 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuanjun Xiong
Learning to Recognize Patch-Wise Consistency for Deepfake Detection
Dec 16, 2020
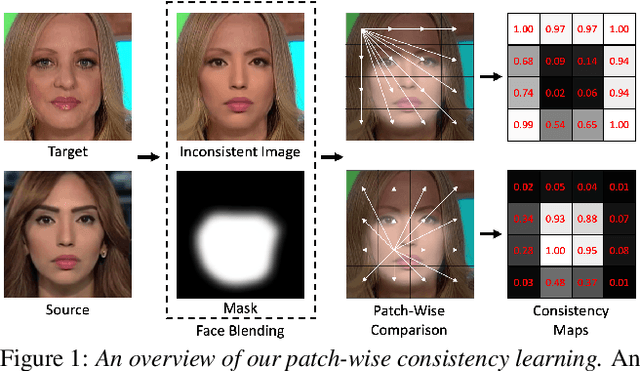

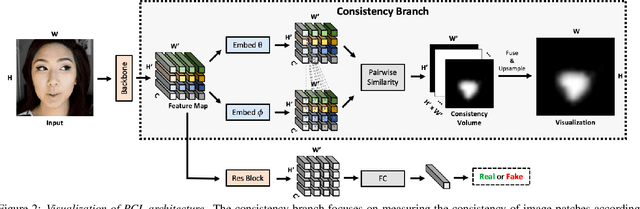
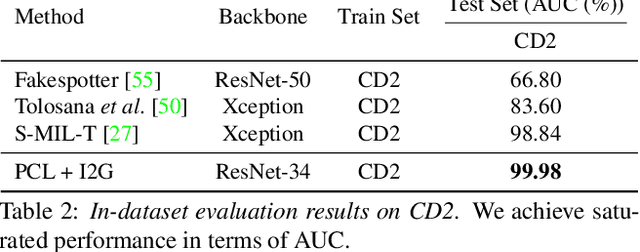
We propose to detect Deepfake generated by face manipulation based on one of their fundamental features: images are blended by patches from multiple sources, carrying distinct and persistent source features. In particular, we propose a novel representation learning approach for this task, called patch-wise consistency learning (PCL). It learns by measuring the consistency of image source features, resulting to representation with good interpretability and robustness to multiple forgery methods. We develop an inconsistency image generator (I2G) to generate training data for PCL and boost its robustness. We evaluate our approach on seven popular Deepfake detection datasets. Our model achieves superior detection accuracy and generalizes well to unseen generation methods. On average, our model outperforms the state-of-the-art in terms of AUC by 2% and 8% in the in- and cross-dataset evaluation, respectively.
A Comprehensive Study of Deep Video Action Recognition
Dec 11, 2020
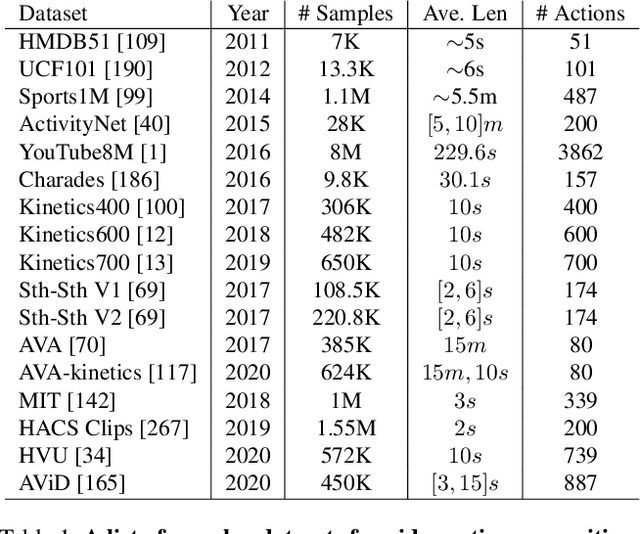
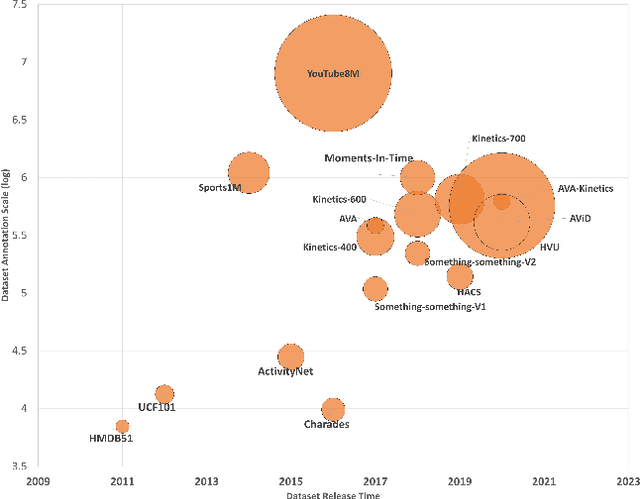
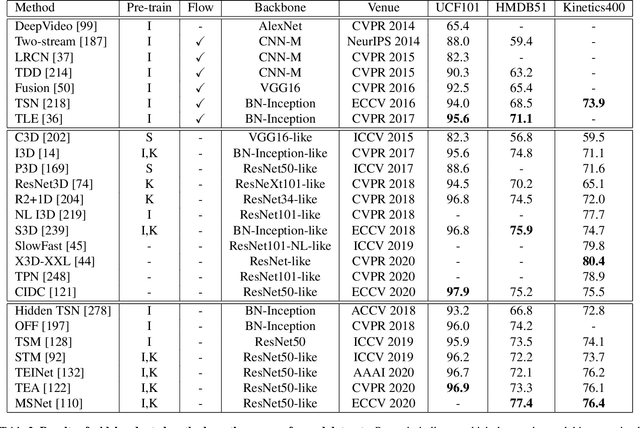
Video action recognition is one of the representative tasks for video understanding. Over the last decade, we have witnessed great advancements in video action recognition thanks to the emergence of deep learning. But we also encountered new challenges, including modeling long-range temporal information in videos, high computation costs, and incomparable results due to datasets and evaluation protocol variances. In this paper, we provide a comprehensive survey of over 200 existing papers on deep learning for video action recognition. We first introduce the 17 video action recognition datasets that influenced the design of models. Then we present video action recognition models in chronological order: starting with early attempts at adapting deep learning, then to the two-stream networks, followed by the adoption of 3D convolutional kernels, and finally to the recent compute-efficient models. In addition, we benchmark popular methods on several representative datasets and release code for reproducibility. In the end, we discuss open problems and shed light on opportunities for video action recognition to facilitate new research ideas.
Positive-Congruent Training: Towards Regression-Free Model Updates
Nov 20, 2020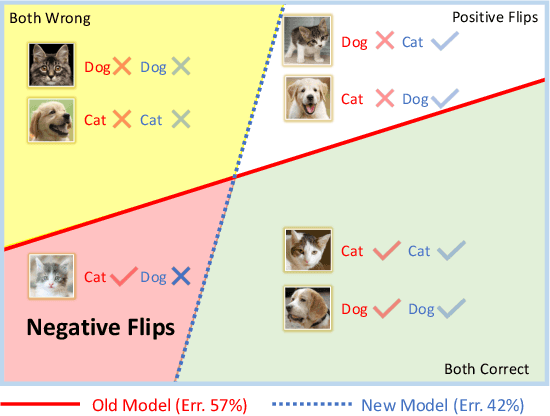
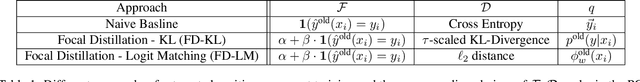
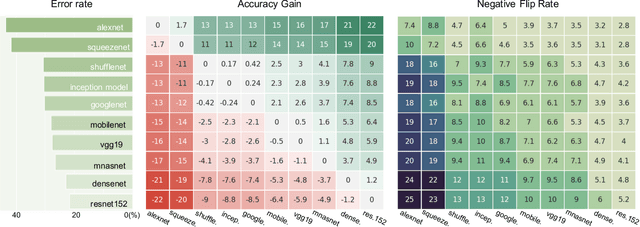
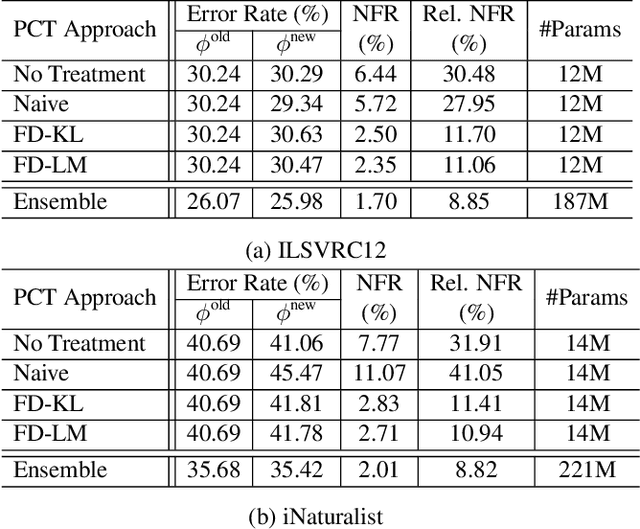
Reducing inconsistencies in the behavior of different versions of an AI system can be as important in practice as reducing its overall error. In image classification, sample-wise inconsistencies appear as "negative flips:" A new model incorrectly predicts the output for a test sample that was correctly classified by the old (reference) model. Positive-congruent (PC) training aims at reducing error rate while at the same time reducing negative flips, thus maximizing congruency with the reference model only on positive predictions, unlike model distillation. We propose a simple approach for PC training, Focal Distillation, which enforces congruence with the reference model by giving more weights to samples that were correctly classified. We also found that, if the reference model itself can be chosen as an ensemble of multiple deep neural networks, negative flips can be further reduced without affecting the new model's accuracy.
SMOT: Single-Shot Multi Object Tracking
Oct 30, 2020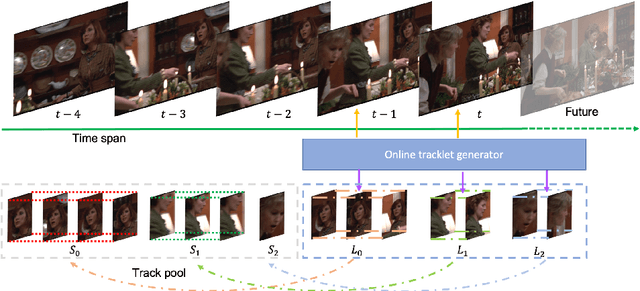
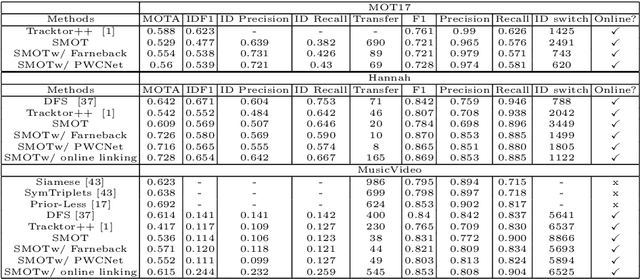
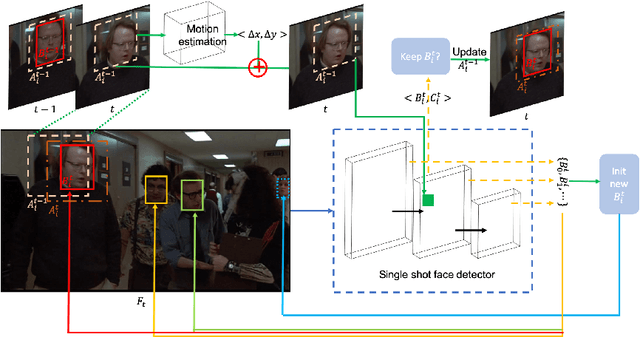
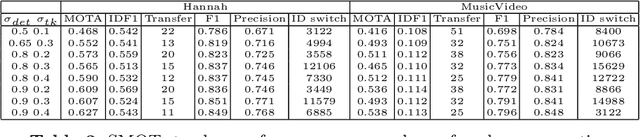
We present single-shot multi-object tracker (SMOT), a new tracking framework that converts any single-shot detector (SSD) model into an online multiple object tracker, which emphasizes simultaneously detecting and tracking of the object paths. Contrary to the existing tracking by detection approaches which suffer from errors made by the object detectors, SMOT adopts the recently proposed scheme of tracking by re-detection. We combine this scheme with SSD detectors by proposing a novel tracking anchor assignment module. With this design SMOT is able to generate tracklets with a constant per-frame runtime. A light-weighted linkage algorithm is then used for online tracklet linking. On three benchmarks of object tracking: Hannah, Music Videos, and MOT17, the proposed SMOT achieves state-of-the-art performance.
Online Action Detection in Streaming Videos with Time Buffers
Oct 06, 2020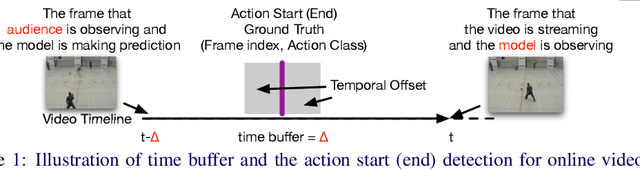
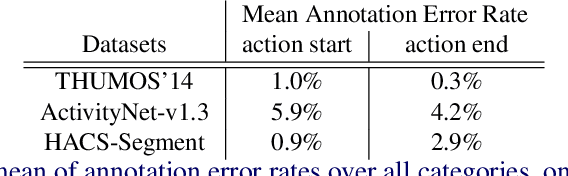

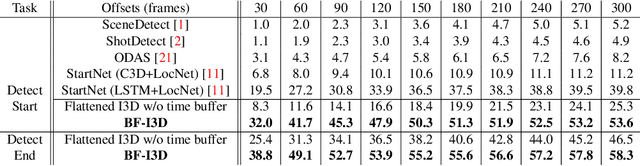
We formulate the problem of online temporal action detection in live streaming videos, acknowledging one important property of live streaming videos that there is normally a broadcast delay between the latest captured frame and the actual frame viewed by the audience. The standard setting of the online action detection task requires immediate prediction after a new frame is captured. We illustrate that its lack of consideration of the delay is imposing unnecessary constraints on the models and thus not suitable for this problem. We propose to adopt the problem setting that allows models to make use of the small `buffer time' incurred by the delay in live streaming videos. We design an action start and end detection framework for this online with buffer setting with two major components: flattened I3D and window-based suppression. Experiments on three standard temporal action detection benchmarks under the proposed setting demonstrate the effectiveness of the proposed framework. We show that by having a suitable problem setting for this problem with wide-applications, we can achieve much better detection accuracy than off-the-shelf online action detection models.
3D-Aided Data Augmentation for Robust Face Understanding
Oct 06, 2020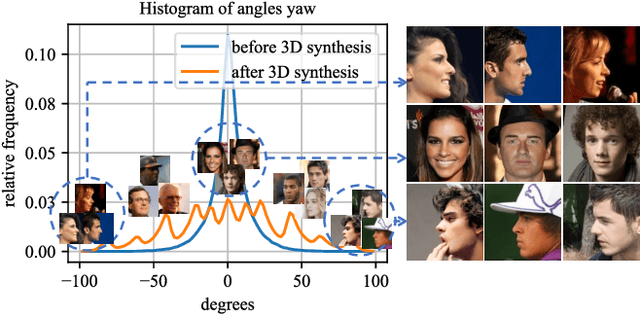

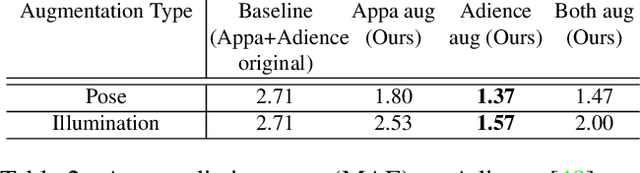
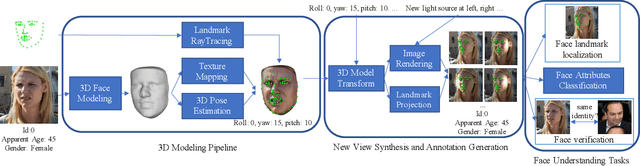
Data augmentation has been highly effective in narrowing the data gap and reducing the cost for human annotation, especially for tasks where ground truth labels are difficult and expensive to acquire. In face recognition, large pose and illumination variation of face images has been a key factor for performance degradation. However, human annotation for the various face understanding tasks including face landmark localization, face attributes classification and face recognition under these challenging scenarios are highly costly to acquire. Therefore, it would be desirable to perform data augmentation for these cases. But simple 2D data augmentation techniques on the image domain are not able to satisfy the requirement of these challenging cases. As such, 3D face modeling, in particular, single image 3D face modeling, stands a feasible solution for these challenging conditions beyond 2D based data augmentation. To this end, we propose a method that produces realistic 3D augmented images from multiple viewpoints with different illumination conditions through 3D face modeling, each associated with geometrically accurate face landmarks, attributes and identity information. Experiments demonstrate that the proposed 3D data augmentation method significantly improves the performance and robustness of various face understanding tasks while achieving state-of-arts on multiple benchmarks.
Towards causal benchmarking of bias in face analysis algorithms
Jul 13, 2020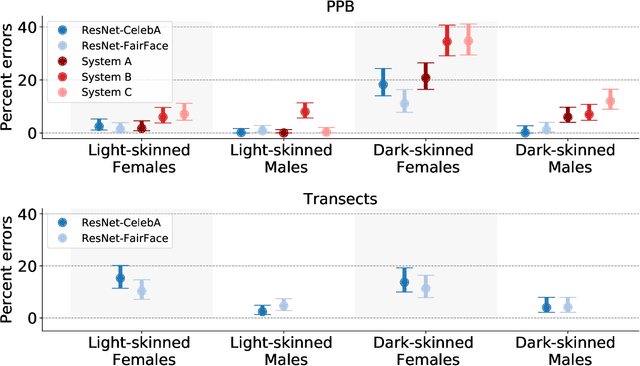
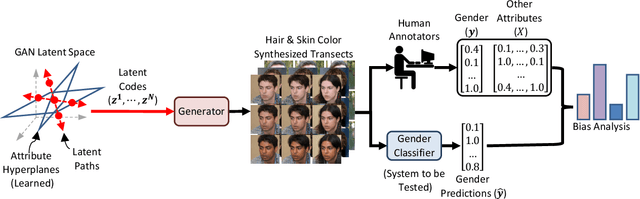


Measuring algorithmic bias is crucial both to assess algorithmic fairness, and to guide the improvement of algorithms. Current methods to measure algorithmic bias in computer vision, which are based on observational datasets, are inadequate for this task because they conflate algorithmic bias with dataset bias. To address this problem we develop an experimental method for measuring algorithmic bias of face analysis algorithms, which manipulates directly the attributes of interest, e.g., gender and skin tone, in order to reveal causal links between attribute variation and performance change. Our proposed method is based on generating synthetic ``transects'' of matched sample images that are designed to differ along specific attributes while leaving other attributes constant. A crucial aspect of our approach is relying on the perception of human observers, both to guide manipulations, and to measure algorithmic bias. Besides allowing the measurement of algorithmic bias, synthetic transects have other advantages with respect to observational datasets: they sample attributes more evenly allowing for more straightforward bias analysis on minority and intersectional groups, they enable prediction of bias in new scenarios, they greatly reduce ethical and legal challenges, and they are economical and fast to obtain, helping make bias testing affordable and widely available. We validate our method by comparing it to a study that employs the traditional observational method for analyzing bias in gender classification algorithms. The two methods reach different conclusions. While the observational method reports gender and skin color biases, the experimental method reveals biases due to gender, hair length, age, and facial hair.
On Improving Temporal Consistency for Online Face Liveness Detection
Jun 11, 2020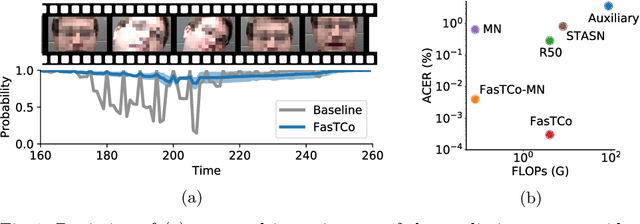
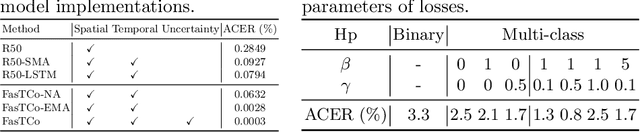
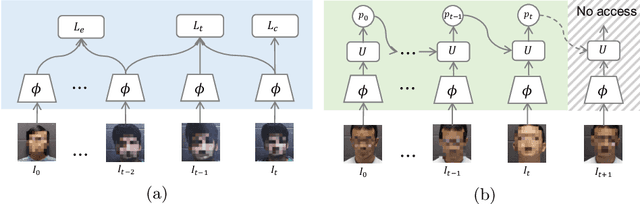

In this paper, we focus on improving the online face liveness detection system to enhance the security of the downstream face recognition system. Most of the existing frame-based methods are suffering from the prediction inconsistency across time. To address the issue, a simple yet effective solution based on temporal consistency is proposed. Specifically, in the training stage, to integrate the temporal consistency constraint, a temporal self-supervision loss and a class consistency loss are proposed in addition to the softmax cross-entropy loss. In the deployment stage, a training-free non-parametric uncertainty estimation module is developed to smooth the predictions adaptively. Beyond the common evaluation approach, a video segment-based evaluation is proposed to accommodate more practical scenarios. Extensive experiments demonstrated that our solution is more robust against several presentation attacks in various scenarios, and significantly outperformed the state-of-the-art on multiple public datasets by at least 40% in terms of ACER. Besides, with much less computational complexity (33% fewer FLOPs), it provides great potential for low-latency online applications.
Motion Guided 3D Pose Estimation from Videos
Apr 29, 2020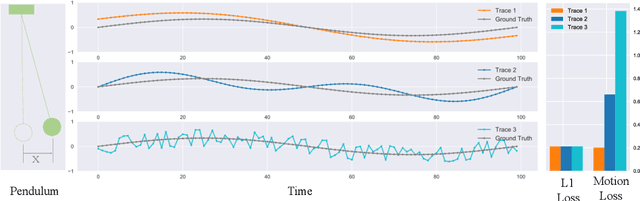



We propose a new loss function, called motion loss, for the problem of monocular 3D Human pose estimation from 2D pose. In computing motion loss, a simple yet effective representation for keypoint motion, called pairwise motion encoding, is introduced. We design a new graph convolutional network architecture, U-shaped GCN (UGCN). It captures both short-term and long-term motion information to fully leverage the additional supervision from the motion loss. We experiment training UGCN with the motion loss on two large scale benchmarks: Human3.6M and MPI-INF-3DHP. Our model surpasses other state-of-the-art models by a large margin. It also demonstrates strong capacity in producing smooth 3D sequences and recovering keypoint motion.