 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAIS: Supervising and Augmenting Intermediate Steps for Document-Level Relation Extraction
Sep 24, 2021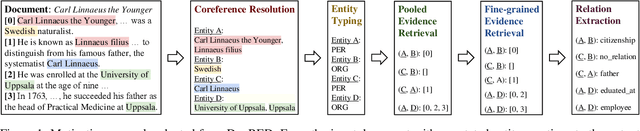

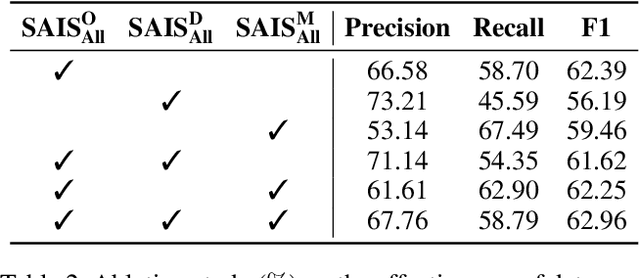
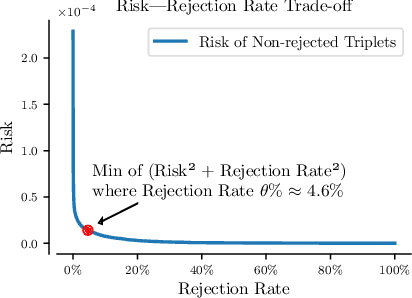
Stepping from sentence-level to document-level relation extraction, the research community confronts increasing text length and more complicated entity interactions. Consequently, it is more challenging to encode the key sources of information--relevant contexts and entity types. However, existing methods only implicitly learn to model these critical information sources while being trained for relation extraction. As a result, they suffer the problems of ineffective supervision and uninterpretable model predictions. In contrast, we propose to explicitly teach the model to capture relevant contexts and entity types by supervising and augmenting intermediate steps (SAIS) for relation extraction. Based on a broad spectrum of carefully designed tasks, our proposed SAIS method not only extracts relations of better quality due to more effective supervision, but also retrieves the corresponding supporting evidence more accurately so as to enhance interpretability. By assessing model uncertainty, SAIS further boosts the performance via evidence-based data augmentation and ensemble inference while reducing the computational cost. Eventually, SAIS delivers state-of-the-art relation extraction results on three benchmarks (DocRED, CDR, and GDA) and achieves 5.04% relative gains in F1 score compared to the runner-up in evidence retrieval on DocRED.
Eider: Evidence-enhanced Document-level Relation Extraction
Jun 16, 2021
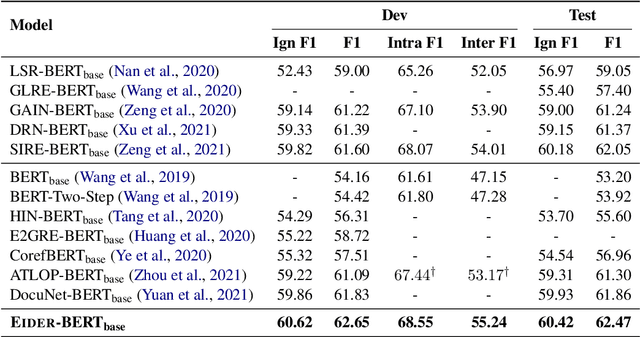
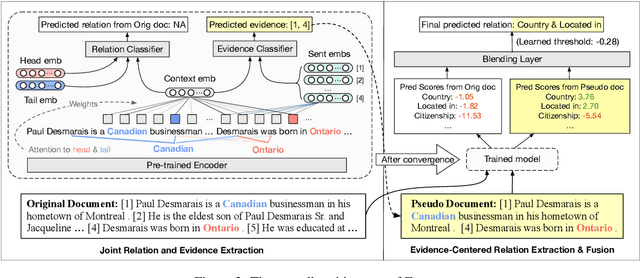

Document-level relation extraction (DocRE) aims at extracting the semantic relations among entity pairs in a document. In DocRE, a subset of the sentences in a document, called the evidence sentences, might be sufficient for predicting the relation between a specific entity pair. To make better use of the evidence sentences, in this paper, we propose a three-stage evidence-enhanced DocRE framework consisting of joint relation and evidence extraction, evidence-centered relation extraction (RE), and fusion of extraction results. We first jointly train an RE model with a simple and memory-efficient evidence extraction model. Then, we construct pseudo documents based on the extracted evidence sentences and run the RE model again. Finally, we fuse the extraction results of the first two stages using a blending layer and make a final prediction. Extensive experiments show that our proposed framework achieves state-of-the-art performance on the DocRED dataset, outperforming the second-best method by 0.76/0.82 Ign F1/F1. In particular, our method significantly improves the performance on inter-sentence relations by 1.23 Inter F1.
Extract, Denoise, and Enforce: Evaluating and Predicting Lexical Constraints for Conditional Text Generation
Apr 18, 2021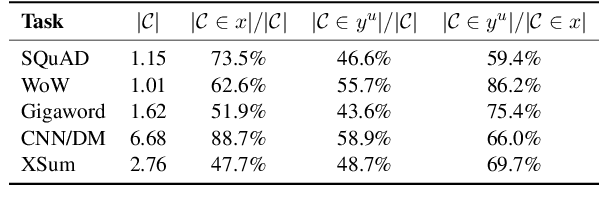
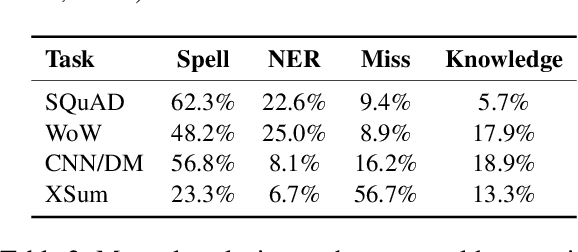
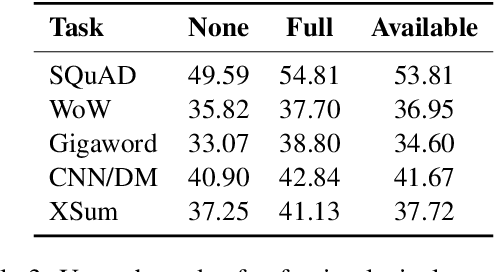
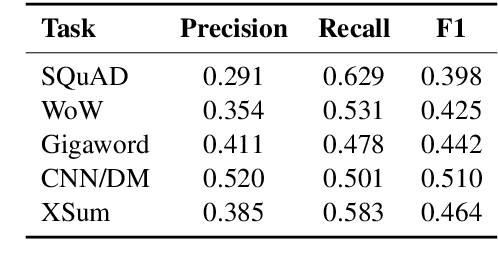
Recently, pre-trained language models (PLMs) have dominated conditional text generation tasks. Given the impressive performance and prevalence of the PLMs, it is seemingly natural to assume that they could figure out what to attend to in the input and what to include in the output via seq2seq learning without more guidance than the training input/output pairs. However, a rigorous study regarding the above assumption is still lacking. In this paper, we present a systematic analysis of conditional generation to study whether current PLMs are good enough for preserving important concepts in the input and to what extent explicitly guiding generation with lexical constraints is beneficial. We conduct extensive analytical experiments on a range of conditional generation tasks and try to answer in what scenarios guiding generation with lexical constraints works well and why. We then propose a framework for automatic constraint extraction, denoising, and enforcement that is shown to perform comparably or better than unconstrained generation. We hope that our findings could serve as a reference when determining whether it is appropriate and worthwhile to use explicit constraints for a specific task or dataset.\footnote{Our code is available at \url{https://github.com/morningmoni/LCGen-eval}.}
Taxonomy Completion via Triplet Matching Network
Jan 07, 2021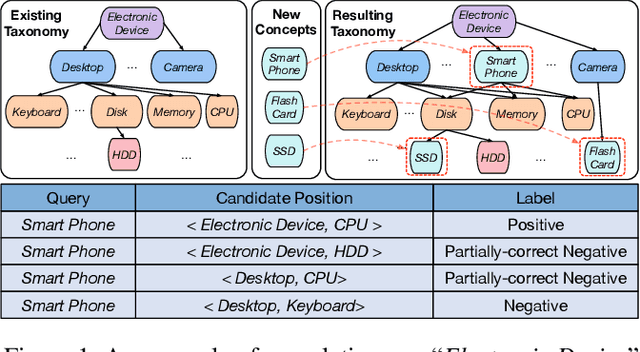
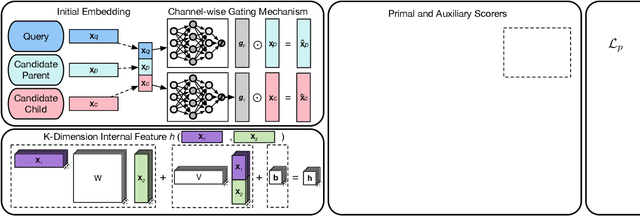
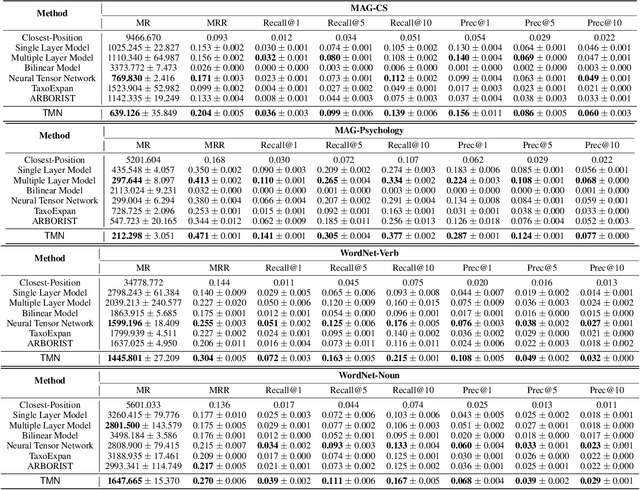
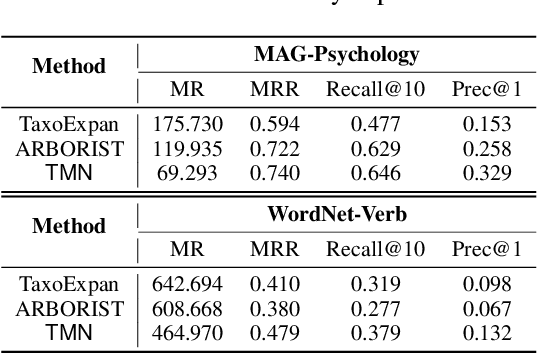
Automatically constructing taxonomy finds many applications in e-commerce and web search. One critical challenge is as data and business scope grow in real applications, new concepts are emerging and needed to be added to the existing taxonomy. Previous approaches focus on the taxonomy expansion, i.e. finding an appropriate hypernym concept from the taxonomy for a new query concept. In this paper, we formulate a new task, "taxonomy completion", by discovering both the hypernym and hyponym concepts for a query. We propose Triplet Matching Network (TMN), to find the appropriate <hypernym, hyponym> pairs for a given query concept. TMN consists of one primal scorer and multiple auxiliary scorers. These auxiliary scorers capture various fine-grained signals (e.g., query to hypernym or query to hyponym semantics), and the primal scorer makes a holistic prediction on <query, hypernym, hyponym> triplet based on the internal feature representations of all auxiliary scorers. Also, an innovative channel-wise gating mechanism that retains task-specific information in concept representations is introduced to further boost model performance. Experiments on four real-world large-scale datasets show that TMN achieves the best performance on both taxonomy completion task and the previous taxonomy expansion task, outperforming existing methods.
Reader-Guided Passage Reranking for Open-Domain Question Answering
Jan 01, 2021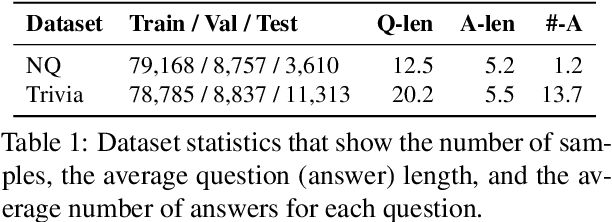
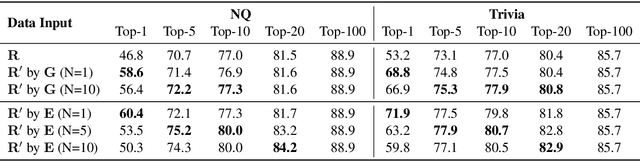
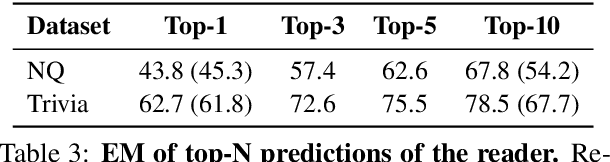
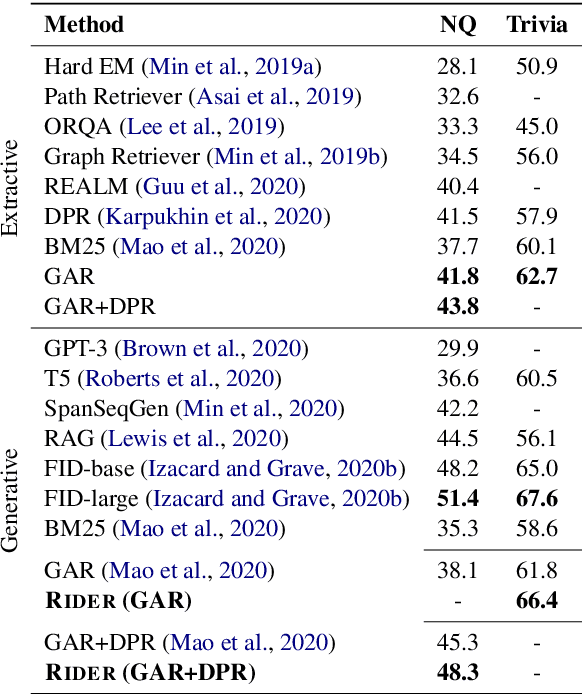
Current open-domain question answering (QA) systems often follow a Retriever-Reader (R2) architecture, where the retriever first retrieves relevant passages and the reader then reads the retrieved passages to form an answer. In this paper, we propose a simple and effective passage reranking method, Reader-guIDEd Reranker (Rider), which does not involve any training and reranks the retrieved passages solely based on the top predictions of the reader before reranking. We show that Rider, despite its simplicity, achieves 10 to 20 absolute gains in top-1 retrieval accuracy and 1 to 4 Exact Match (EM) score gains without refining the retriever or reader. In particular, Rider achieves 48.3 EM on the Natural Questions dataset and 66.4 on the TriviaQA dataset when only 1,024 tokens (7.8 passages on average) are used as the reader input.
Constrained Abstractive Summarization: Preserving Factual Consistency with Constrained Generation
Oct 24, 2020
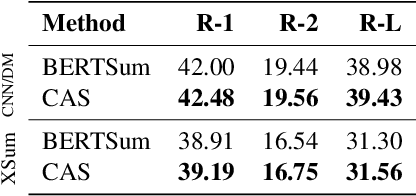
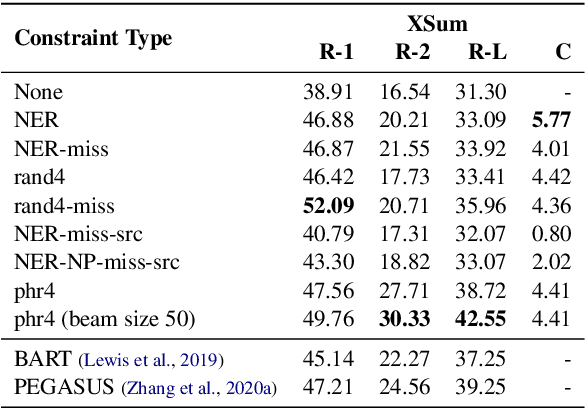
Summaries generated by abstractive summarization are supposed to only contain statements entailed by the source documents. However, state-of-the-art abstractive methods are still prone to hallucinate content inconsistent with the source documents. In this paper, we propose constrained abstractive summarization (CAS), a general setup that preserves the factual consistency of abstractive summarization by specifying tokens as constraints that must be present in the summary. We explore the feasibility of using lexically constrained decoding, a technique applicable to any abstractive method with beam search decoding, to fulfill CAS and conduct experiments in two scenarios: (1) Standard summarization without human involvement, where keyphrase extraction is used to extract constraints from source documents; (2) Interactive summarization with human feedback, which is simulated by taking missing tokens in the reference summaries as constraints. Automatic and human evaluations on two benchmark datasets demonstrate that CAS improves the quality of abstractive summaries, especially on factual consistency. In particular, we observe up to 11.2 ROUGE-2 gains when several ground-truth tokens are used as constraints in the interactive summarization scenario.
Multi-document Summarization with Maximal Marginal Relevance-guided Reinforcement Learning
Sep 30, 2020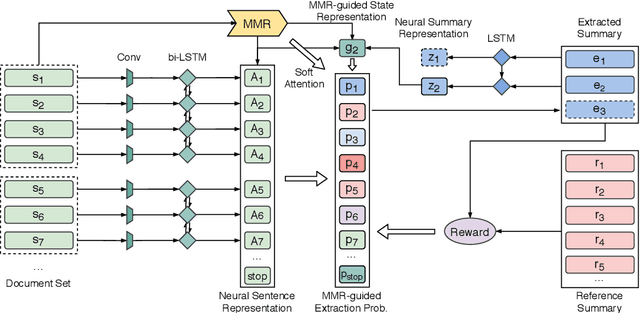
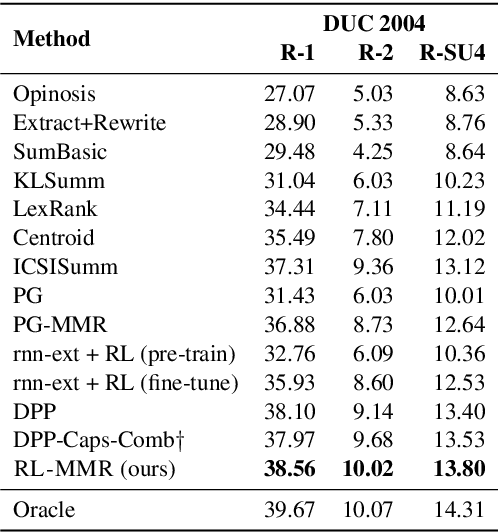
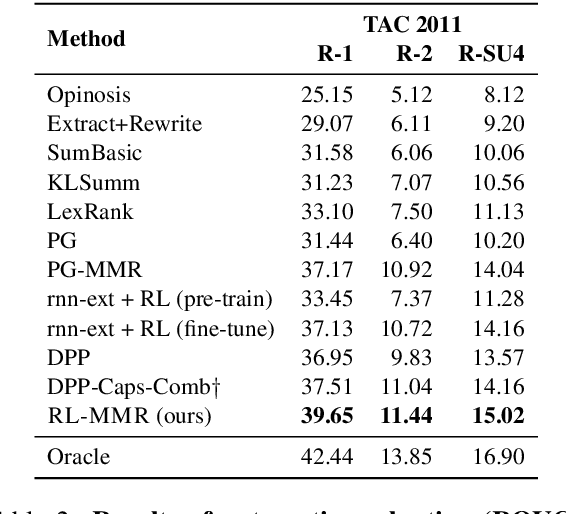
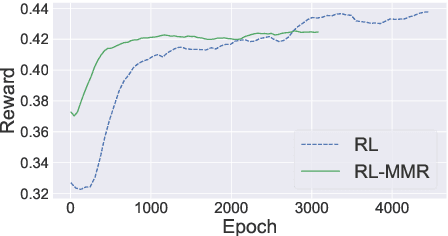
While neural sequence learning methods have made significant progress in single-document summarization (SDS), they produce unsatisfactory results on multi-document summarization (MDS). We observe two major challenges when adapting SDS advances to MDS: (1) MDS involves larger search space and yet more limited training data, setting obstacles for neural methods to learn adequate representations; (2) MDS needs to resolve higher information redundancy among the source documents, which SDS methods are less effective to handle. To close the gap, we present RL-MMR, Maximal Margin Relevance-guided Reinforcement Learning for MDS, which unifies advanced neural SDS methods and statistical measures used in classical MDS. RL-MMR casts MMR guidance on fewer promising candidates, which restrains the search space and thus leads to better representation learning. Additionally, the explicit redundancy measure in MMR helps the neural representation of the summary to better capture redundancy. Extensive experiments demonstrate that RL-MMR achieves state-of-the-art performance on benchmark MDS datasets. In particular, we show the benefits of incorporating MMR into end-to-end learning when adapting SDS to MDS in terms of both learning effectiveness and efficiency.
Generation-Augmented Retrieval for Open-domain Question Answering
Sep 17, 2020
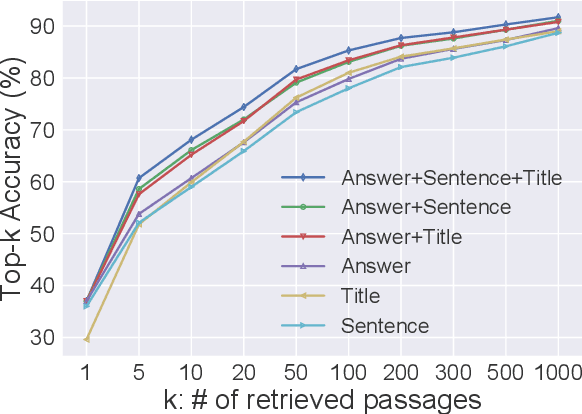
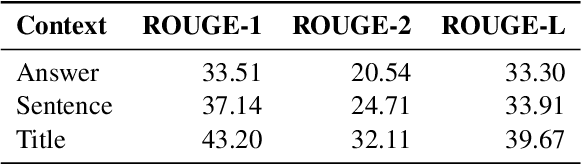
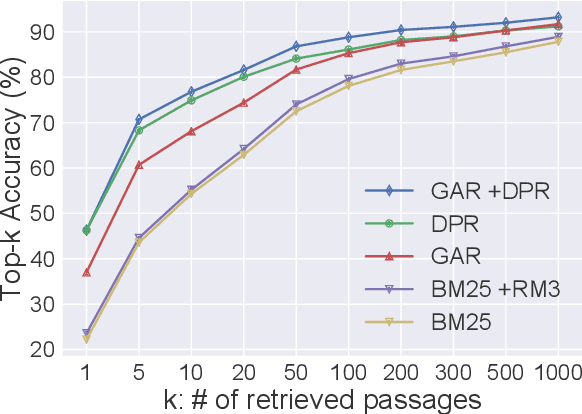
Conventional sparse retrieval methods such as TF-IDF and BM25 are simple and efficient, but solely rely on lexical overlap and fail to conduct semantic matching. Recent dense retrieval methods learn latent representations to tackle the lexical mismatch problem, while being more computationally expensive and sometimes insufficient for exact matching as they embed the entire text sequence into a single vector with limited capacity. In this paper, we present Generation-Augmented Retrieval (GAR), a query expansion method that augments a query with relevant contexts through text generation. We demonstrate on open-domain question answering (QA) that the generated contexts significantly enrich the semantics of the queries and thus GAR with sparse representations (BM25) achieves comparable or better performance than the current state-of-the-art dense method DPR \cite{karpukhin2020dense}. We show that generating various contexts of a query is beneficial as fusing their results consistently yields a better retrieval accuracy. Moreover, GAR achieves the state-of-the-art performance of extractive QA on the Natural Questions and TriviaQA datasets when equipped with an extractive reader.
AutoKnow: Self-Driving Knowledge Collection for Products of Thousands of Types
Jun 24, 2020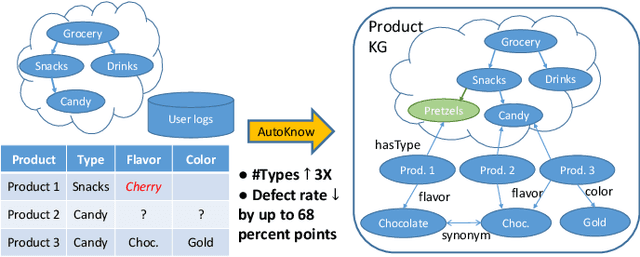

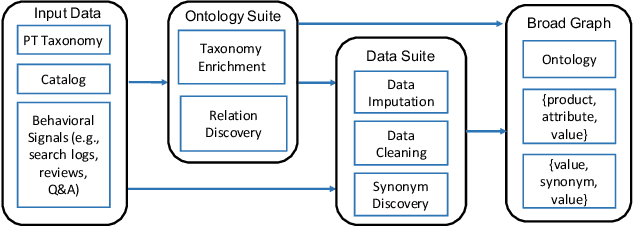
Can one build a knowledge graph (KG) for all products in the world? Knowledge graphs have firmly established themselves as valuable sources of information for search and question answering, and it is natural to wonder if a KG can contain information about products offered at online retail sites. There have been several successful examples of generic KGs, but organizing information about products poses many additional challenges, including sparsity and noise of structured data for products, complexity of the domain with millions of product types and thousands of attributes, heterogeneity across large number of categories, as well as large and constantly growing number of products. We describe AutoKnow, our automatic (self-driving) system that addresses these challenges. The system includes a suite of novel techniques for taxonomy construction, product property identification, knowledge extraction, anomaly detection, and synonym discovery. AutoKnow is (a) automatic, requiring little human intervention, (b) multi-scalable, scalable in multiple dimensions (many domains, many products, and many attributes), and (c) integrative, exploiting rich customer behavior logs. AutoKnow has been operational in collecting product knowledge for over 11K product types.
Octet: Online Catalog Taxonomy Enrichment with Self-Supervision
Jun 18, 2020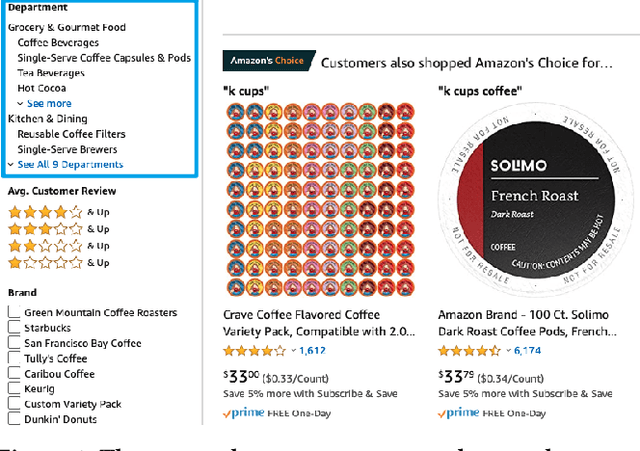
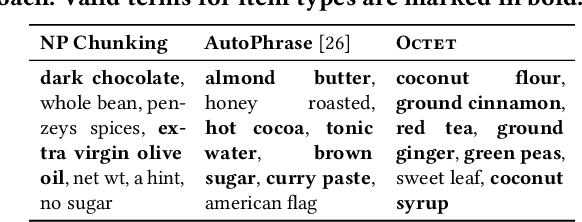
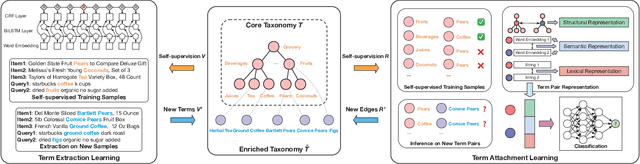
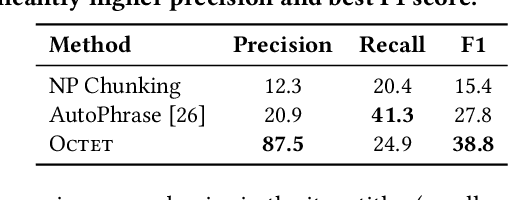
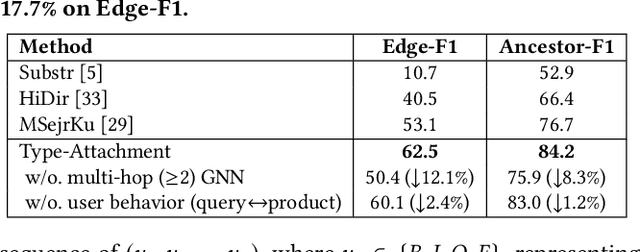
Taxonomies have found wide applications in various domains, especially online for item categorization, browsing, and search. Despite the prevalent use of online catalog taxonomies, most of them in practice are maintained by humans, which is labor-intensive and difficult to scale. While taxonomy construction from scratch is considerably studied in the literature, how to effectively enrich existing incomplete taxonomies remains an open yet important research question. Taxonomy enrichment not only requires the robustness to deal with emerging terms but also the consistency between existing taxonomy structure and new term attachment. In this paper, we present a self-supervised end-to-end framework, Octet, for Online Catalog Taxonomy EnrichmenT. Octet leverages heterogeneous information unique to online catalog taxonomies such as user queries, items, and their relations to the taxonomy nodes while requiring no other supervision than the existing taxonomies. We propose to distantly train a sequence labeling model for term extraction and employ graph neural networks (GNNs) to capture the taxonomy structure as well as the query-item-taxonomy interactions for term attachment. Extensive experiments in different online domains demonstrate the superiority of Octet over state-of-the-art methods via both automatic and human evaluations. Notably, Octet enriches an online catalog taxonomy in production to 2 times larger in the open-world evaluation.