 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuxian Meng
Query-Based Named Entity Recognition
Aug 24, 2019

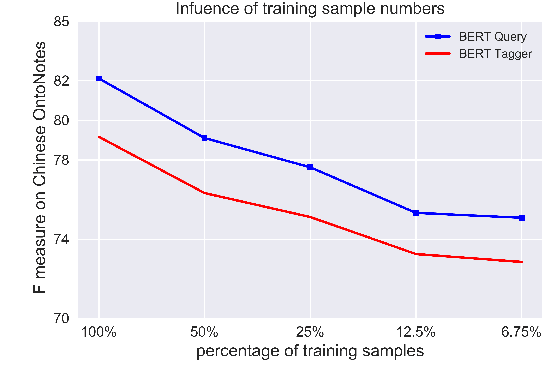
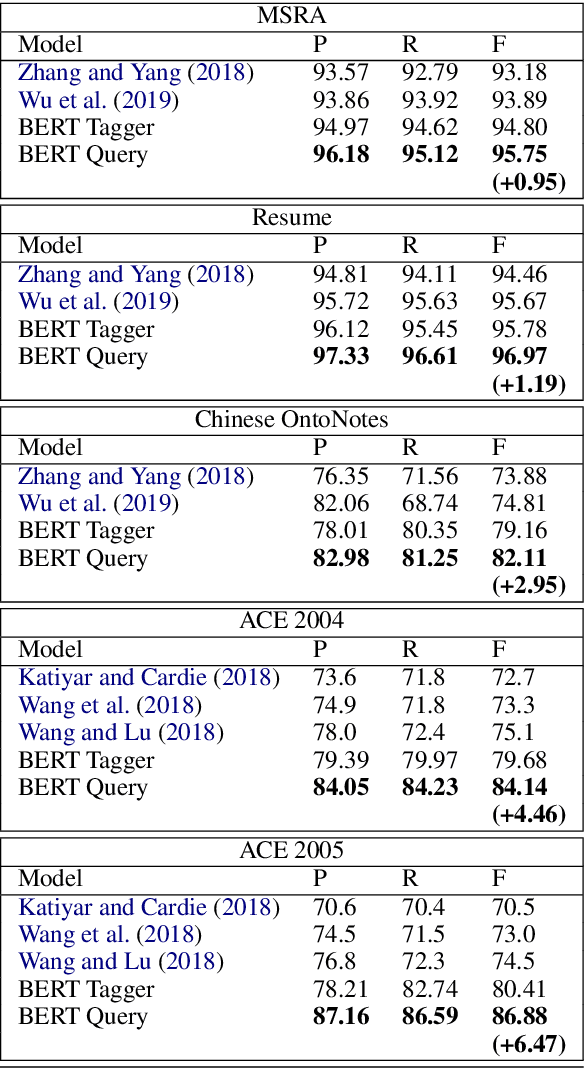
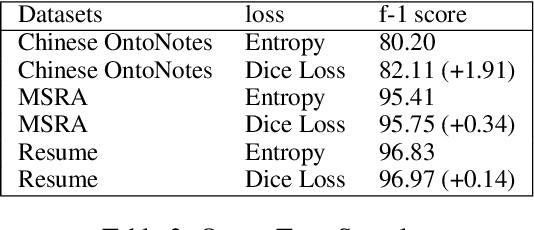
In this paper, we propose a new strategy for the task of named entity recognition (NER). We cast the task as a query-based machine reading comprehension task: e.g., the task of extracting entities with PER is formalized as answering the question of "which person is mentioned in the text ?". Such a strategy comes with the advantage that it solves the long-standing issue of handling overlapping or nested entities (the same token that participates in more than one entity categories) with sequence-labeling techniques for NER. Additionally, since the query encodes informative prior knowledge, this strategy facilitates the process of entity extraction, leading to better performances. We experiment the proposed model on five widely used NER datasets on English and Chinese, including MSRA, Resume, OntoNotes, ACE04 and ACE05. The proposed model sets new SOTA results on all of these datasets.
DSReg: Using Distant Supervision as a Regularizer
May 30, 2019
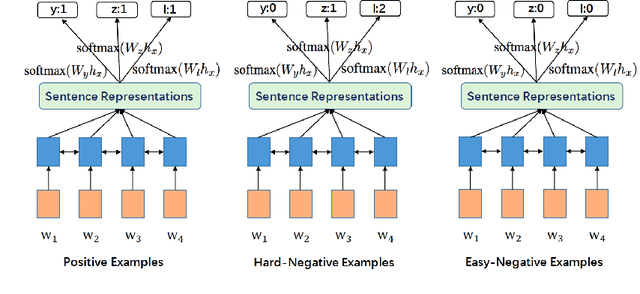
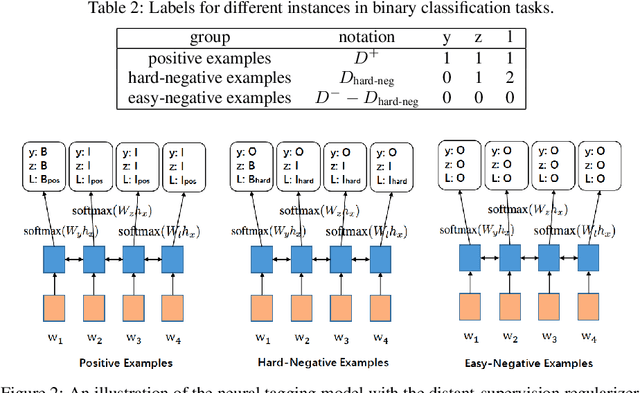
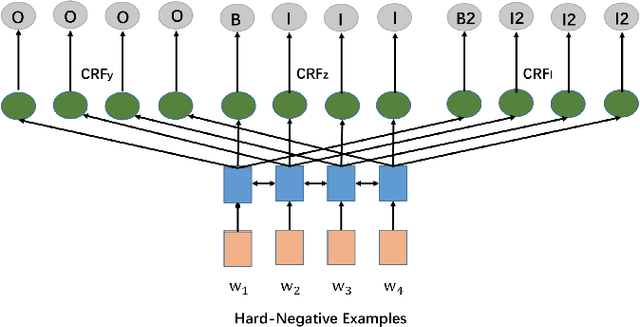
In this paper, we aim at tackling a general issue in NLP tasks where some of the negative examples are highly similar to the positive examples, i.e., hard-negative examples. We propose the distant supervision as a regularizer (DSReg) approach to tackle this issue. The original task is converted to a multi-task learning problem, in which distant supervision is used to retrieve hard-negative examples. The obtained hard-negative examples are then used as a regularizer. The original target objective of distinguishing positive examples from negative examples is jointly optimized with the auxiliary task objective of distinguishing softened positive (i.e., hard-negative examples plus positive examples) from easy-negative examples. In the neural context, this can be done by outputting the same representation from the last neural layer to different $softmax$ functions. Using this strategy, we can improve the performance of baseline models in a range of different NLP tasks, including text classification, sequence labeling and reading comprehension.
Is Word Segmentation Necessary for Deep Learning of Chinese Representations?
May 14, 2019
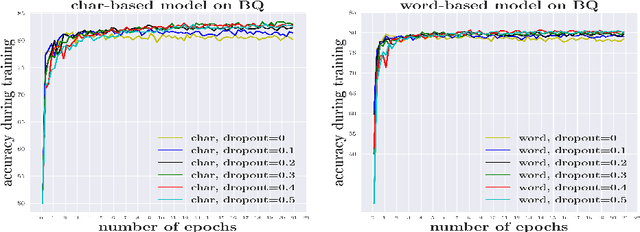

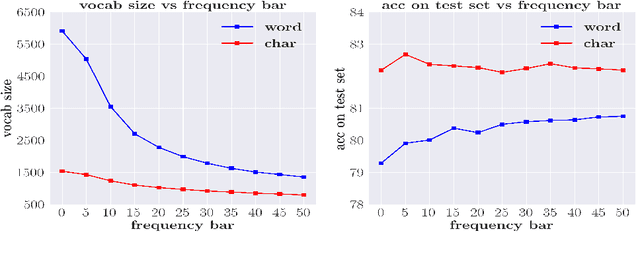
Segmenting a chunk of text into words is usually the first step of processing Chinese text, but its necessity has rarely been explored. In this paper, we ask the fundamental question of whether Chinese word segmentation (CWS) is necessary for deep learning-based Chinese Natural Language Processing. We benchmark neural word-based models which rely on word segmentation against neural char-based models which do not involve word segmentation in four end-to-end NLP benchmark tasks: language modeling, machine translation, sentence matching/paraphrase and text classification. Through direct comparisons between these two types of models, we find that char-based models consistently outperform word-based models. Based on these observations, we conduct comprehensive experiments to study why word-based models underperform char-based models in these deep learning-based NLP tasks. We show that it is because word-based models are more vulnerable to data sparsity and the presence of out-of-vocabulary (OOV) words, and thus more prone to overfitting. We hope this paper could encourage researchers in the community to rethink the necessity of word segmentation in deep learning-based Chinese Natural Language Processing. \footnote{Yuxian Meng and Xiaoya Li contributed equally to this paper.}
Glyce: Glyph-vectors for Chinese Character Representations
Jan 29, 2019

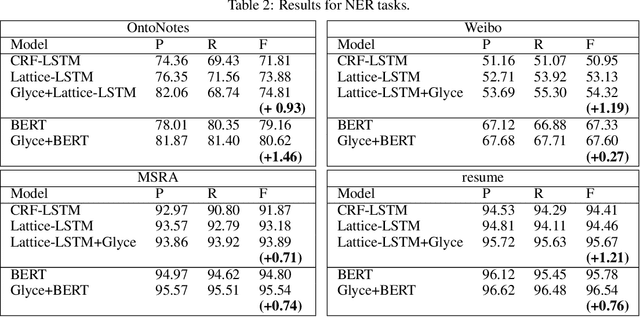
It is intuitive that NLP tasks for logographic languages like Chinese should benefit from the use of the glyph information in those languages. However, due to the lack of rich pictographic evidence in glyphs and the weak generalization ability of standard computer vision models on character data, an effective way to utilize the glyph information remains to be found. In this paper, we address this gap by presenting the Glyce, the glyph-vectors for Chinese character representations. We make three major innovations: (1) We use historical Chinese scripts (e.g., bronzeware script, seal script, traditional Chinese, etc) to enrich the pictographic evidence in characters; (2) We design CNN structures tailored to Chinese character image processing; and (3) We use image-classification as an auxiliary task in a multi-task learning setup to increase the model's ability to generalize. For the first time, we show that glyph-based models are able to consistently outperform word/char ID-based models in a wide range of Chinese NLP tasks. Using Glyce, we are able to achieve the state-of-the-art performances on 13 (almost all) Chinese NLP tasks, including (1) character-Level language modeling, (2) word-Level language modeling, (3) Chinese word segmentation, (4) name entity recognition, (5) part-of-speech tagging, (6) dependency parsing, (7) semantic role labeling, (8) sentence semantic similarity, (9) sentence intention identification, (10) Chinese-English machine translation, (11) sentiment analysis, (12) document classification and (13) discourse parsing