 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhe Chen
DDP: Diffusion Model for Dense Visual Prediction
Mar 30, 2023
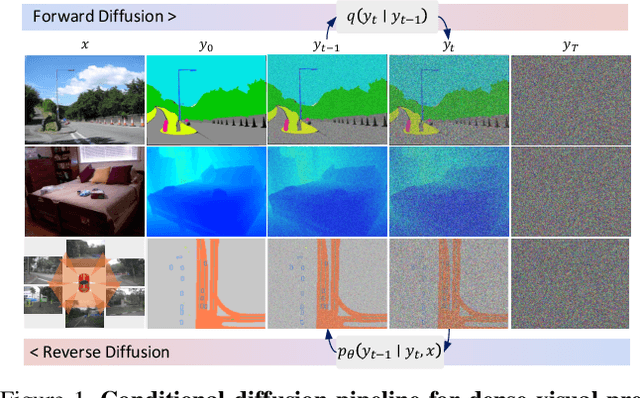
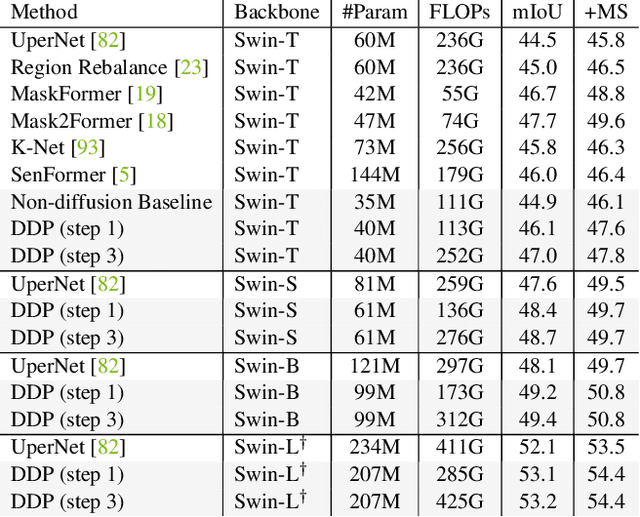
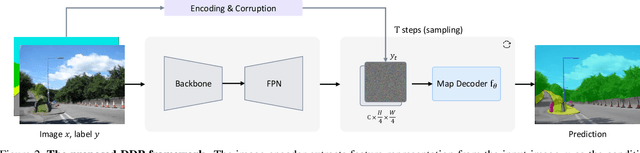
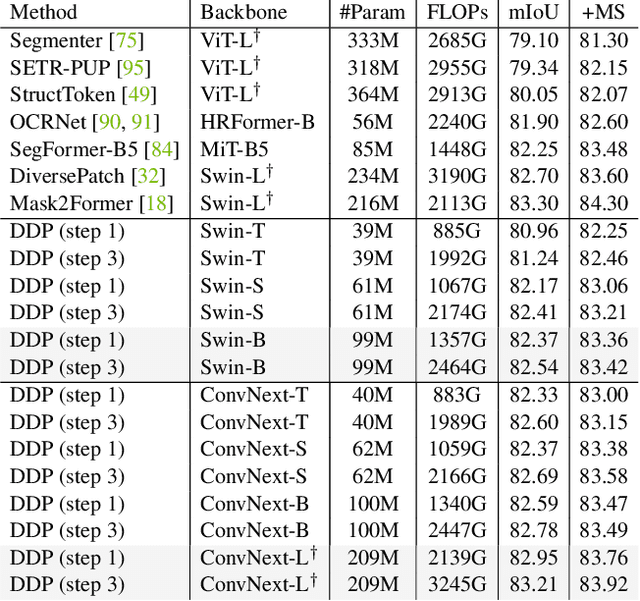
We propose a simple, efficient, yet powerful framework for dense visual predictions based on the conditional diffusion pipeline. Our approach follows a "noise-to-map" generative paradigm for prediction by progressively removing noise from a random Gaussian distribution, guided by the image. The method, called DDP, efficiently extends the denoising diffusion process into the modern perception pipeline. Without task-specific design and architecture customization, DDP is easy to generalize to most dense prediction tasks, e.g., semantic segmentation and depth estimation. In addition, DDP shows attractive properties such as dynamic inference and uncertainty awareness, in contrast to previous single-step discriminative methods. We show top results on three representative tasks with six diverse benchmarks, without tricks, DDP achieves state-of-the-art or competitive performance on each task compared to the specialist counterparts. For example, semantic segmentation (83.9 mIoU on Cityscapes), BEV map segmentation (70.6 mIoU on nuScenes), and depth estimation (0.05 REL on KITTI). We hope that our approach will serve as a solid baseline and facilitate future research
Multi-band Reconfigurable Holographic Surface Based ISAC Systems: Design and Optimization
Mar 28, 2023
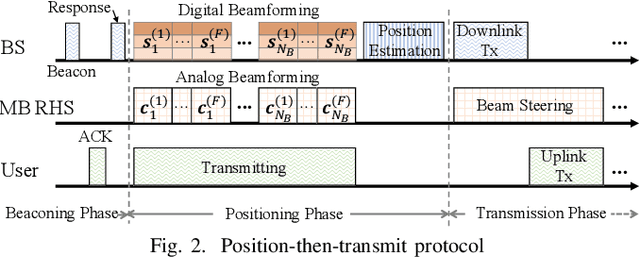
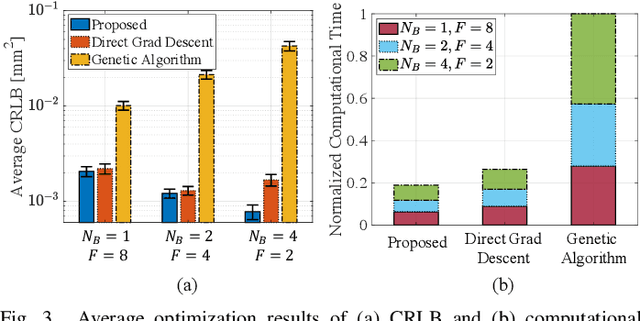

Metamaterial-based reconfigurable holographic surfaces (RHSs) have been proposed as novel cost-efficient antenna arrays, which are promising for improving the positioning and communication performance of integrated sensing and communications (ISAC) systems. However, due to the high frequency selectivity of the metamaterial elements, RHSs face challenges in supporting ultra-wide bandwidth (UWB), which significantly limits the positioning precision. In this paper, to avoid the physical limitations of UWB RHS while enhancing the performance of RHS-based ISAC systems, we propose a multi-band (MB) based ISAC system. We analyze its positioning precision and propose an efficient algorithm to optimize the large number of variables in analog and digital beamforming. Through comparison with benchmark results, simulation results verify the efficiency of our proposed system and algorithm, and show that the system achieves $42\%$ less positioning error, which reduces $82\%$ communication capacity loss.
AutoFed: Heterogeneity-Aware Federated Multimodal Learning for Robust Autonomous Driving
Feb 24, 2023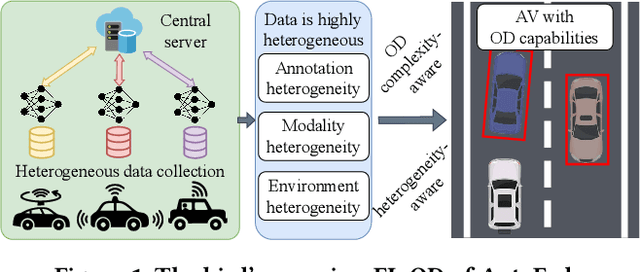
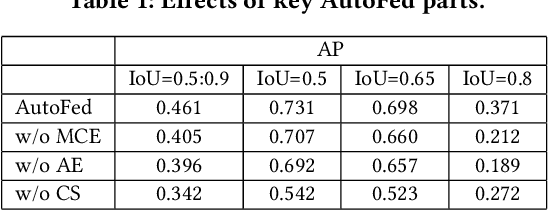
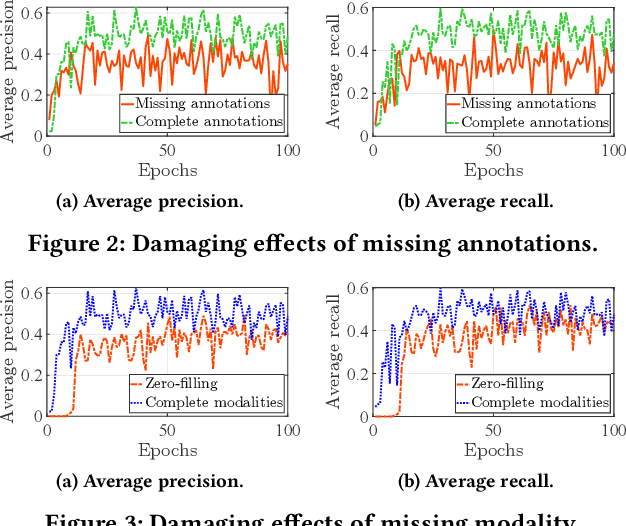
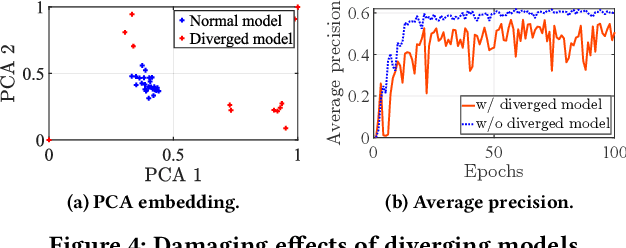
Object detection with on-board sensors (e.g., lidar, radar, and camera) play a crucial role in autonomous driving (AD), and these sensors complement each other in modalities. While crowdsensing may potentially exploit these sensors (of huge quantity) to derive more comprehensive knowledge, \textit{federated learning} (FL) appears to be the necessary tool to reach this potential: it enables autonomous vehicles (AVs) to train machine learning models without explicitly sharing raw sensory data. However, the multimodal sensors introduce various data heterogeneity across distributed AVs (e.g., label quantity skews and varied modalities), posing critical challenges to effective FL. To this end, we present AutoFed as a heterogeneity-aware FL framework to fully exploit multimodal sensory data on AVs and thus enable robust AD. Specifically, we first propose a novel model leveraging pseudo-labeling to avoid mistakenly treating unlabeled objects as the background. We also propose an autoencoder-based data imputation method to fill missing data modality (of certain AVs) with the available ones. To further reconcile the heterogeneity, we finally present a client selection mechanism exploiting the similarities among client models to improve both training stability and convergence rate. Our experiments on benchmark dataset confirm that AutoFed substantially improves over status quo approaches in both precision and recall, while demonstrating strong robustness to adverse weather conditions.
Champion Solution for the WSDM2023 Toloka VQA Challenge
Jan 22, 2023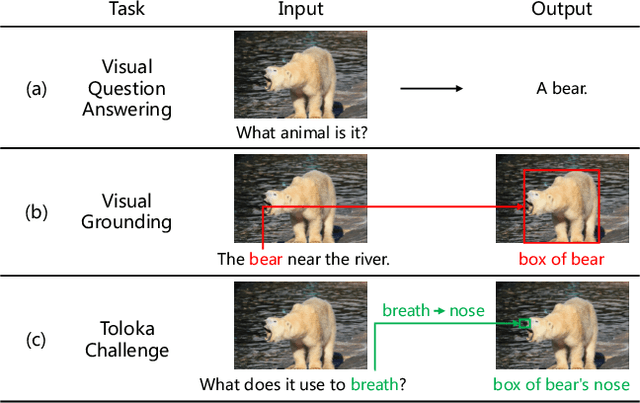
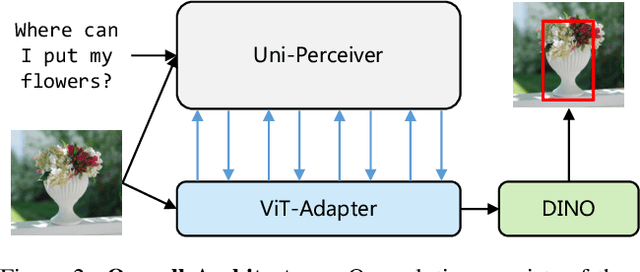

In this report, we present our champion solution to the WSDM2023 Toloka Visual Question Answering (VQA) Challenge. Different from the common VQA and visual grounding (VG) tasks, this challenge involves a more complex scenario, i.e. inferring and locating the object implicitly specified by the given interrogative question. For this task, we leverage ViT-Adapter, a pre-training-free adapter network, to adapt multi-modal pre-trained Uni-Perceiver for better cross-modal localization. Our method ranks first on the leaderboard, achieving 77.5 and 76.347 IoU on public and private test sets, respectively. It shows that ViT-Adapter is also an effective paradigm for adapting the unified perception model to vision-language downstream tasks. Code and models will be released at https://github.com/czczup/ViT-Adapter/tree/main/wsdm2023.
LegalRelectra: Mixed-domain Language Modeling for Long-range Legal Text Comprehension
Dec 16, 2022
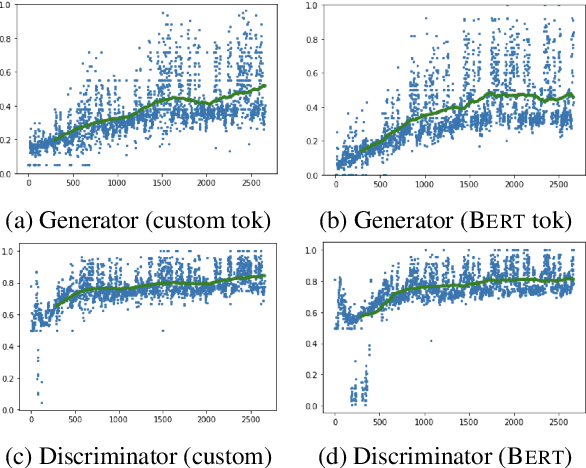
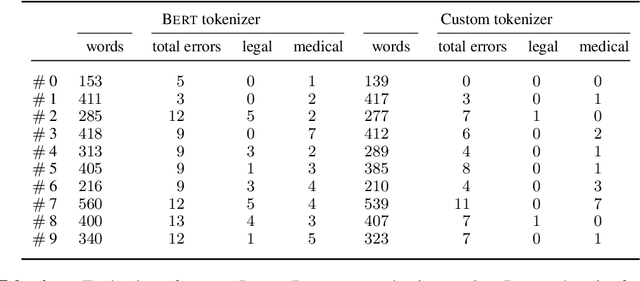
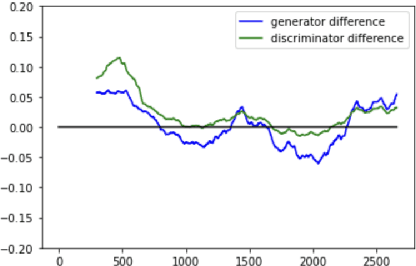
The application of Natural Language Processing (NLP) to specialized domains, such as the law, has recently received a surge of interest. As many legal services rely on processing and analyzing large collections of documents, automating such tasks with NLP tools emerges as a key challenge. Many popular language models, such as BERT or RoBERTa, are general-purpose models, which have limitations on processing specialized legal terminology and syntax. In addition, legal documents may contain specialized vocabulary from other domains, such as medical terminology in personal injury text. Here, we propose LegalRelectra, a legal-domain language model that is trained on mixed-domain legal and medical corpora. We show that our model improves over general-domain and single-domain medical and legal language models when processing mixed-domain (personal injury) text. Our training architecture implements the Electra framework, but utilizes Reformer instead of BERT for its generator and discriminator. We show that this improves the model's performance on processing long passages and results in better long-range text comprehension.
FPGA-Based In-Vivo Calcium Image Decoding for Closed-Loop Feedback Applications
Dec 09, 2022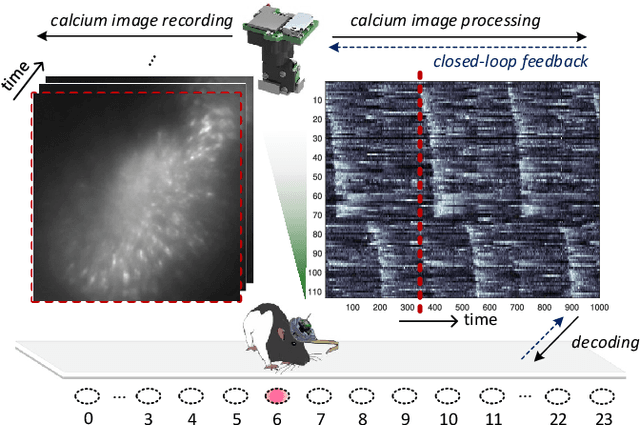
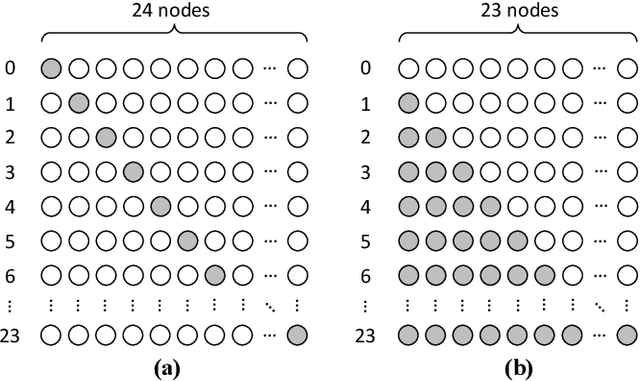
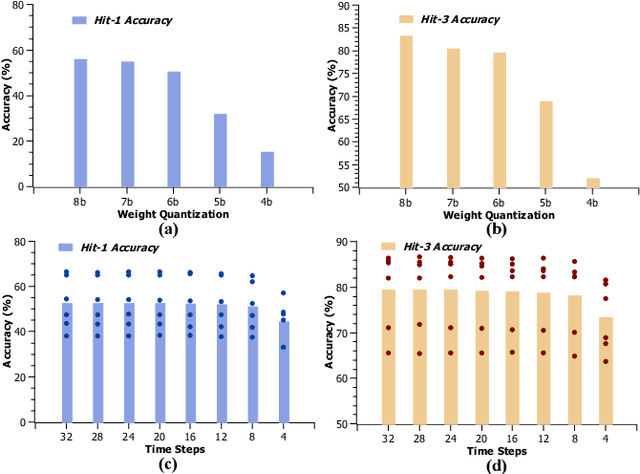

The miniaturized calcium imaging is an emerging neural recording technique that can monitor neural activity at large scale at a specific brain region of a rat or mice. It has been widely used in the study of brain functions in experimental neuroscientific research. Most calcium-image analysis pipelines operate offline, which incurs long processing latency thus are hard to be used for closed-loop feedback stimulation targeting certain neural circuits. In this paper, we propose our FPGA-based design that enables real-time calcium image processing and position decoding for closed-loop feedback applications. Our design can perform real-time calcium image motion correction, enhancement, and fast trace extraction based on predefined cell contours and tiles. With that, we evaluated a variety of machine learning methods to decode positions from the extracted traces. Our proposed design and implementation can achieve position decoding with less than 1 ms latency under 300 MHz on FPGA for a variety of mainstream 1-photon miniscope sensors. We benchmarked the position decoding accuracy on open-sourced datasets collected from six different rats, and we show that by taking advantage of the ordinal encoding in the decoding task, we can consistently improve decoding accuracy without any overhead on hardware implementation and runtime across the subjects.
Pose-disentangled Contrastive Learning for Self-supervised Facial Representation
Nov 24, 2022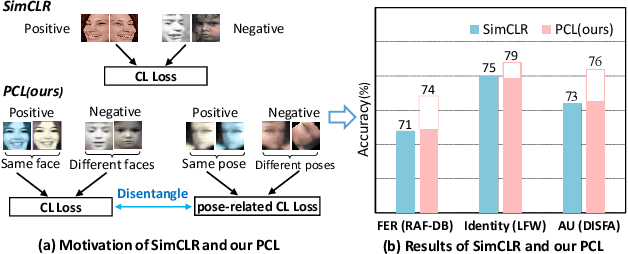
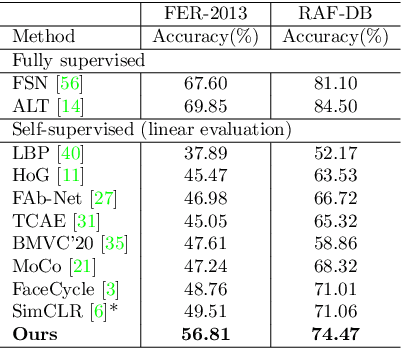
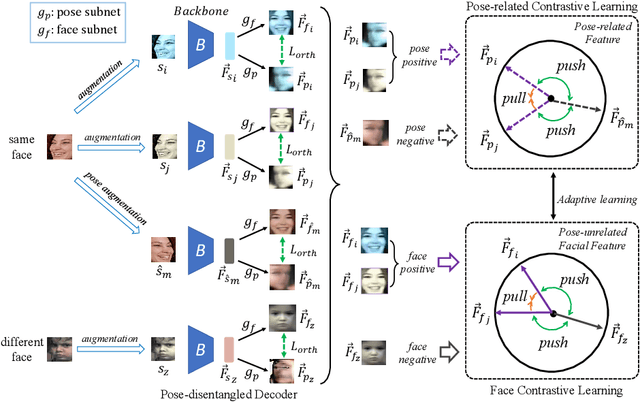
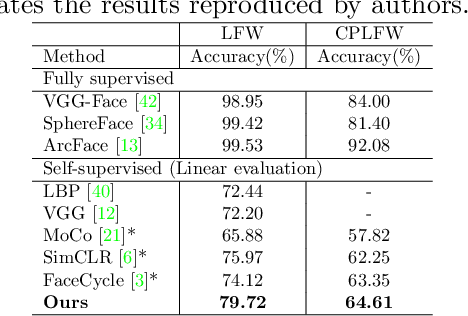
Self-supervised facial representation has recently attracted increasing attention due to its ability to perform face understanding without relying on large-scale annotated datasets heavily. However, analytically, current contrastive-based self-supervised learning still performs unsatisfactorily for learning facial representation. More specifically, existing contrastive learning (CL) tends to learn pose-invariant features that cannot depict the pose details of faces, compromising the learning performance. To conquer the above limitation of CL, we propose a novel Pose-disentangled Contrastive Learning (PCL) method for general self-supervised facial representation. Our PCL first devises a pose-disentangled decoder (PDD) with a delicately designed orthogonalizing regulation, which disentangles the pose-related features from the face-aware features; therefore, pose-related and other pose-unrelated facial information could be performed in individual subnetworks and do not affect each other's training. Furthermore, we introduce a pose-related contrastive learning scheme that learns pose-related information based on data augmentation of the same image, which would deliver more effective face-aware representation for various downstream tasks. We conducted a comprehensive linear evaluation on three challenging downstream facial understanding tasks, i.e., facial expression recognition, face recognition, and AU detection. Experimental results demonstrate that our method outperforms cutting-edge contrastive and other self-supervised learning methods with a great margin.
InternVideo-Ego4D: A Pack of Champion Solutions to Ego4D Challenges
Nov 17, 2022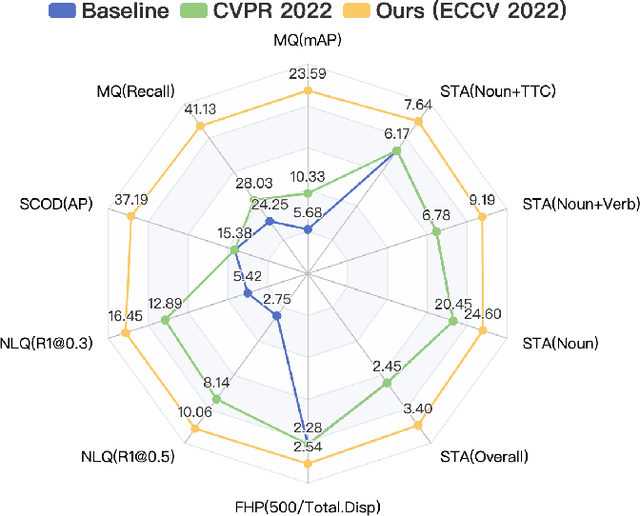

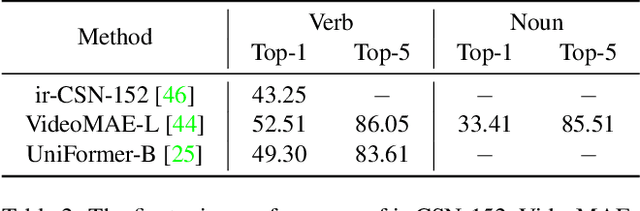
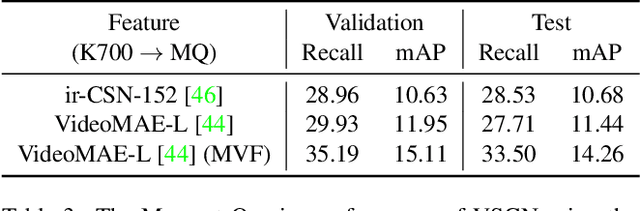
In this report, we present our champion solutions to five tracks at Ego4D challenge. We leverage our developed InternVideo, a video foundation model, for five Ego4D tasks, including Moment Queries, Natural Language Queries, Future Hand Prediction, State Change Object Detection, and Short-term Object Interaction Anticipation. InternVideo-Ego4D is an effective paradigm to adapt the strong foundation model to the downstream ego-centric video understanding tasks with simple head designs. In these five tasks, the performance of InternVideo-Ego4D comprehensively surpasses the baseline methods and the champions of CVPR2022, demonstrating the powerful representation ability of InternVideo as a video foundation model. Our code will be released at https://github.com/OpenGVLab/ego4d-eccv2022-solutions
InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
Nov 13, 2022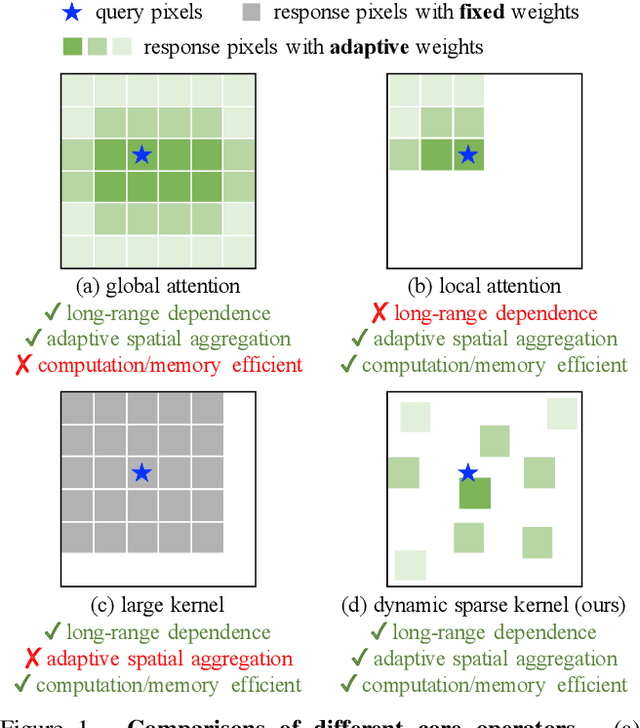
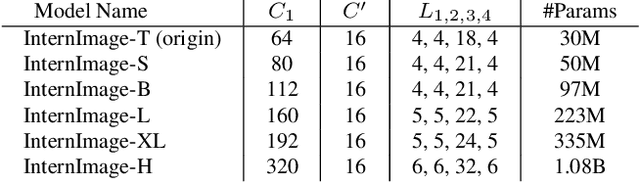
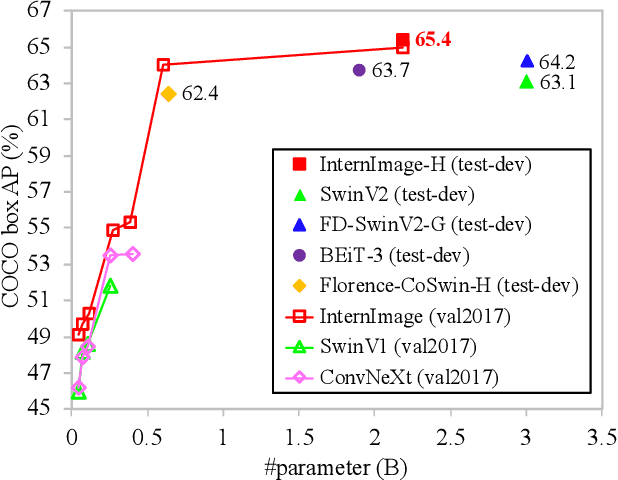
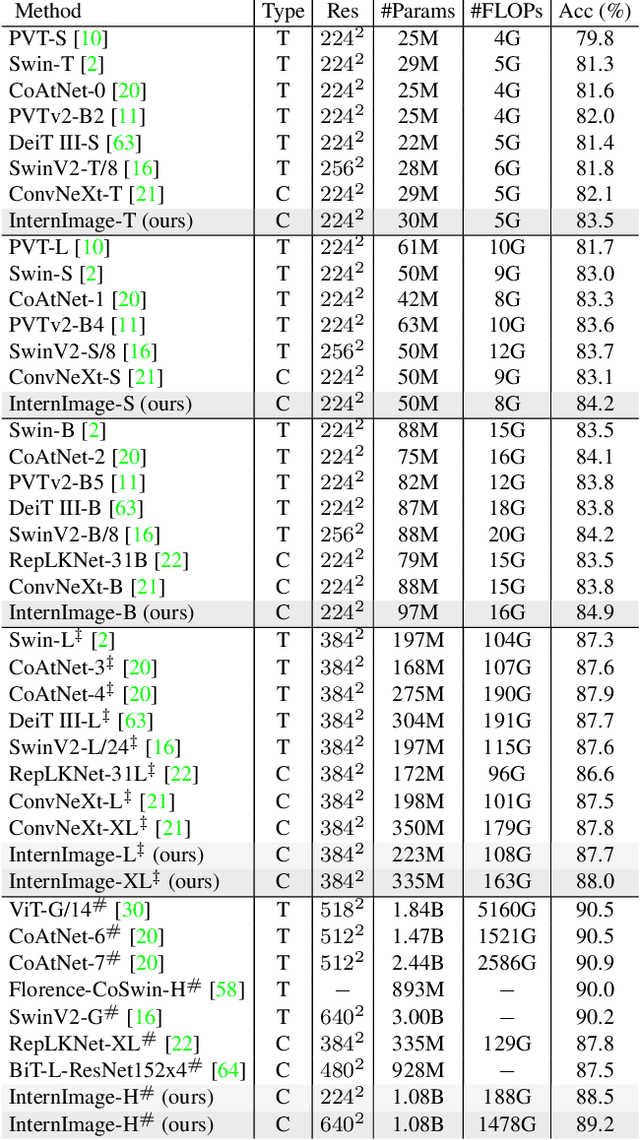
Compared to the great progress of large-scale vision transformers (ViTs) in recent years, large-scale models based on convolutional neural networks (CNNs) are still in an early state. This work presents a new large-scale CNN-based foundation model, termed InternImage, which can obtain the gain from increasing parameters and training data like ViTs. Different from the recent CNNs that focus on large dense kernels, InternImage takes deformable convolution as the core operator, so that our model not only has the large effective receptive field required for downstream tasks such as detection and segmentation, but also has the adaptive spatial aggregation conditioned by input and task information. As a result, the proposed InternImage reduces the strict inductive bias of traditional CNNs and makes it possible to learn stronger and more robust patterns with large-scale parameters from massive data like ViTs. The effectiveness of our model is proven on challenging benchmarks including ImageNet, COCO, and ADE20K. It is worth mentioning that InternImage-H achieved a new record 65.4 mAP on COCO test-dev and 62.9 mIoU on ADE20K, outperforming current leading CNNs and ViTs. The code will be released at https://github.com/OpenGVLab/InternImage.