 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZheng Zhang
Learning Hierarchical Graph Neural Networks for Image Clustering
Jul 17, 2021
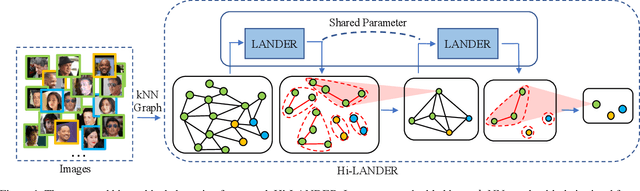
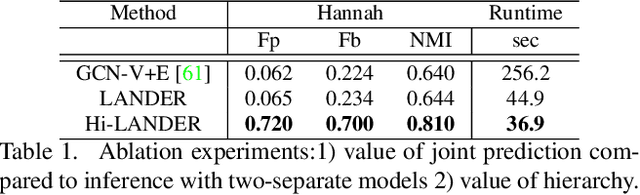
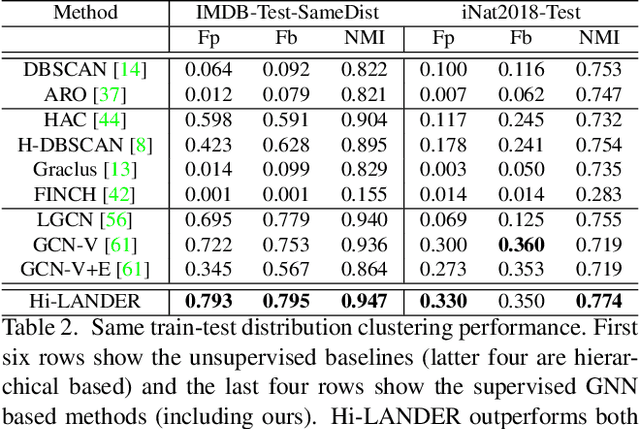
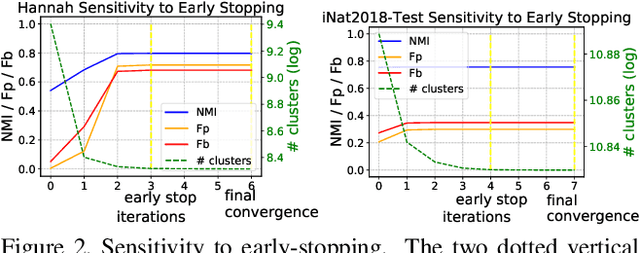
We propose a hierarchical graph neural network (GNN) model that learns how to cluster a set of images into an unknown number of identities using a training set of images annotated with labels belonging to a disjoint set of identities. Our hierarchical GNN uses a novel approach to merge connected components predicted at each level of the hierarchy to form a new graph at the next level. Unlike fully unsupervised hierarchical clustering, the choice of grouping and complexity criteria stems naturally from supervision in the training set. The resulting method, Hi-LANDER, achieves an average of 54% improvement in F-score and 8% increase in Normalized Mutual Information (NMI) relative to current GNN-based clustering algorithms. Additionally, state-of-the-art GNN-based methods rely on separate models to predict linkage probabilities and node densities as intermediate steps of the clustering process. In contrast, our unified framework achieves a seven-fold decrease in computational cost. We release our training and inference code at https://github.com/dmlc/dgl/tree/master/examples/pytorch/hilander.
TransAttUnet: Multi-level Attention-guided U-Net with Transformer for Medical Image Segmentation
Jul 12, 2021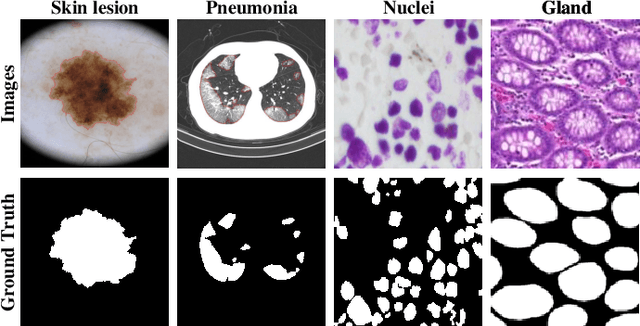
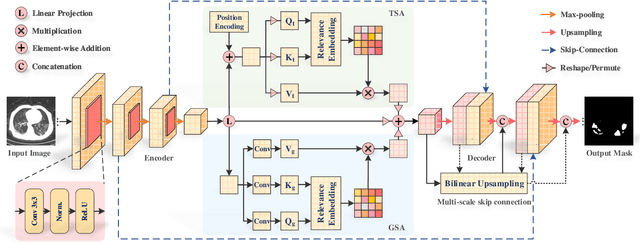
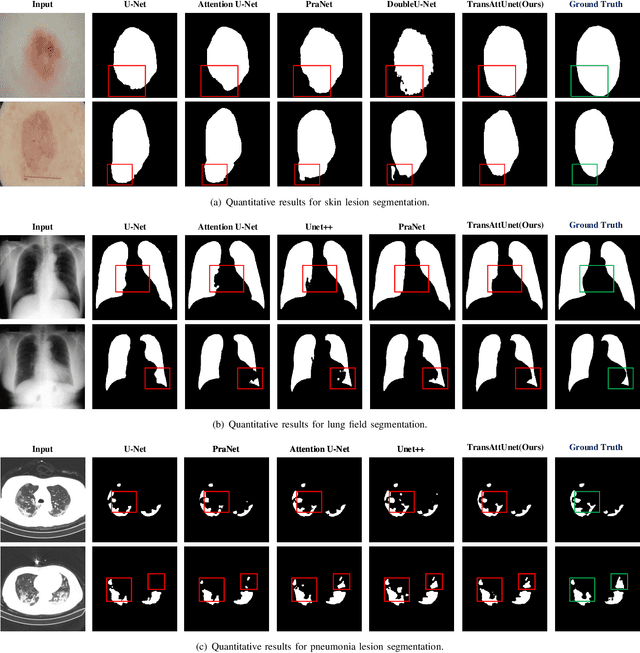
With the development of deep encoder-decoder architectures and large-scale annotated medical datasets, great progress has been achieved in the development of automatic medical image segmentation. Due to the stacking of convolution layers and the consecutive sampling operations, existing standard models inevitably encounter the information recession problem of feature representations, which fails to fully model the global contextual feature dependencies. To overcome the above challenges, this paper proposes a novel Transformer based medical image semantic segmentation framework called TransAttUnet, in which the multi-level guided attention and multi-scale skip connection are jointly designed to effectively enhance the functionality and flexibility of traditional U-shaped architecture. Inspired by Transformer, a novel self-aware attention (SAA) module with both Transformer Self Attention (TSA) and Global Spatial Attention (GSA) is incorporated into TransAttUnet to effectively learn the non-local interactions between encoder features. In particular, we also establish additional multi-scale skip connections between decoder blocks to aggregate the different semantic-scale upsampling features. In this way, the representation ability of multi-scale context information is strengthened to generate discriminative features. Benefitting from these complementary components, the proposed TransAttUnet can effectively alleviate the loss of fine details caused by the information recession problem, improving the diagnostic sensitivity and segmentation quality of medical image analysis. Extensive experiments on multiple medical image segmentation datasets of different imaging demonstrate that our method consistently outperforms the state-of-the-art baselines.
Context-Aware Attention-Based Data Augmentation for POI Recommendation
Jun 30, 2021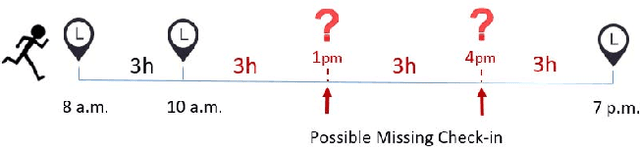
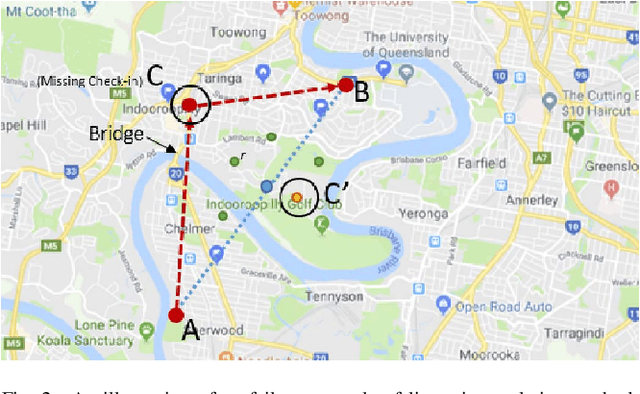
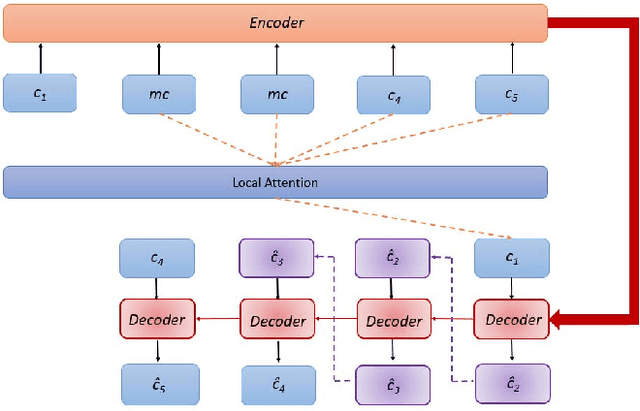
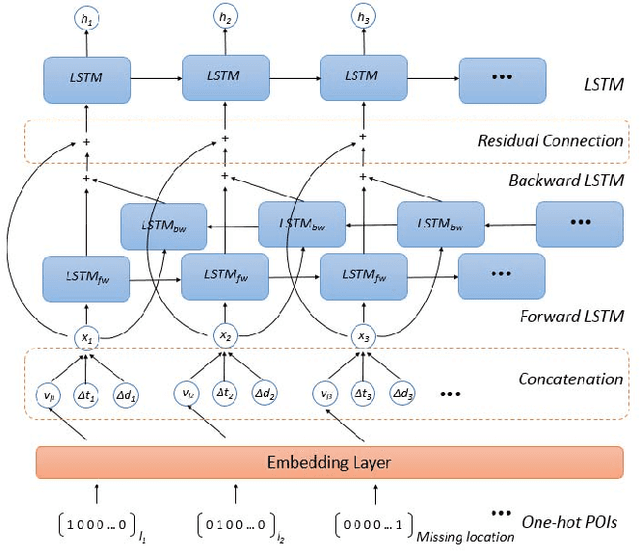
With the rapid growth of location-based social networks (LBSNs), Point-Of-Interest (POI) recommendation has been broadly studied in this decade. Recently, the next POI recommendation, a natural extension of POI recommendation, has attracted much attention. It aims at suggesting the next POI to a user in spatial and temporal context, which is a practical yet challenging task in various applications. Existing approaches mainly model the spatial and temporal information, and memorize historical patterns through user's trajectories for recommendation. However, they suffer from the negative impact of missing and irregular check-in data, which significantly influences the model performance. In this paper, we propose an attention-based sequence-to-sequence generative model, namely POI-Augmentation Seq2Seq (PA-Seq2Seq), to address the sparsity of training set by making check-in records to be evenly-spaced. Specifically, the encoder summarises each check-in sequence and the decoder predicts the possible missing check-ins based on the encoded information. In order to learn time-aware correlation among user history, we employ local attention mechanism to help the decoder focus on a specific range of context information when predicting a certain missing check-in point. Extensive experiments have been conducted on two real-world check-in datasets, Gowalla and Brightkite, for performance and effectiveness evaluation.
Video Swin Transformer
Jun 24, 2021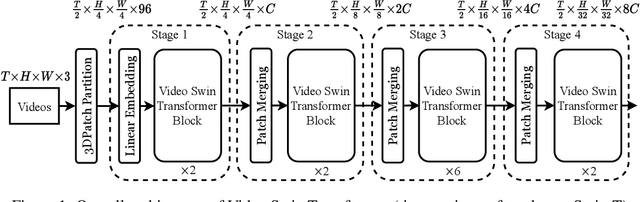
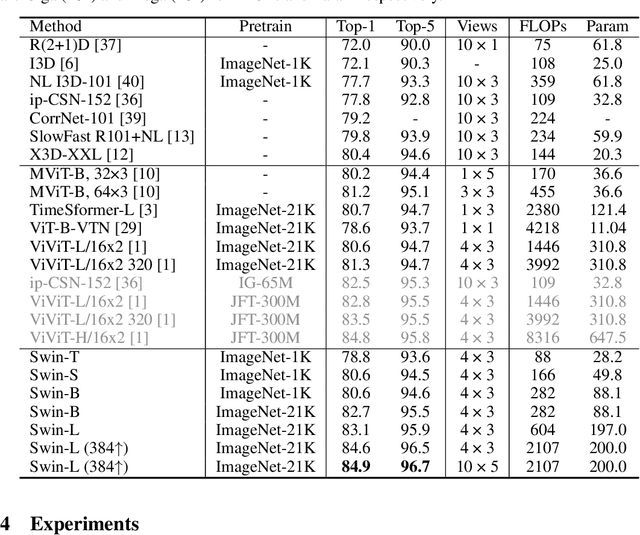
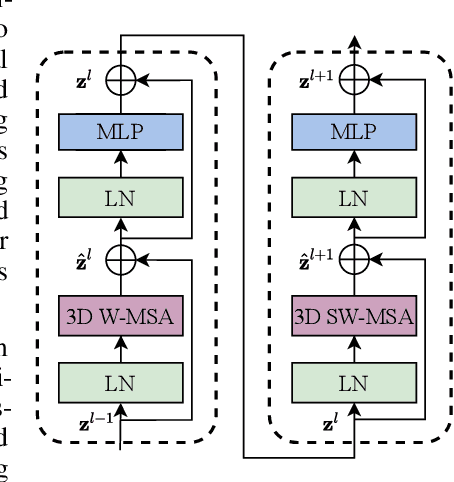
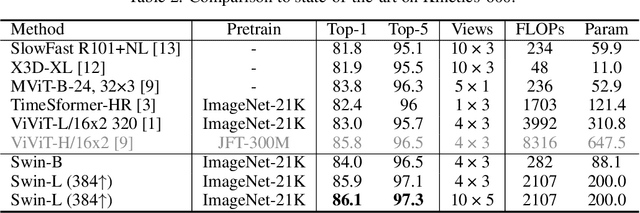
The vision community is witnessing a modeling shift from CNNs to Transformers, where pure Transformer architectures have attained top accuracy on the major video recognition benchmarks. These video models are all built on Transformer layers that globally connect patches across the spatial and temporal dimensions. In this paper, we instead advocate an inductive bias of locality in video Transformers, which leads to a better speed-accuracy trade-off compared to previous approaches which compute self-attention globally even with spatial-temporal factorization. The locality of the proposed video architecture is realized by adapting the Swin Transformer designed for the image domain, while continuing to leverage the power of pre-trained image models. Our approach achieves state-of-the-art accuracy on a broad range of video recognition benchmarks, including on action recognition (84.9 top-1 accuracy on Kinetics-400 and 86.1 top-1 accuracy on Kinetics-600 with ~20x less pre-training data and ~3x smaller model size) and temporal modeling (69.6 top-1 accuracy on Something-Something v2). The code and models will be made publicly available at https://github.com/SwinTransformer/Video-Swin-Transformer.
End-to-End Semi-Supervised Object Detection with Soft Teacher
Jun 17, 2021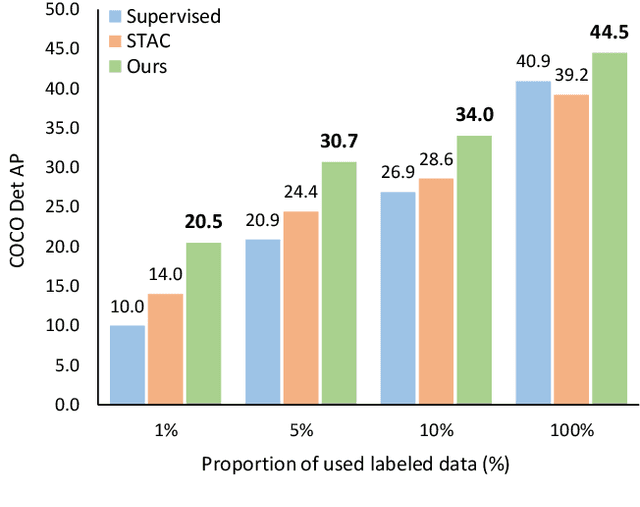
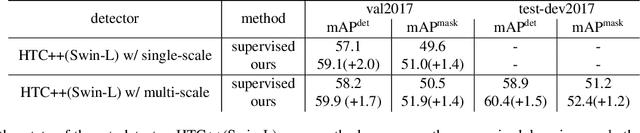
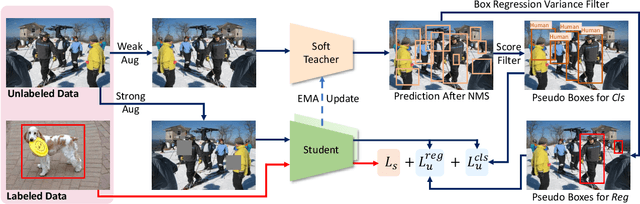
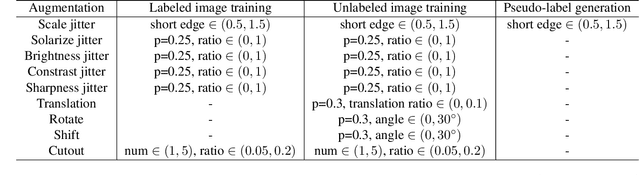
This paper presents an end-to-end semi-supervised object detection approach, in contrast to previous more complex multi-stage methods. The end-to-end training gradually improves pseudo label qualities during the curriculum, and the more and more accurate pseudo labels in turn benefit object detection training. We also propose two simple yet effective techniques within this framework: a soft teacher mechanism where the classification loss of each unlabeled bounding box is weighed by the classification score produced by the teacher network; a box jittering approach to select reliable pseudo boxes for the learning of box regression. On COCO benchmark, the proposed approach outperforms previous methods by a large margin under various labeling ratios, i.e. 1\%, 5\% and 10\%. Moreover, our approach proves to perform also well when the amount of labeled data is relatively large. For example, it can improve a 40.9 mAP baseline detector trained using the full COCO training set by +3.6 mAP, reaching 44.5 mAP, by leveraging the 123K unlabeled images of COCO. On the state-of-the-art Swin Transformer-based object detector (58.9 mAP on test-dev), it can still significantly improve the detection accuracy by +1.5 mAP, reaching 60.4 mAP, and improve the instance segmentation accuracy by +1.2 mAP, reaching 52.4 mAP, pushing the new state-of-the-art.
DS-TransUNet:Dual Swin Transformer U-Net for Medical Image Segmentation
Jun 12, 2021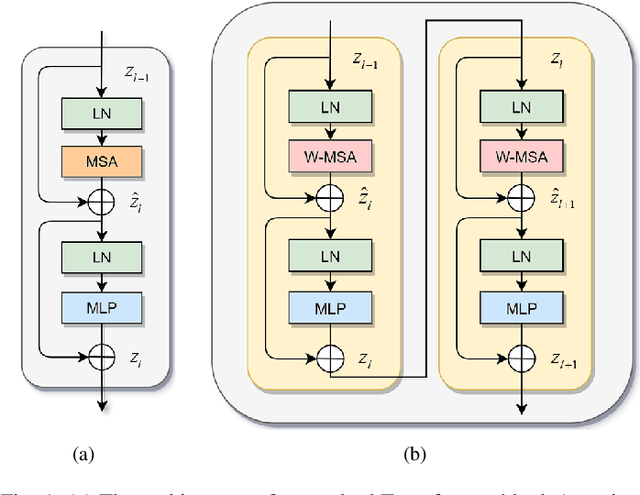
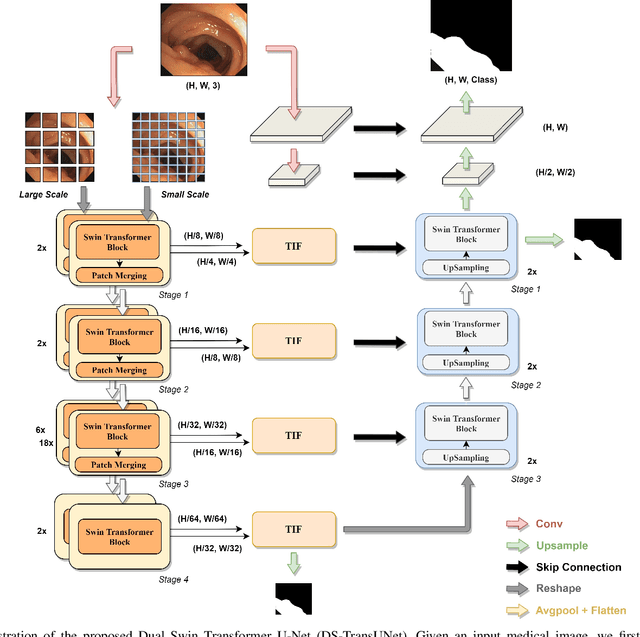
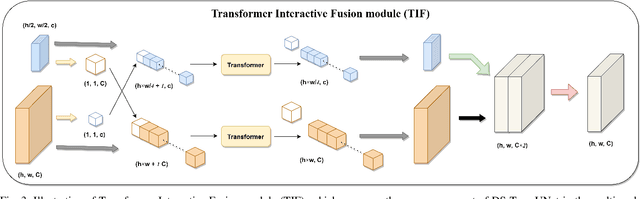

Automatic medical image segmentation has made great progress benefit from the development of deep learning. However, most existing methods are based on convolutional neural networks (CNNs), which fail to build long-range dependencies and global context connections due to the limitation of receptive field in convolution operation. Inspired by the success of Transformer in modeling the long-range contextual information, some researchers have expended considerable efforts in designing the robust variants of Transformer-based U-Net. Moreover, the patch division used in vision transformers usually ignores the pixel-level intrinsic structural features inside each patch. To alleviate these problems, we propose a novel deep medical image segmentation framework called Dual Swin Transformer U-Net (DS-TransUNet), which might be the first attempt to concurrently incorporate the advantages of hierarchical Swin Transformer into both encoder and decoder of the standard U-shaped architecture to enhance the semantic segmentation quality of varying medical images. Unlike many prior Transformer-based solutions, the proposed DS-TransUNet first adopts dual-scale encoder subnetworks based on Swin Transformer to extract the coarse and fine-grained feature representations of different semantic scales. As the core component for our DS-TransUNet, a well-designed Transformer Interactive Fusion (TIF) module is proposed to effectively establish global dependencies between features of different scales through the self-attention mechanism. Furthermore, we also introduce the Swin Transformer block into decoder to further explore the long-range contextual information during the up-sampling process. Extensive experiments across four typical tasks for medical image segmentation demonstrate the effectiveness of DS-TransUNet, and show that our approach significantly outperforms the state-of-the-art methods.
A Unified Generative Framework for Aspect-Based Sentiment Analysis
Jun 08, 2021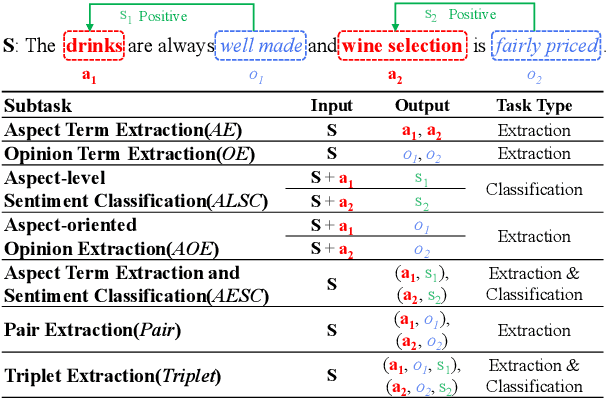
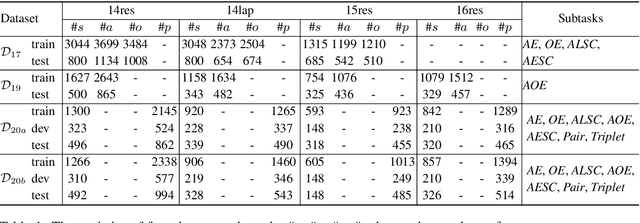
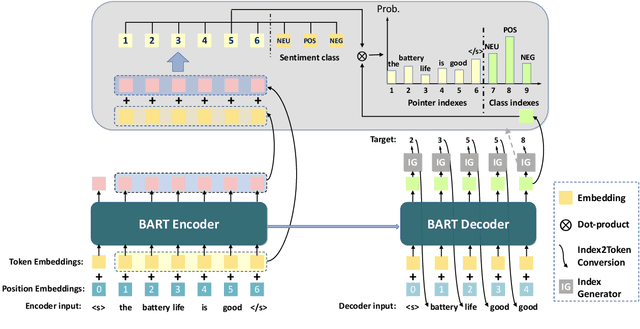
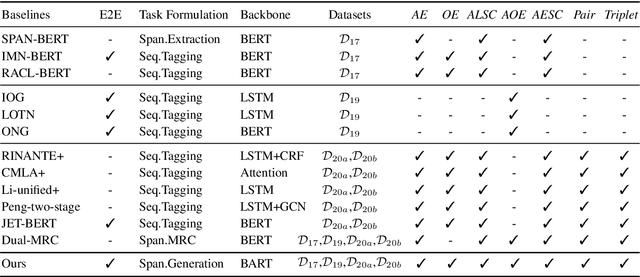
Aspect-based Sentiment Analysis (ABSA) aims to identify the aspect terms, their corresponding sentiment polarities, and the opinion terms. There exist seven subtasks in ABSA. Most studies only focus on the subsets of these subtasks, which leads to various complicated ABSA models while hard to solve these subtasks in a unified framework. In this paper, we redefine every subtask target as a sequence mixed by pointer indexes and sentiment class indexes, which converts all ABSA subtasks into a unified generative formulation. Based on the unified formulation, we exploit the pre-training sequence-to-sequence model BART to solve all ABSA subtasks in an end-to-end framework. Extensive experiments on four ABSA datasets for seven subtasks demonstrate that our framework achieves substantial performance gain and provides a real unified end-to-end solution for the whole ABSA subtasks, which could benefit multiple tasks.
A Unified Generative Framework for Various NER Subtasks
Jun 02, 2021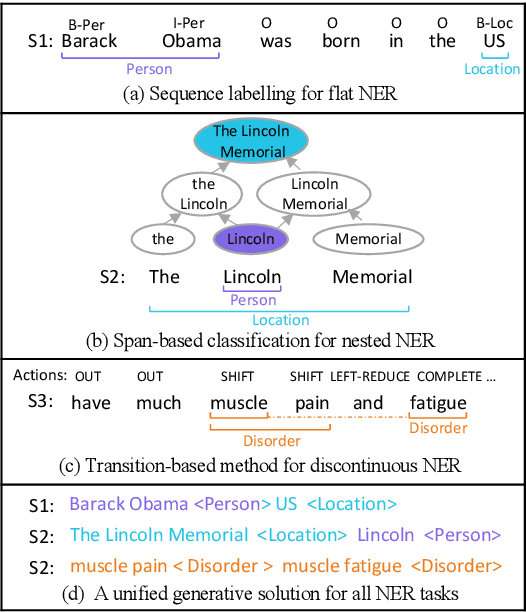
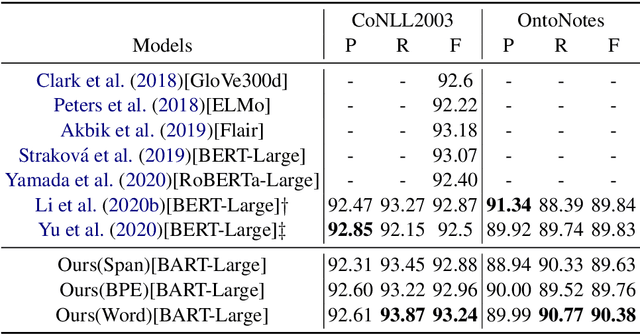
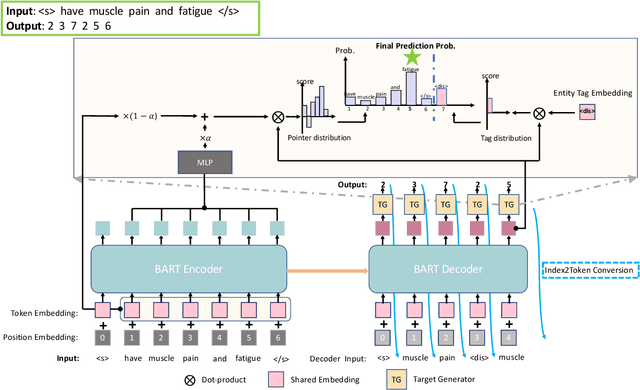
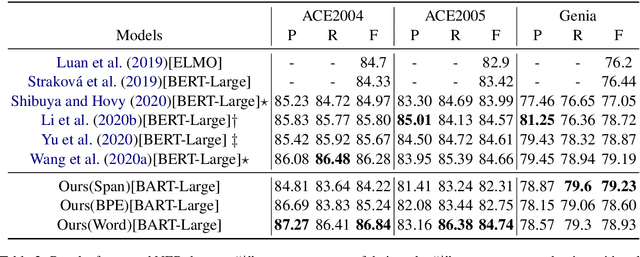
Named Entity Recognition (NER) is the task of identifying spans that represent entities in sentences. Whether the entity spans are nested or discontinuous, the NER task can be categorized into the flat NER, nested NER, and discontinuous NER subtasks. These subtasks have been mainly solved by the token-level sequence labelling or span-level classification. However, these solutions can hardly tackle the three kinds of NER subtasks concurrently. To that end, we propose to formulate the NER subtasks as an entity span sequence generation task, which can be solved by a unified sequence-to-sequence (Seq2Seq) framework. Based on our unified framework, we can leverage the pre-trained Seq2Seq model to solve all three kinds of NER subtasks without the special design of the tagging schema or ways to enumerate spans. We exploit three types of entity representations to linearize entities into a sequence. Our proposed framework is easy-to-implement and achieves state-of-the-art (SoTA) or near SoTA performance on eight English NER datasets, including two flat NER datasets, three nested NER datasets, and three discontinuous NER datasets.