 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZheng Zhang
Self-Healing Robust Neural Networks via Closed-Loop Control
Jun 26, 2022
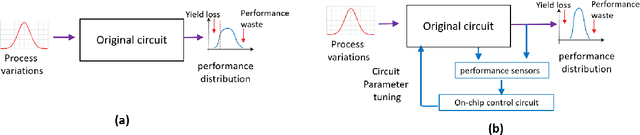

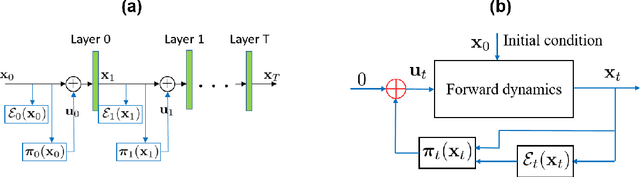
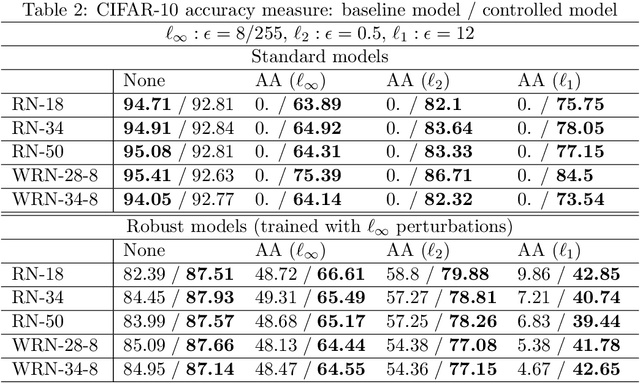
Despite the wide applications of neural networks, there have been increasing concerns about their vulnerability issue. While numerous attack and defense techniques have been developed, this work investigates the robustness issue from a new angle: can we design a self-healing neural network that can automatically detect and fix the vulnerability issue by itself? A typical self-healing mechanism is the immune system of a human body. This biology-inspired idea has been used in many engineering designs but is rarely investigated in deep learning. This paper considers the post-training self-healing of a neural network, and proposes a closed-loop control formulation to automatically detect and fix the errors caused by various attacks or perturbations. We provide a margin-based analysis to explain how this formulation can improve the robustness of a classifier. To speed up the inference of the proposed self-healing network, we solve the control problem via improving the Pontryagin Maximum Principle-based solver. Lastly, we present an error estimation of the proposed framework for neural networks with nonlinear activation functions. We validate the performance on several network architectures against various perturbations. Since the self-healing method does not need a-priori information about data perturbations/attacks, it can handle a broad class of unforeseen perturbations.
Learning Enhanced Representations for Tabular Data via Neighborhood Propagation
Jun 14, 2022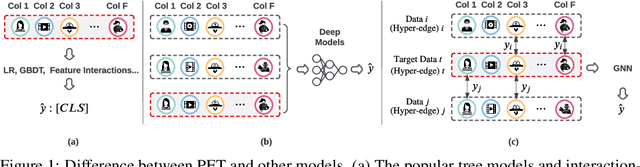
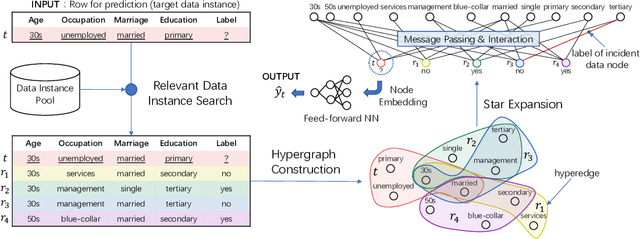
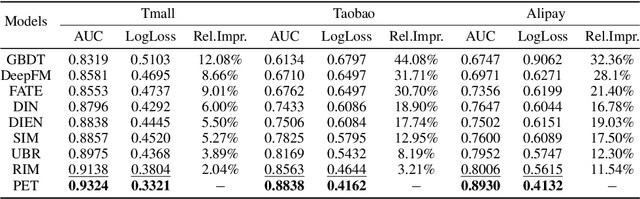
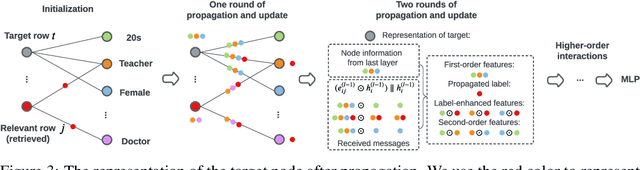
Prediction over tabular data is an essential and fundamental problem in many important downstream tasks. However, existing methods either take a data instance of the table independently as input or do not fully utilize the multi-rows features and labels to directly change and enhance the target data representations. In this paper, we propose to 1) construct a hypergraph from relevant data instance retrieval to model the cross-row and cross-column patterns of those instances, and 2) perform message Propagation to Enhance the target data instance representation for Tabular prediction tasks. Specifically, our specially-designed message propagation step benefits from 1) fusion of label and features during propagation, and 2) locality-aware high-order feature interactions. Experiments on two important tabular data prediction tasks validate the superiority of the proposed PET model against other baselines. Additionally, we demonstrate the effectiveness of the model components and the feature enhancement ability of PET via various ablation studies and visualizations. The code is included in https://github.com/KounianhuaDu/PET.
On Data Scaling in Masked Image Modeling
Jun 09, 2022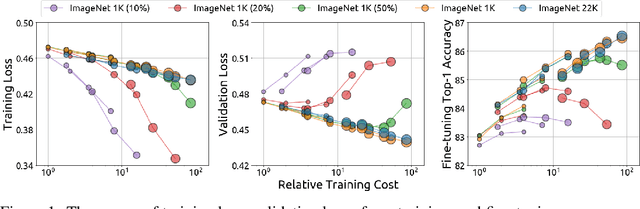


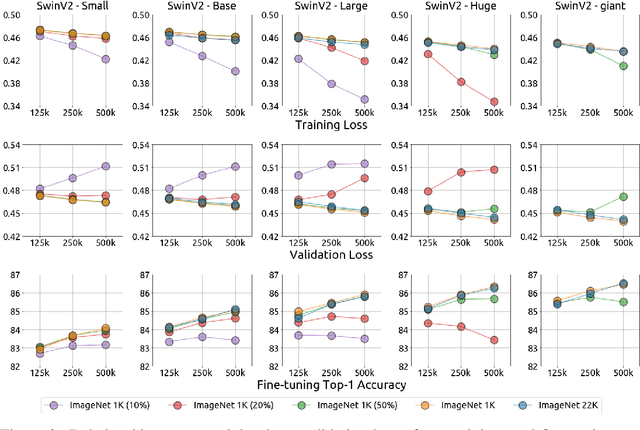
An important goal of self-supervised learning is to enable model pre-training to benefit from almost unlimited data. However, one method that has recently become popular, namely masked image modeling (MIM), is suspected to be unable to benefit from larger data. In this work, we break this misconception through extensive experiments, with data scales ranging from 10\% of ImageNet-1K to full ImageNet-22K, model sizes ranging from 49 million to 1 billion, and training lengths ranging from 125K iterations to 500K iterations. Our study reveals that: (i) Masked image modeling is also demanding on larger data. We observed that very large models got over-fitted with relatively small data; (ii) The length of training matters. Large models trained with masked image modeling can benefit from more data with longer training; (iii) The validation loss in pre-training is a good indicator to measure how well the model performs for fine-tuning on multiple tasks. This observation allows us to pre-evaluate pre-trained models in advance without having to make costly trial-and-error assessments of downstream tasks. We hope that our findings will advance the understanding of masked image modeling in terms of scaling ability.
Predicting Electricity Infrastructure Induced Wildfire Risk in California
Jun 06, 2022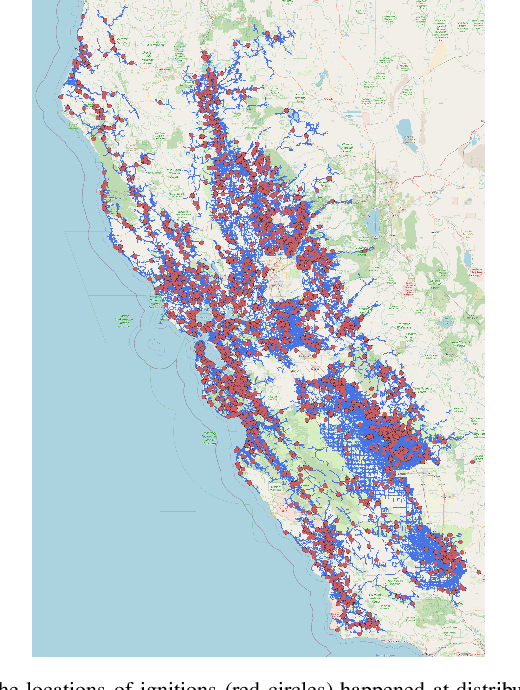
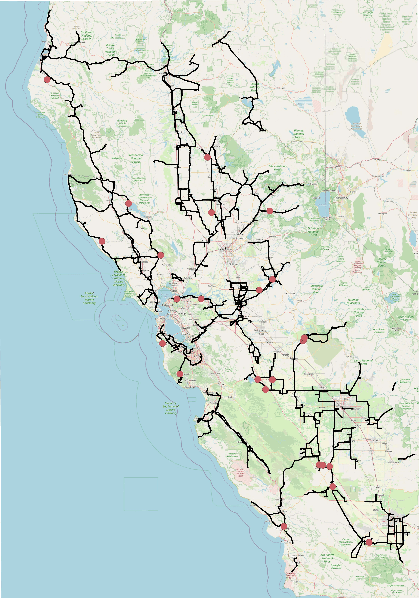
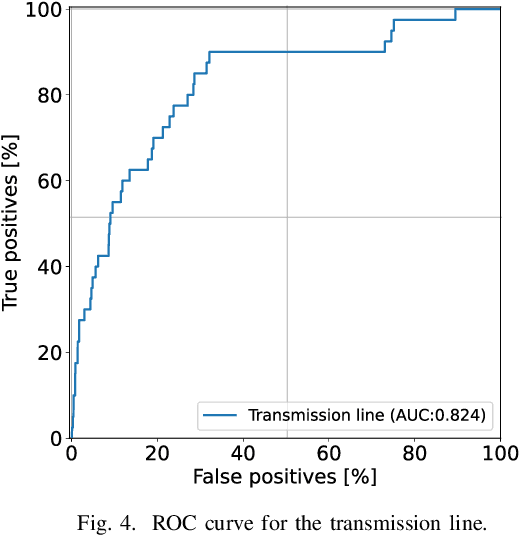
This paper examines the use of risk models to predict the timing and location of wildfires caused by electricity infrastructure. Our data include historical ignition and wire-down points triggered by grid infrastructure collected between 2015 to 2019 in Pacific Gas & Electricity territory along with various weather, vegetation, and very high resolution data on grid infrastructure including location, age, materials. With these data we explore a range of machine learning methods and strategies to manage training data imbalance. The best area under the receiver operating characteristic we obtain is 0.776 for distribution feeder ignitions and 0.824 for transmission line wire-down events, both using the histogram-based gradient boosting tree algorithm (HGB) with under-sampling. We then use these models to identify which information provides the most predictive value. After line length, we find that weather and vegetation features dominate the list of top important features for ignition or wire-down risk. Distribution ignition models show more dependence on slow-varying vegetation variables such as burn index, energy release content, and tree height, whereas transmission wire-down models rely more on primary weather variables such as wind speed and precipitation. These results point to the importance of improved vegetation modeling for feeder ignition risk models, and improved weather forecasting for transmission wire-down models. We observe that infrastructure features make small but meaningful improvements to risk model predictive power.
Contrastive Learning Rivals Masked Image Modeling in Fine-tuning via Feature Distillation
May 27, 2022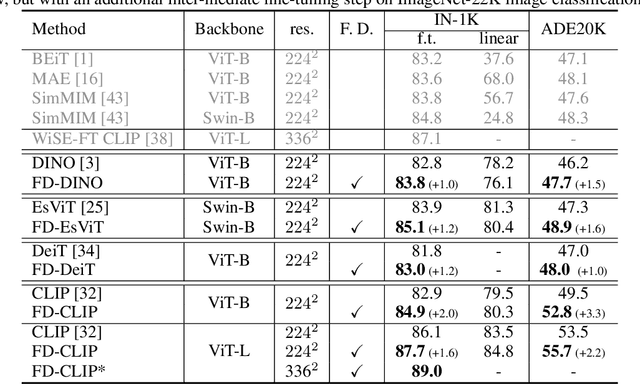
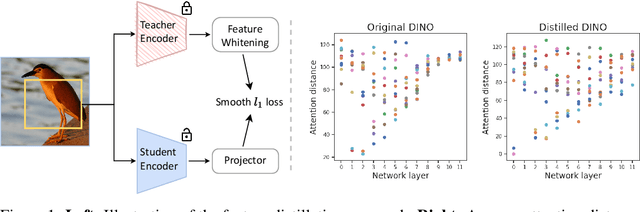
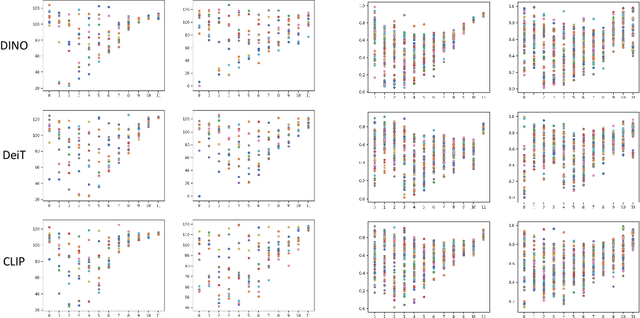
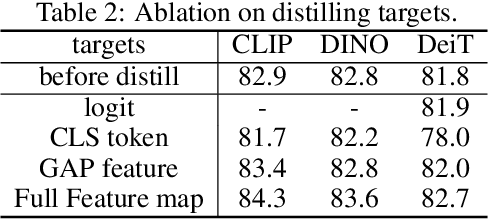
Masked image modeling (MIM) learns representations with remarkably good fine-tuning performances, overshadowing previous prevalent pre-training approaches such as image classification, instance contrastive learning, and image-text alignment. In this paper, we show that the inferior fine-tuning performance of these pre-training approaches can be significantly improved by a simple post-processing in the form of feature distillation (FD). The feature distillation converts the old representations to new representations that have a few desirable properties just like those representations produced by MIM. These properties, which we aggregately refer to as optimization friendliness, are identified and analyzed by a set of attention- and optimization-related diagnosis tools. With these properties, the new representations show strong fine-tuning performance. Specifically, the contrastive self-supervised learning methods are made as competitive in fine-tuning as the state-of-the-art masked image modeling (MIM) algorithms. The CLIP models' fine-tuning performance is also significantly improved, with a CLIP ViT-L model reaching 89.0% top-1 accuracy on ImageNet-1K classification. More importantly, our work provides a way for the future research to focus more effort on the generality and scalability of the learnt representations without being pre-occupied with optimization friendliness since it can be enhanced rather easily. The code will be available at https://github.com/SwinTransformer/Feature-Distillation.
Revealing the Dark Secrets of Masked Image Modeling
May 27, 2022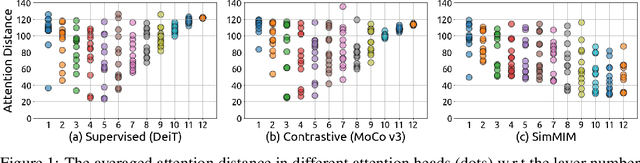

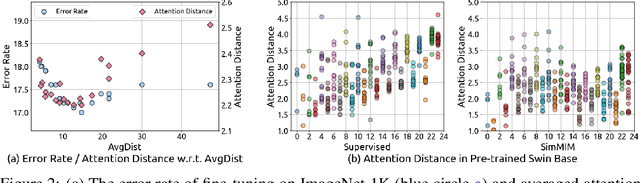
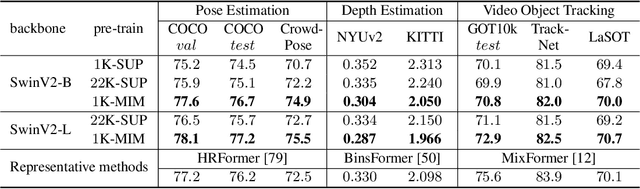
Masked image modeling (MIM) as pre-training is shown to be effective for numerous vision downstream tasks, but how and where MIM works remain unclear. In this paper, we compare MIM with the long-dominant supervised pre-trained models from two perspectives, the visualizations and the experiments, to uncover their key representational differences. From the visualizations, we find that MIM brings locality inductive bias to all layers of the trained models, but supervised models tend to focus locally at lower layers but more globally at higher layers. That may be the reason why MIM helps Vision Transformers that have a very large receptive field to optimize. Using MIM, the model can maintain a large diversity on attention heads in all layers. But for supervised models, the diversity on attention heads almost disappears from the last three layers and less diversity harms the fine-tuning performance. From the experiments, we find that MIM models can perform significantly better on geometric and motion tasks with weak semantics or fine-grained classification tasks, than their supervised counterparts. Without bells and whistles, a standard MIM pre-trained SwinV2-L could achieve state-of-the-art performance on pose estimation (78.9 AP on COCO test-dev and 78.0 AP on CrowdPose), depth estimation (0.287 RMSE on NYUv2 and 1.966 RMSE on KITTI), and video object tracking (70.7 SUC on LaSOT). For the semantic understanding datasets where the categories are sufficiently covered by the supervised pre-training, MIM models can still achieve highly competitive transfer performance. With a deeper understanding of MIM, we hope that our work can inspire new and solid research in this direction.
Tensor Shape Search for Optimum Data Compression
May 21, 2022
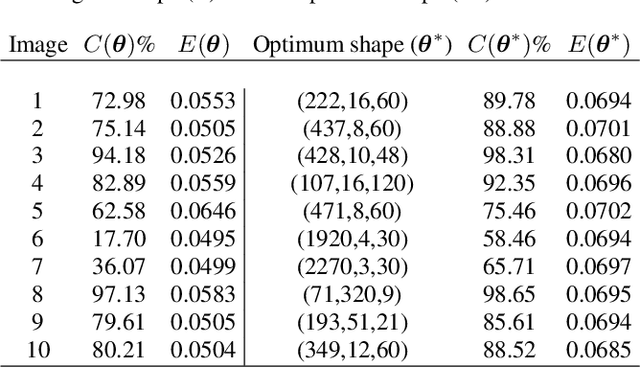
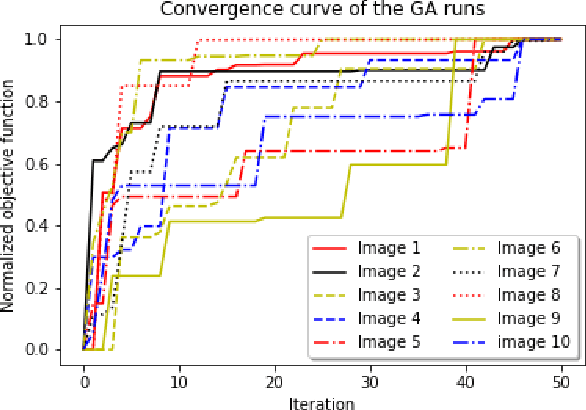
Various tensor decomposition methods have been proposed for data compression. In real world applications of the tensor decomposition, selecting the tensor shape for the given data poses a challenge and the shape of the tensor may affect the error and the compression ratio. In this work, we study the effect of the tensor shape on the tensor decomposition and propose an optimization model to find an optimum shape for the tensor train (TT) decomposition. The proposed optimization model maximizes the compression ratio of the TT decomposition given an error bound. We implement a genetic algorithm (GA) linked with the TT-SVD algorithm to solve the optimization model. We apply the proposed method for the compression of RGB images. The results demonstrate the effectiveness of the proposed evolutionary tensor shape search for the TT decomposition.
Heterogeneous Information Network based Default Analysis on Banking Micro and Small Enterprise Users
May 02, 2022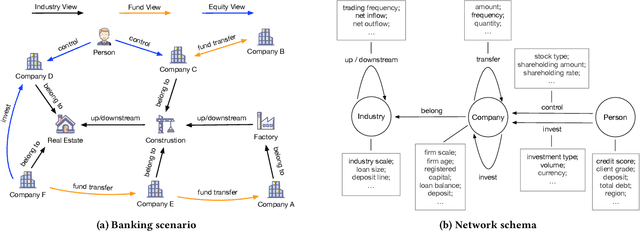
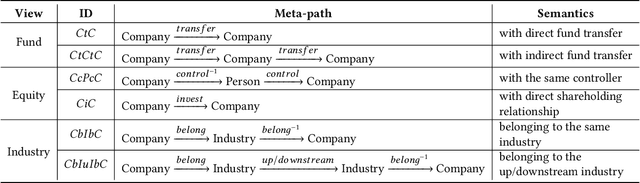
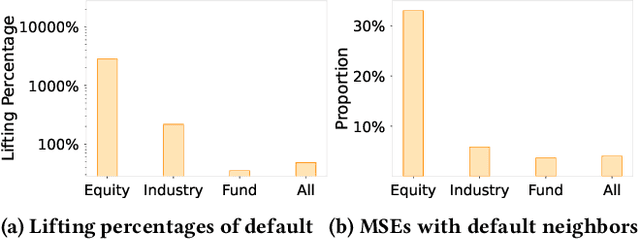

Risk assessment is a substantial problem for financial institutions that has been extensively studied both for its methodological richness and its various practical applications. With the expansion of inclusive finance, recent attentions are paid to micro and small-sized enterprises (MSEs). Compared with large companies, MSEs present a higher exposure rate to default owing to their insecure financial stability. Conventional efforts learn classifiers from historical data with elaborate feature engineering. However, the main obstacle for MSEs involves severe deficiency in credit-related information, which may degrade the performance of prediction. Besides, financial activities have diverse explicit and implicit relations, which have not been fully exploited for risk judgement in commercial banks. In particular, the observations on real data show that various relationships between company users have additional power in financial risk analysis. In this paper, we consider a graph of banking data, and propose a novel HIDAM model for the purpose. Specifically, we attempt to incorporate heterogeneous information network with rich attributes on multi-typed nodes and links for modeling the scenario of business banking service. To enhance feature representation of MSEs, we extract interactive information through meta-paths and fully exploit path information. Furthermore, we devise a hierarchical attention mechanism respectively to learn the importance of contents inside each meta-path and the importance of different metapahs. Experimental results verify that HIDAM outperforms state-of-the-art competitors on real-world banking data.
BLISS: Robust Sequence-to-Sequence Learning via Self-Supervised Input Representation
Apr 24, 2022
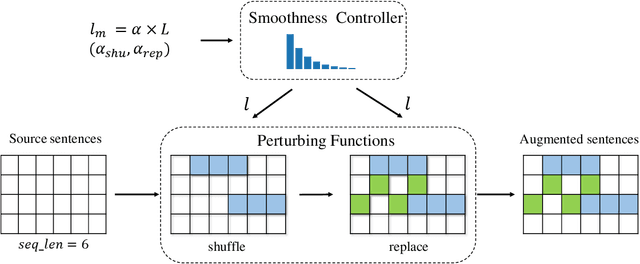
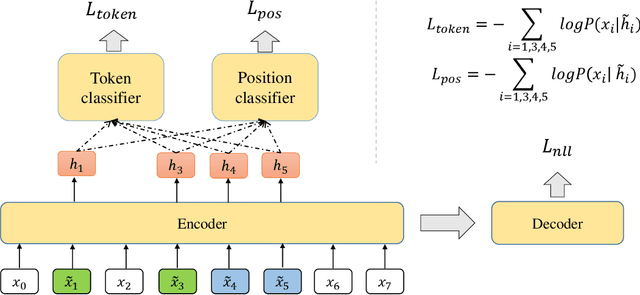
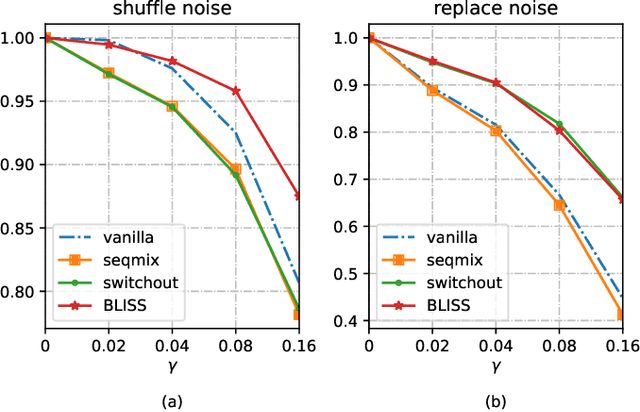
Data augmentations (DA) are the cores to achieving robust sequence-to-sequence learning on various natural language processing (NLP) tasks. However, most of the DA approaches force the decoder to make predictions conditioned on the perturbed input representation, underutilizing supervised information provided by perturbed input. In this work, we propose a framework-level robust sequence-to-sequence learning approach, named BLISS, via self-supervised input representation, which has the great potential to complement the data-level augmentation approaches. The key idea is to supervise the sequence-to-sequence framework with both the \textit{supervised} ("input$\rightarrow$output") and \textit{self-supervised} ("perturbed input$\rightarrow$input") information. We conduct comprehensive experiments to validate the effectiveness of BLISS on various tasks, including machine translation, grammatical error correction, and text summarization. The results show that BLISS outperforms significantly the vanilla Transformer and consistently works well across tasks than the other five contrastive baselines. Extensive analyses reveal that BLISS learns robust representations and rich linguistic knowledge, confirming our claim. Source code will be released upon publication.