 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhichao Wang
An Improved Structured Mesh Generation Method Based on Physics-informed Neural Networks
Oct 18, 2022
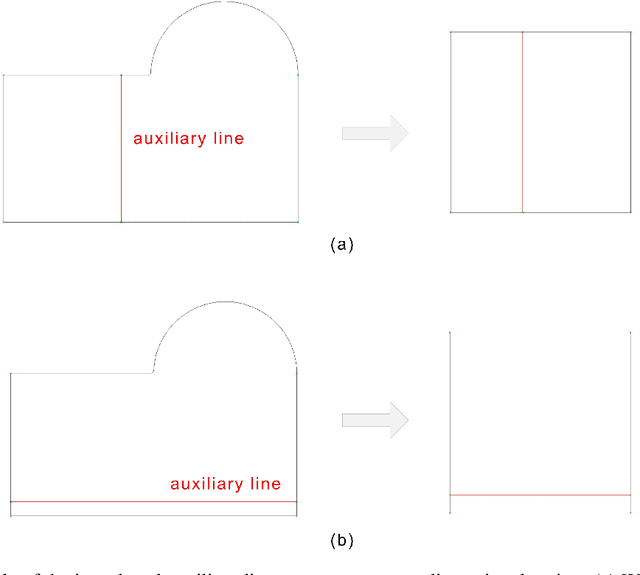
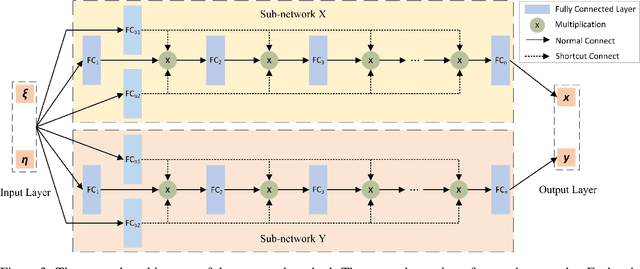
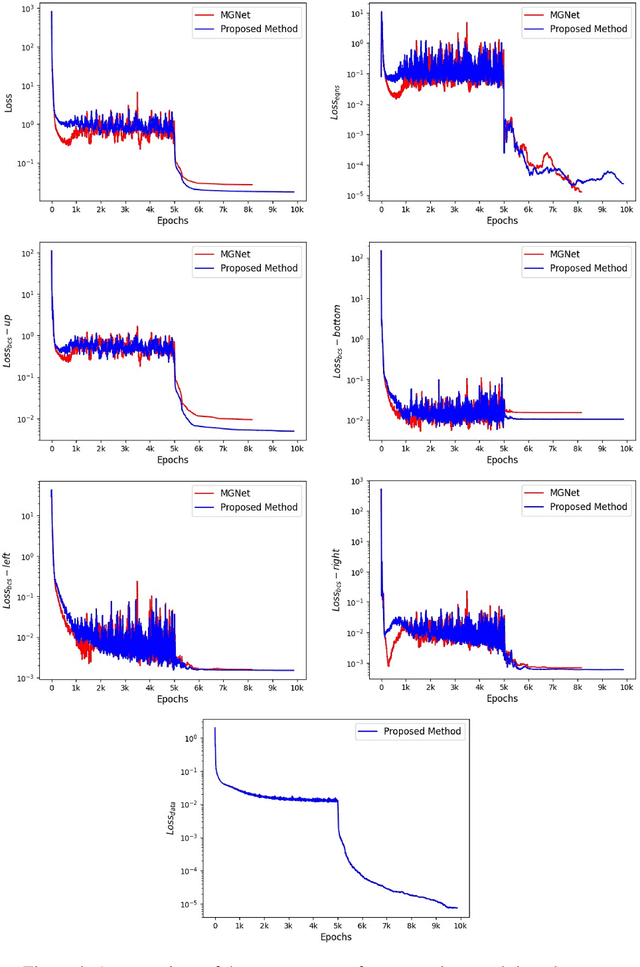
Mesh generation remains a key technology in many areas where numerical simulations are required. As numerical algorithms become more efficient and computers become more powerful, the percentage of time devoted to mesh generation becomes higher. In this paper, we present an improved structured mesh generation method. The method formulates the meshing problem as a global optimization problem related to a physics-informed neural network. The mesh is obtained by intelligently solving the physical boundary-constrained partial differential equations. To improve the prediction accuracy of the neural network, we also introduce a novel auxiliary line strategy and an efficient network model during meshing. The strategy first employs a priori auxiliary lines to provide ground truth data and then uses these data to construct a loss term to better constrain the convergence of the subsequent training. The experimental results indicate that the proposed method is effective and robust. It can accurately approximate the mapping (transformation) from the computational domain to the physical domain and enable fast high-quality structured mesh generation.
Cross-speaker Emotion Transfer Based On Prosody Compensation for End-to-End Speech Synthesis
Jul 04, 2022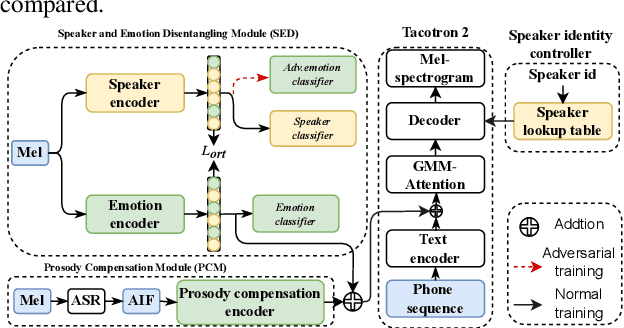
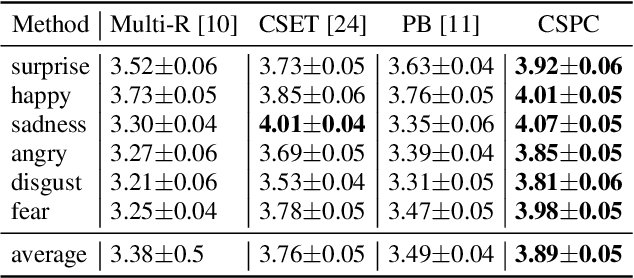
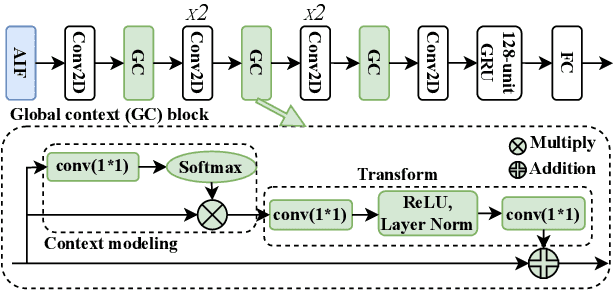
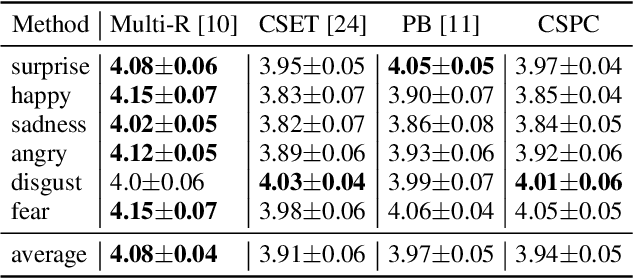
Cross-speaker emotion transfer speech synthesis aims to synthesize emotional speech for a target speaker by transferring the emotion from reference speech recorded by another (source) speaker. In this task, extracting speaker-independent emotion embedding from reference speech plays an important role. However, the emotional information conveyed by such emotion embedding tends to be weakened in the process to squeeze out the source speaker's timbre information. In response to this problem, a prosody compensation module (PCM) is proposed in this paper to compensate for the emotional information loss. Specifically, the PCM tries to obtain speaker-independent emotional information from the intermediate feature of a pre-trained ASR model. To this end, a prosody compensation encoder with global context (GC) blocks is introduced to obtain global emotional information from the ASR model's intermediate feature. Experiments demonstrate that the proposed PCM can effectively compensate the emotion embedding for the emotional information loss, and meanwhile maintain the timbre of the target speaker. Comparisons with state-of-the-art models show that our proposed method presents obvious superiority on the cross-speaker emotion transfer task.
TorchNTK: A Library for Calculation of Neural Tangent Kernels of PyTorch Models
May 24, 2022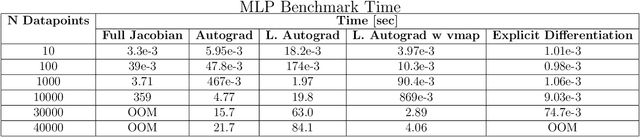
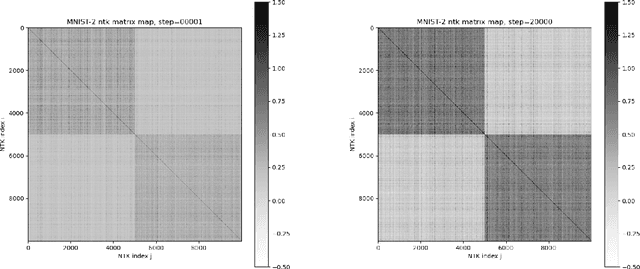
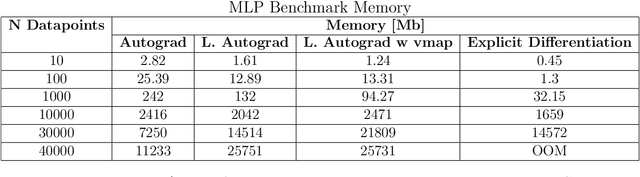
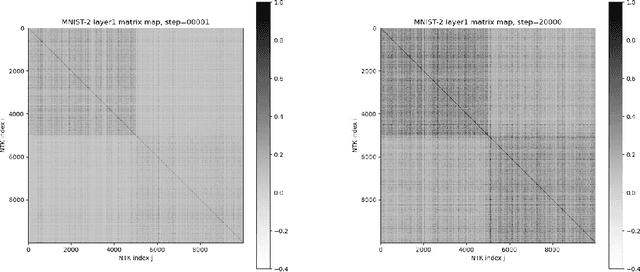
We introduce torchNTK, a python library to calculate the empirical neural tangent kernel (NTK) of neural network models in the PyTorch framework. We provide an efficient method to calculate the NTK of multilayer perceptrons. We compare the explicit differentiation implementation against autodifferentiation implementations, which have the benefit of extending the utility of the library to any architecture supported by PyTorch, such as convolutional networks. A feature of the library is that we expose the user to layerwise NTK components, and show that in some regimes a layerwise calculation is more memory efficient. We conduct preliminary experiments to demonstrate use cases for the software and probe the NTK.
High-dimensional Asymptotics of Feature Learning: How One Gradient Step Improves the Representation
May 03, 2022
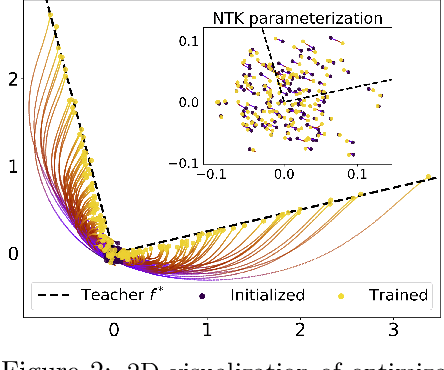
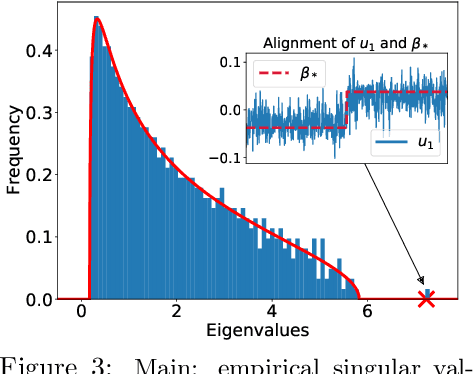
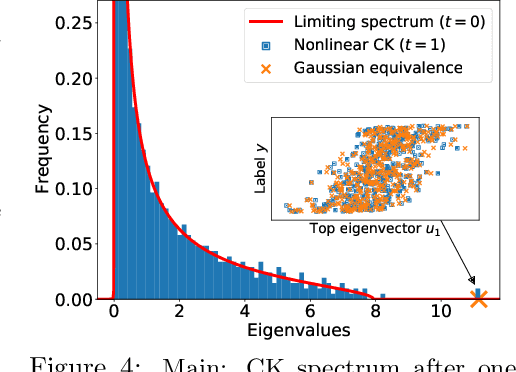
We study the first gradient descent step on the first-layer parameters $\boldsymbol{W}$ in a two-layer neural network: $f(\boldsymbol{x}) = \frac{1}{\sqrt{N}}\boldsymbol{a}^\top\sigma(\boldsymbol{W}^\top\boldsymbol{x})$, where $\boldsymbol{W}\in\mathbb{R}^{d\times N}, \boldsymbol{a}\in\mathbb{R}^{N}$ are randomly initialized, and the training objective is the empirical MSE loss: $\frac{1}{n}\sum_{i=1}^n (f(\boldsymbol{x}_i)-y_i)^2$. In the proportional asymptotic limit where $n,d,N\to\infty$ at the same rate, and an idealized student-teacher setting, we show that the first gradient update contains a rank-1 "spike", which results in an alignment between the first-layer weights and the linear component of the teacher model $f^*$. To characterize the impact of this alignment, we compute the prediction risk of ridge regression on the conjugate kernel after one gradient step on $\boldsymbol{W}$ with learning rate $\eta$, when $f^*$ is a single-index model. We consider two scalings of the first step learning rate $\eta$. For small $\eta$, we establish a Gaussian equivalence property for the trained feature map, and prove that the learned kernel improves upon the initial random features model, but cannot defeat the best linear model on the input. Whereas for sufficiently large $\eta$, we prove that for certain $f^*$, the same ridge estimator on trained features can go beyond this "linear regime" and outperform a wide range of random features and rotationally invariant kernels. Our results demonstrate that even one gradient step can lead to a considerable advantage over random features, and highlight the role of learning rate scaling in the initial phase of training.
Causal Disentanglement for Semantics-Aware Intent Learning in Recommendation
Feb 05, 2022

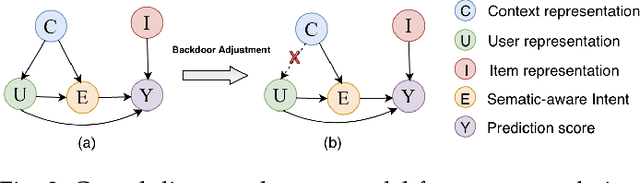
Traditional recommendation models trained on observational interaction data have generated large impacts in a wide range of applications, it faces bias problems that cover users' true intent and thus deteriorate the recommendation effectiveness. Existing methods tracks this problem as eliminating bias for the robust recommendation, e.g., by re-weighting training samples or learning disentangled representation. The disentangled representation methods as the state-of-the-art eliminate bias through revealing cause-effect of the bias generation. However, how to design the semantics-aware and unbiased representation for users true intents is largely unexplored. To bridge the gap, we are the first to propose an unbiased and semantics-aware disentanglement learning called CaDSI (Causal Disentanglement for Semantics-Aware Intent Learning) from a causal perspective. Particularly, CaDSI explicitly models the causal relations underlying recommendation task, and thus produces semantics-aware representations via disentangling users true intents aware of specific item context. Moreover, the causal intervention mechanism is designed to eliminate confounding bias stemmed from context information, which further to align the semantics-aware representation with users true intent. Extensive experiments and case studies both validate the robustness and interpretability of our proposed model.
IQDUBBING: Prosody modeling based on discrete self-supervised speech representation for expressive voice conversion
Jan 02, 2022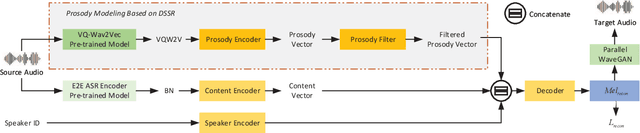
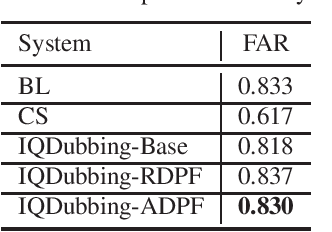
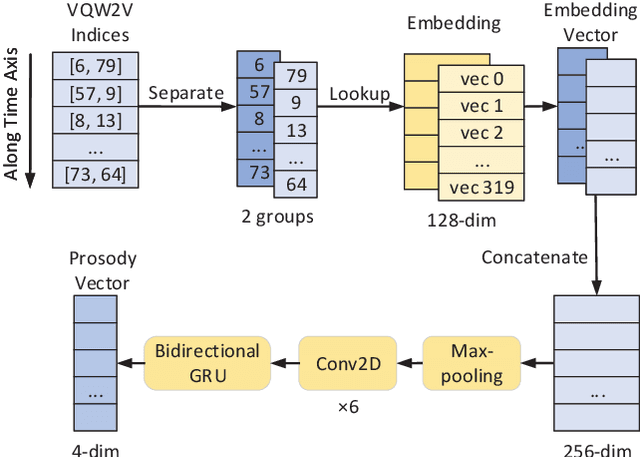
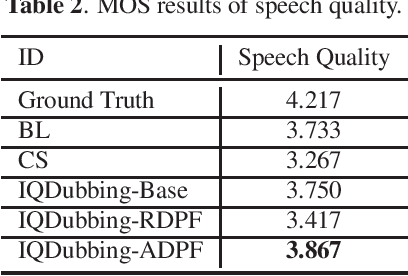
Prosody modeling is important, but still challenging in expressive voice conversion. As prosody is difficult to model, and other factors, e.g., speaker, environment and content, which are entangled with prosody in speech, should be removed in prosody modeling. In this paper, we present IQDubbing to solve this problem for expressive voice conversion. To model prosody, we leverage the recent advances in discrete self-supervised speech representation (DSSR). Specifically, prosody vector is first extracted from pre-trained VQ-Wav2Vec model, where rich prosody information is embedded while most speaker and environment information are removed effectively by quantization. To further filter out the redundant information except prosody, such as content and partial speaker information, we propose two kinds of prosody filters to sample prosody from the prosody vector. Experiments show that IQDubbing is superior to baseline and comparison systems in terms of speech quality while maintaining prosody consistency and speaker similarity.
Deep Treatment-Adaptive Network for Causal Inference
Dec 27, 2021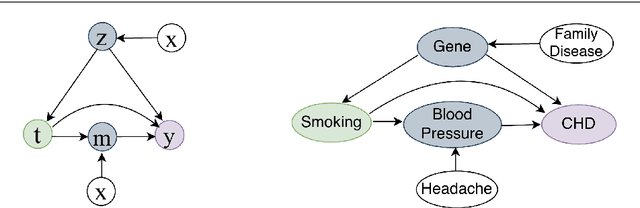
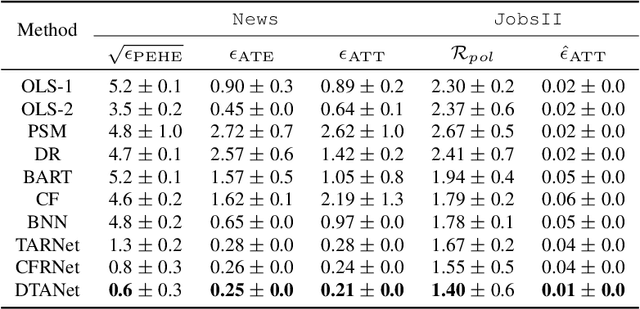
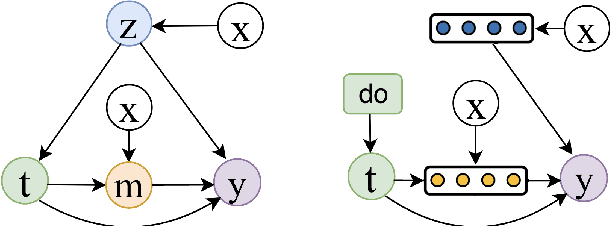
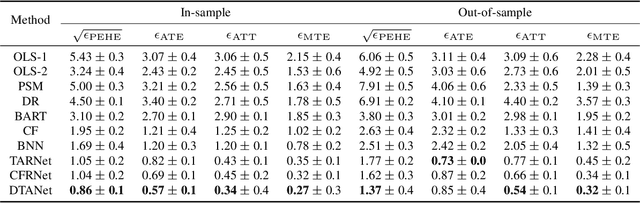
Causal inference is capable of estimating the treatment effect (i.e., the causal effect of treatment on the outcome) to benefit the decision making in various domains. One fundamental challenge in this research is that the treatment assignment bias in observational data. To increase the validity of observational studies on causal inference, representation based methods as the state-of-the-art have demonstrated the superior performance of treatment effect estimation. Most representation based methods assume all observed covariates are pre-treatment (i.e., not affected by the treatment), and learn a balanced representation from these observed covariates for estimating treatment effect. Unfortunately, this assumption is often too strict a requirement in practice, as some covariates are changed by doing an intervention on treatment (i.e., post-treatment). By contrast, the balanced representation learned from unchanged covariates thus biases the treatment effect estimation.
Multi-speaker Multi-style Text-to-speech Synthesis With Single-speaker Single-style Training Data Scenarios
Dec 23, 2021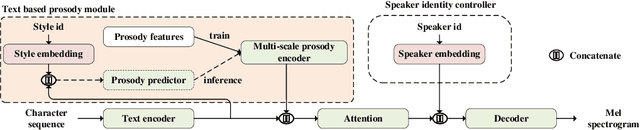
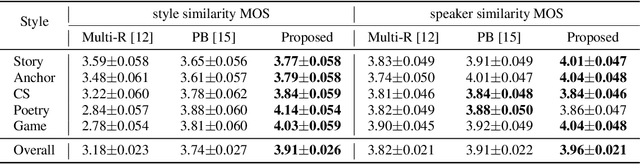
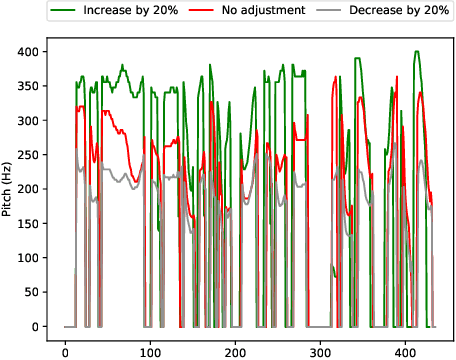
In the existing cross-speaker style transfer task, a source speaker with multi-style recordings is necessary to provide the style for a target speaker. However, it is hard for one speaker to express all expected styles. In this paper, a more general task, which is to produce expressive speech by combining any styles and timbres from a multi-speaker corpus in which each speaker has a unique style, is proposed. To realize this task, a novel method is proposed. This method is a Tacotron2-based framework but with a fine-grained text-based prosody predicting module and a speaker identity controller. Experiments demonstrate that the proposed method can successfully express a style of one speaker with the timber of another speaker bypassing the dependency on a single speaker's multi-style corpus. Moreover, the explicit prosody features used in the prosody predicting module can increase the diversity of synthetic speech by adjusting the value of prosody features.
One-shot Voice Conversion For Style Transfer Based On Speaker Adaptation
Nov 24, 2021One-shot style transfer is a challenging task, since training on one utterance makes model extremely easy to over-fit to training data and causes low speaker similarity and lack of expressiveness. In this paper, we build on the recognition-synthesis framework and propose a one-shot voice conversion approach for style transfer based on speaker adaptation. First, a speaker normalization module is adopted to remove speaker-related information in bottleneck features extracted by ASR. Second, we adopt weight regularization in the adaptation process to prevent over-fitting caused by using only one utterance from target speaker as training data. Finally, to comprehensively decouple the speech factors, i.e., content, speaker, style, and transfer source style to the target, a prosody module is used to extract prosody representation. Experiments show that our approach is superior to the state-of-the-art one-shot VC systems in terms of style and speaker similarity; additionally, our approach also maintains good speech quality.
Deformed semicircle law and concentration of nonlinear random matrices for ultra-wide neural networks
Sep 20, 2021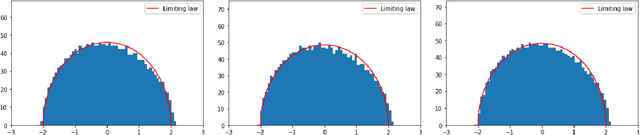
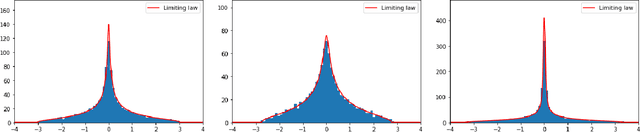
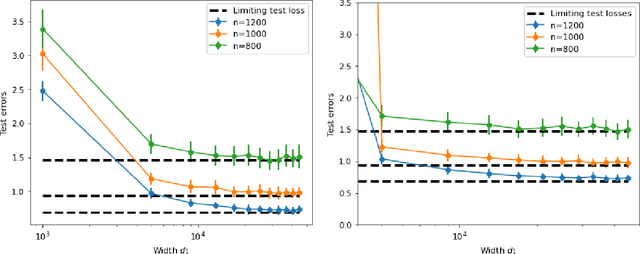
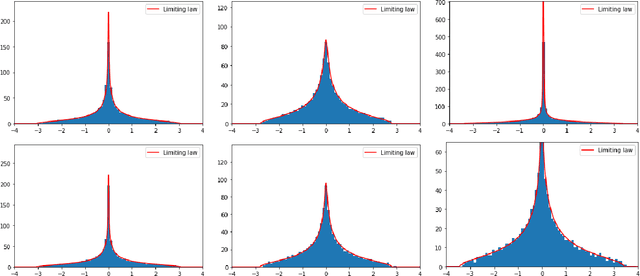
In this paper, we study the two-layer fully connected neural network given by $f(X)=\frac{1}{\sqrt{d_1}}\boldsymbol{a}^\top\sigma\left(WX\right)$, where $X\in\mathbb{R}^{d_0\times n}$ is a deterministic data matrix, $W\in\mathbb{R}^{d_1\times d_0}$ and $\boldsymbol{a}\in\mathbb{R}^{d_1}$ are random Gaussian weights, and $\sigma$ is a nonlinear activation function. We obtain the limiting spectral distributions of two kernel matrices related to $f(X)$: the empirical conjugate kernel (CK) and neural tangent kernel (NTK), beyond the linear-width regime ($d_1\asymp n$). Under the ultra-width regime $d_1/n\to\infty$, with proper assumptions on $X$ and $\sigma$, a deformed semicircle law appears. Such limiting law is first proved for general centered sample covariance matrices with correlation and then specified for our neural network model. We also prove non-asymptotic concentrations of empirical CK and NTK around their limiting kernel in the spectral norm, and lower bounds on their smallest eigenvalues. As an application, we verify the random feature regression achieves the same asymptotic performance as its limiting kernel regression in ultra-width limit. The limiting training and test errors for random feature regression are calculated by corresponding kernel regression. We also provide a nonlinear Hanson-Wright inequality suitable for neural networks with random weights and Lipschitz activation functions.