 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhiqiang He
Confidence-Guided Radiology Report Generation
Jun 21, 2021
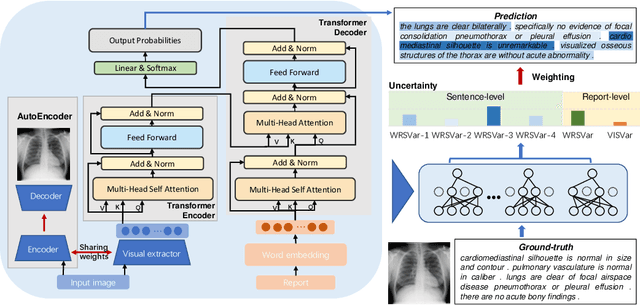
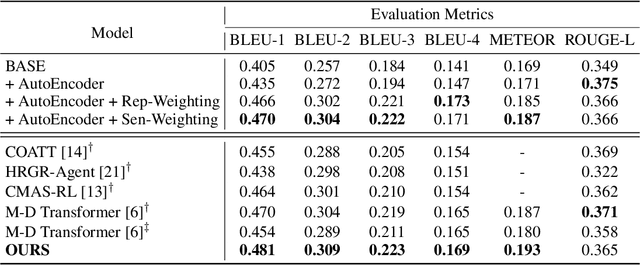
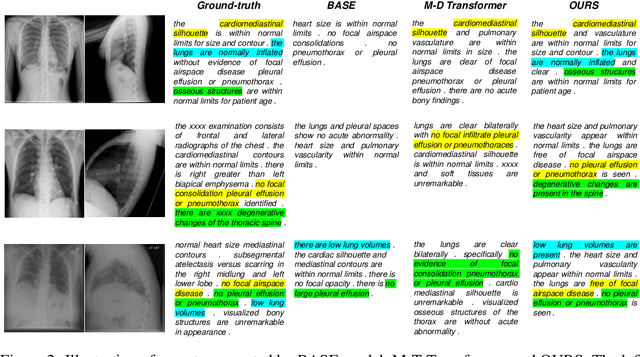

Medical imaging plays a pivotal role in diagnosis and treatment in clinical practice. Inspired by the significant progress in automatic image captioning, various deep learning (DL)-based architectures have been proposed for generating radiology reports for medical images. However, model uncertainty (i.e., model reliability/confidence on report generation) is still an under-explored problem. In this paper, we propose a novel method to explicitly quantify both the visual uncertainty and the textual uncertainty for the task of radiology report generation. Such multi-modal uncertainties can sufficiently capture the model confidence scores at both the report-level and the sentence-level, and thus they are further leveraged to weight the losses for achieving more comprehensive model optimization. Our experimental results have demonstrated that our proposed method for model uncertainty characterization and estimation can provide more reliable confidence scores for radiology report generation, and our proposed uncertainty-weighted losses can achieve more comprehensive model optimization and result in state-of-the-art performance on a public radiology report dataset.
Semi-supervised Cardiac Image Segmentation via Label Propagation and Style Transfer
Dec 29, 2020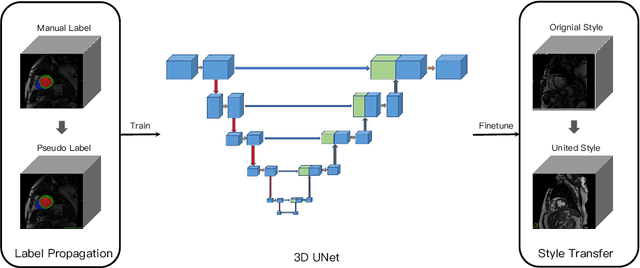
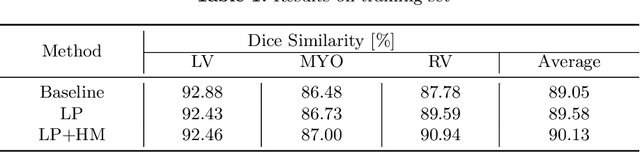
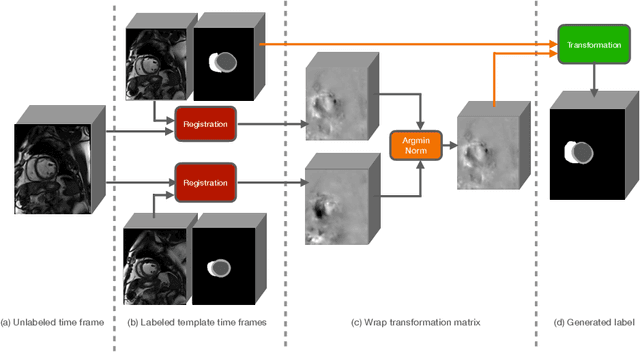

Accurate segmentation of cardiac structures can assist doctors to diagnose diseases, and to improve treatment planning, which is highly demanded in the clinical practice. However, the shortage of annotation and the variance of the data among different vendors and medical centers restrict the performance of advanced deep learning methods. In this work, we present a fully automatic method to segment cardiac structures including the left (LV) and right ventricle (RV) blood pools, as well as for the left ventricular myocardium (MYO) in MRI volumes. Specifically, we design a semi-supervised learning method to leverage unlabelled MRI sequence timeframes by label propagation. Then we exploit style transfer to reduce the variance among different centers and vendors for more robust cardiac image segmentation. We evaluate our method in the M&Ms challenge 7 , ranking 2nd place among 14 competitive teams.
Double-Uncertainty Weighted Method for Semi-supervised Learning
Oct 19, 2020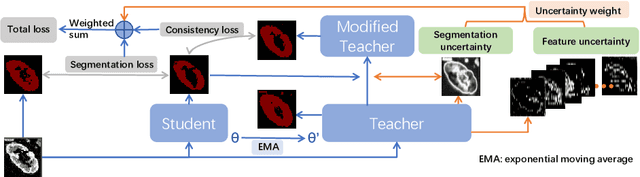
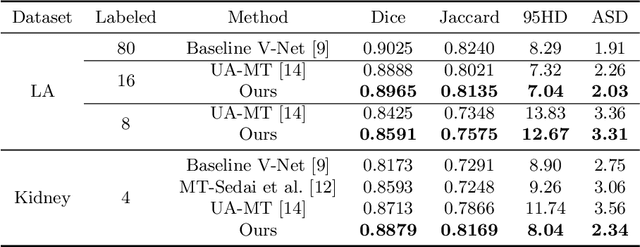
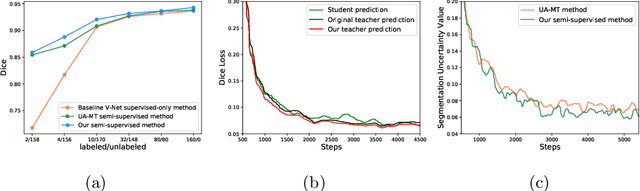
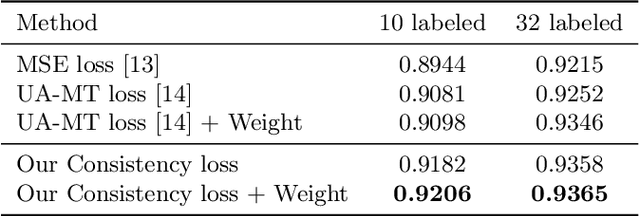
Though deep learning has achieved advanced performance recently, it remains a challenging task in the field of medical imaging, as obtaining reliable labeled training data is time-consuming and expensive. In this paper, we propose a double-uncertainty weighted method for semi-supervised segmentation based on the teacher-student model. The teacher model provides guidance for the student model by penalizing their inconsistent prediction on both labeled and unlabeled data. We train the teacher model using Bayesian deep learning to obtain double-uncertainty, i.e. segmentation uncertainty and feature uncertainty. It is the first to extend segmentation uncertainty estimation to feature uncertainty, which reveals the capability to capture information among channels. A learnable uncertainty consistency loss is designed for the unsupervised learning process in an interactive manner between prediction and uncertainty. With no ground-truth for supervision, it can still incentivize more accurate teacher's predictions and facilitate the model to reduce uncertain estimations. Furthermore, our proposed double-uncertainty serves as a weight on each inconsistency penalty to balance and harmonize supervised and unsupervised training processes. We validate the proposed feature uncertainty and loss function through qualitative and quantitative analyses. Experimental results show that our method outperforms the state-of-the-art uncertainty-based semi-supervised methods on two public medical datasets.
Modality-Pairing Learning for Brain Tumor Segmentation
Oct 19, 2020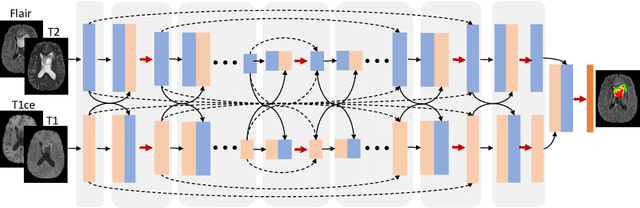
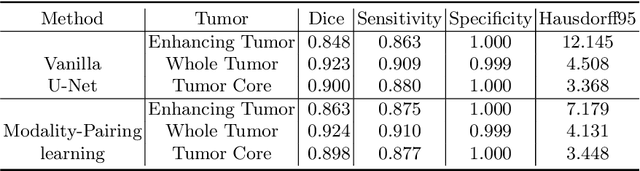
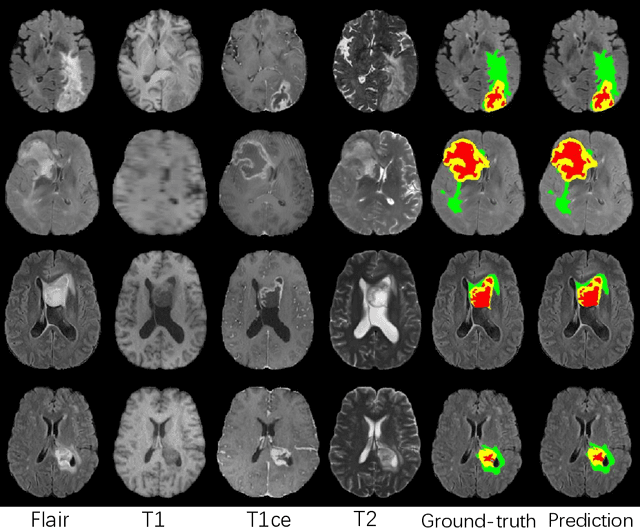
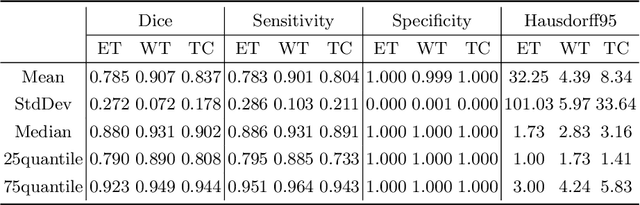
Automatic brain tumor segmentation from multi-modality Magnetic Resonance Images (MRI) using deep learning methods plays an important role in assisting the diagnosis and treatment of brain tumor. However, previous methods mostly ignore the latent relationship among different modalities. In this work, we propose a novel end-to-end Modality-Pairing learning method for brain tumor segmentation. Paralleled branches are designed to exploit different modality features and a series of layer connections are utilized to capture complex relationships and abundant information among modalities. We also use a consistency loss to minimize the prediction variance between two branches. Besides, learning rate warmup strategy is adopted to solve the problem of the training instability and early over-fitting. Lastly, we use average ensemble of multiple models and some post-processing techniques to get final results. Our method is tested on the BraTS 2020 validation dataset, obtaining promising segmentation performance, with average dice scores of $0.908, 0.856, 0.787$ for the whole tumor, tumor core and enhancing tumor, respectively. We won the second place of the BraTS 2020 Challenge for the tumor segmentation on the testing dataset.
Does Non-COVID19 Lung Lesion Help? Investigating Transferability in COVID-19 CT Image Segmentation
Jun 23, 2020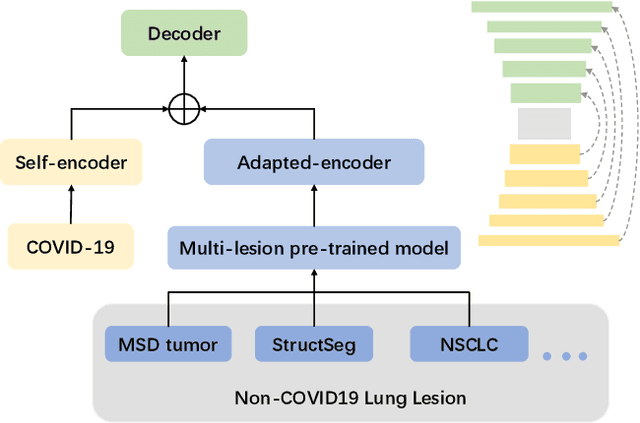
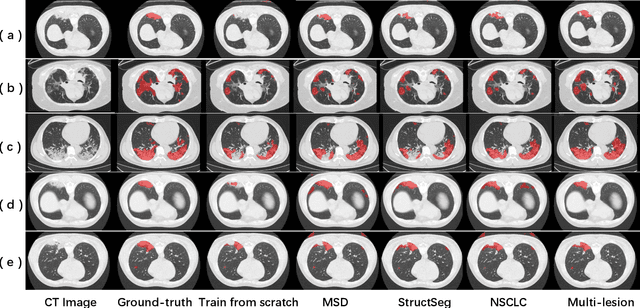
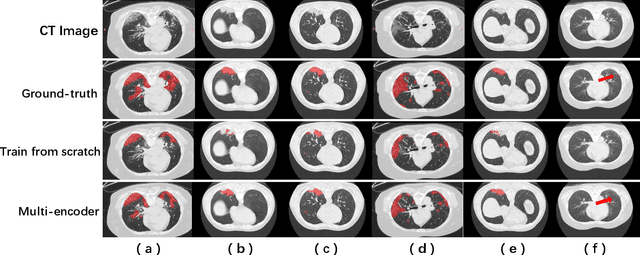
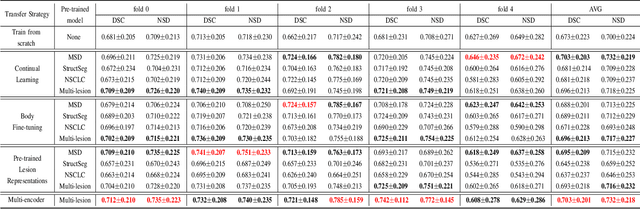
Coronavirus disease 2019 (COVID-19) is a highly contagious virus spreading all around the world. Deep learning has been adopted as an effective technique to aid COVID-19 detection and segmentation from computed tomography (CT) images. The major challenge lies in the inadequate public COVID-19 datasets. Recently, transfer learning has become a widely used technique that leverages the knowledge gained while solving one problem and applying it to a different but related problem. However, it remains unclear whether various non-COVID19 lung lesions could contribute to segmenting COVID-19 infection areas and how to better conduct this transfer procedure. This paper provides a way to understand the transferability of non-COVID19 lung lesions. Based on a publicly available COVID-19 CT dataset and three public non-COVID19 datasets, we evaluate four transfer learning methods using 3D U-Net as a standard encoder-decoder method. The results reveal the benefits of transferring knowledge from non-COVID19 lung lesions, and learning from multiple lung lesion datasets can extract more general features, leading to accurate and robust pre-trained models. We further show the capability of the encoder to learn feature representations of lung lesions, which improves segmentation accuracy and facilitates training convergence. In addition, our proposed Multi-encoder learning method incorporates transferred lung lesion features from non-COVID19 datasets effectively and achieves significant improvement. These findings promote new insights into transfer learning for COVID-19 CT image segmentation, which can also be further generalized to other medical tasks.
Towards Efficient COVID-19 CT Annotation: A Benchmark for Lung and Infection Segmentation
Apr 27, 2020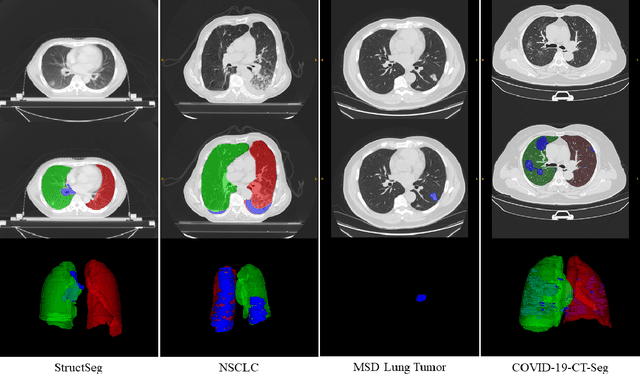

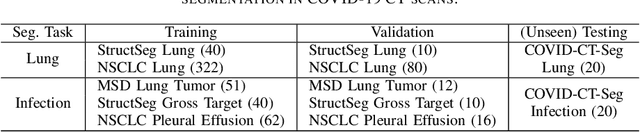
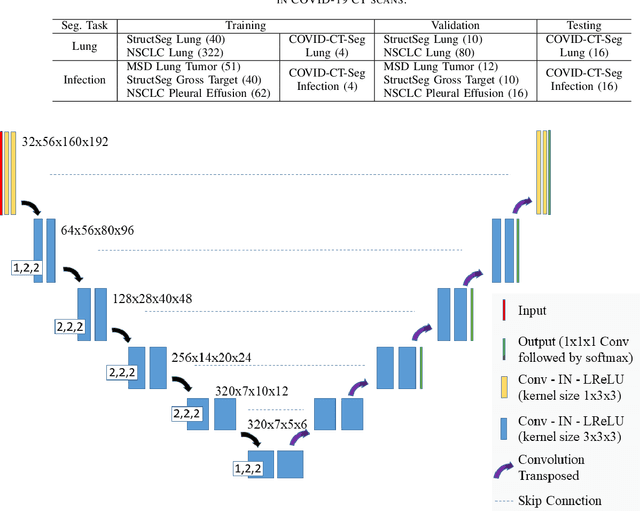
Accurate segmentation of lung and infection in COVID-19 CT scans plays an important role in the quantitative management of patients. Most of the existing studies are based on large and private annotated datasets that are impractical to obtain from a single institution, especially when radiologists are busy fighting the coronavirus disease. Furthermore, it is hard to compare current COVID-19 CT segmentation methods as they are developed on different datasets, trained in different settings, and evaluated with different metrics. In this paper, we created a COVID-19 3D CT dataset with 20 cases that contains 1800+ annotated slices and made it publicly available. To promote the development of annotation-efficient deep learning methods, we built three benchmarks for lung and infection segmentation that contain current main research interests, e.g., few-shot learning, domain generalization, and knowledge transfer. For a fair comparison among different segmentation methods, we also provide unified training, validation and testing dataset splits, and evaluation metrics and corresponding code. In addition, we provided more than 40 pre-trained baseline models for the benchmarks, which not only serve as out-of-the-box segmentation tools but also save computational time for researchers who are interested in COVID-19 lung and infection segmentation. To the best of our knowledge, this work presents the largest public annotated COVID-19 CT volume dataset, the first segmentation benchmark, and the most pre-trained models up to now. We hope these resources (\url{https://gitee.com/junma11/COVID-19-CT-Seg-Benchmark}) could advance the development of deep learning methods for COVID-19 CT segmentation with limited data.
Semantic Feature Attention Network for Liver Tumor Segmentation in Large-scale CT database
Nov 01, 2019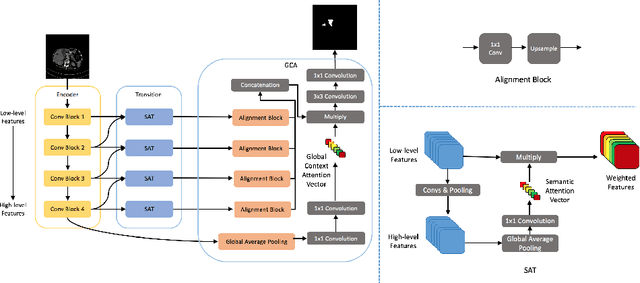
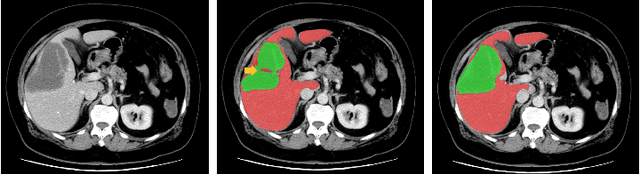
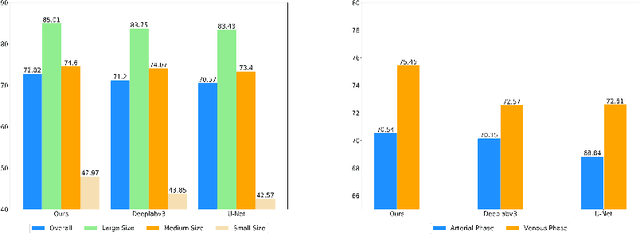
Liver tumor segmentation plays an important role in hepatocellular carcinoma diagnosis and surgical planning. In this paper, we propose a novel Semantic Feature Attention Network (SFAN) for liver tumor segmentation from Computed Tomography (CT) volumes, which exploits the impact of both low-level and high-level features. In the SFAN, a Semantic Attention Transmission (SAT) module is designed to select discriminative low-level localization details with the guidance of neighboring high-level semantic information. Furthermore, a Global Context Attention (GCA) module is proposed to effectively fuse the multi-level features with the guidance of global context. Our experiments are based on 2 challenging databases, the public Liver Tumor Segmentation (LiTS) Challenge database and a large-scale in-house clinical database with 912 CT volumes. Experimental results show that our proposed framework can not only achieve the state-of-the-art performance with the Dice per case on liver tumor segmentation in LiTS database, but also outperform some widely used segmentation algorithms in the large-scale clinical database.
Image Co-segmentation via Multi-scale Local Shape Transfer
May 15, 2018
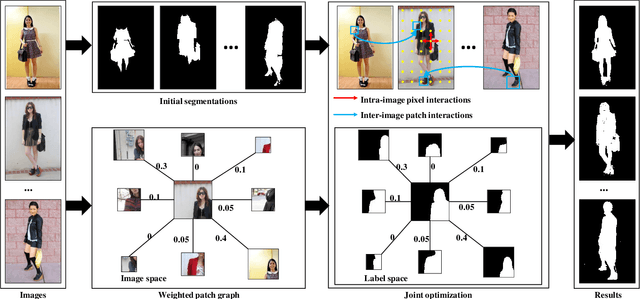


Image co-segmentation is a challenging task in computer vision that aims to segment all pixels of the objects from a predefined semantic category. In real-world cases, however, common foreground objects often vary greatly in appearance, making their global shapes highly inconsistent across images and difficult to be segmented. To address this problem, this paper proposes a novel co-segmentation approach that transfers patch-level local object shapes which appear more consistent across different images. In our framework, a multi-scale patch neighbourhood system is first generated using proposal flow on arbitrary image-pair, which is further refined by Locally Linear Embedding. Based on the patch relationships, we propose an efficient algorithm to jointly segment the objects in each image while transferring their local shapes across different images. Extensive experiments demonstrate that the proposed method can robustly and effectively segment common objects from an image set. On iCoseg, MSRC and Coseg-Rep dataset, the proposed approach performs comparable or better than the state-of-thearts, while on a more challenging benchmark Fashionista dataset, our method achieves significant improvements.