 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Adversarial Perturbation in Input Embedding Space for Text
May 08, 2018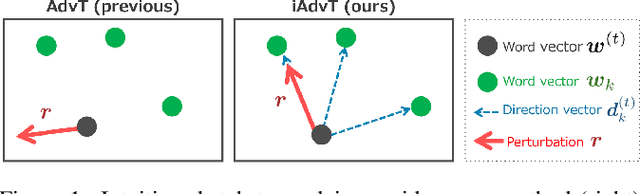
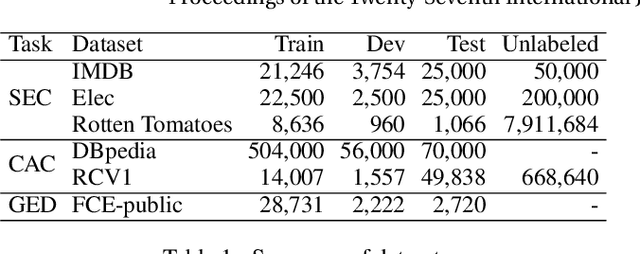
Following great success in the image processing field, the idea of adversarial training has been applied to tasks in the natural language processing (NLP) field. One promising approach directly applies adversarial training developed in the image processing field to the input word embedding space instead of the discrete input space of texts. However, this approach abandons such interpretability as generating adversarial texts to significantly improve the performance of NLP tasks. This paper restores interpretability to such methods by restricting the directions of perturbations toward the existing words in the input embedding space. As a result, we can straightforwardly reconstruct each input with perturbations to an actual text by considering the perturbations to be the replacement of words in the sentence while maintaining or even improving the task performance.
* 8 pages, 4 figures
Knowledge Transfer for Out-of-Knowledge-Base Entities: A Graph Neural Network Approach
Jun 20, 2017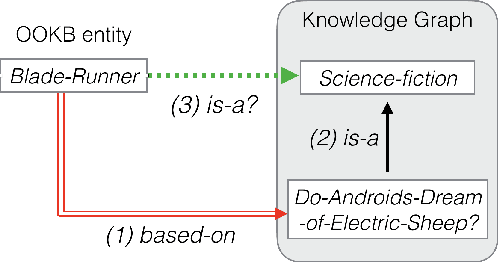
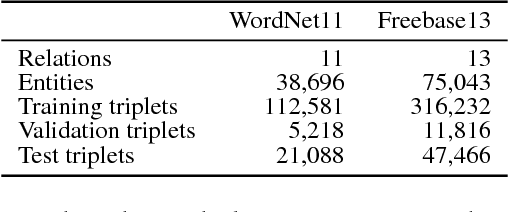
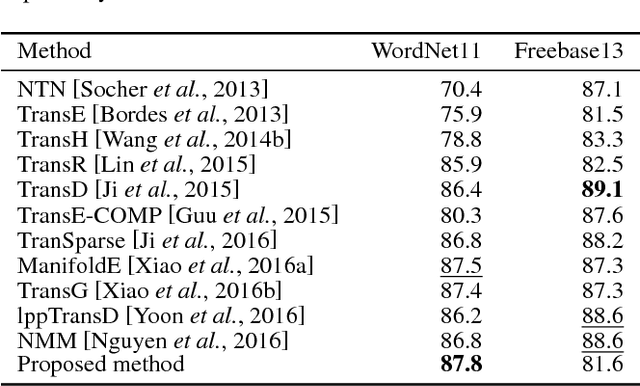
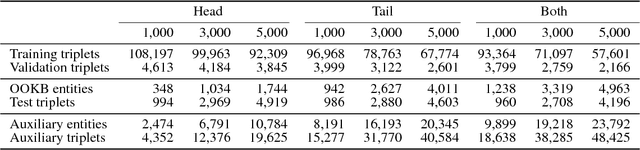
Knowledge base completion (KBC) aims to predict missing information in a knowledge base.In this paper, we address the out-of-knowledge-base (OOKB) entity problem in KBC:how to answer queries concerning test entities not observed at training time. Existing embedding-based KBC models assume that all test entities are available at training time, making it unclear how to obtain embeddings for new entities without costly retraining. To solve the OOKB entity problem without retraining, we use graph neural networks (Graph-NNs) to compute the embeddings of OOKB entities, exploiting the limited auxiliary knowledge provided at test time.The experimental results show the effectiveness of our proposed model in the OOKB setting.Additionally, in the standard KBC setting in which OOKB entities are not involved, our model achieves state-of-the-art performance on the WordNet dataset. The code and dataset are available at https://github.com/takuo-h/GNN-for-OOKB
A* CCG Parsing with a Supertag and Dependency Factored Model
Apr 23, 2017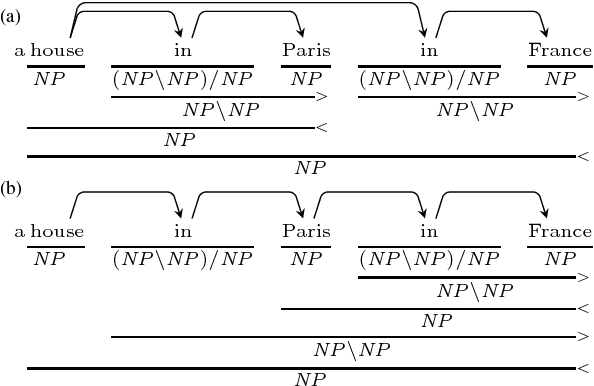
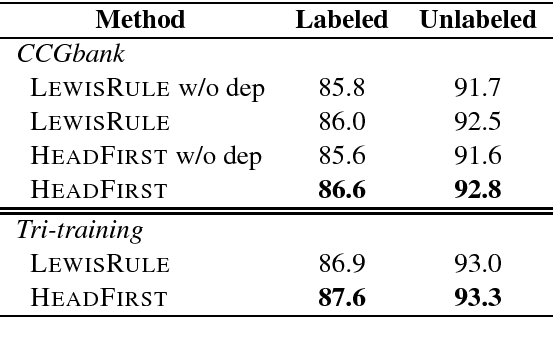
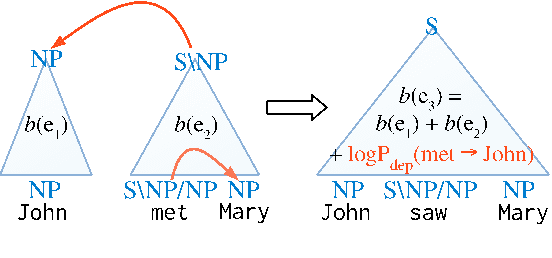
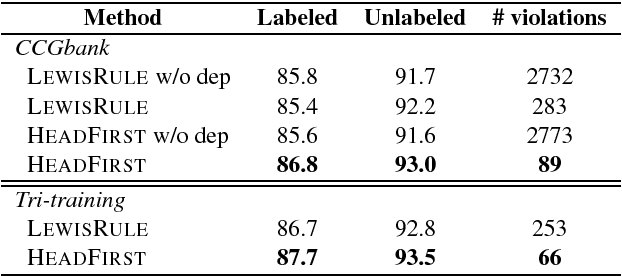
We propose a new A* CCG parsing model in which the probability of a tree is decomposed into factors of CCG categories and its syntactic dependencies both defined on bi-directional LSTMs. Our factored model allows the precomputation of all probabilities and runs very efficiently, while modeling sentence structures explicitly via dependencies. Our model achieves the state-of-the-art results on English and Japanese CCG parsing.
An Algebraic Formalization of Forward and Forward-backward Algorithms
Feb 22, 2017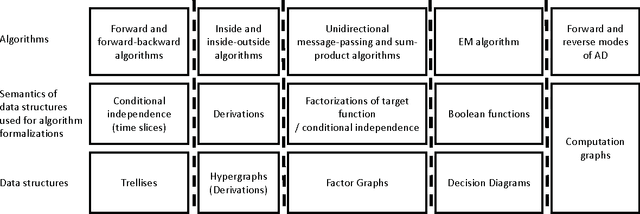
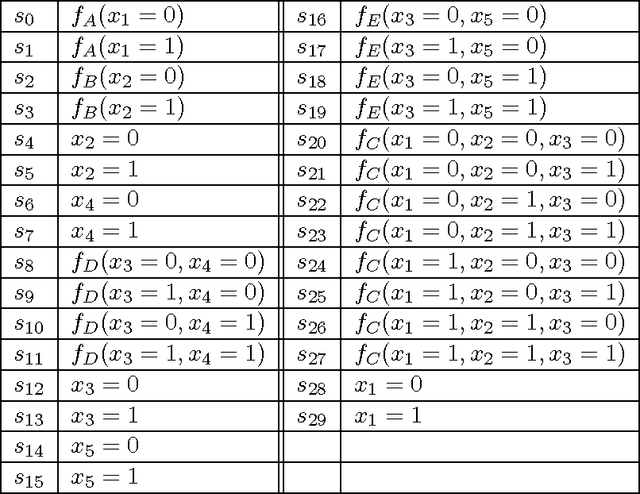
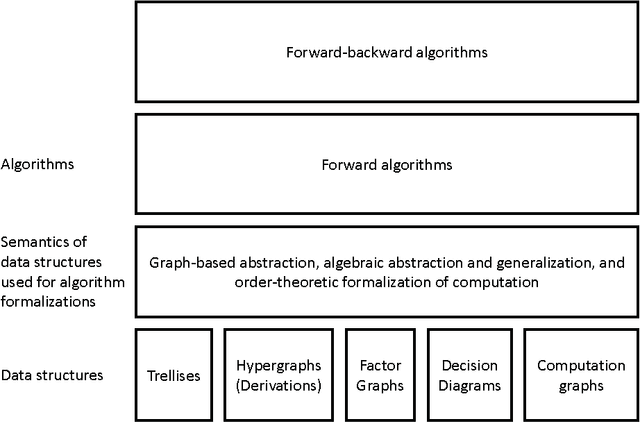
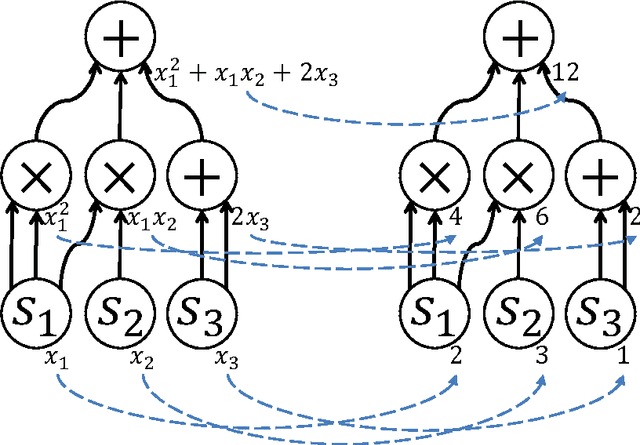
In this paper, we propose an algebraic formalization of the two important classes of dynamic programming algorithms called forward and forward-backward algorithms. They are generalized extensively in this study so that a wide range of other existing algorithms is subsumed. Forward algorithms generalized in this study subsume the ordinary forward algorithm on trellises for sequence labeling, the inside algorithm on derivation forests for CYK parsing, a unidirectional message passing on acyclic factor graphs, the forward mode of automatic differentiation on computation graphs with addition and multiplication, and so on. In addition, we reveal algebraic structures underlying complicated computation with forward algorithms. By the aid of the revealed algebraic structures, we also propose a systematic framework to design complicated variants of forward algorithms. Forward-backward algorithms generalized in this study subsume the ordinary forward-backward algorithm on trellises for sequence labeling, the inside-outside algorithm on derivation forests for CYK parsing, the sum-product algorithm on acyclic factor graphs, the reverse mode of automatic differentiation (a.k.a. back propagation) on computation graphs with addition and multiplication, and so on. We also propose an algebraic characterization of what can be computed by forward-backward algorithms and elucidate the relationship between forward and forward-backward algorithms.
Dependency Parsing with LSTMs: An Empirical Evaluation
Jun 30, 2016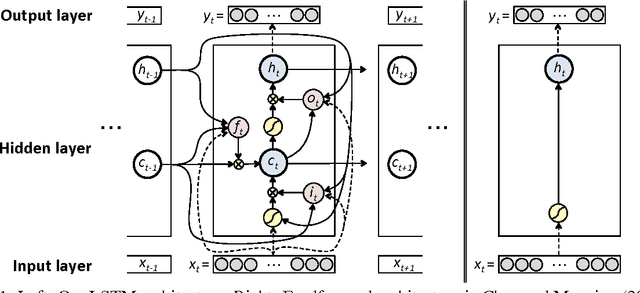
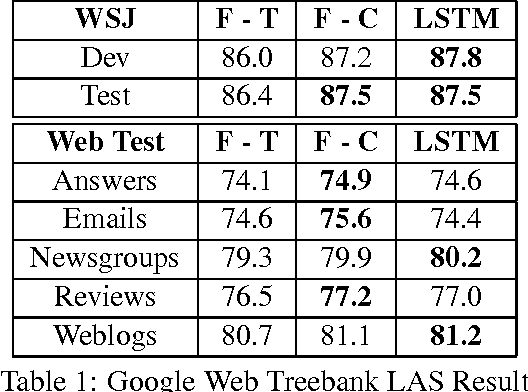
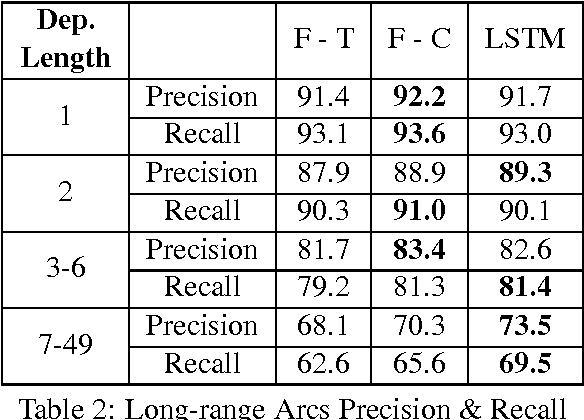
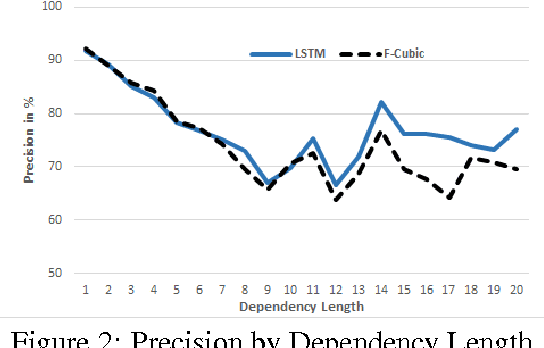
We propose a transition-based dependency parser using Recurrent Neural Networks with Long Short-Term Memory (LSTM) units. This extends the feedforward neural network parser of Chen and Manning (2014) and enables modelling of entire sequences of shift/reduce transition decisions. On the Google Web Treebank, our LSTM parser is competitive with the best feedforward parser on overall accuracy and notably achieves more than 3% improvement for long-range dependencies, which has proved difficult for previous transition-based parsers due to error propagation and limited context information. Our findings additionally suggest that dropout regularisation on the embedding layer is crucial to improve the LSTM's generalisation.
Ridge Regression, Hubness, and Zero-Shot Learning
Jul 03, 2015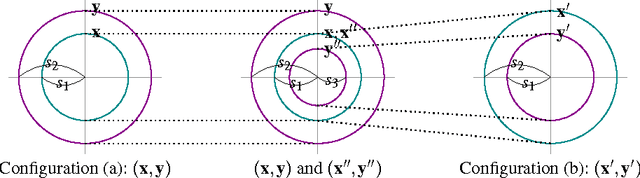
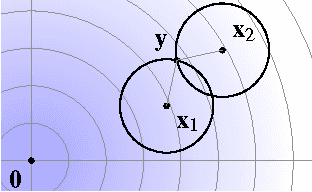
This paper discusses the effect of hubness in zero-shot learning, when ridge regression is used to find a mapping between the example space to the label space. Contrary to the existing approach, which attempts to find a mapping from the example space to the label space, we show that mapping labels into the example space is desirable to suppress the emergence of hubs in the subsequent nearest neighbor search step. Assuming a simple data model, we prove that the proposed approach indeed reduces hubness. This was verified empirically on the tasks of bilingual lexicon extraction and image labeling: hubness was reduced with both of these tasks and the accuracy was improved accordingly.
Japanese-Spanish Thesaurus Construction Using English as a Pivot
Mar 06, 2013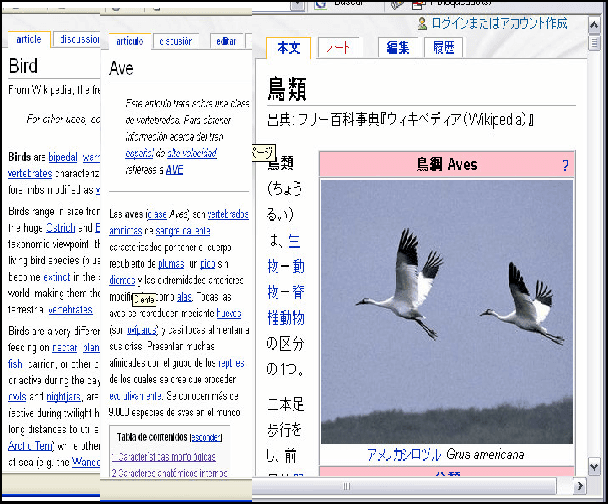
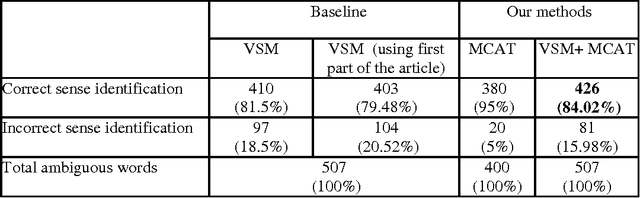
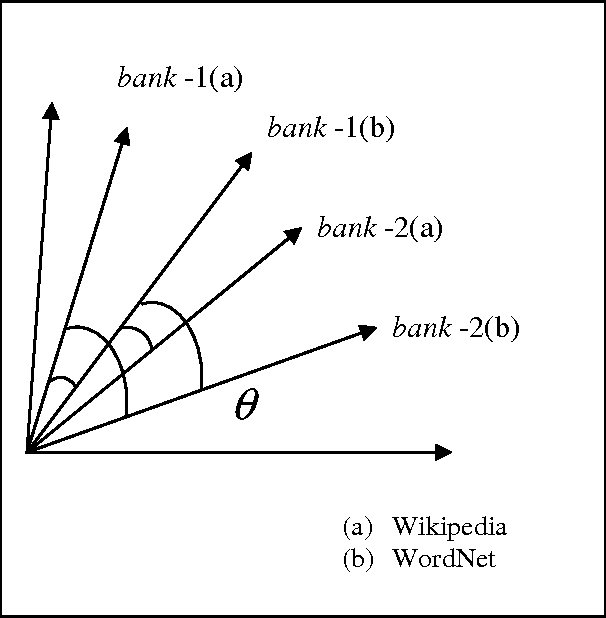
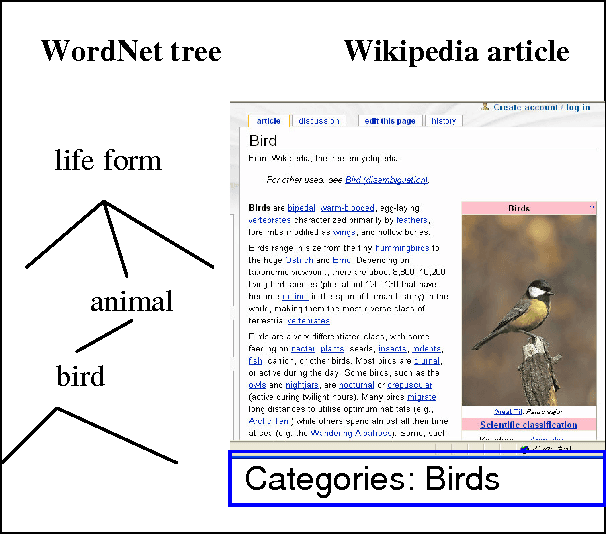
We present the results of research with the goal of automatically creating a multilingual thesaurus based on the freely available resources of Wikipedia and WordNet. Our goal is to increase resources for natural language processing tasks such as machine translation targeting the Japanese-Spanish language pair. Given the scarcity of resources, we use existing English resources as a pivot for creating a trilingual Japanese-Spanish-English thesaurus. Our approach consists of extracting the translation tuples from Wikipedia, disambiguating them by mapping them to WordNet word senses. We present results comparing two methods of disambiguation, the first using VSM on Wikipedia article texts and WordNet definitions, and the second using categorical information extracted from Wikipedia, We find that mixing the two methods produces favorable results. Using the proposed method, we have constructed a multilingual Spanish-Japanese-English thesaurus consisting of 25,375 entries. The same method can be applied to any pair of languages that are linked to English in Wikipedia.
A Rule-Based Approach For Aligning Japanese-Spanish Sentences From A Comparable Corpora
Nov 19, 2012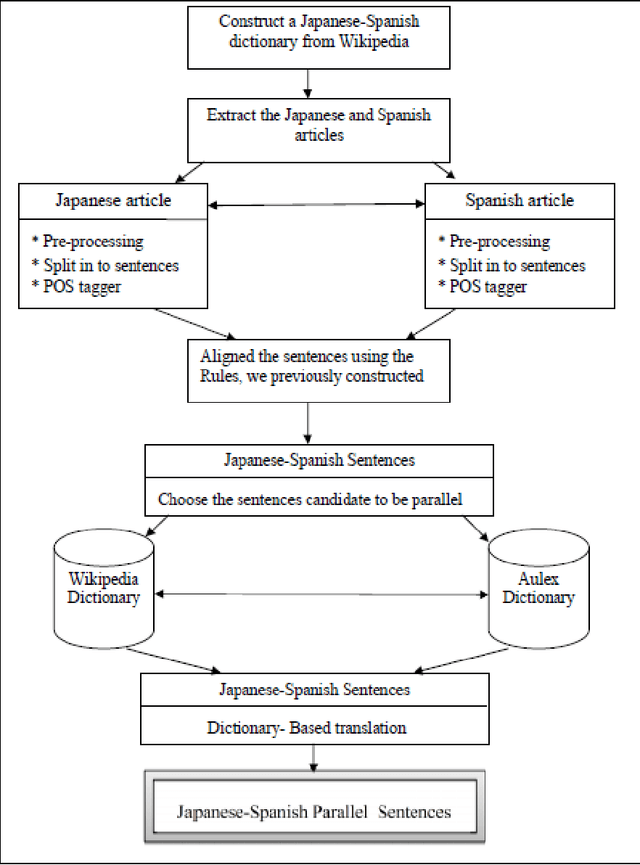
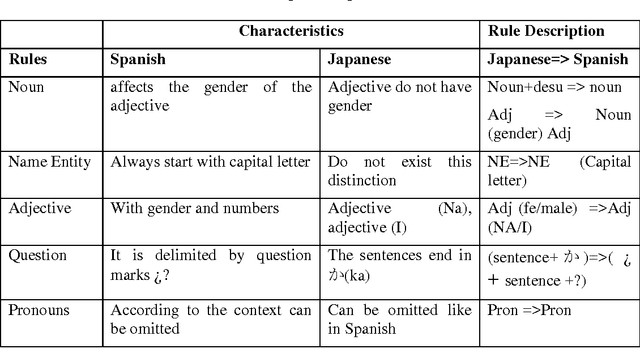
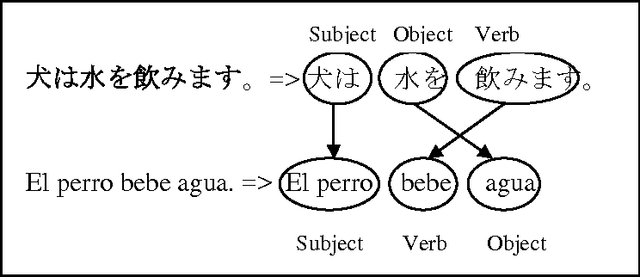

The performance of a Statistical Machine Translation System (SMT) system is proportionally directed to the quality and length of the parallel corpus it uses. However for some pair of languages there is a considerable lack of them. The long term goal is to construct a Japanese-Spanish parallel corpus to be used for SMT, whereas, there are a lack of useful Japanese-Spanish parallel Corpus. To address this problem, In this study we proposed a method for extracting Japanese-Spanish Parallel Sentences from Wikipedia using POS tagging and Rule-Based approach. The main focus of this approach is the syntactic features of both languages. Human evaluation was performed over a sample and shows promising results, in comparison with the baseline.