 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYufei Wang
RoboGen: Towards Unleashing Infinite Data for Automated Robot Learning via Generative Simulation
Nov 02, 2023
We present RoboGen, a generative robotic agent that automatically learns diverse robotic skills at scale via generative simulation. RoboGen leverages the latest advancements in foundation and generative models. Instead of directly using or adapting these models to produce policies or low-level actions, we advocate for a generative scheme, which uses these models to automatically generate diversified tasks, scenes, and training supervisions, thereby scaling up robotic skill learning with minimal human supervision. Our approach equips a robotic agent with a self-guided propose-generate-learn cycle: the agent first proposes interesting tasks and skills to develop, and then generates corresponding simulation environments by populating pertinent objects and assets with proper spatial configurations. Afterwards, the agent decomposes the proposed high-level task into sub-tasks, selects the optimal learning approach (reinforcement learning, motion planning, or trajectory optimization), generates required training supervision, and then learns policies to acquire the proposed skill. Our work attempts to extract the extensive and versatile knowledge embedded in large-scale models and transfer them to the field of robotics. Our fully generative pipeline can be queried repeatedly, producing an endless stream of skill demonstrations associated with diverse tasks and environments.
FollowBench: A Multi-level Fine-grained Constraints Following Benchmark for Large Language Models
Oct 31, 2023
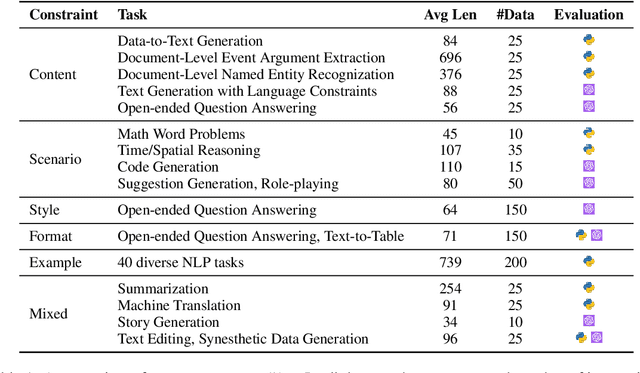
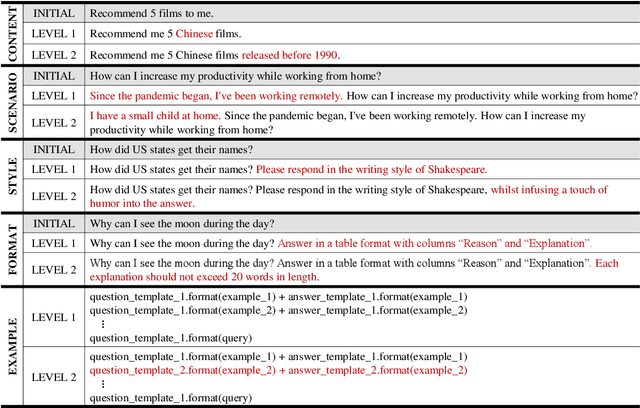
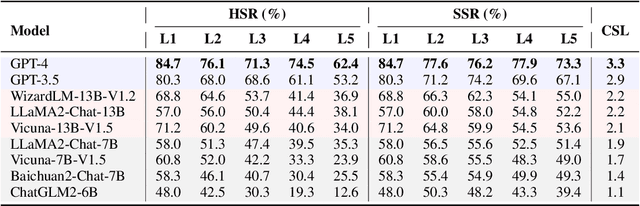
The ability to follow instructions is crucial to Large Language Models (LLMs) to handle various real-world applications. Existing benchmarks primarily focus on evaluating superficial response quality, which does not necessarily indicate instruction-following capability. To fill this research gap, in this paper, we propose FollowBench, a Multi-level Fine-grained Constraints Following Benchmark for LLMs. FollowBench comprehensively includes five different types (i.e., Content, Scenario, Style, Format, and Example) of fine-grained constraints. To enable a precise constraint following estimation, we introduce a Multi-level mechanism that incrementally adds a single constraint to the initial instruction at each level. To evaluate whether LLMs' outputs have satisfied every individual constraint, we propose to prompt strong LLMs with constraint evolution paths to handle challenging semantic constraints. By evaluating nine closed-source and open-source popular LLMs on FollowBench, we highlight the weaknesses of LLMs in instruction following and point towards potential avenues for future work. The data and code are publicly available at https://github.com/YJiangcm/FollowBench.
M4LE: A Multi-Ability Multi-Range Multi-Task Multi-Domain Long-Context Evaluation Benchmark for Large Language Models
Oct 30, 2023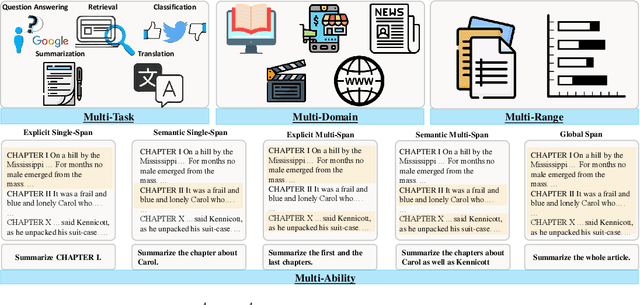

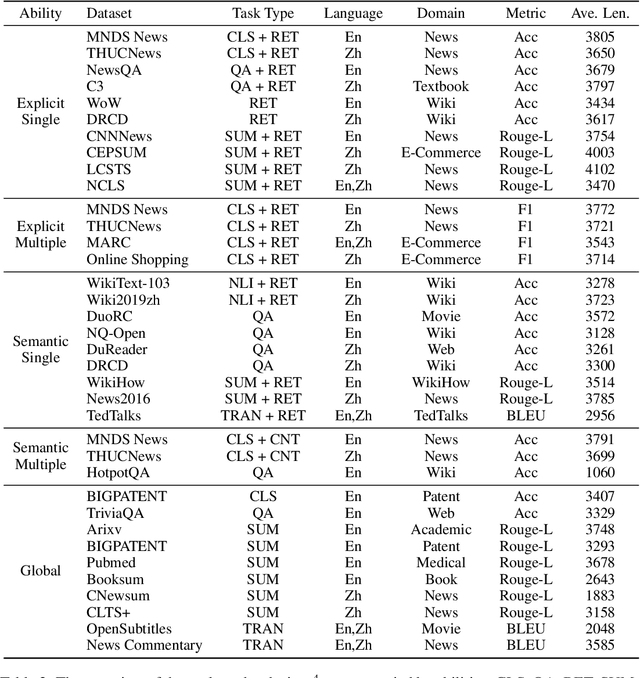
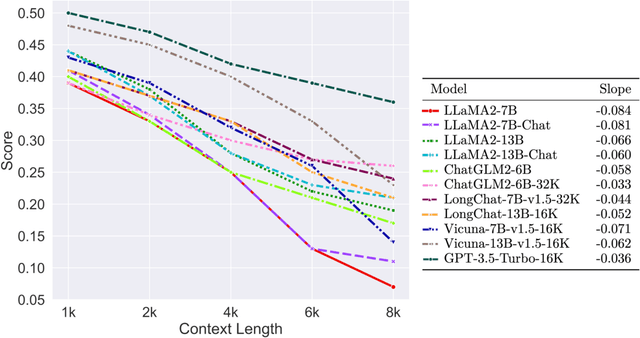
Managing long sequences has become an important and necessary feature for large language models (LLMs). However, it is still an open question of how to comprehensively and systematically evaluate the long-sequence capability of LLMs. One of the reasons is that conventional and widely-used benchmarks mainly consist of short sequences. In this paper, we propose M4LE, a Multi-ability, Multi-range, Multi-task, Multi-domain benchmark for Long-context Evaluation. M4LE is based on a diverse NLP task pool comprising 36 NLP datasets, 11 task types and 12 domains. To alleviate the scarcity of tasks with naturally long sequences and incorporate multiple-ability assessment, we propose an automatic approach (but with negligible human annotations) to convert short-sequence tasks into a unified long-sequence scenario where LLMs have to identify single or multiple relevant spans in long contexts based on explicit or semantic hints. Specifically, the scenario includes five different types of abilities: (1) explicit single-span; (2) semantic single-span; (3) explicit multiple-span; (4) semantic multiple-span; and (5) global context understanding. The resulting samples in M4LE are evenly distributed from 1k to 8k input length. We conducted a systematic evaluation on 11 well-established LLMs, especially those optimized for long-sequence inputs. Our results reveal that: 1) Current LLMs struggle to understand long context, particularly when tasks require multiple-span attention. 2) Semantic retrieval task is more difficult for competent LLMs. 3) Models fine-tuned on longer text with position interpolation have comparable performance to those using Neural Tangent Kernel (NTK) aware scaling methods without fine-tuning. We make our benchmark publicly available to encourage future research in this challenging area.
LRRU: Long-short Range Recurrent Updating Networks for Depth Completion
Oct 13, 2023Existing deep learning-based depth completion methods generally employ massive stacked layers to predict the dense depth map from sparse input data. Although such approaches greatly advance this task, their accompanied huge computational complexity hinders their practical applications. To accomplish depth completion more efficiently, we propose a novel lightweight deep network framework, the Long-short Range Recurrent Updating (LRRU) network. Without learning complex feature representations, LRRU first roughly fills the sparse input to obtain an initial dense depth map, and then iteratively updates it through learned spatially-variant kernels. Our iterative update process is content-adaptive and highly flexible, where the kernel weights are learned by jointly considering the guidance RGB images and the depth map to be updated, and large-to-small kernel scopes are dynamically adjusted to capture long-to-short range dependencies. Our initial depth map has coarse but complete scene depth information, which helps relieve the burden of directly regressing the dense depth from sparse ones, while our proposed method can effectively refine it to an accurate depth map with less learnable parameters and inference time. Experimental results demonstrate that our proposed LRRU variants achieve state-of-the-art performance across different parameter regimes. In particular, the LRRU-Base model outperforms competing approaches on the NYUv2 dataset, and ranks 1st on the KITTI depth completion benchmark at the time of submission. Project page: https://npucvr.github.io/LRRU/.
SELF: Language-Driven Self-Evolution for Large Language Model
Oct 07, 2023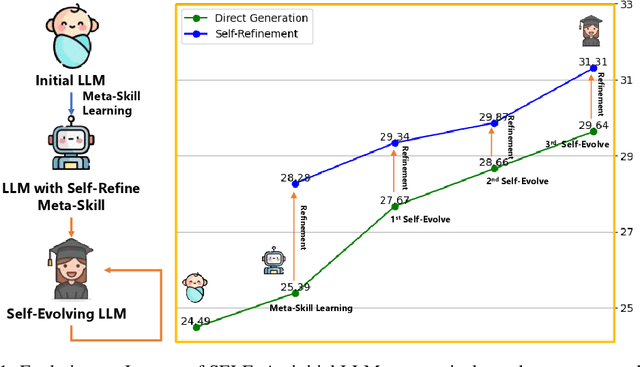
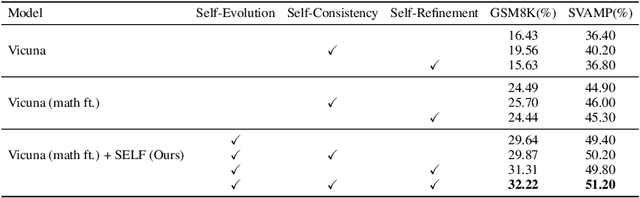
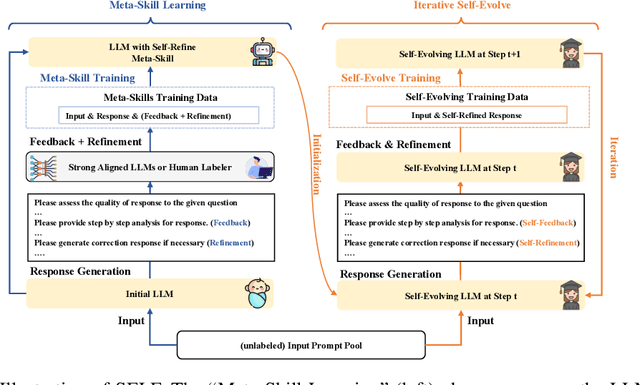

Large Language Models (LLMs) have showcased remarkable versatility across diverse domains. However, the pathway toward autonomous model development, a cornerstone for achieving human-level learning and advancing autonomous AI, remains largely uncharted. We introduce an innovative approach, termed "SELF" (Self-Evolution with Language Feedback). This methodology empowers LLMs to undergo continual self-evolution. Furthermore, SELF employs language-based feedback as a versatile and comprehensive evaluative tool, pinpointing areas for response refinement and bolstering the stability of self-evolutionary training. Initiating with meta-skill learning, SELF acquires foundational meta-skills with a focus on self-feedback and self-refinement. These meta-skills are critical, guiding the model's subsequent self-evolution through a cycle of perpetual training with self-curated data, thereby enhancing its intrinsic abilities. Given unlabeled instructions, SELF equips the model with the capability to autonomously generate and interactively refine responses. This synthesized training data is subsequently filtered and utilized for iterative fine-tuning, enhancing the model's capabilities. Experimental results on representative benchmarks substantiate that SELF can progressively advance its inherent abilities without the requirement of human intervention, thereby indicating a viable pathway for autonomous model evolution. Additionally, SELF can employ online self-refinement strategy to produce responses of superior quality. In essence, the SELF framework signifies a progressive step towards autonomous LLM development, transforming the LLM from a mere passive recipient of information into an active participant in its own evolution.
Towards Lexical Analysis of Dog Vocalizations via Online Videos
Sep 21, 2023Deciphering the semantics of animal language has been a grand challenge. This study presents a data-driven investigation into the semantics of dog vocalizations via correlating different sound types with consistent semantics. We first present a new dataset of Shiba Inu sounds, along with contextual information such as location and activity, collected from YouTube with a well-constructed pipeline. The framework is also applicable to other animal species. Based on the analysis of conditioned probability between dog vocalizations and corresponding location and activity, we discover supporting evidence for previous heuristic research on the semantic meaning of various dog sounds. For instance, growls can signify interactions. Furthermore, our study yields new insights that existing word types can be subdivided into finer-grained subtypes and minimal semantic unit for Shiba Inu is word-related. For example, whimper can be subdivided into two types, attention-seeking and discomfort.
Does My Dog ''Speak'' Like Me? The Acoustic Correlation between Pet Dogs and Their Human Owners
Sep 21, 2023How hosts language influence their pets' vocalization is an interesting yet underexplored problem. This paper presents a preliminary investigation into the possible correlation between domestic dog vocal expressions and their human host's language environment. We first present a new dataset of Shiba Inu dog vocals from YouTube, which provides 7500 clean sound clips, including their contextual information of these vocals and their owner's speech clips with a carefully-designed data processing pipeline. The contextual information includes the scene category in which the vocal was recorded, the dog's location and activity. With a classification task and prominent factor analysis, we discover significant acoustic differences in the dog vocals from the two language environments. We further identify some acoustic features from dog vocalizations that are potentially correlated to their host language patterns.
When Large Language Models Meet Citation: A Survey
Sep 18, 2023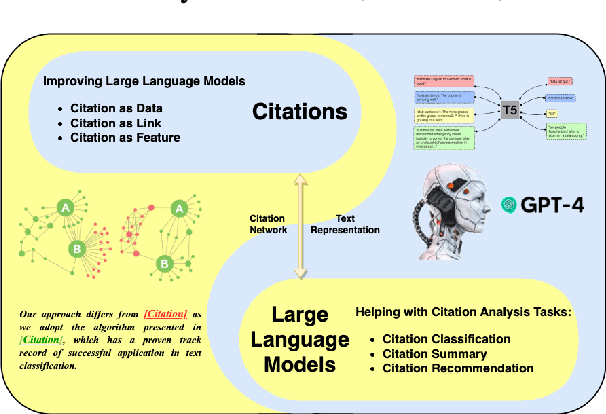


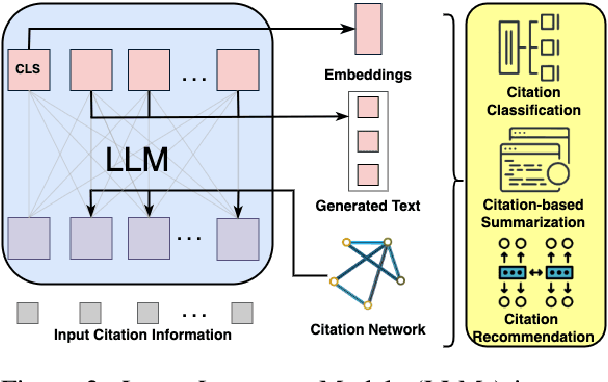
Citations in scholarly work serve the essential purpose of acknowledging and crediting the original sources of knowledge that have been incorporated or referenced. Depending on their surrounding textual context, these citations are used for different motivations and purposes. Large Language Models (LLMs) could be helpful in capturing these fine-grained citation information via the corresponding textual context, thereby enabling a better understanding towards the literature. Furthermore, these citations also establish connections among scientific papers, providing high-quality inter-document relationships and human-constructed knowledge. Such information could be incorporated into LLMs pre-training and improve the text representation in LLMs. Therefore, in this paper, we offer a preliminary review of the mutually beneficial relationship between LLMs and citation analysis. Specifically, we review the application of LLMs for in-text citation analysis tasks, including citation classification, citation-based summarization, and citation recommendation. We then summarize the research pertinent to leveraging citation linkage knowledge to improve text representations of LLMs via citation prediction, network structure information, and inter-document relationship. We finally provide an overview of these contemporary methods and put forth potential promising avenues in combining LLMs and citation analysis for further investigation.
Decomposed Guided Dynamic Filters for Efficient RGB-Guided Depth Completion
Sep 05, 2023RGB-guided depth completion aims at predicting dense depth maps from sparse depth measurements and corresponding RGB images, where how to effectively and efficiently exploit the multi-modal information is a key issue. Guided dynamic filters, which generate spatially-variant depth-wise separable convolutional filters from RGB features to guide depth features, have been proven to be effective in this task. However, the dynamically generated filters require massive model parameters, computational costs and memory footprints when the number of feature channels is large. In this paper, we propose to decompose the guided dynamic filters into a spatially-shared component multiplied by content-adaptive adaptors at each spatial location. Based on the proposed idea, we introduce two decomposition schemes A and B, which decompose the filters by splitting the filter structure and using spatial-wise attention, respectively. The decomposed filters not only maintain the favorable properties of guided dynamic filters as being content-dependent and spatially-variant, but also reduce model parameters and hardware costs, as the learned adaptors are decoupled with the number of feature channels. Extensive experimental results demonstrate that the methods using our schemes outperform state-of-the-art methods on the KITTI dataset, and rank 1st and 2nd on the KITTI benchmark at the time of submission. Meanwhile, they also achieve comparable performance on the NYUv2 dataset. In addition, our proposed methods are general and could be employed as plug-and-play feature fusion blocks in other multi-modal fusion tasks such as RGB-D salient object detection.
Investigating the Learning Behaviour of In-context Learning: A Comparison with Supervised Learning
Aug 01, 2023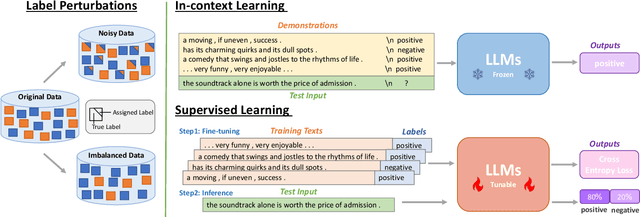
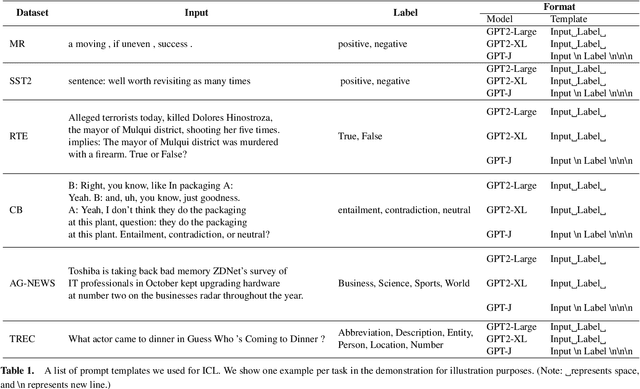
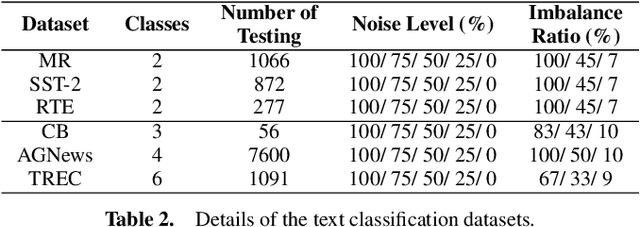
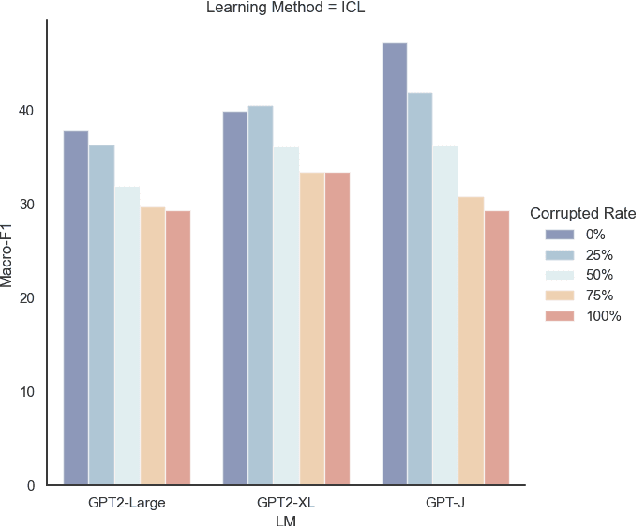
Large language models (LLMs) have shown remarkable capacity for in-context learning (ICL), where learning a new task from just a few training examples is done without being explicitly pre-trained. However, despite the success of LLMs, there has been little understanding of how ICL learns the knowledge from the given prompts. In this paper, to make progress toward understanding the learning behaviour of ICL, we train the same LLMs with the same demonstration examples via ICL and supervised learning (SL), respectively, and investigate their performance under label perturbations (i.e., noisy labels and label imbalance) on a range of classification tasks. First, via extensive experiments, we find that gold labels have significant impacts on the downstream in-context performance, especially for large language models; however, imbalanced labels matter little to ICL across all model sizes. Second, when comparing with SL, we show empirically that ICL is less sensitive to label perturbations than SL, and ICL gradually attains comparable performance to SL as the model size increases.