 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhiwu Huang
Improving Video Generation for Multi-functional Applications
Mar 14, 2018
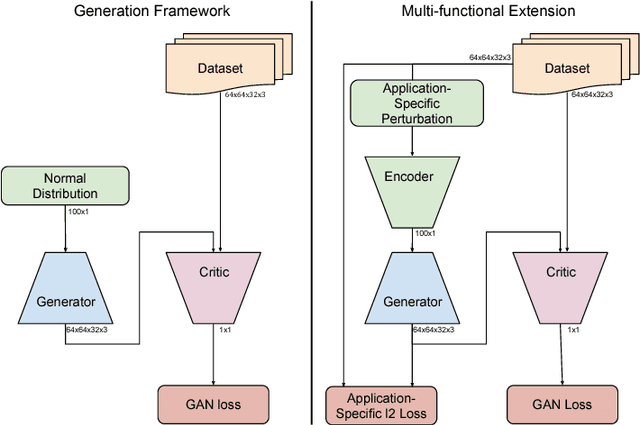


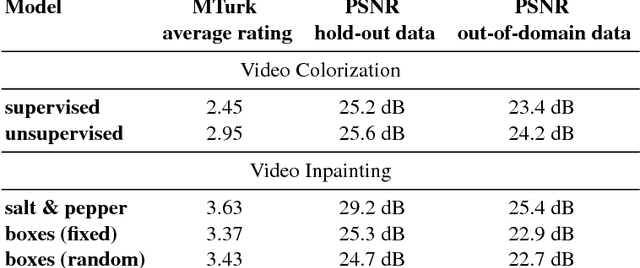
In this paper, we aim to improve the state-of-the-art video generative adversarial networks (GANs) with a view towards multi-functional applications. Our improved video GAN model does not separate foreground from background nor dynamic from static patterns, but learns to generate the entire video clip conjointly. Our model can thus be trained to generate - and learn from - a broad set of videos with no restriction. This is achieved by designing a robust one-stream video generation architecture with an extension of the state-of-the-art Wasserstein GAN framework that allows for better convergence. The experimental results show that our improved video GAN model outperforms state-of-theart video generative models on multiple challenging datasets. Furthermore, we demonstrate the superiority of our model by successfully extending it to three challenging problems: video colorization, video inpainting, and future prediction. To the best of our knowledge, this is the first work using GANs to colorize and inpaint video clips.
Sliced Wasserstein Generative Models
Mar 05, 2018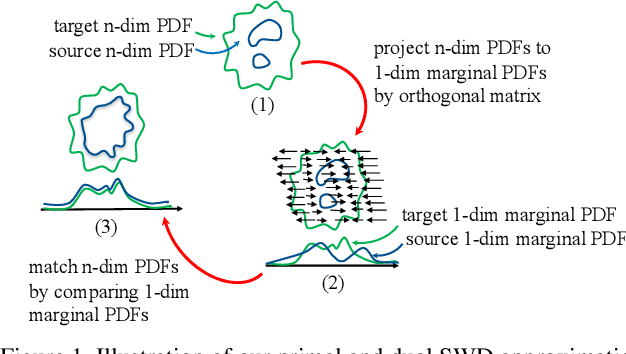
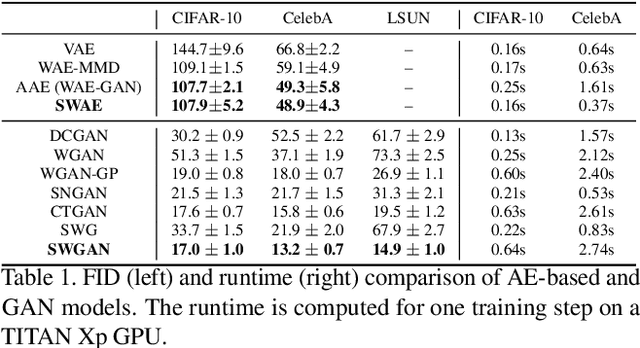
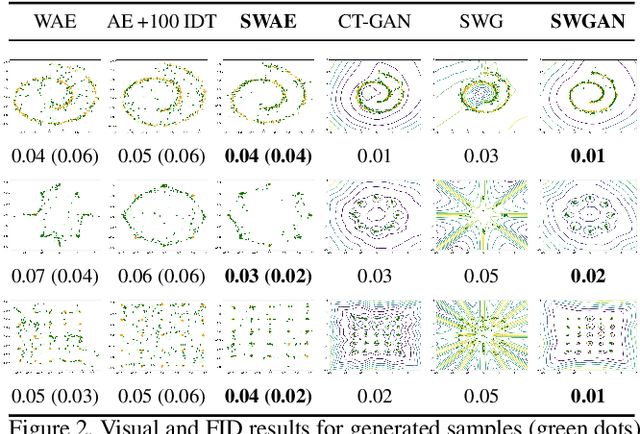
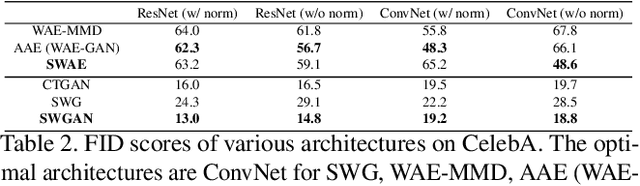
In the paper, we introduce a model of sliced optimal transport (SOT), which measures the distribution affinity with sliced Wasserstein distance (SWD). Since SWD enjoys the property of factorizing high-dimensional joint distributions into their multiple one-dimensional marginal distributions, its dual and primal forms can be approximated easier compared to Wasserstein distance (WD). Thus, we propose two types of differentiable SOT blocks to equip modern generative frameworks---Auto-Encoders (AEs) and Generative Adversarial Networks (GANs)---with the primal and dual forms of SWD. The superiority of our SWAE and SWGAN over the state-of-the-art generative models is studied both qualitatively and quantitatively on standard benchmarks.
Building Deep Networks on Grassmann Manifolds
Jan 29, 2018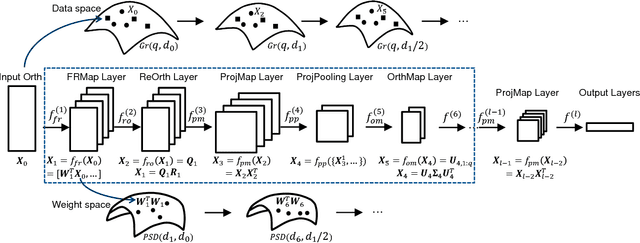
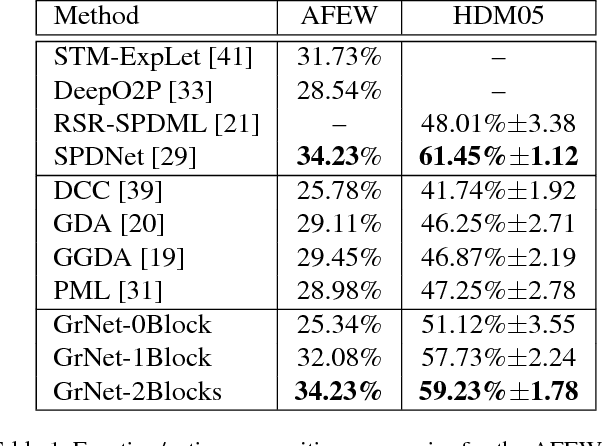
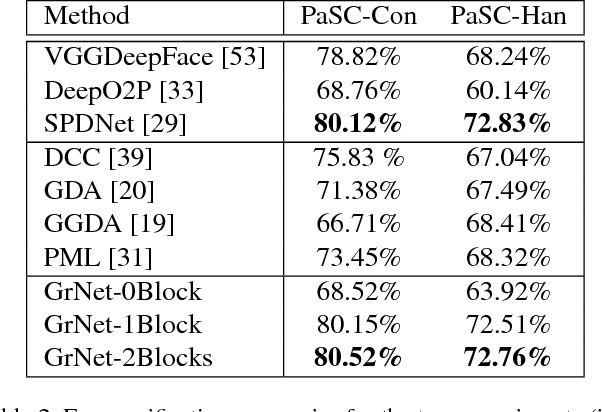
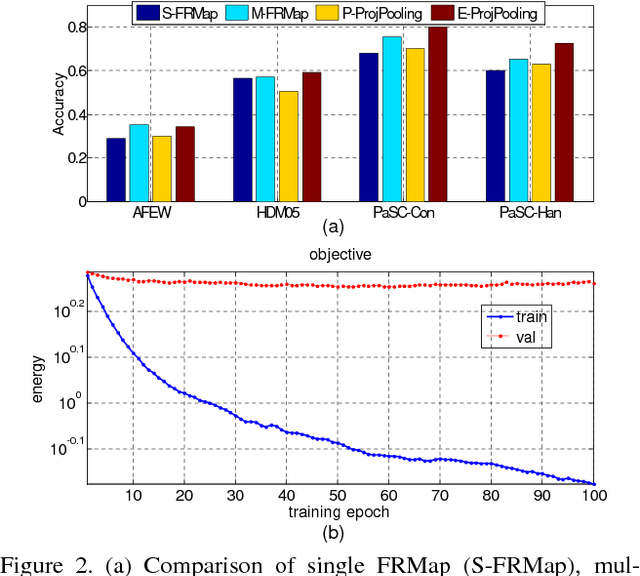
Learning representations on Grassmann manifolds is popular in quite a few visual recognition tasks. In order to enable deep learning on Grassmann manifolds, this paper proposes a deep network architecture by generalizing the Euclidean network paradigm to Grassmann manifolds. In particular, we design full rank mapping layers to transform input Grassmannian data to more desirable ones, exploit re-orthonormalization layers to normalize the resulting matrices, study projection pooling layers to reduce the model complexity in the Grassmannian context, and devise projection mapping layers to respect Grassmannian geometry and meanwhile achieve Euclidean forms for regular output layers. To train the Grassmann networks, we exploit a stochastic gradient descent setting on manifolds of the connection weights, and study a matrix generalization of backpropagation to update the structured data. The evaluations on three visual recognition tasks show that our Grassmann networks have clear advantages over existing Grassmann learning methods, and achieve results comparable with state-of-the-art approaches.
Manifold-valued Image Generation with Wasserstein Adversarial Networks
Dec 05, 2017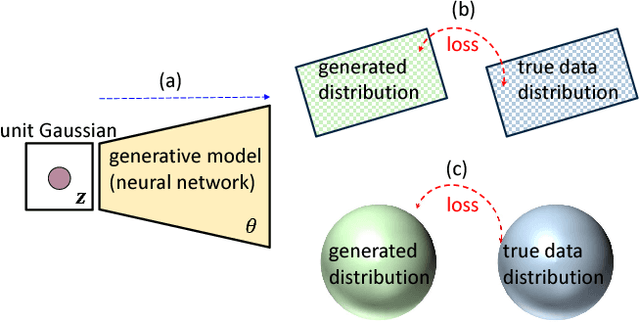

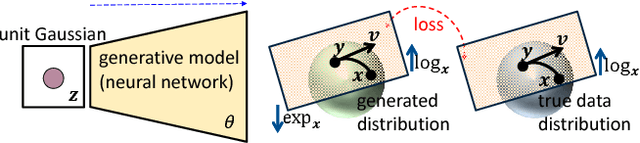

Unsupervised image generation has recently received an increasing amount of attention thanks to the great success of generative adversarial networks (GANs), particularly Wasserstein GANs. Inspired by the paradigm of real-valued image generation, this paper makes the first attempt to formulate the problem of generating manifold-valued images, which are frequently encountered in real-world applications. For the study, we specially exploit three typical manifold-valued image generation tasks: hue-saturation-value (HSV) color image generation, chromaticity-brightness (CB) color image generation, and diffusion-tensor (DT) image generation. In order to produce such kinds of images as realistic as possible, we generalize the state-of-the-art technique of Wasserstein GANs to the manifold context with exploiting Riemannian geometry. For the proposed manifold-valued image generation problem, we recommend three benchmark datasets that are CIFAR-10 HSV/CB color images, ImageNet HSV/CB color images, UCL DT image datasets. On the three datasets, we experimentally demonstrate the proposed manifold-aware Wasserestein GAN can generate high quality manifold-valued images.
Face Translation between Images and Videos using Identity-aware CycleGAN
Dec 04, 2017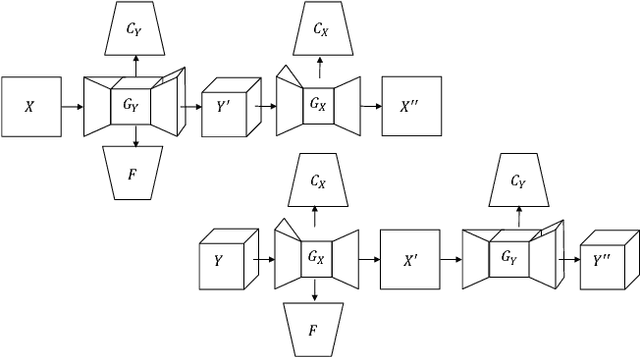
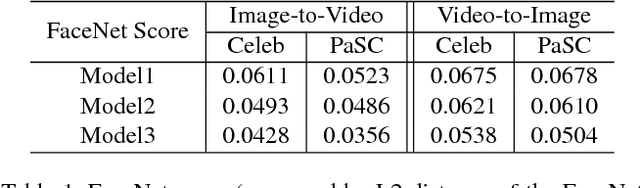
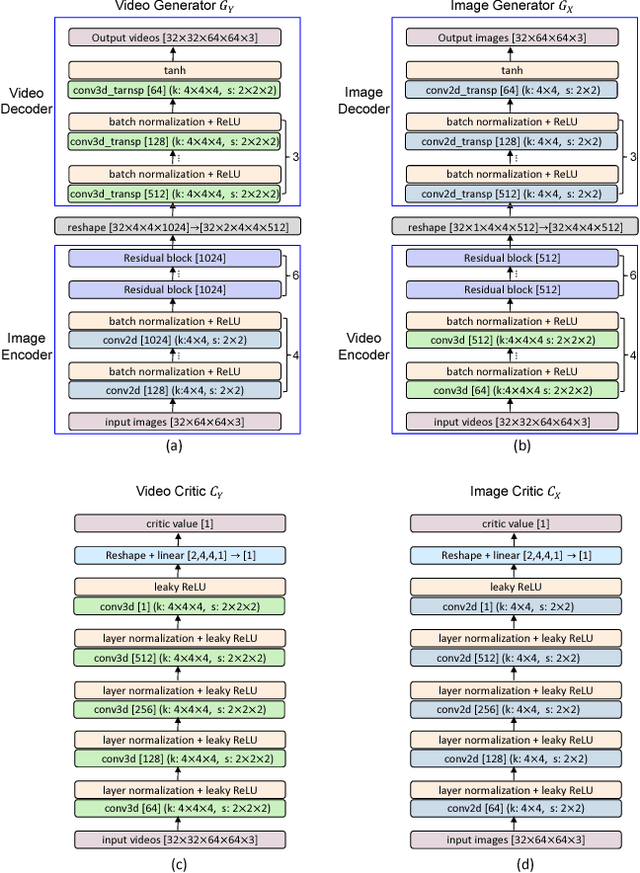

This paper presents a new problem of unpaired face translation between images and videos, which can be applied to facial video prediction and enhancement. In this problem there exist two major technical challenges: 1) designing a robust translation model between static images and dynamic videos, and 2) preserving facial identity during image-video translation. To address such two problems, we generalize the state-of-the-art image-to-image translation network (Cycle-Consistent Adversarial Networks) to the image-to-video/video-to-image translation context by exploiting a image-video translation model and an identity preservation model. In particular, we apply the state-of-the-art Wasserstein GAN technique to the setting of image-video translation for better convergence, and we meanwhile introduce a face verificator to ensure the identity. Experiments on standard image/video face datasets demonstrate the effectiveness of the proposed model in both terms of qualitative and quantitative evaluations.
Deep Learning on Lie Groups for Skeleton-based Action Recognition
Apr 11, 2017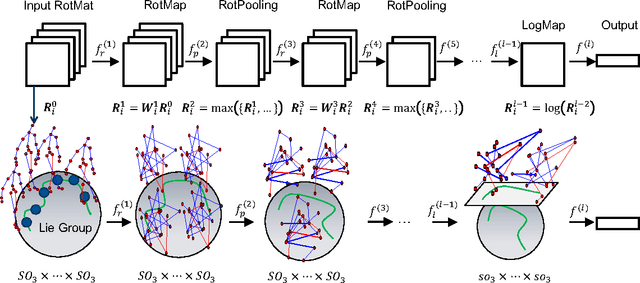
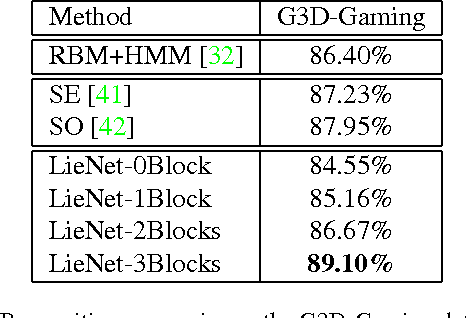
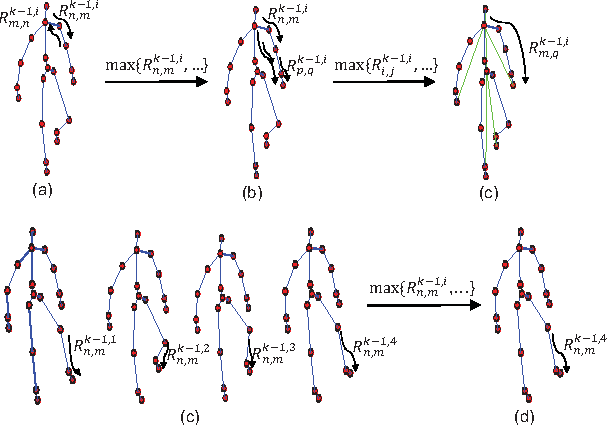
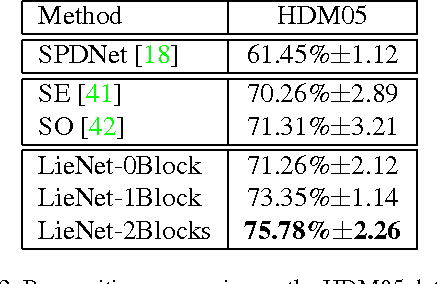
In recent years, skeleton-based action recognition has become a popular 3D classification problem. State-of-the-art methods typically first represent each motion sequence as a high-dimensional trajectory on a Lie group with an additional dynamic time warping, and then shallowly learn favorable Lie group features. In this paper we incorporate the Lie group structure into a deep network architecture to learn more appropriate Lie group features for 3D action recognition. Within the network structure, we design rotation mapping layers to transform the input Lie group features into desirable ones, which are aligned better in the temporal domain. To reduce the high feature dimensionality, the architecture is equipped with rotation pooling layers for the elements on the Lie group. Furthermore, we propose a logarithm mapping layer to map the resulting manifold data into a tangent space that facilitates the application of regular output layers for the final classification. Evaluations of the proposed network for standard 3D human action recognition datasets clearly demonstrate its superiority over existing shallow Lie group feature learning methods as well as most conventional deep learning methods.
On the Relation between Color Image Denoising and Classification
Apr 05, 2017
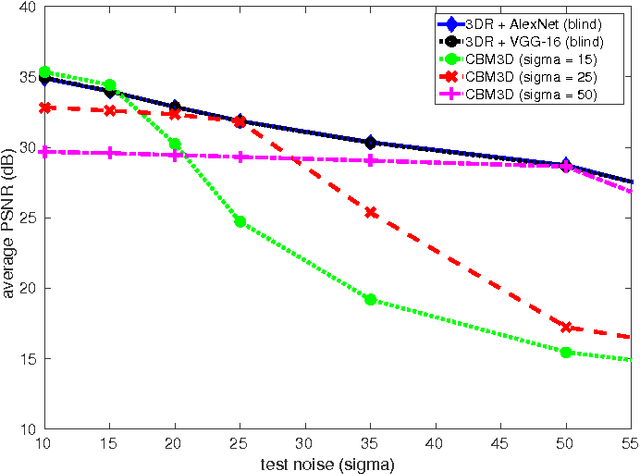

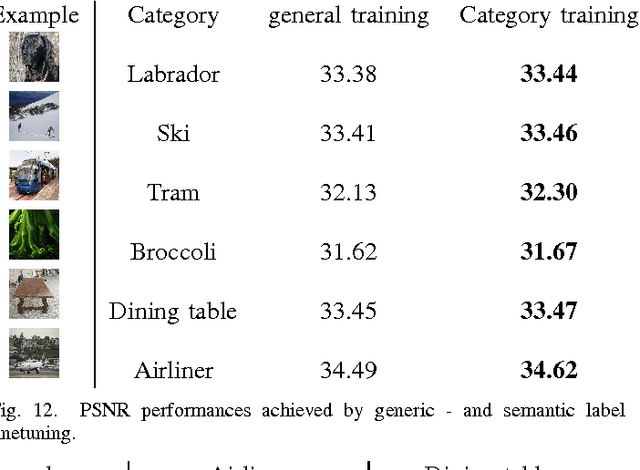
Large amount of image denoising literature focuses on single channel images and often experimentally validates the proposed methods on tens of images at most. In this paper, we investigate the interaction between denoising and classification on large scale dataset. Inspired by classification models, we propose a novel deep learning architecture for color (multichannel) image denoising and report on thousands of images from ImageNet dataset as well as commonly used imagery. We study the importance of (sufficient) training data, how semantic class information can be traded for improved denoising results. As a result, our method greatly improves PSNR performance by 0.34 - 0.51 dB on average over state-of-the art methods on large scale dataset. We conclude that it is beneficial to incorporate in classification models. On the other hand, we also study how noise affect classification performance. In the end, we come to a number of interesting conclusions, some being counter-intuitive.
Cross Euclidean-to-Riemannian Metric Learning with Application to Face Recognition from Video
Jan 06, 2017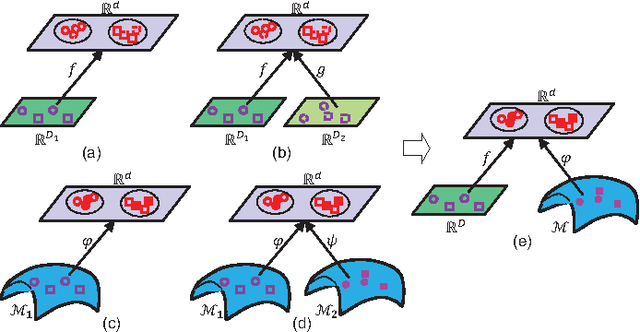
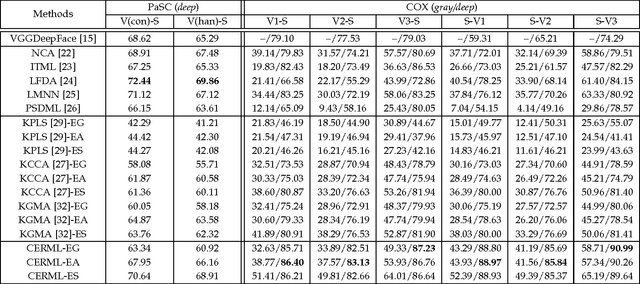
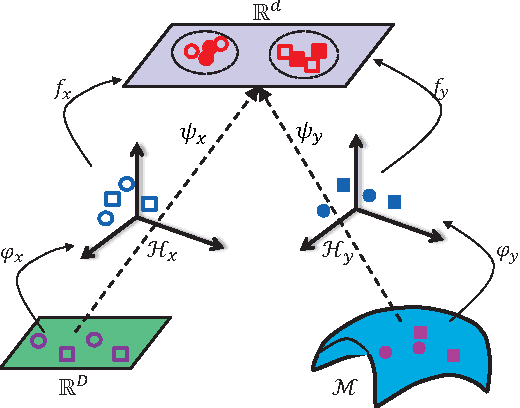
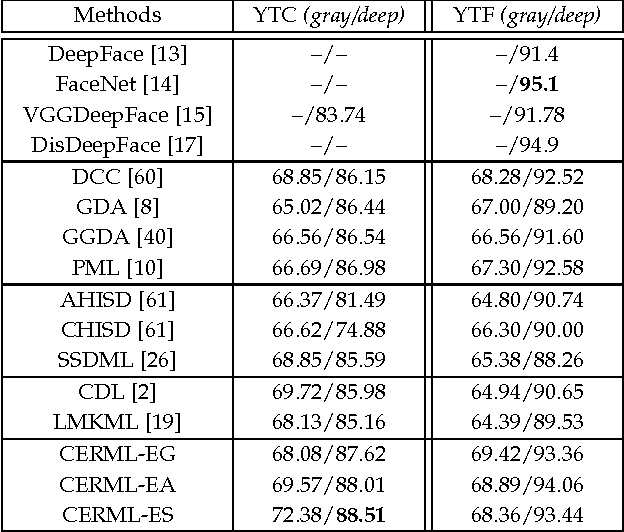
Riemannian manifolds have been widely employed for video representations in visual classification tasks including video-based face recognition. The success mainly derives from learning a discriminant Riemannian metric which encodes the non-linear geometry of the underlying Riemannian manifolds. In this paper, we propose a novel metric learning framework to learn a distance metric across a Euclidean space and a Riemannian manifold to fuse the average appearance and pattern variation of faces within one video. The proposed metric learning framework can handle three typical tasks of video-based face recognition: Video-to-Still, Still-to-Video and Video-to-Video settings. To accomplish this new framework, by exploiting typical Riemannian geometries for kernel embedding, we map the source Euclidean space and Riemannian manifold into a common Euclidean subspace, each through a corresponding high-dimensional Reproducing Kernel Hilbert Space (RKHS). With this mapping, the problem of learning a cross-view metric between the two source heterogeneous spaces can be expressed as learning a single-view Euclidean distance metric in the target common Euclidean space. By learning information on heterogeneous data with the shared label, the discriminant metric in the common space improves face recognition from videos. Extensive experiments on four challenging video face databases demonstrate that the proposed framework has a clear advantage over the state-of-the-art methods in the three classical video-based face recognition tasks.
A Riemannian Network for SPD Matrix Learning
Dec 22, 2016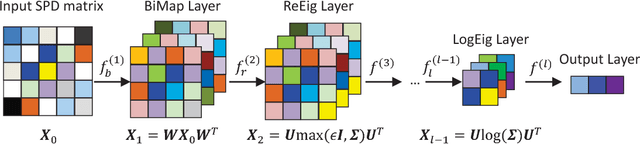
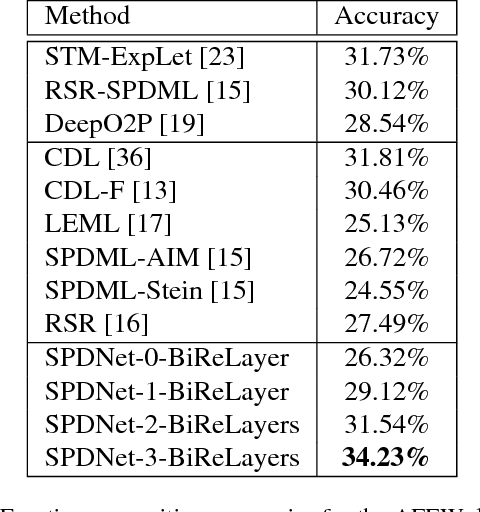
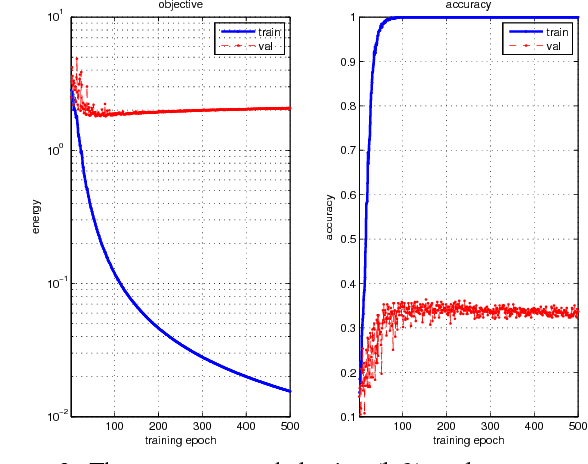
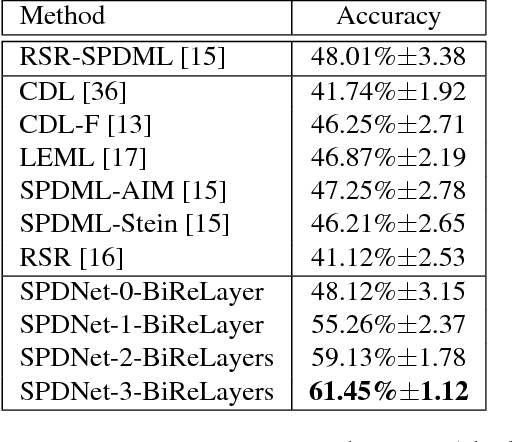
Symmetric Positive Definite (SPD) matrix learning methods have become popular in many image and video processing tasks, thanks to their ability to learn appropriate statistical representations while respecting Riemannian geometry of underlying SPD manifolds. In this paper we build a Riemannian network architecture to open up a new direction of SPD matrix non-linear learning in a deep model. In particular, we devise bilinear mapping layers to transform input SPD matrices to more desirable SPD matrices, exploit eigenvalue rectification layers to apply a non-linear activation function to the new SPD matrices, and design an eigenvalue logarithm layer to perform Riemannian computing on the resulting SPD matrices for regular output layers. For training the proposed deep network, we exploit a new backpropagation with a variant of stochastic gradient descent on Stiefel manifolds to update the structured connection weights and the involved SPD matrix data. We show through experiments that the proposed SPD matrix network can be simply trained and outperform existing SPD matrix learning and state-of-the-art methods in three typical visual classification tasks.
Geometry-aware Similarity Learning on SPD Manifolds for Visual Recognition
Aug 17, 2016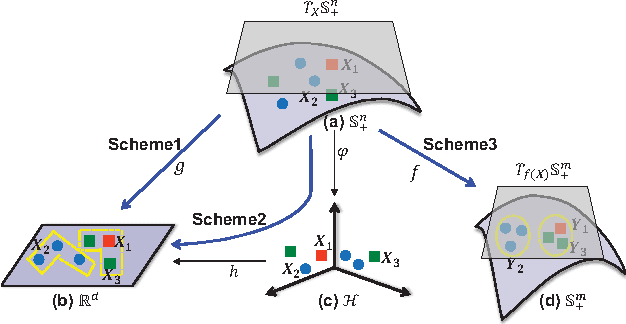
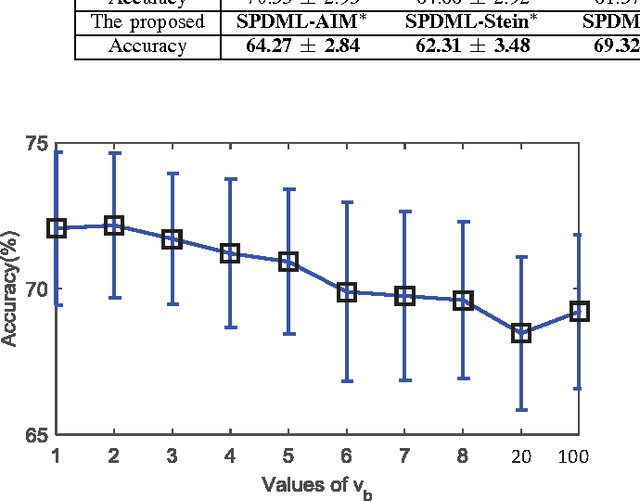
Symmetric Positive Definite (SPD) matrices have been widely used for data representation in many visual recognition tasks. The success mainly attributes to learning discriminative SPD matrices with encoding the Riemannian geometry of the underlying SPD manifold. In this paper, we propose a geometry-aware SPD similarity learning (SPDSL) framework to learn discriminative SPD features by directly pursuing manifold-manifold transformation matrix of column full-rank. Specifically, by exploiting the Riemannian geometry of the manifold of fixed-rank Positive Semidefinite (PSD) matrices, we present a new solution to reduce optimizing over the space of column full-rank transformation matrices to optimizing on the PSD manifold which has a well-established Riemannian structure. Under this solution, we exploit a new supervised SPD similarity learning technique to learn the transformation by regressing the similarities of selected SPD data pairs to their ground-truth similarities on the target SPD manifold. To optimize the proposed objective function, we further derive an algorithm on the PSD manifold. Evaluations on three visual classification tasks show the advantages of the proposed approach over the existing SPD-based discriminant learning methods.