 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZheng Wang
Disentangled Implicit Shape and Pose Learning for Scalable 6D Pose Estimation
Jul 27, 2021
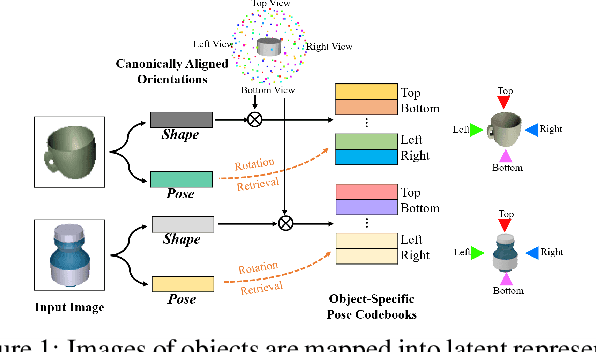
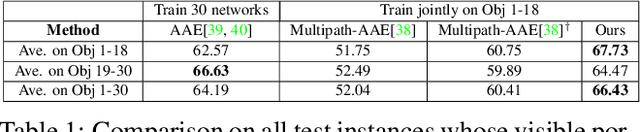
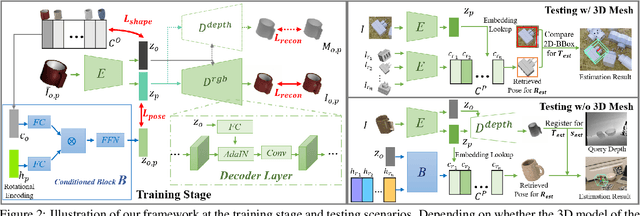

6D pose estimation of rigid objects from a single RGB image has seen tremendous improvements recently by using deep learning to combat complex real-world variations, but a majority of methods build models on the per-object level, failing to scale to multiple objects simultaneously. In this paper, we present a novel approach for scalable 6D pose estimation, by self-supervised learning on synthetic data of multiple objects using a single autoencoder. To handle multiple objects and generalize to unseen objects, we disentangle the latent object shape and pose representations, so that the latent shape space models shape similarities, and the latent pose code is used for rotation retrieval by comparison with canonical rotations. To encourage shape space construction, we apply contrastive metric learning and enable the processing of unseen objects by referring to similar training objects. The different symmetries across objects induce inconsistent latent pose spaces, which we capture with a conditioned block producing shape-dependent pose codebooks by re-entangling shape and pose representations. We test our method on two multi-object benchmarks with real data, T-LESS and NOCS REAL275, and show it outperforms existing RGB-based methods in terms of pose estimation accuracy and generalization.
Spectrum Gaussian Processes Based On Tunable Basis Functions
Jul 14, 2021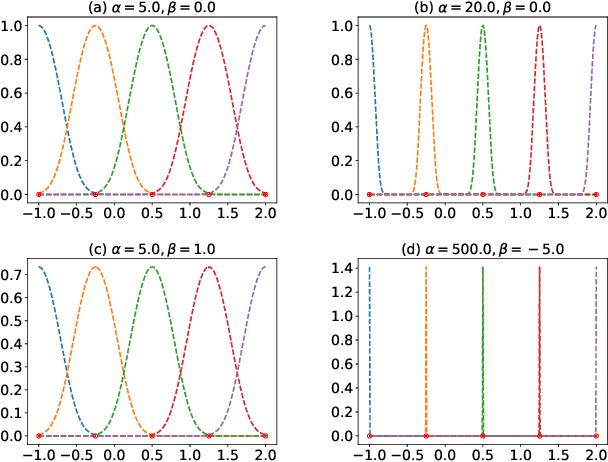
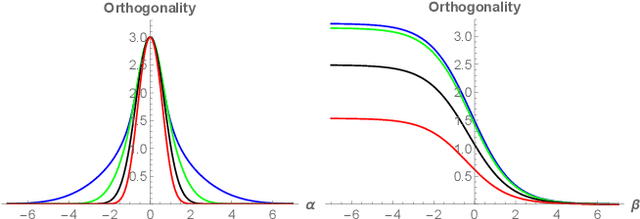
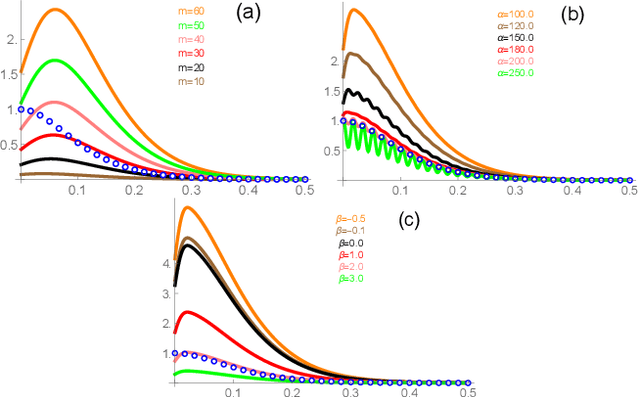
Spectral approximation and variational inducing learning for the Gaussian process are two popular methods to reduce computational complexity. However, in previous research, those methods always tend to adopt the orthonormal basis functions, such as eigenvectors in the Hilbert space, in the spectrum method, or decoupled orthogonal components in the variational framework. In this paper, inspired by quantum physics, we introduce a novel basis function, which is tunable, local and bounded, to approximate the kernel function in the Gaussian process. There are two adjustable parameters in these functions, which control their orthogonality to each other and limit their boundedness. And we conduct extensive experiments on open-source datasets to testify its performance. Compared to several state-of-the-art methods, it turns out that the proposed method can obtain satisfactory or even better results, especially with poorly chosen kernel functions.
Reinforcement Learning-based Dialogue Guided Event Extraction to Exploit Argument Relations
Jun 23, 2021
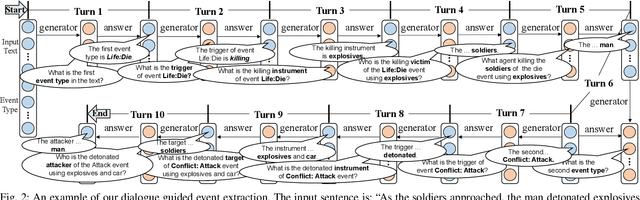
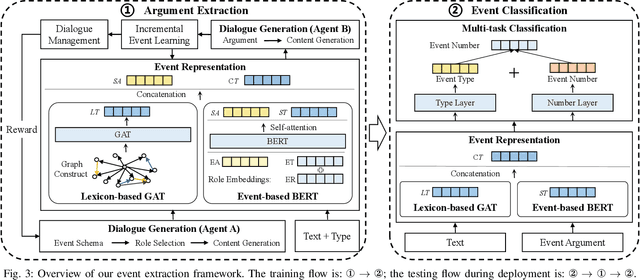
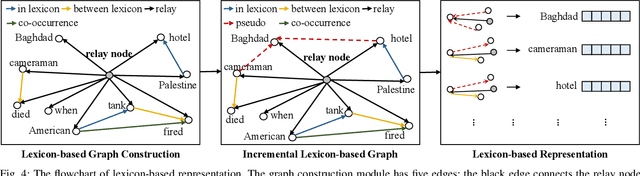
Event extraction is a fundamental task for natural language processing. Finding the roles of event arguments like event participants is essential for event extraction. However, doing so for real-life event descriptions is challenging because an argument's role often varies in different contexts. While the relationship and interactions between multiple arguments are useful for settling the argument roles, such information is largely ignored by existing approaches. This paper presents a better approach for event extraction by explicitly utilizing the relationships of event arguments. We achieve this through a carefully designed task-oriented dialogue system. To model the argument relation, we employ reinforcement learning and incremental learning to extract multiple arguments via a multi-turned, iterative process. Our approach leverages knowledge of the already extracted arguments of the same sentence to determine the role of arguments that would be difficult to decide individually. It then uses the newly obtained information to improve the decisions of previously extracted arguments. This two-way feedback process allows us to exploit the argument relations to effectively settle argument roles, leading to better sentence understanding and event extraction. Experimental results show that our approach consistently outperforms seven state-of-the-art event extraction methods for the classification of events and argument role and argument identification.
Zero-shot Node Classification with Decomposed Graph Prototype Network
Jun 15, 2021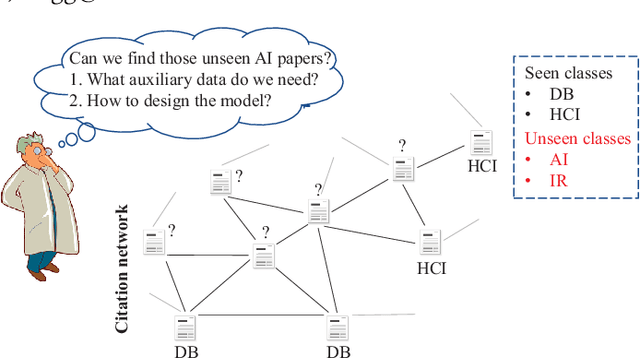
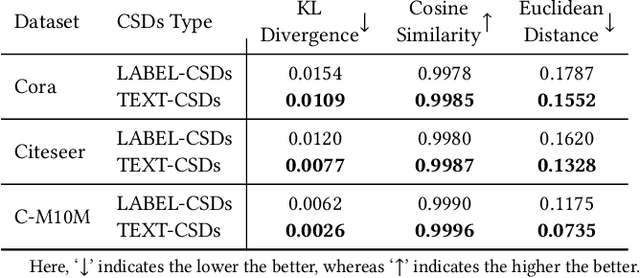
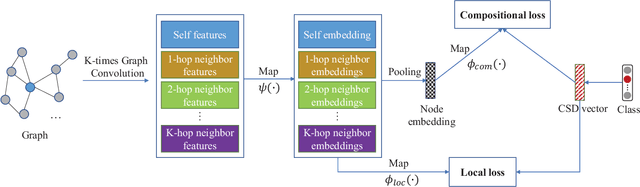

Node classification is a central task in graph data analysis. Scarce or even no labeled data of emerging classes is a big challenge for existing methods. A natural question arises: can we classify the nodes from those classes that have never been seen? In this paper, we study this zero-shot node classification (ZNC) problem which has a two-stage nature: (1) acquiring high-quality class semantic descriptions (CSDs) for knowledge transfer, and (2) designing a well generalized graph-based learning model. For the first stage, we give a novel quantitative CSDs evaluation strategy based on estimating the real class relationships, so as to get the "best" CSDs in a completely automatic way. For the second stage, we propose a novel Decomposed Graph Prototype Network (DGPN) method, following the principles of locality and compositionality for zero-shot model generalization. Finally, we conduct extensive experiments to demonstrate the effectiveness of our solutions.
Unsupervised Video Person Re-identification via Noise and Hard frame Aware Clustering
Jun 10, 2021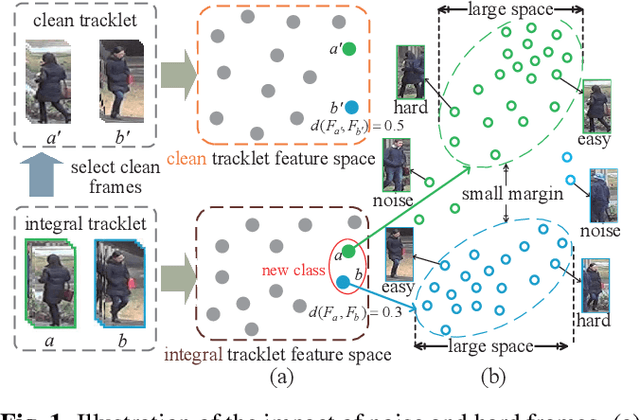
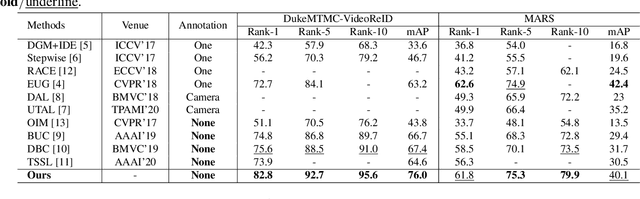
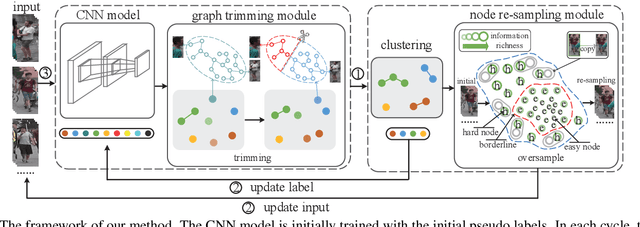
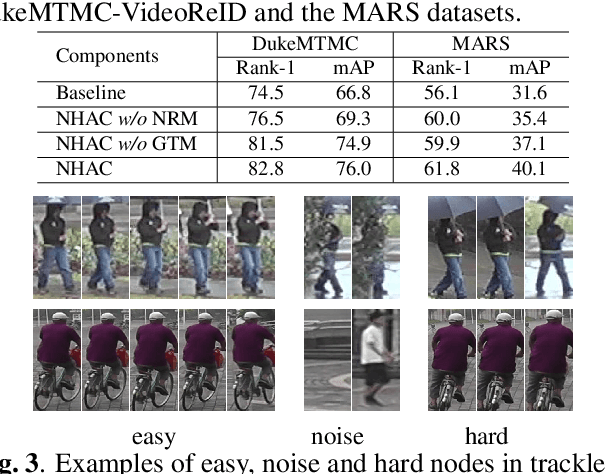
Unsupervised video-based person re-identification (re-ID) methods extract richer features from video tracklets than image-based ones. The state-of-the-art methods utilize clustering to obtain pseudo-labels and train the models iteratively. However, they underestimate the influence of two kinds of frames in the tracklet: 1) noise frames caused by detection errors or heavy occlusions exist in the tracklet, which may be allocated with unreliable labels during clustering; 2) the tracklet also contains hard frames caused by pose changes or partial occlusions, which are difficult to distinguish but informative. This paper proposes a Noise and Hard frame Aware Clustering (NHAC) method. NHAC consists of a graph trimming module and a node re-sampling module. The graph trimming module obtains stable graphs by removing noise frame nodes to improve the clustering accuracy. The node re-sampling module enhances the training of hard frame nodes to learn rich tracklet information. Experiments conducted on two video-based datasets demonstrate the effectiveness of the proposed NHAC under the unsupervised re-ID setting.
Effect of Adaptive and Fixed Shared Steering Control on Distracted Driver Behavior
Jun 07, 2021
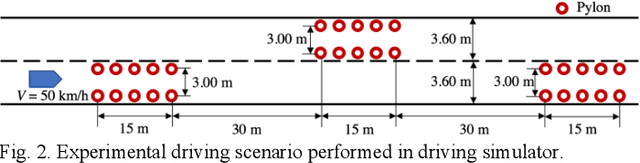


Driver distraction is a well-known cause for traffic collisions worldwide. Studies have indicated that shared steering control, which actively provides haptic guidance torque on the steering wheel, effectively improves the performance of distracted drivers. Recently, adaptive shared steering control based on the physiological status of the driver has been developed, although its effect on distracted driver behavior remains unclear. To this end, a high-fidelity driving simulator experiment was conducted involving 18 participants performing double lane changes. The experimental conditions comprised two driver states: attentive and distracted. Under each condition, evaluations were performed on three types of haptic guidance: none (manual), fixed authority, and adaptive authority based on feedback from the forearm surface electromyography of the driver. Evaluation results indicated that, for both attentive and distracted drivers, haptic guidance with adaptive authority yielded lower driver workload and reduced lane departure risk than manual driving and fixed authority. Moreover, there was a tendency for distracted drivers to reduce grip strength on the steering wheel to follow the haptic guidance with fixed authority, resulting in a relatively shorter double lane change duration.
Automated Timeline Length Selection for Flexible Timeline Summarization
May 29, 2021
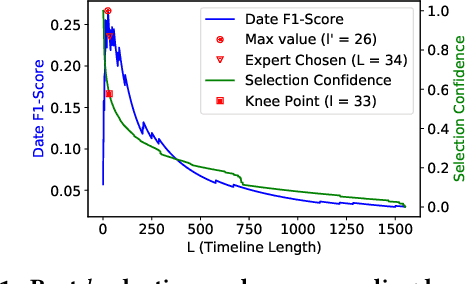
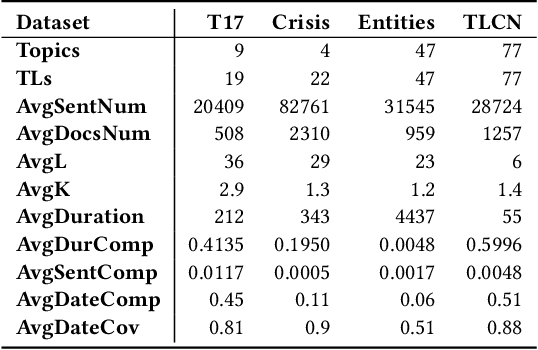
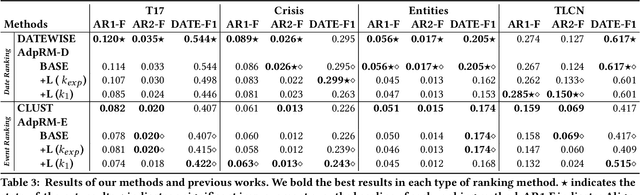
By producing summaries for long-running events, timeline summarization (TLS) underpins many information retrieval tasks. Successful TLS requires identifying an appropriate set of key dates (the timeline length) to cover. However, doing so is challenging as the right length can change from one topic to another. Existing TLS solutions either rely on an event-agnostic fixed length or an expert-supplied setting. Neither of the strategies is desired for real-life TLS scenarios. A fixed, event-agnostic setting ignores the diversity of events and their development and hence can lead to low-quality TLS. Relying on expert-crafted settings is neither scalable nor sustainable for processing many dynamically changing events. This paper presents a better TLS approach for automatically and dynamically determining the TLS timeline length. We achieve this by employing the established elbow method from the machine learning community to automatically find the minimum number of dates within the time series to generate concise and informative summaries. We applied our approach to four TLS datasets of English and Chinese and compared them against three prior methods. Experimental results show that our approach delivers comparable or even better summaries over state-of-art TLS methods, but it achieves this without expert involvement.
Federated Learning with Fair Averaging
May 17, 2021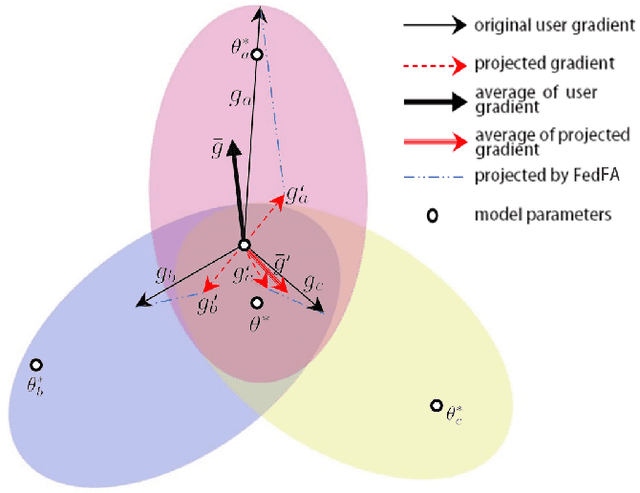
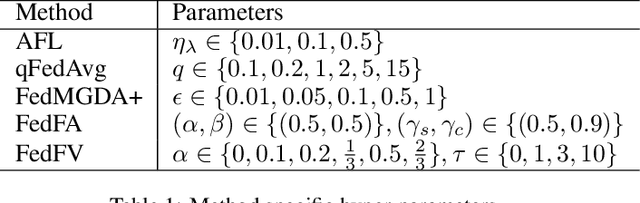
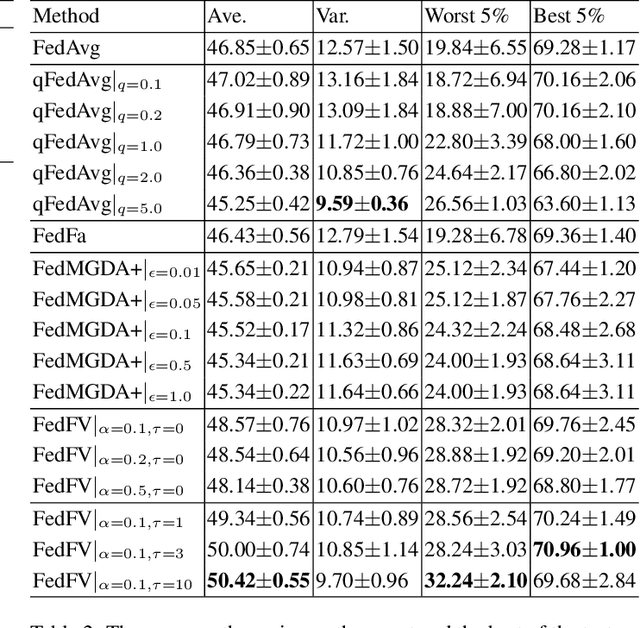
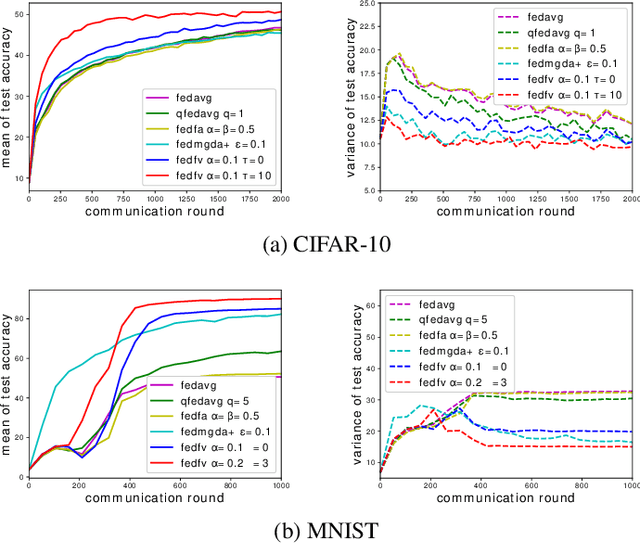
Fairness has emerged as a critical problem in federated learning (FL). In this work, we identify a cause of unfairness in FL -- \emph{conflicting} gradients with large differences in the magnitudes. To address this issue, we propose the federated fair averaging (FedFV) algorithm to mitigate potential conflicts among clients before averaging their gradients. We first use the cosine similarity to detect gradient conflicts, and then iteratively eliminate such conflicts by modifying both the direction and the magnitude of the gradients. We further show the theoretical foundation of FedFV to mitigate the issue conflicting gradients and converge to Pareto stationary solutions. Extensive experiments on a suite of federated datasets confirm that FedFV compares favorably against state-of-the-art methods in terms of fairness, accuracy and efficiency.
Analysis and Modeling of Driver Behavior with Integrated Feedback of Visual and Haptic Information Under Shared Control
Apr 23, 2021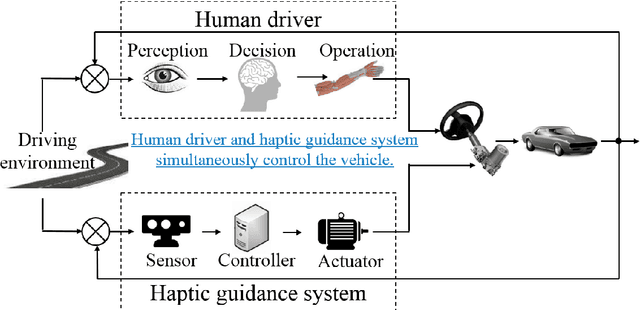
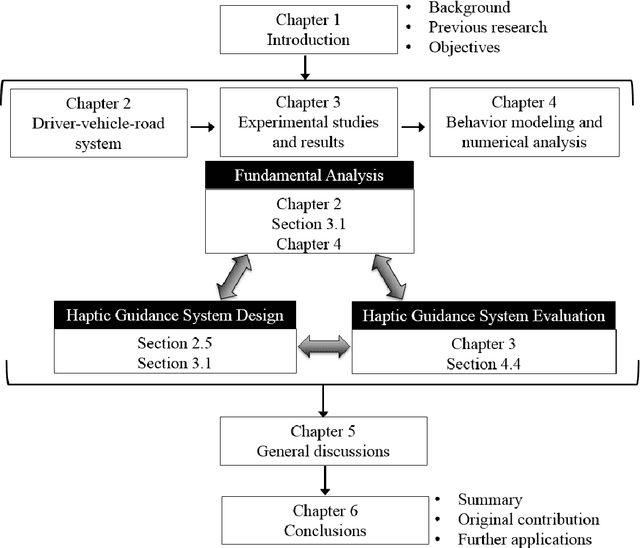
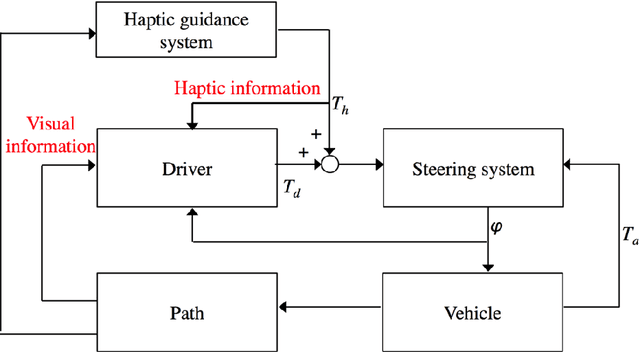
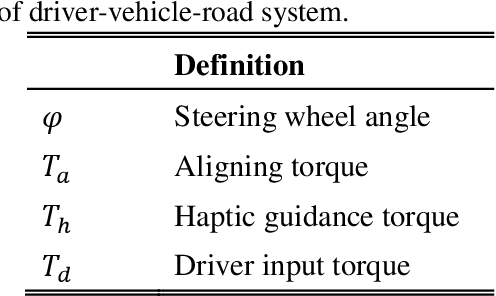
The thesis presents contributions made to the evaluation and design of a haptic guidance system on improving driving performance in cases of normal and degraded visual information, which are based on behavior experiments, modeling and numerical simulations. The effect of shared control on driver behavior in cases of normal and degraded visual information has been successfully evaluated experimentally and numerically. The evaluation results indicate that the proposed haptic guidance system is capable of providing reliable haptic information, and is effective on improving lane following performance in the conditions of visual occlusion from road ahead and declined visual attention under fatigue driving. Moreover, the appropriate degree of haptic guidance is highly related to the reliability of visual information perceived by the driver, which suggests that designing the haptic guidance system based on the reliability of visual information would allow for greater driver acceptance. Furthermore, the parameterized driver model, which considers the integrated feedback of visual and haptic information, is capable of predicting driver behavior under shared control, and has the potential of being used for designing and evaluating the haptic guidance system.