 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuhang Song
Learning on Arbitrary Graph Topologies via Predictive Coding
Feb 05, 2022


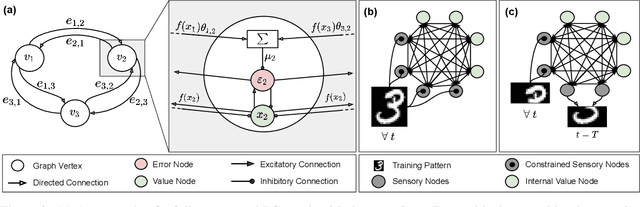

Training with backpropagation (BP) in standard deep learning consists of two main steps: a forward pass that maps a data point to its prediction, and a backward pass that propagates the error of this prediction back through the network. This process is highly effective when the goal is to minimize a specific objective function. However, it does not allow training on networks with cyclic or backward connections. This is an obstacle to reaching brain-like capabilities, as the highly complex heterarchical structure of the neural connections in the neocortex are potentially fundamental for its effectiveness. In this paper, we show how predictive coding (PC), a theory of information processing in the cortex, can be used to perform inference and learning on arbitrary graph topologies. We experimentally show how this formulation, called PC graphs, can be used to flexibly perform different tasks with the same network by simply stimulating specific neurons, and investigate how the topology of the graph influences the final performance. We conclude by comparing against simple baselines trained~with~BP.
Associative Memories via Predictive Coding
Sep 16, 2021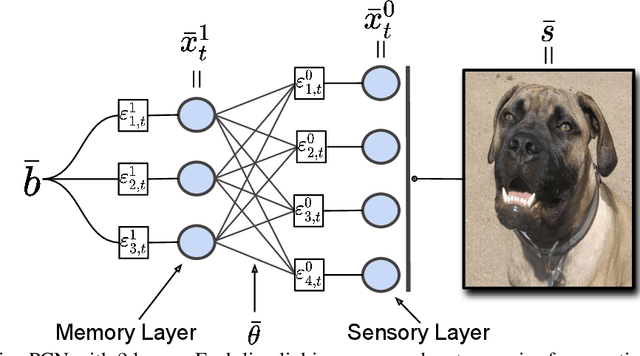
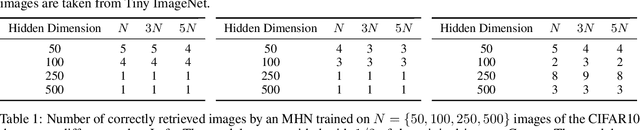
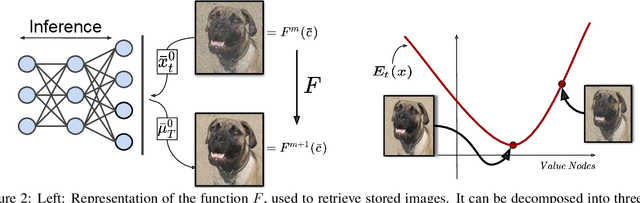
Associative memories in the brain receive and store patterns of activity registered by the sensory neurons, and are able to retrieve them when necessary. Due to their importance in human intelligence, computational models of associative memories have been developed for several decades now. They include autoassociative memories, which allow for storing data points and retrieving a stored data point $s$ when provided with a noisy or partial variant of $s$, and heteroassociative memories, able to store and recall multi-modal data. In this paper, we present a novel neural model for realizing associative memories, based on a hierarchical generative network that receives external stimuli via sensory neurons. This model is trained using predictive coding, an error-based learning algorithm inspired by information processing in the cortex. To test the capabilities of this model, we perform multiple retrieval experiments from both corrupted and incomplete data points. In an extensive comparison, we show that this new model outperforms in retrieval accuracy and robustness popular associative memory models, such as autoencoders trained via backpropagation, and modern Hopfield networks. In particular, in completing partial data points, our model achieves remarkable results on natural image datasets, such as ImageNet, with a surprisingly high accuracy, even when only a tiny fraction of pixels of the original images is presented. Furthermore, we show that this method is able to handle multi-modal data, retrieving images from descriptions, and vice versa. We conclude by discussing the possible impact of this work in the neuroscience community, by showing that our model provides a plausible framework to study learning and retrieval of memories in the brain, as it closely mimics the behavior of the hippocampus as a memory index and generative model.
Predictive Coding Can Do Exact Backpropagation on Any Neural Network
Mar 08, 2021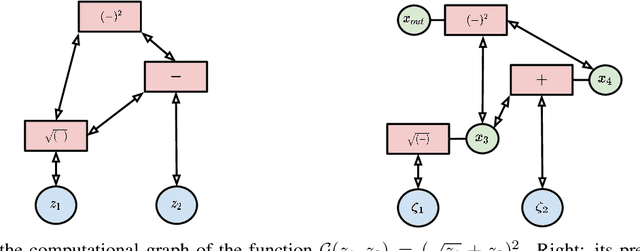
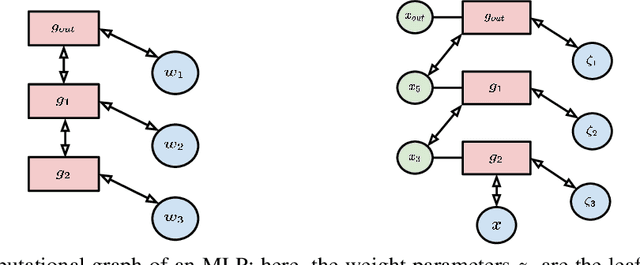

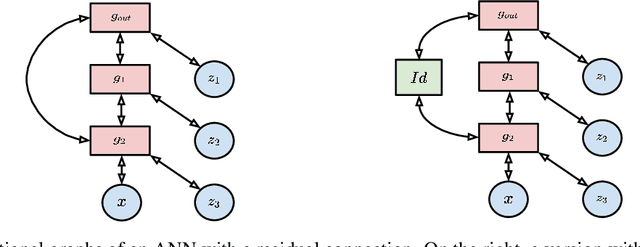
Intersecting neuroscience and deep learning has brought benefits and developments to both fields for several decades, which help to both understand how learning works in the brain, and to achieve the state-of-the-art performances in different AI benchmarks. Backpropagation (BP) is the most widely adopted method for the training of artificial neural networks, which, however, is often criticized for its biological implausibility (e.g., lack of local update rules for the parameters). Therefore, biologically plausible learning methods (e.g., inference learning (IL)) that rely on predictive coding (a framework for describing information processing in the brain) are increasingly studied. Recent works prove that IL can approximate BP up to a certain margin on multilayer perceptrons (MLPs), and asymptotically on any other complex model, and that zero-divergence inference learning (Z-IL), a variant of IL, is able to exactly implement BP on MLPs. However, the recent literature shows also that there is no biologically plausible method yet that can exactly replicate the weight update of BP on complex models. To fill this gap, in this paper, we generalize (IL and) Z-IL by directly defining them on computational graphs. To our knowledge, this is the first biologically plausible algorithm that is shown to be equivalent to BP in the way of updating parameters on any neural network, and it is thus a great breakthrough for the interdisciplinary research of neuroscience and deep learning.
Predictive Coding Can Do Exact Backpropagation on Convolutional and Recurrent Neural Networks
Mar 05, 2021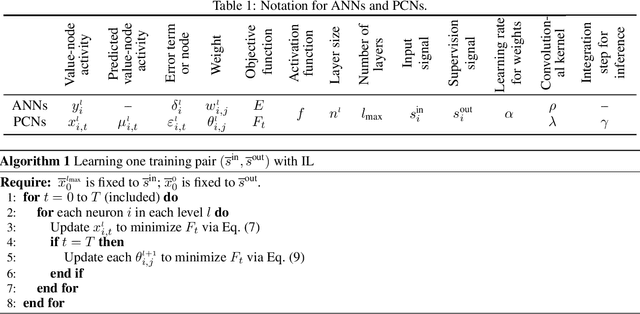
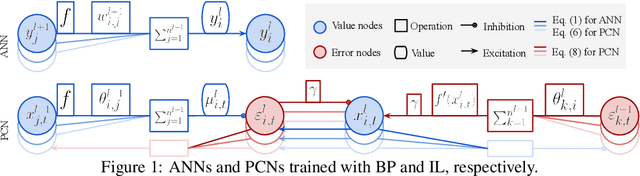

Predictive coding networks (PCNs) are an influential model for information processing in the brain. They have appealing theoretical interpretations and offer a single mechanism that accounts for diverse perceptual phenomena of the brain. On the other hand, backpropagation (BP) is commonly regarded to be the most successful learning method in modern machine learning. Thus, it is exciting that recent work formulates inference learning (IL) that trains PCNs to approximate BP. However, there are several remaining critical issues: (i) IL is an approximation to BP with unrealistic/non-trivial requirements, (ii) IL approximates BP in single-step weight updates; whether it leads to the same point as BP after the weight updates are conducted for more steps is unknown, and (iii) IL is computationally significantly more costly than BP. To solve these issues, a variant of IL that is strictly equivalent to BP in fully connected networks has been proposed. In this work, we build on this result by showing that it also holds for more complex architectures, namely, convolutional neural networks and (many-to-one) recurrent neural networks. To our knowledge, we are the first to show that a biologically plausible algorithm is able to exactly replicate the accuracy of BP on such complex architectures, bridging the existing gap between IL and BP, and setting an unprecedented performance for PCNs, which can now be considered as efficient alternatives to BP.
Multi-level Wavelet-based Generative Adversarial Network for Perceptual Quality Enhancement of Compressed Video
Aug 02, 2020
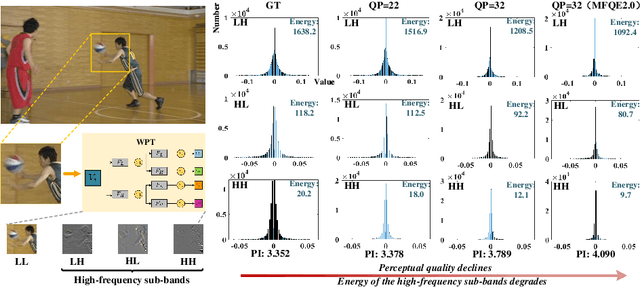
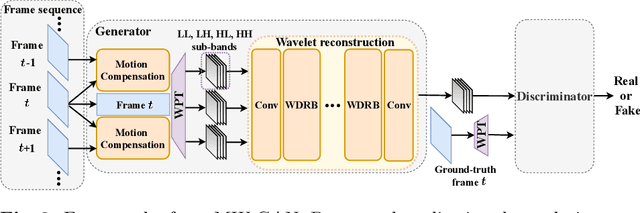
The past few years have witnessed fast development in video quality enhancement via deep learning. Existing methods mainly focus on enhancing the objective quality of compressed video while ignoring its perceptual quality. In this paper, we focus on enhancing the perceptual quality of compressed video. Our main observation is that enhancing the perceptual quality mostly relies on recovering high-frequency sub-bands in wavelet domain. Accordingly, we propose a novel generative adversarial network (GAN) based on multi-level wavelet packet transform (WPT) to enhance the perceptual quality of compressed video, which is called multi-level wavelet-based GAN (MW-GAN). In MW-GAN, we first apply motion compensation with a pyramid architecture to obtain temporal information. Then, we propose a wavelet reconstruction network with wavelet-dense residual blocks (WDRB) to recover the high-frequency details. In addition, the adversarial loss of MW-GAN is added via WPT to further encourage high-frequency details recovery for video frames. Experimental results demonstrate the superiority of our method.
Zeroth-Order Supervised Policy Improvement
Jun 11, 2020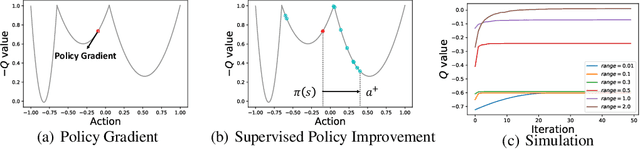
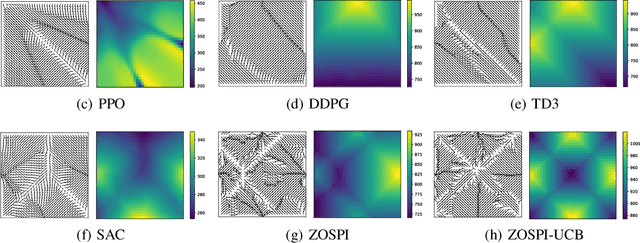
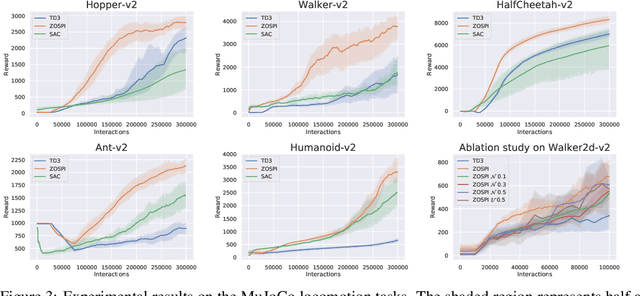
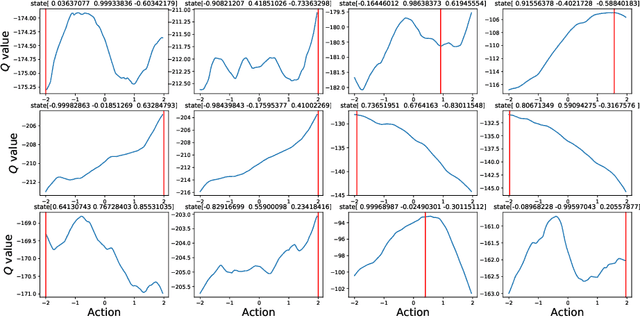
Despite the remarkable progress made by the policy gradient algorithms in reinforcement learning (RL), sub-optimal policies usually result from the local exploration property of the policy gradient update. In this work, we propose a method referred to as Zeroth-Order Supervised Policy Improvement (ZOSPI) that exploits the estimated value function Q globally while preserves the local exploitation of the policy gradient methods. We prove that with a good function structure, the zeroth-order optimization strategy combining both local and global samplings can find the global minima within a polynomial number of samples. To improve the exploration efficiency in unknown environments, ZOSPI is further combined with bootstrapped Q networks. Different from the standard policy gradient methods, the policy learning of ZOSPI is conducted in a self-supervision manner so that the policy can be implemented with gradient-free non-parametric models besides the neural network approximator. Experiments show that ZOSPI achieves competitive results on MuJoCo locomotion tasks with a remarkable sample efficiency.
Novel Human-Object Interaction Detection via Adversarial Domain Generalization
May 22, 2020
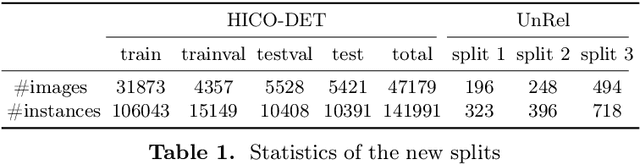
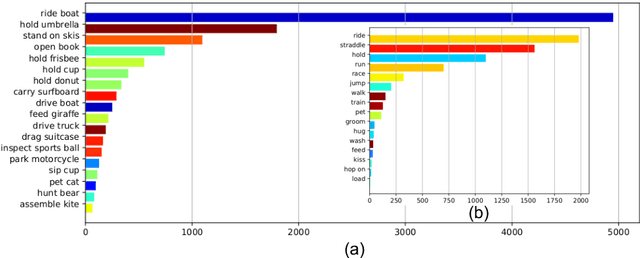
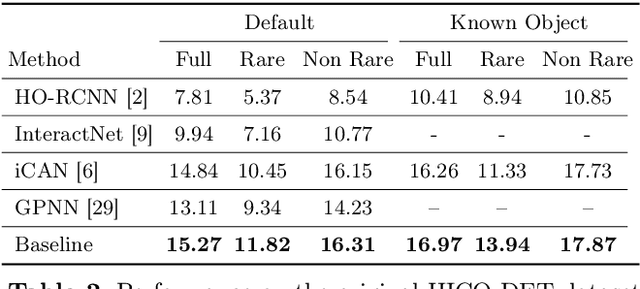
We study in this paper the problem of novel human-object interaction (HOI) detection, aiming at improving the generalization ability of the model to unseen scenarios. The challenge mainly stems from the large compositional space of objects and predicates, which leads to the lack of sufficient training data for all the object-predicate combinations. As a result, most existing HOI methods heavily rely on object priors and can hardly generalize to unseen combinations. To tackle this problem, we propose a unified framework of adversarial domain generalization to learn object-invariant features for predicate prediction. To measure the performance improvement, we create a new split of the HICO-DET dataset, where the HOIs in the test set are all unseen triplet categories in the training set. Our experiments show that the proposed framework significantly increases the performance by up to 50% on the new split of HICO-DET dataset and up to 125% on the UnRel dataset for auxiliary evaluation in detecting novel HOIs.
AutoRemover: Automatic Object Removal for Autonomous Driving Videos
Nov 28, 2019
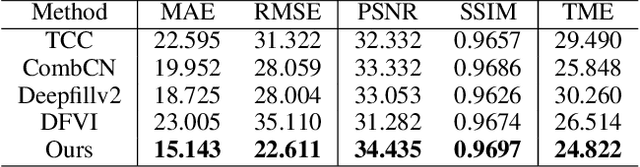
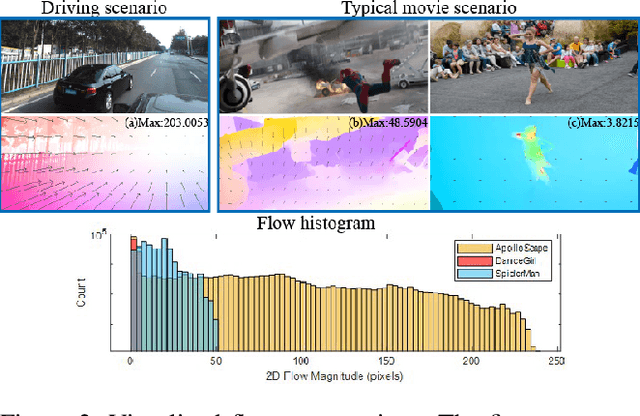
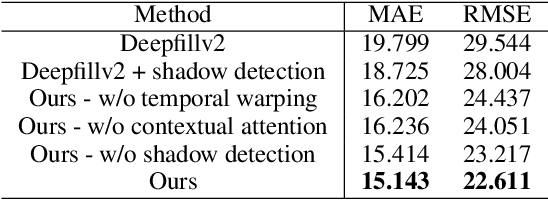
Motivated by the need for photo-realistic simulation in autonomous driving, in this paper we present a video inpainting algorithm \emph{AutoRemover}, designed specifically for generating street-view videos without any moving objects. In our setup we have two challenges: the first is the shadow, shadows are usually unlabeled but tightly coupled with the moving objects. The second is the large ego-motion in the videos. To deal with shadows, we build up an autonomous driving shadow dataset and design a deep neural network to detect shadows automatically. To deal with large ego-motion, we take advantage of the multi-source data, in particular the 3D data, in autonomous driving. More specifically, the geometric relationship between frames is incorporated into an inpainting deep neural network to produce high-quality structurally consistent video output. Experiments show that our method outperforms other state-of-the-art (SOTA) object removal algorithms, reducing the RMSE by over $19\%$.
Arena: A General Evaluation Platform and Building Toolkit for Multi-Agent Intelligence
May 30, 2019

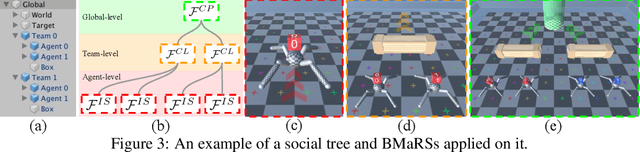
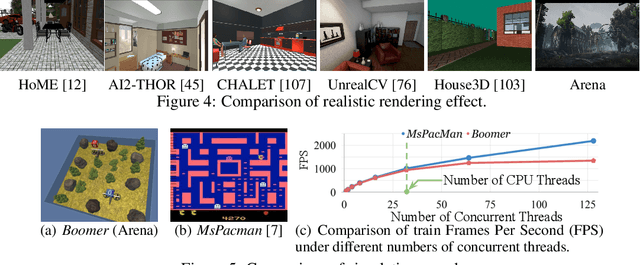
Learning agents that are not only capable of taking tests but are also innovating are becoming a hot topic in artificial intelligence (AI). One of the most promising paths towards this vision is multi-agent learning, where agents act as the environment for each other, and improving each agent means proposing new problems for others. However, the existing evaluation platforms are either not compatible with multi-agent settings, or limited to a specific game. That is, there is not yet a general evaluation platform for research on multi-agent intelligence. To this end, we introduce Arena, a general evaluation platform for multi-agent intelligence with 35 games of diverse logic and representations. Furthermore, multi-agent intelligence is still at the stage where many problems remain unexplored. Therefore, we provide a building toolkit for researchers to easily invent and build novel multi-agent problems from the provided games set based on a GUI-configurable social tree and five basic multi-agent reward schemes. Finally, we provide python implementations of five state-of-the-art deep multi-agent reinforcement learning baselines. Along with the baseline implementations, we release a set of 100 best agents/teams that we can train with different training schemes for each game, as the base for evaluating agents with population performance. As such, the research community can perform comparisons under a stable and uniform standard.
Mega-Reward: Achieving Human-Level Play without Extrinsic Rewards
May 30, 2019

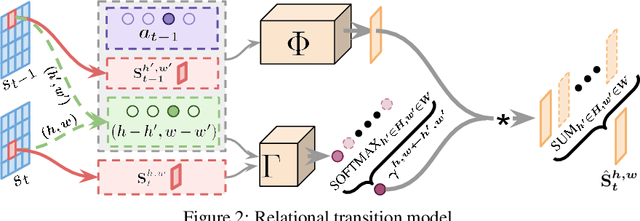
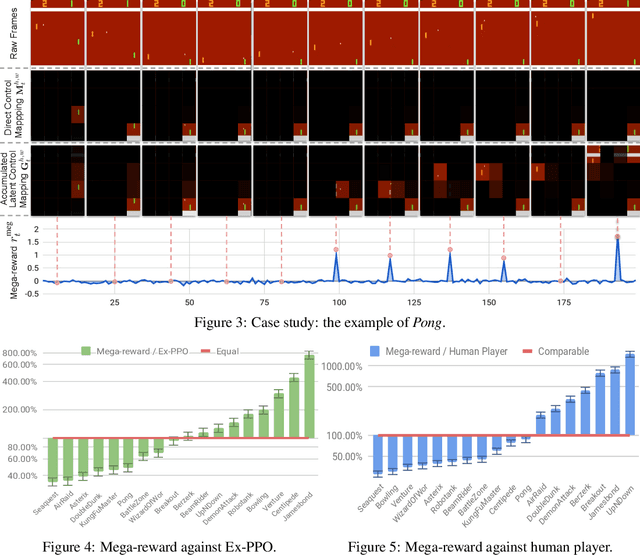
Intrinsic rewards are introduced to simulate how human intelligence works; they are usually evaluated by intrinsically-motivated play, i.e., playing games without extrinsic rewards but evaluated with extrinsic rewards. However, none of the existing intrinsic reward approaches can achieve human-level performance under this very challenging setting of intrinsically-motivated play. In this work, we propose a novel megalomania-driven intrinsic reward (called \emph{mega-reward}), which, to our knowledge, is the first approach that achieves human-level performance in intrinsically-motivated play. Intuitively, mega-reward comes from the observation that infants' intelligence develops when they try to gain more control on entities in an environment; therefore, mega-reward aims to maximize the control capabilities of agents on given entities in a given environment. To formalize mega-reward, a relational transition model is proposed to bridge the gaps between direct and latent control. Experimental studies show that mega-reward can (i) greatly outperform all state-of-the-art intrinsic reward approaches, (ii) generally achieves the same level of performance as Ex-PPO and professional human-level scores; and (iii) has also superior performance when it is incorporated with extrinsic reward.