 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuxin Chen
Settling the Sample Complexity of Model-Based Offline Reinforcement Learning
Apr 11, 2022

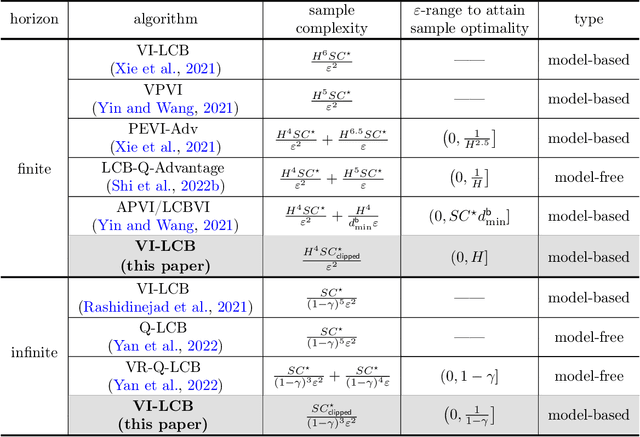
This paper is concerned with offline reinforcement learning (RL), which learns using pre-collected data without further exploration. Effective offline RL would be able to accommodate distribution shift and limited data coverage. However, prior algorithms or analyses either suffer from suboptimal sample complexities or incur high burn-in cost to reach sample optimality, thus posing an impediment to efficient offline RL in sample-starved applications. We demonstrate that the model-based (or "plug-in") approach achieves minimax-optimal sample complexity without burn-in cost for tabular Markov decision processes (MDPs). Concretely, consider a finite-horizon (resp. $\gamma$-discounted infinite-horizon) MDP with $S$ states and horizon $H$ (resp. effective horizon $\frac{1}{1-\gamma}$), and suppose the distribution shift of data is reflected by some single-policy clipped concentrability coefficient $C^{\star}_{\text{clipped}}$. We prove that model-based offline RL yields $\varepsilon$-accuracy with a sample complexity of \[ \begin{cases} \frac{H^{4}SC_{\text{clipped}}^{\star}}{\varepsilon^{2}} & (\text{finite-horizon MDPs}) \frac{SC_{\text{clipped}}^{\star}}{(1-\gamma)^{3}\varepsilon^{2}} & (\text{infinite-horizon MDPs}) \end{cases} \] up to log factor, which is minimax optimal for the entire $\varepsilon$-range. Our algorithms are "pessimistic" variants of value iteration with Bernstein-style penalties, and do not require sophisticated variance reduction.
CREATE: A Benchmark for Chinese Short Video Retrieval and Title Generation
Mar 31, 2022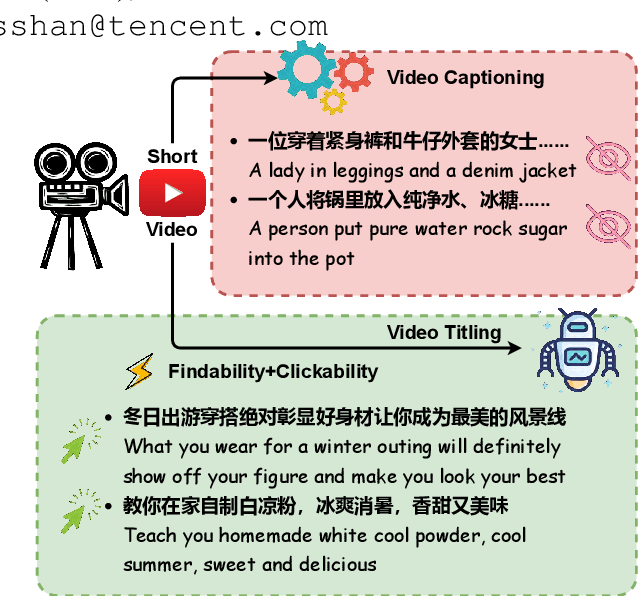
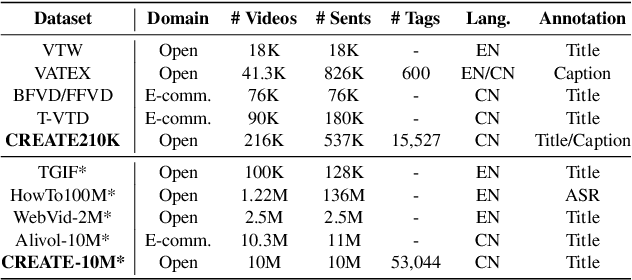

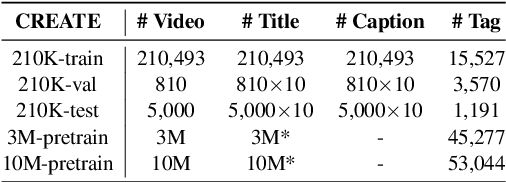
Previous works of video captioning aim to objectively describe the video's actual content, which lacks subjective and attractive expression, limiting its practical application scenarios. Video titling is intended to achieve this goal, but there is a lack of a proper benchmark. In this paper, we propose to CREATE, the first large-scale Chinese shoRt vidEo retrievAl and Title gEneration benchmark, to facilitate research and application in video titling and video retrieval in Chinese. CREATE consists of a high-quality labeled 210K dataset and two large-scale 3M/10M pre-training datasets, covering 51 categories, 50K+ tags, 537K manually annotated titles and captions, and 10M+ short videos. Based on CREATE, we propose a novel model ALWIG which combines video retrieval and video titling tasks to achieve the purpose of multi-modal ALignment WIth Generation with the help of video tags and a GPT pre-trained model. CREATE opens new directions for facilitating future research and applications on video titling and video retrieval in the field of Chinese short videos.
Open-Vocabulary One-Stage Detection with Hierarchical Visual-Language Knowledge Distillation
Mar 20, 2022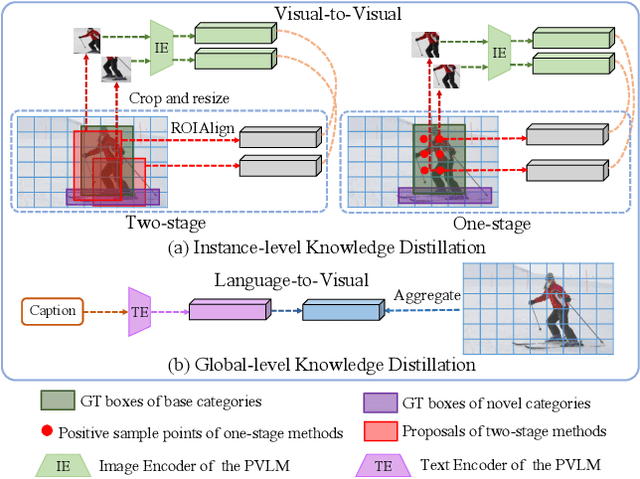
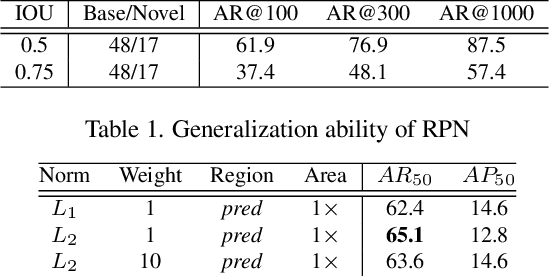
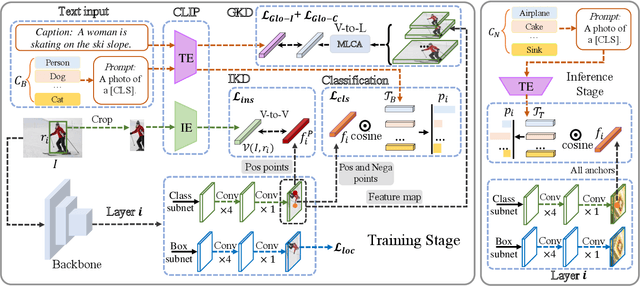
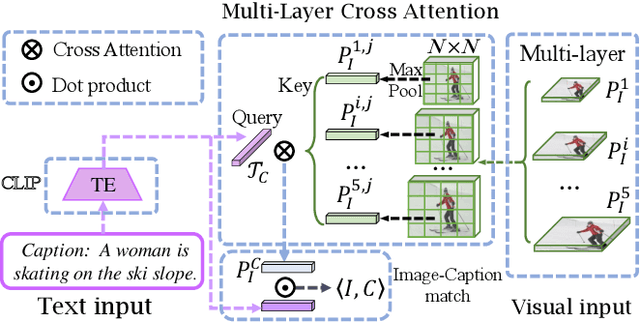
Open-vocabulary object detection aims to detect novel object categories beyond the training set. The advanced open-vocabulary two-stage detectors employ instance-level visual-to-visual knowledge distillation to align the visual space of the detector with the semantic space of the Pre-trained Visual-Language Model (PVLM). However, in the more efficient one-stage detector, the absence of class-agnostic object proposals hinders the knowledge distillation on unseen objects, leading to severe performance degradation. In this paper, we propose a hierarchical visual-language knowledge distillation method, i.e., HierKD, for open-vocabulary one-stage detection. Specifically, a global-level knowledge distillation is explored to transfer the knowledge of unseen categories from the PVLM to the detector. Moreover, we combine the proposed global-level knowledge distillation and the common instance-level knowledge distillation to learn the knowledge of seen and unseen categories simultaneously. Extensive experiments on MS-COCO show that our method significantly surpasses the previous best one-stage detector with 11.9\% and 6.7\% $AP_{50}$ gains under the zero-shot detection and generalized zero-shot detection settings, and reduces the $AP_{50}$ performance gap from 14\% to 7.3\% compared to the best two-stage detector.
Learning Representation for Bayesian Optimization with Collision-free Regularization
Mar 16, 2022


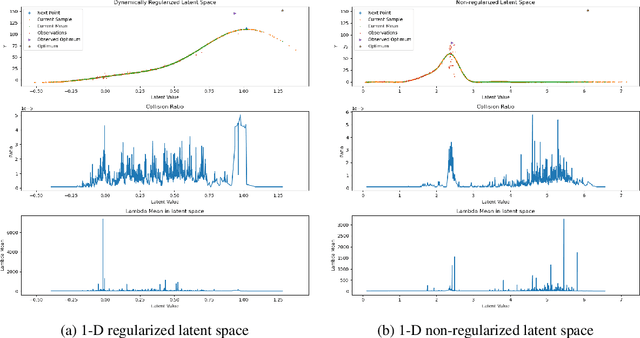
Bayesian optimization has been challenged by datasets with large-scale, high-dimensional, and non-stationary characteristics, which are common in real-world scenarios. Recent works attempt to handle such input by applying neural networks ahead of the classical Gaussian process to learn a latent representation. We show that even with proper network design, such learned representation often leads to collision in the latent space: two points with significantly different observations collide in the learned latent space, leading to degraded optimization performance. To address this issue, we propose LOCo, an efficient deep Bayesian optimization framework which employs a novel regularizer to reduce the collision in the learned latent space and encourage the mapping from the latent space to the objective value to be Lipschitz continuous. LOCo takes in pairs of data points and penalizes those too close in the latent space compared to their target space distance. We provide a rigorous theoretical justification for LOCo by inspecting the regret of this dynamic-embedding-based Bayesian optimization algorithm, where the neural network is iteratively retrained with the regularizer. Our empirical results demonstrate the effectiveness of LOCo on several synthetic and real-world benchmark Bayesian optimization tasks.
The Efficacy of Pessimism in Asynchronous Q-Learning
Mar 14, 2022This paper is concerned with the asynchronous form of Q-learning, which applies a stochastic approximation scheme to Markovian data samples. Motivated by the recent advances in offline reinforcement learning, we develop an algorithmic framework that incorporates the principle of pessimism into asynchronous Q-learning, which penalizes infrequently-visited state-action pairs based on suitable lower confidence bounds (LCBs). This framework leads to, among other things, improved sample efficiency and enhanced adaptivity in the presence of near-expert data. Our approach permits the observed data in some important scenarios to cover only partial state-action space, which is in stark contrast to prior theory that requires uniform coverage of all state-action pairs. When coupled with the idea of variance reduction, asynchronous Q-learning with LCB penalization achieves near-optimal sample complexity, provided that the target accuracy level is small enough. In comparison, prior works were suboptimal in terms of the dependency on the effective horizon even when i.i.d. sampling is permitted. Our results deliver the first theoretical support for the use of pessimism principle in the presence of Markovian non-i.i.d. data.
Pessimistic Q-Learning for Offline Reinforcement Learning: Towards Optimal Sample Complexity
Feb 28, 2022

Offline or batch reinforcement learning seeks to learn a near-optimal policy using history data without active exploration of the environment. To counter the insufficient coverage and sample scarcity of many offline datasets, the principle of pessimism has been recently introduced to mitigate high bias of the estimated values. While pessimistic variants of model-based algorithms (e.g., value iteration with lower confidence bounds) have been theoretically investigated, their model-free counterparts -- which do not require explicit model estimation -- have not been adequately studied, especially in terms of sample efficiency. To address this inadequacy, we study a pessimistic variant of Q-learning in the context of finite-horizon Markov decision processes, and characterize its sample complexity under the single-policy concentrability assumption which does not require the full coverage of the state-action space. In addition, a variance-reduced pessimistic Q-learning algorithm is proposed to achieve near-optimal sample complexity. Altogether, this work highlights the efficiency of model-free algorithms in offline RL when used in conjunction with pessimism and variance reduction.
Rethinking Explainability as a Dialogue: A Practitioner's Perspective
Feb 03, 2022
As practitioners increasingly deploy machine learning models in critical domains such as health care, finance, and policy, it becomes vital to ensure that domain experts function effectively alongside these models. Explainability is one way to bridge the gap between human decision-makers and machine learning models. However, most of the existing work on explainability focuses on one-off, static explanations like feature importances or rule lists. These sorts of explanations may not be sufficient for many use cases that require dynamic, continuous discovery from stakeholders. In the literature, few works ask decision-makers about the utility of existing explanations and other desiderata they would like to see in an explanation going forward. In this work, we address this gap and carry out a study where we interview doctors, healthcare professionals, and policymakers about their needs and desires for explanations. Our study indicates that decision-makers would strongly prefer interactive explanations in the form of natural language dialogues. Domain experts wish to treat machine learning models as "another colleague", i.e., one who can be held accountable by asking why they made a particular decision through expressive and accessible natural language interactions. Considering these needs, we outline a set of five principles researchers should follow when designing interactive explanations as a starting place for future work. Further, we show why natural language dialogues satisfy these principles and are a desirable way to build interactive explanations. Next, we provide a design of a dialogue system for explainability and discuss the risks, trade-offs, and research opportunities of building these systems. Overall, we hope our work serves as a starting place for researchers and engineers to design interactive explainability systems.
LRSVRG-IMC: An SVRG-Based Algorithm for LowRank Inductive Matrix Completion
Jan 21, 2022
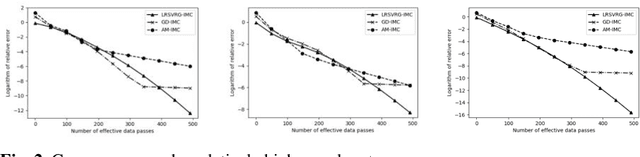
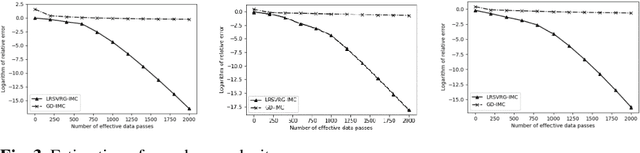
Low-rank inductive matrix completion (IMC) is currently widely used in IoT data completion, recommendation systems, and so on, as the side information in IMC has demonstrated great potential in reducing sample point remains a major obstacle for the convergence of the nonconvex solutions to IMC. What's more, carefully choosing the initial solution alone does not usually help remove the saddle points. To address this problem, we propose a stocastic variance reduction gradient-based algorithm called LRSVRG-IMC. LRSVRG-IMC can escape from the saddle points under various low-rank and sparse conditions with a properly chosen initial input. We also prove that LRSVVRG-IMC achieves both a linear convergence rate and a near-optimal sample complexity. The superiority and applicability of LRSVRG-IMC are verified via experiments on synthetic datasets.
BALanCe: Deep Bayesian Active Learning via Equivalence Class Annealing
Dec 27, 2021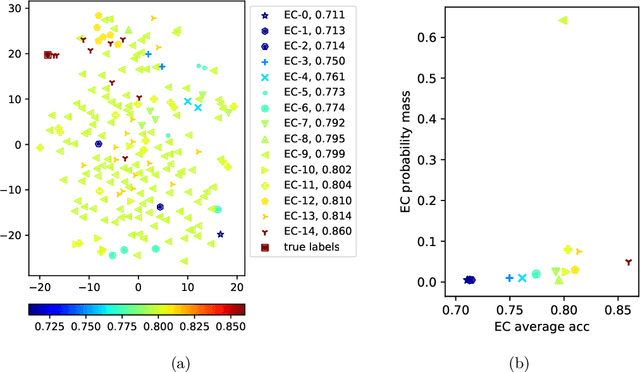

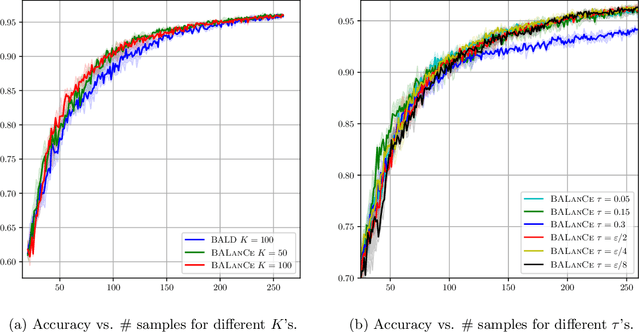
Active learning has demonstrated data efficiency in many fields. Existing active learning algorithms, especially in the context of deep Bayesian active models, rely heavily on the quality of uncertainty estimations of the model. However, such uncertainty estimates could be heavily biased, especially with limited and imbalanced training data. In this paper, we propose BALanCe, a Bayesian deep active learning framework that mitigates the effect of such biases. Concretely, BALanCe employs a novel acquisition function which leverages the structure captured by equivalence hypothesis classes and facilitates differentiation among different equivalence classes. Intuitively, each equivalence class consists of instantiations of deep models with similar predictions, and BALanCe adaptively adjusts the size of the equivalence classes as learning progresses. Besides the fully sequential setting, we further propose Batch-BALanCe -- a generalization of the sequential algorithm to the batched setting -- to efficiently select batches of training examples that are jointly effective for model improvement. We show that Batch-BALanCe achieves state-of-the-art performance on several benchmark datasets for active learning, and that both algorithms can effectively handle realistic challenges that often involve multi-class and imbalanced data.
Class-wise Thresholding for Detecting Out-of-Distribution Data
Nov 24, 2021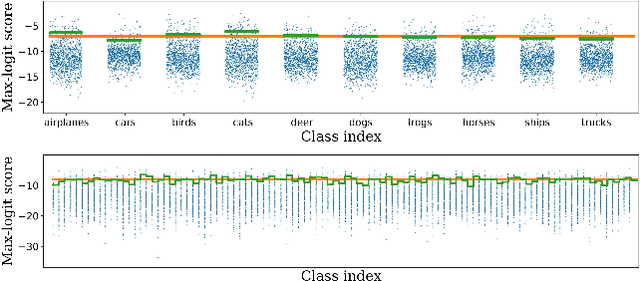

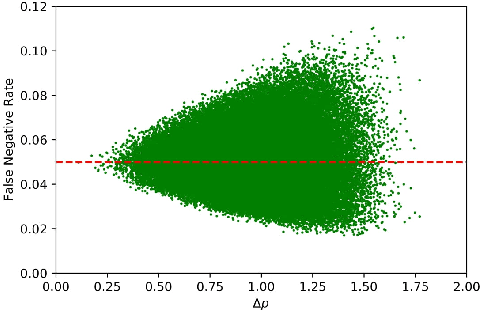
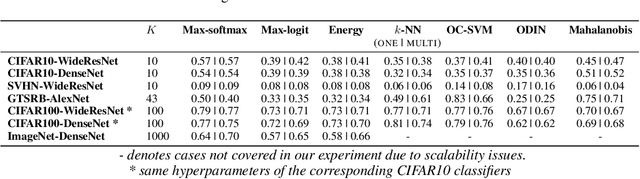
We consider the problem of detecting OoD(Out-of-Distribution) input data when using deep neural networks, and we propose a simple yet effective way to improve the robustness of several popular OoD detection methods against label shift. Our work is motivated by the observation that most existing OoD detection algorithms consider all training/test data as a whole, regardless of which class entry each input activates (inter-class differences). Through extensive experimentation, we have found that such practice leads to a detector whose performance is sensitive and vulnerable to label shift. To address this issue, we propose a class-wise thresholding scheme that can apply to most existing OoD detection algorithms and can maintain similar OoD detection performance even in the presence of label shift in the test distribution.