 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuxi Xie
Prompt Optimization via Adversarial In-Context Learning
Dec 05, 2023
We propose a new method, Adversarial In-Context Learning (adv-ICL), to optimize prompt for in-context learning (ICL) by employing one LLM as a generator, another as a discriminator, and a third as a prompt modifier. As in traditional adversarial learning, adv-ICL is implemented as a two-player game between the generator and discriminator, where the generator tries to generate realistic enough output to fool the discriminator. In each round, given an input prefixed by task instructions and several exemplars, the generator produces an output. The discriminator is then tasked with classifying the generator input-output pair as model-generated or real data. Based on the discriminator loss, the prompt modifier proposes possible edits to the generator and discriminator prompts, and the edits that most improve the adversarial loss are selected. We show that adv-ICL results in significant improvements over state-of-the-art prompt optimization techniques for both open and closed-source models on 11 generation and classification tasks including summarization, arithmetic reasoning, machine translation, data-to-text generation, and the MMLU and big-bench hard benchmarks. In addition, because our method uses pre-trained models and updates only prompts rather than model parameters, it is computationally efficient, easy to extend to any LLM and task, and effective in low-resource settings.
InstructCoder: Empowering Language Models for Code Editing
Oct 31, 2023Code editing encompasses a variety of pragmatic tasks that developers deal with daily. Despite its relevance and practical usefulness, automatic code editing remains an underexplored area in the evolution of deep learning models, partly due to data scarcity. In this work, we explore the use of large language models (LLMs) to edit code based on user instructions, covering a broad range of implicit tasks such as comment insertion, code optimization, and code refactoring. To facilitate this, we introduce InstructCoder, the first dataset designed to adapt LLMs for general-purpose code editing, containing highdiversity code-editing tasks. It consists of over 114,000 instruction-input-output triplets and covers multiple distinct code editing scenarios. The dataset is systematically expanded through an iterative process that commences with code editing data sourced from GitHub commits as seed tasks. Seed and generated tasks are used subsequently to prompt ChatGPT for more task data. Our experiments demonstrate that open-source LLMs fine-tuned on InstructCoder can edit code correctly based on users' instructions most of the time, exhibiting unprecedented code-editing performance levels. Such results suggest that proficient instruction-finetuning can lead to significant amelioration in code editing abilities. The dataset and the source code are available at https://github.com/qishenghu/CodeInstruct.
ECHo: Event Causality Inference via Human-centric Reasoning
May 24, 2023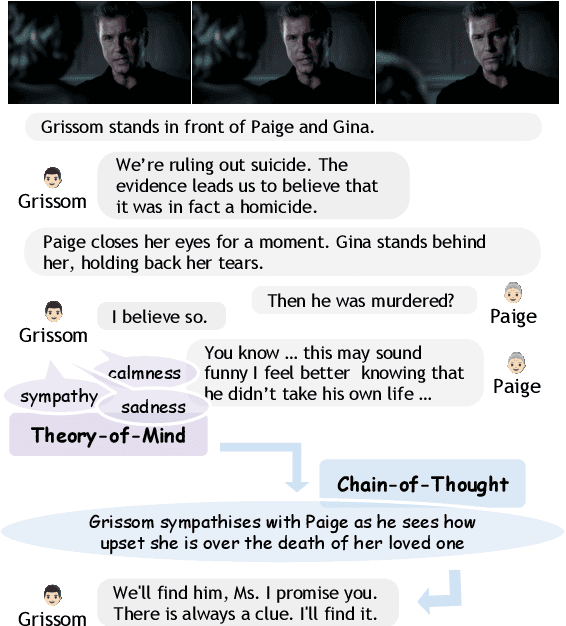
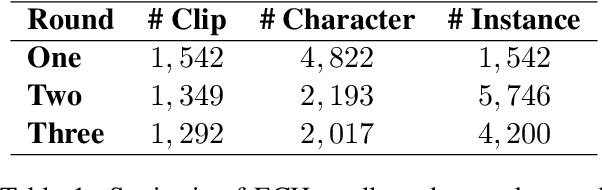
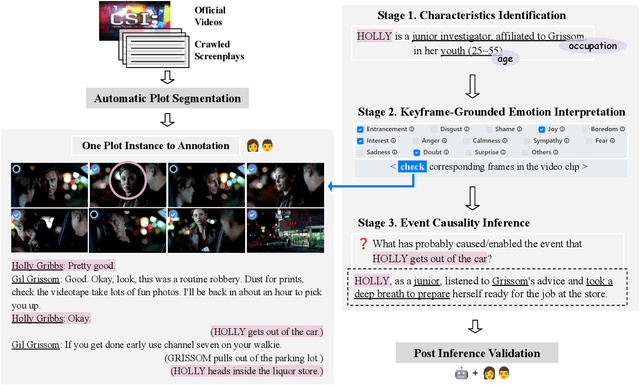
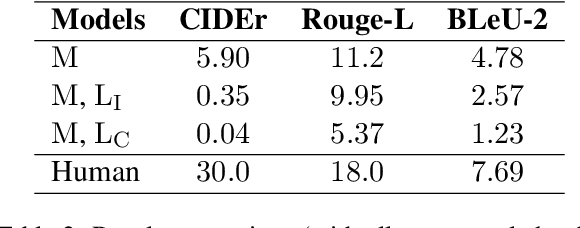
We introduce ECHo, a diagnostic dataset of event causality inference grounded in visual-and-linguistic social scenarios. ECHo employs real-world human-centric deductive information collected from crime drama, bridging the gap in multimodal reasoning towards higher social intelligence through the elicitation of intermediate Theory-of-Mind (ToM). We propose a unified framework aligned with the Chain-of-Thought (CoT) paradigm to assess the reasoning capability of current AI systems. This ToM-enhanced CoT pipeline can accommodate and integrate various large foundation models in zero-shot visual-and-linguistic understanding. With this framework, we scrutinize the advanced large language and multimodal models via three complementary human-centric ECHo tasks. Further analysis demonstrates ECHo as a challenging dataset to expose imperfections and inconsistencies in reasoning.
Automatic Model Selection with Large Language Models for Reasoning
May 23, 2023
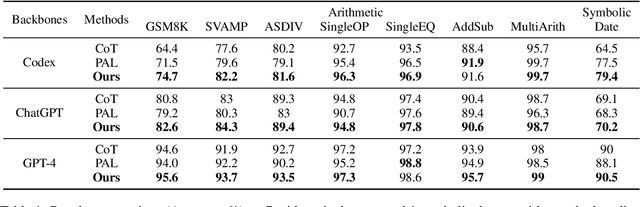
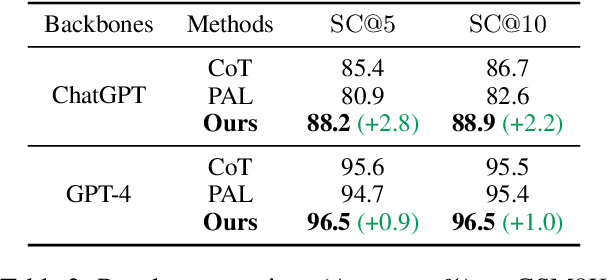
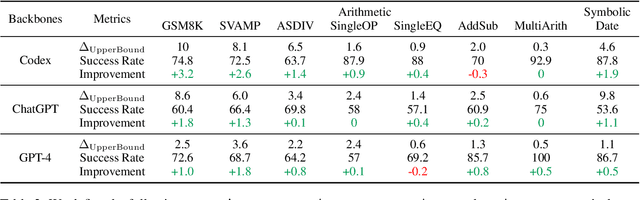
Chain-of-Thought and Program-Aided Language Models represent two distinct reasoning methods, each with its own strengths and weaknesses. We demonstrate that it is possible to combine the best of both worlds by using different models for different problems, employing a large language model (LLM) to perform model selection. Through a theoretical analysis, we discover that the performance improvement is determined by the differences between the combined methods and the success rate of choosing the correct model. On eight reasoning datasets, our proposed approach shows significant improvements. Furthermore, we achieve new state-of-the-art results on GSM8K and SVAMP with accuracies of 96.5% and 93.7%, respectively. Our code is publicly available at https://github.com/XuZhao0/Model-Selection-Reasoning.
Decomposition Enhances Reasoning via Self-Evaluation Guided Decoding
May 02, 2023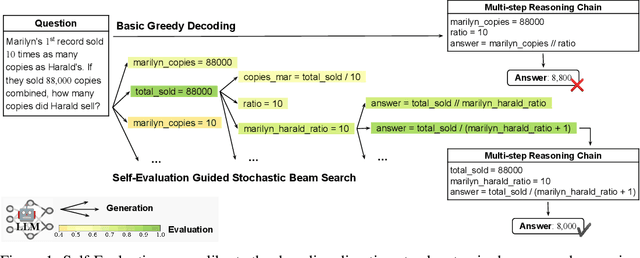
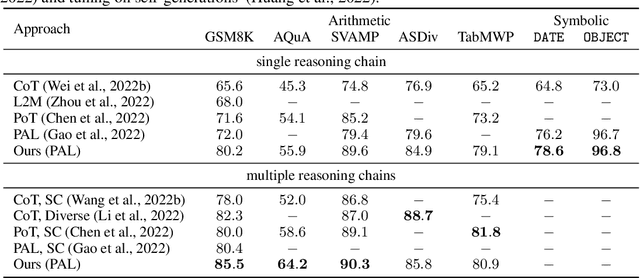
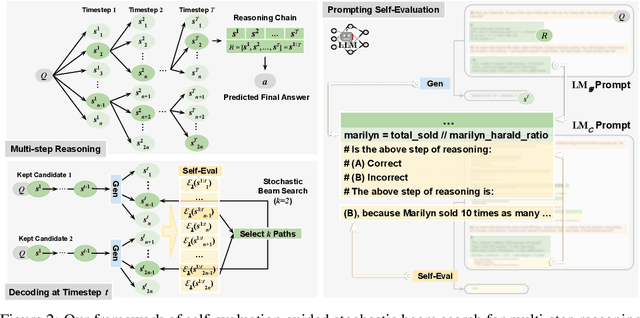
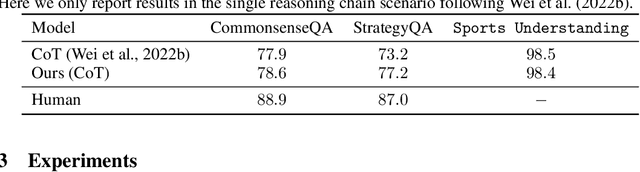
We endow Large Language Models (LLMs) with fine-grained self-evaluation to refine multi-step reasoning inference. We propose an effective prompting approach that integrates self-evaluation guidance through stochastic beam search. Our approach explores the reasoning search space using a well-calibrated automatic criterion. This enables an efficient search to produce higher-quality final predictions. With the self-evaluation guided stochastic beam search, we also balance the quality-diversity trade-off in the generation of reasoning chains. This allows our approach to adapt well with majority voting and surpass the corresponding Codex-backboned baselines by $6.34\%$, $9.56\%$, and $5.46\%$ on the GSM8K, AQuA, and StrategyQA benchmarks, respectively, in few-shot accuracy. Analysis of our decompositional reasoning finds it pinpoints logic failures and leads to higher consistency and robustness. Our code is publicly available at https://github.com/YuxiXie/SelfEval-Guided-Decoding.
Exploring Question-Specific Rewards for Generating Deep Questions
Nov 02, 2020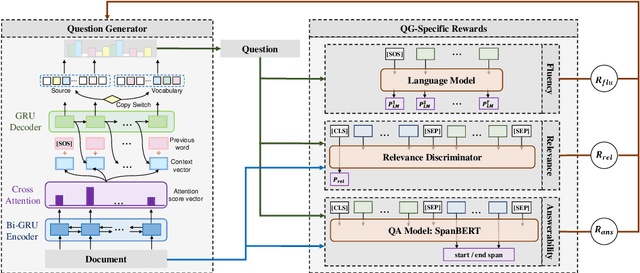
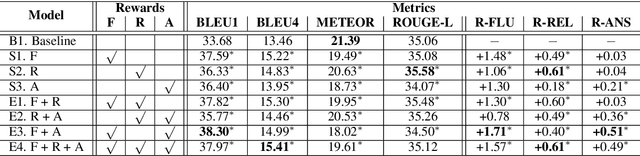
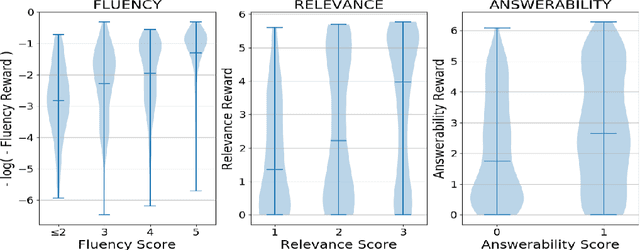
Recent question generation (QG) approaches often utilize the sequence-to-sequence framework (Seq2Seq) to optimize the log-likelihood of ground-truth questions using teacher forcing. However, this training objective is inconsistent with actual question quality, which is often reflected by certain global properties such as whether the question can be answered by the document. As such, we directly optimize for QG-specific objectives via reinforcement learning to improve question quality. We design three different rewards that target to improve the fluency, relevance, and answerability of generated questions. We conduct both automatic and human evaluations in addition to a thorough analysis to explore the effect of each QG-specific reward. We find that optimizing question-specific rewards generally leads to better performance in automatic evaluation metrics. However, only the rewards that correlate well with human judgement (e.g., relevance) lead to real improvement in question quality. Optimizing for the others, especially answerability, introduces incorrect bias to the model, resulting in poor question quality. Our code is publicly available at https://github.com/YuxiXie/RL-for-Question-Generation.
Semantic Graphs for Generating Deep Questions
Apr 27, 2020
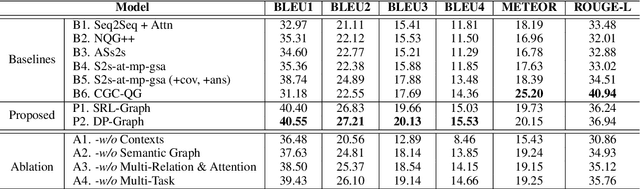
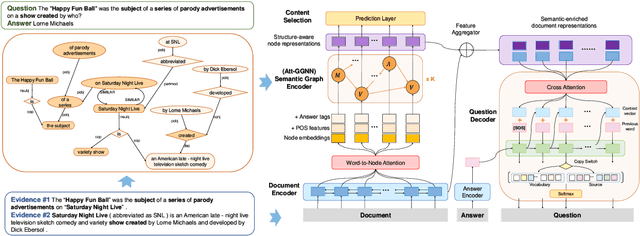
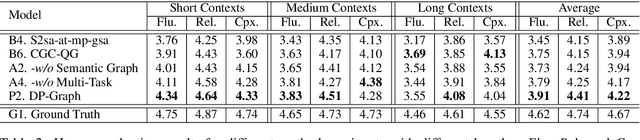
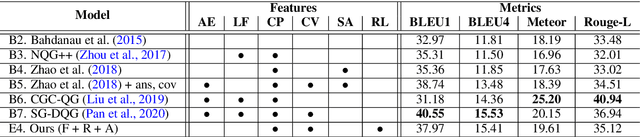
This paper proposes the problem of Deep Question Generation (DQG), which aims to generate complex questions that require reasoning over multiple pieces of information of the input passage. In order to capture the global structure of the document and facilitate reasoning, we propose a novel framework which first constructs a semantic-level graph for the input document and then encodes the semantic graph by introducing an attention-based GGNN (Att-GGNN). Afterwards, we fuse the document-level and graph-level representations to perform joint training of content selection and question decoding. On the HotpotQA deep-question centric dataset, our model greatly improves performance over questions requiring reasoning over multiple facts, leading to state-of-the-art performance. The code is publicly available at https://github.com/WING-NUS/SG-Deep-Question-Generation.
A Sketch-Based System for Semantic Parsing
Sep 12, 2019
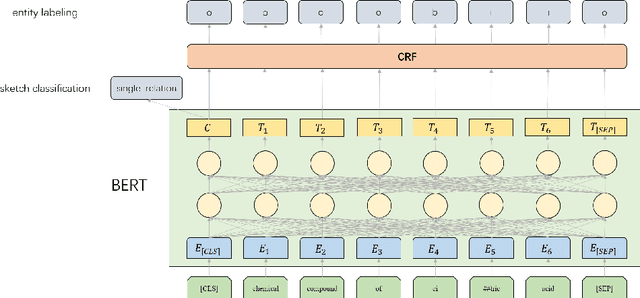


This paper presents our semantic parsing system for the evaluation task of open domain semantic parsing in NLPCC 2019. Many previous works formulate semantic parsing as a sequence-to-sequence(seq2seq) problem. Instead, we treat the task as a sketch-based problem in a coarse-to-fine(coarse2fine) fashion. The sketch is a high-level structure of the logical form exclusive of low-level details such as entities and predicates. In this way, we are able to optimize each part individually. Specifically, we decompose the process into three stages: the sketch classification determines the high-level structure while the entity labeling and the matching network fill in missing details. Moreover, we adopt the seq2seq method to evaluate logical form candidates from an overall perspective. The co-occurrence relationship between predicates and entities contribute to the reranking as well. Our submitted system achieves the exactly matching accuracy of 82.53% on full test set and 47.83% on hard test subset, which is the 3rd place in NLPCC 2019 Shared Task 2. After optimizations for parameters, network structure and sampling, the accuracy reaches 84.47% on full test set and 63.08% on hard test subset(Our code and data are available at https://github.com/zechagl/NLPCC2019-Semantic-Parsing).