that can generalize well on the unseen test dataset, i.e., out-of-distribution data, which has different distribution from the training dataset. To address domain generalization in computer vision, we introduce the loss landscape theory into this field. Specifically, we bootstrap the generalization ability of the deep learning model from the loss landscape perspective in four aspects, including backbone, regularization, training paradigm, and learning rate. We verify the proposed theory on the NICO++, PACS, and VLCS datasets by doing extensive ablation studies as well as visualizations. In addition, we apply this theory in the ECCV 2022 NICO Challenge1 and achieve the 3rd place without using any domain invariant methods.
Modeling Price Elasticity for Occupancy Prediction in Hotel Dynamic Pricing
Aug 11, 2022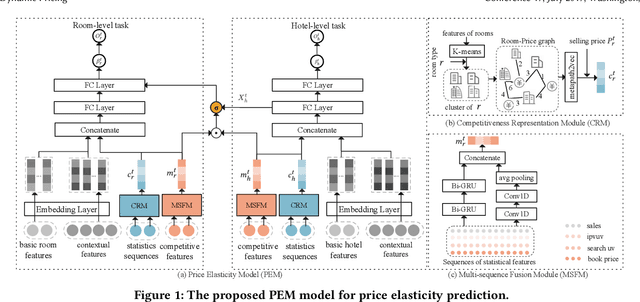
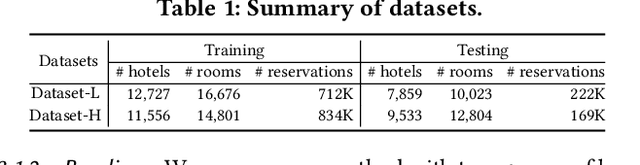
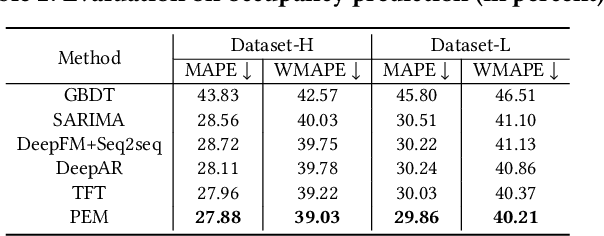

Demand estimation plays an important role in dynamic pricing where the optimal price can be obtained via maximizing the revenue based on the demand curve. In online hotel booking platform, the demand or occupancy of rooms varies across room-types and changes over time, and thus it is challenging to get an accurate occupancy estimate. In this paper, we propose a novel hotel demand function that explicitly models the price elasticity of demand for occupancy prediction, and design a price elasticity prediction model to learn the dynamic price elasticity coefficient from a variety of affecting factors. Our model is composed of carefully designed elasticity learning modules to alleviate the endogeneity problem, and trained in a multi-task framework to tackle the data sparseness. We conduct comprehensive experiments on real-world datasets and validate the superiority of our method over the state-of-the-art baselines for both occupancy prediction and dynamic pricing.
P2P: Tuning Pre-trained Image Models for Point Cloud Analysis with Point-to-Pixel Prompting
Aug 04, 2022
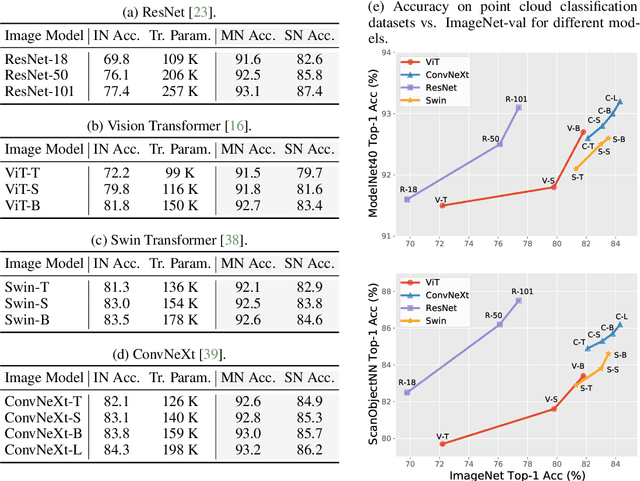
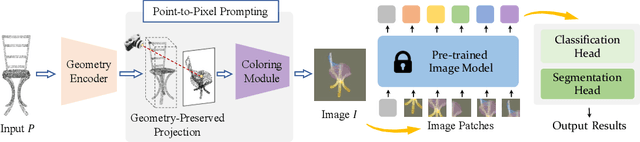
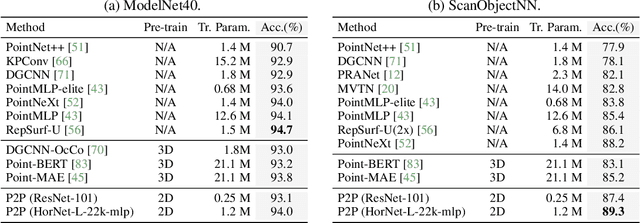
Nowadays, pre-training big models on large-scale datasets has become a crucial topic in deep learning. The pre-trained models with high representation ability and transferability achieve a great success and dominate many downstream tasks in natural language processing and 2D vision. However, it is non-trivial to promote such a pretraining-tuning paradigm to the 3D vision, given the limited training data that are relatively inconvenient to collect. In this paper, we provide a new perspective of leveraging pre-trained 2D knowledge in 3D domain to tackle this problem, tuning pre-trained image models with the novel Point-to-Pixel prompting for point cloud analysis at a minor parameter cost. Following the principle of prompting engineering, we transform point clouds into colorful images with geometry-preserved projection and geometry-aware coloring to adapt to pre-trained image models, whose weights are kept frozen during the end-to-end optimization of point cloud analysis tasks. We conduct extensive experiments to demonstrate that cooperating with our proposed Point-to-Pixel Prompting, better pre-trained image model will lead to consistently better performance in 3D vision. Enjoying prosperous development from image pre-training field, our method attains 89.3% accuracy on the hardest setting of ScanObjectNN, surpassing conventional point cloud models with much fewer trainable parameters. Our framework also exhibits very competitive performance on ModelNet classification and ShapeNet Part Segmentation. Code is available at https://github.com/wangzy22/P2P
Research: Modeling Price Elasticity for Occupancy Prediction in Hotel Dynamic Pricing
Aug 04, 2022Demand estimation plays an important role in dynamic pricing where the optimal price can be obtained via maximizing the revenue based on the demand curve. In online hotel booking platform, the demand or occupancy of rooms varies across room-types and changes over time, and thus it is challenging to get an accurate occupancy estimate. In this paper, we propose a novel hotel demand function that explicitly models the price elasticity of demand for occupancy prediction, and design a price elasticity prediction model to learn the dynamic price elasticity coefficient from a variety of affecting factors. Our model is composed of carefully designed elasticity learning modules to alleviate the endogeneity problem, and trained in a multi-task framework to tackle the data sparseness. We conduct comprehensive experiments on real-world datasets and validate the superiority of our method over the state-of-the-art baselines for both occupancy prediction and dynamic pricing.
AutoLaparo: A New Dataset of Integrated Multi-tasks for Image-guided Surgical Automation in Laparoscopic Hysterectomy
Aug 03, 2022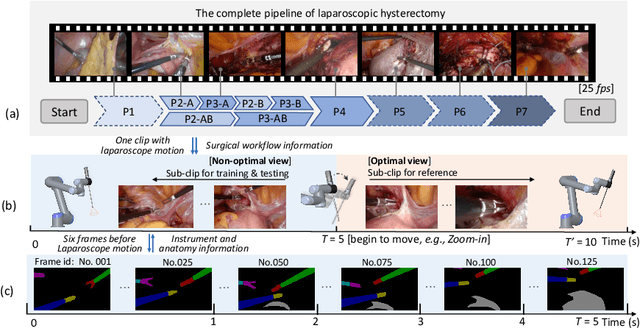

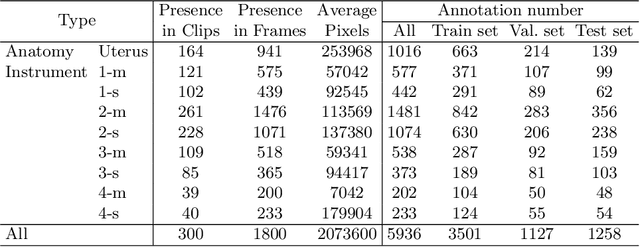

Computer-assisted minimally invasive surgery has great potential in benefiting modern operating theatres. The video data streamed from the endoscope provides rich information to support context-awareness for next-generation intelligent surgical systems. To achieve accurate perception and automatic manipulation during the procedure, learning based technique is a promising way, which enables advanced image analysis and scene understanding in recent years. However, learning such models highly relies on large-scale, high-quality, and multi-task labelled data. This is currently a bottleneck for the topic, as available public dataset is still extremely limited in the field of CAI. In this paper, we present and release the first integrated dataset (named AutoLaparo) with multiple image-based perception tasks to facilitate learning-based automation in hysterectomy surgery. Our AutoLaparo dataset is developed based on full-length videos of entire hysterectomy procedures. Specifically, three different yet highly correlated tasks are formulated in the dataset, including surgical workflow recognition, laparoscope motion prediction, and instrument and key anatomy segmentation. In addition, we provide experimental results with state-of-the-art models as reference benchmarks for further model developments and evaluations on this dataset. The dataset is available at https://autolaparo.github.io.
SemAffiNet: Semantic-Affine Transformation for Point Cloud Segmentation
May 26, 2022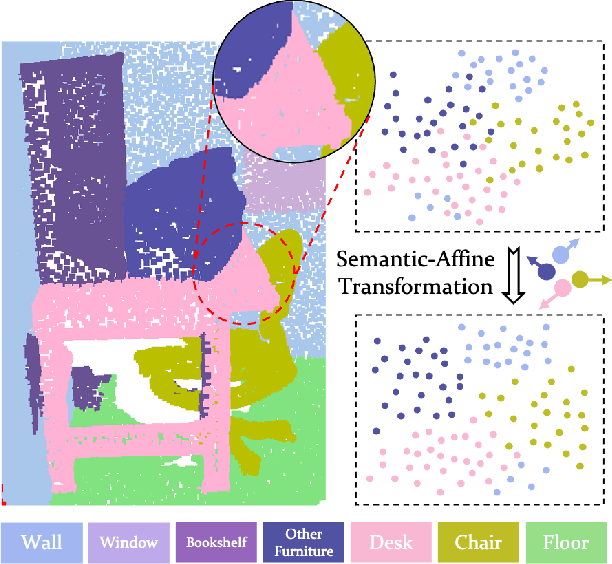
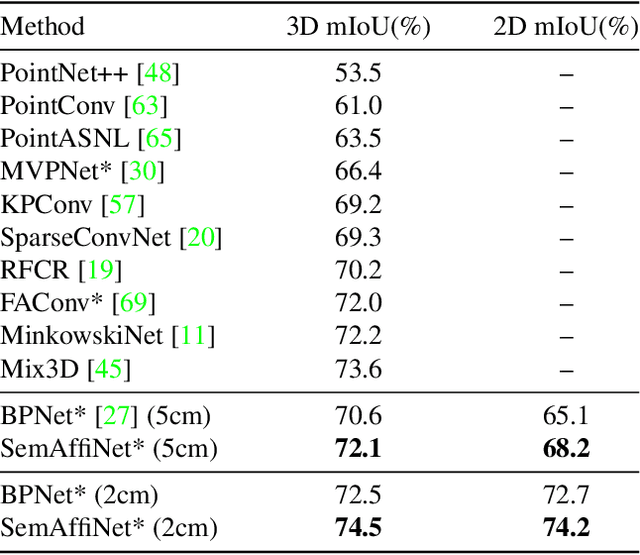
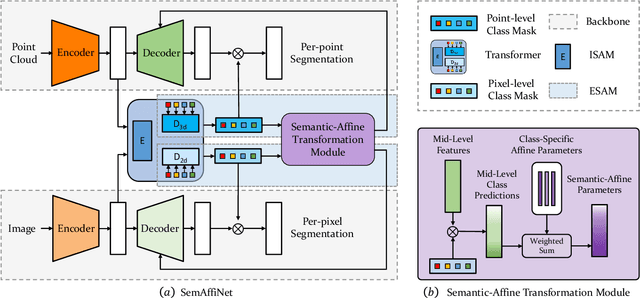
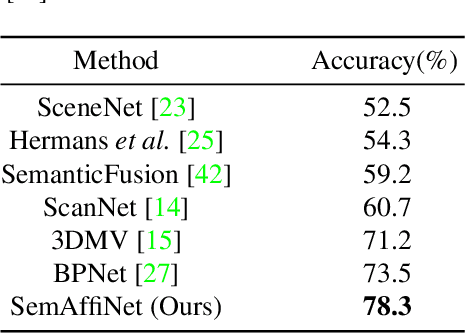
Conventional point cloud semantic segmentation methods usually employ an encoder-decoder architecture, where mid-level features are locally aggregated to extract geometric information. However, the over-reliance on these class-agnostic local geometric representations may raise confusion between local parts from different categories that are similar in appearance or spatially adjacent. To address this issue, we argue that mid-level features can be further enhanced with semantic information, and propose semantic-affine transformation that transforms features of mid-level points belonging to different categories with class-specific affine parameters. Based on this technique, we propose SemAffiNet for point cloud semantic segmentation, which utilizes the attention mechanism in the Transformer module to implicitly and explicitly capture global structural knowledge within local parts for overall comprehension of each category. We conduct extensive experiments on the ScanNetV2 and NYUv2 datasets, and evaluate semantic-affine transformation on various 3D point cloud and 2D image segmentation baselines, where both qualitative and quantitative results demonstrate the superiority and generalization ability of our proposed approach. Code is available at https://github.com/wangzy22/SemAffiNet.
Deep Graphic FBSDEs for Opinion Dynamics Stochastic Control
Apr 18, 2022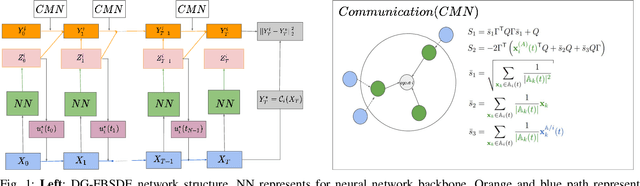
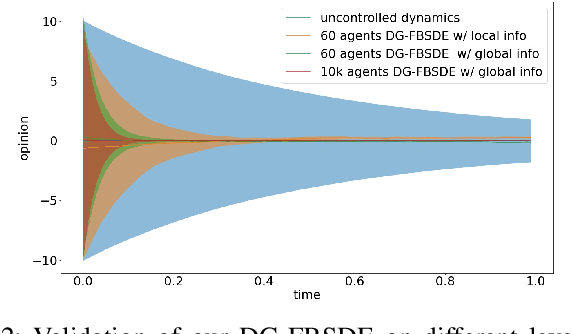

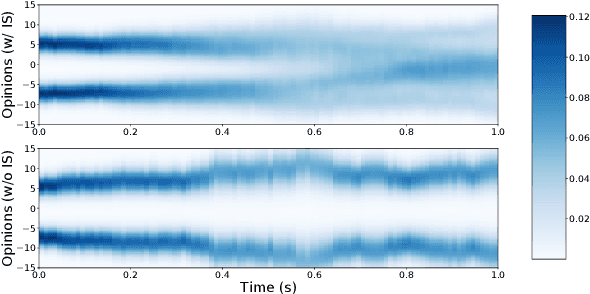
In this paper, we present a scalable deep learning approach to solve opinion dynamics stochastic optimal control problems with mean field term coupling in the dynamics and cost function. Our approach relies on the probabilistic representation of the solution of the Hamilton-Jacobi-Bellman partial differential equation. Grounded on the nonlinear version of the Feynman-Kac lemma, the solutions of the Hamilton-Jacobi-Bellman partial differential equation are linked to the solution of Forward-Backward Stochastic Differential Equations. These equations can be solved numerically using a novel deep neural network with architecture tailored to the problem in consideration. The resulting algorithm is tested on a polarized opinion consensus experiment. The large-scale (10K) agents experiment validates the scalability and generalizability of our algorithm. The proposed framework opens up the possibility for future applications on extremely large-scale problems.
A Roadmap for Big Model
Apr 02, 2022



With the rapid development of deep learning, training Big Models (BMs) for multiple downstream tasks becomes a popular paradigm. Researchers have achieved various outcomes in the construction of BMs and the BM application in many fields. At present, there is a lack of research work that sorts out the overall progress of BMs and guides the follow-up research. In this paper, we cover not only the BM technologies themselves but also the prerequisites for BM training and applications with BMs, dividing the BM review into four parts: Resource, Models, Key Technologies and Application. We introduce 16 specific BM-related topics in those four parts, they are Data, Knowledge, Computing System, Parallel Training System, Language Model, Vision Model, Multi-modal Model, Theory&Interpretability, Commonsense Reasoning, Reliability&Security, Governance, Evaluation, Machine Translation, Text Generation, Dialogue and Protein Research. In each topic, we summarize clearly the current studies and propose some future research directions. At the end of this paper, we conclude the further development of BMs in a more general view.