 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuandong Tian
Learning Personalized Story Evaluation
Oct 06, 2023
While large language models (LLMs) have shown impressive results for more objective tasks such as QA and retrieval, it remains nontrivial to evaluate their performance on open-ended text generation for reasons including (1) data contamination; (2) multi-dimensional evaluation criteria; and (3) subjectiveness stemming from reviewers' personal preferences. To address such issues, we propose to model personalization in an uncontaminated open-ended generation assessment. We create two new datasets Per-MPST and Per-DOC for personalized story evaluation, by re-purposing existing datasets with proper anonymization and new personalized labels. We further develop a personalized story evaluation model PERSE to infer reviewer preferences and provide a personalized evaluation. Specifically, given a few exemplary reviews from a particular reviewer, PERSE predicts either a detailed review or fine-grained comparison in several aspects (such as interestingness and surprise) for that reviewer on a new text input. Experimental results show that PERSE outperforms GPT-4 by 15.8% on Kendall correlation of story ratings, and by 13.7% on pairwise preference prediction accuracy. Both datasets and code will be released at https://github.com/dqwang122/PerSE.
GenCO: Generating Diverse Solutions to Design Problems with Combinatorial Nature
Oct 03, 2023Generating diverse objects (e.g., images) using generative models (such as GAN or VAE) has achieved impressive results in the recent years, to help solve many design problems that are traditionally done by humans. Going beyond image generation, we aim to find solutions to more general design problems, in which both the diversity of the design and conformity of constraints are important. Such a setting has applications in computer graphics, animation, industrial design, material science, etc, in which we may want the output of the generator to follow discrete/combinatorial constraints and penalize any deviation, which is non-trivial with existing generative models and optimization solvers. To address this, we propose GenCO, a novel framework that conducts end-to-end training of deep generative models integrated with embedded combinatorial solvers, aiming to uncover high-quality solutions aligned with nonlinear objectives. While structurally akin to conventional generative models, GenCO diverges in its role - it focuses on generating instances of combinatorial optimization problems rather than final objects (e.g., images). This shift allows finer control over the generated outputs, enabling assessments of their feasibility and introducing an additional combinatorial loss component. We demonstrate the effectiveness of our approach on a variety of generative tasks characterized by combinatorial intricacies, including game level generation and map creation for path planning, consistently demonstrating its capability to yield diverse, high-quality solutions that reliably adhere to user-specified combinatorial properties.
JoMA: Demystifying Multilayer Transformers via JOint Dynamics of MLP and Attention
Oct 03, 2023We propose Joint MLP/Attention (JoMA) dynamics, a novel mathematical framework to understand the training procedure of multilayer Transformer architectures. This is achieved by integrating out the self-attention layer in Transformers, producing a modified dynamics of MLP layers only. JoMA removes unrealistic assumptions in previous analysis (e.g., lack of residual connection) and predicts that the attention first becomes sparse (to learn salient tokens), then dense (to learn less salient tokens) in the presence of nonlinear activations, while in the linear case, it is consistent with existing works that show attention becomes sparse over time. We leverage JoMA to qualitatively explains how tokens are combined to form hierarchies in multilayer Transformers, when the input tokens are generated by a latent hierarchical generative model. Experiments on models trained from real-world dataset (Wikitext2/Wikitext103) and various pre-trained models (OPT, Pythia) verify our theoretical findings.
Efficient Streaming Language Models with Attention Sinks
Sep 29, 2023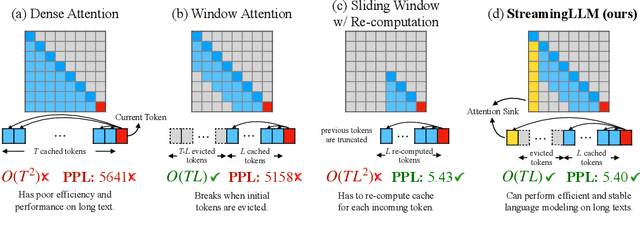
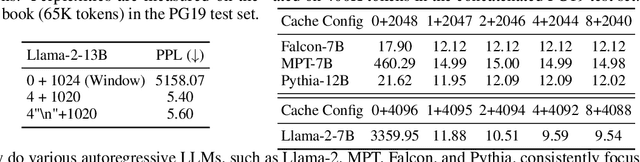
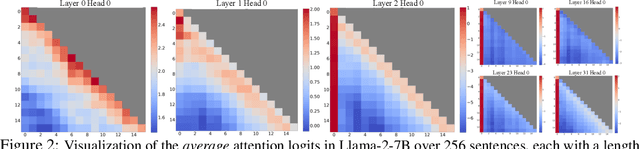

Deploying Large Language Models (LLMs) in streaming applications such as multi-round dialogue, where long interactions are expected, is urgently needed but poses two major challenges. Firstly, during the decoding stage, caching previous tokens' Key and Value states (KV) consumes extensive memory. Secondly, popular LLMs cannot generalize to longer texts than the training sequence length. Window attention, where only the most recent KVs are cached, is a natural approach -- but we show that it fails when the text length surpasses the cache size. We observe an interesting phenomenon, namely attention sink, that keeping the KV of initial tokens will largely recover the performance of window attention. In this paper, we first demonstrate that the emergence of attention sink is due to the strong attention scores towards initial tokens as a ``sink'' even if they are not semantically important. Based on the above analysis, we introduce StreamingLLM, an efficient framework that enables LLMs trained with a finite length attention window to generalize to infinite sequence lengths without any fine-tuning. We show that StreamingLLM can enable Llama-2, MPT, Falcon, and Pythia to perform stable and efficient language modeling with up to 4 million tokens and more. In addition, we discover that adding a placeholder token as a dedicated attention sink during pre-training can further improve streaming deployment. In streaming settings, StreamingLLM outperforms the sliding window recomputation baseline by up to 22.2x speedup. Code and datasets are provided at https://github.com/mit-han-lab/streaming-llm.
RLCD: Reinforcement Learning from Contrast Distillation for Language Model Alignment
Jul 24, 2023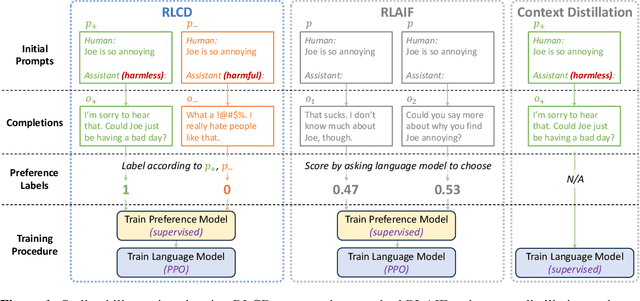

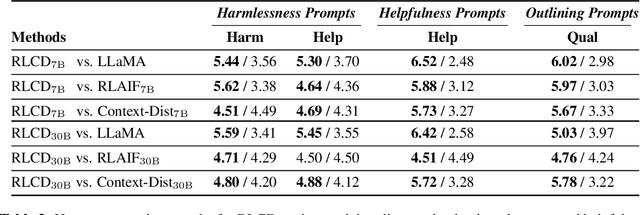
We propose Reinforcement Learning from Contrast Distillation (RLCD), a method for aligning language models to follow natural language principles without using human feedback. RLCD trains a preference model using simulated preference pairs that contain both a high-quality and low-quality example, generated using contrasting positive and negative prompts. The preference model is then used to improve a base unaligned language model via reinforcement learning. Empirically, RLCD outperforms RLAIF (Bai et al., 2022b) and context distillation (Huang et al., 2022) baselines across three diverse alignment tasks--harmlessness, helpfulness, and story outline generation--and on both 7B and 30B model scales for preference data simulation.
H$_2$O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
Jul 19, 2023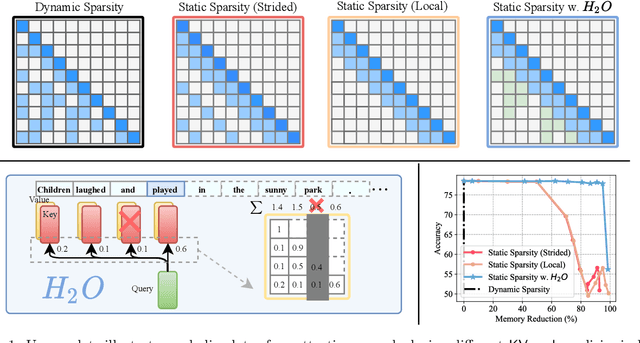
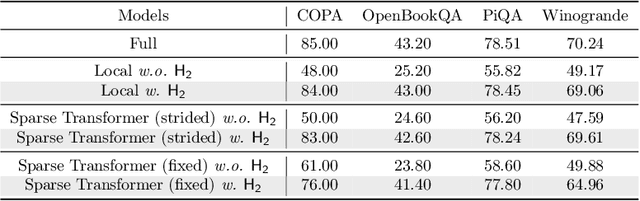
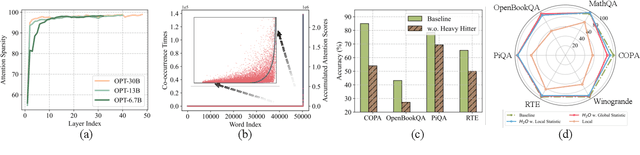

Large Language Models (LLMs), despite their recent impressive accomplishments, are notably cost-prohibitive to deploy, particularly for applications involving long-content generation, such as dialogue systems and story writing. Often, a large amount of transient state information, referred to as the KV cache, is stored in GPU memory in addition to model parameters, scaling linearly with the sequence length and batch size. In this paper, we introduce a novel approach for implementing the KV cache which significantly reduces its memory footprint. Our approach is based on the noteworthy observation that a small portion of tokens contributes most of the value when computing attention scores. We call these tokens Heavy Hitters (H$_2$). Through a comprehensive investigation, we find that (i) the emergence of H$_2$ is natural and strongly correlates with the frequent co-occurrence of tokens in the text, and (ii) removing them results in significant performance degradation. Based on these insights, we propose Heavy Hitter Oracle (H$_2$O), a KV cache eviction policy that dynamically retains a balance of recent and H$_2$ tokens. We formulate the KV cache eviction as a dynamic submodular problem and prove (under mild assumptions) a theoretical guarantee for our novel eviction algorithm which could help guide future work. We validate the accuracy of our algorithm with OPT, LLaMA, and GPT-NeoX across a wide range of tasks. Our implementation of H$_2$O with 20% heavy hitters improves the throughput over three leading inference systems DeepSpeed Zero-Inference, Hugging Face Accelerate, and FlexGen by up to 29$\times$, 29$\times$, and 3$\times$ on OPT-6.7B and OPT-30B. With the same batch size, H2O can reduce the latency by up to 1.9$\times$. The code is available at https://github.com/FMInference/H2O.
Landscape Surrogate: Learning Decision Losses for Mathematical Optimization Under Partial Information
Jul 18, 2023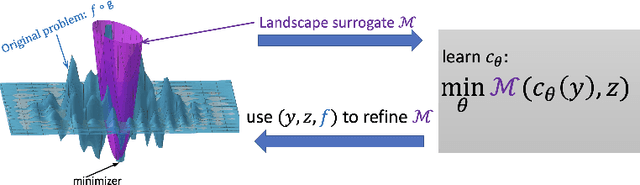
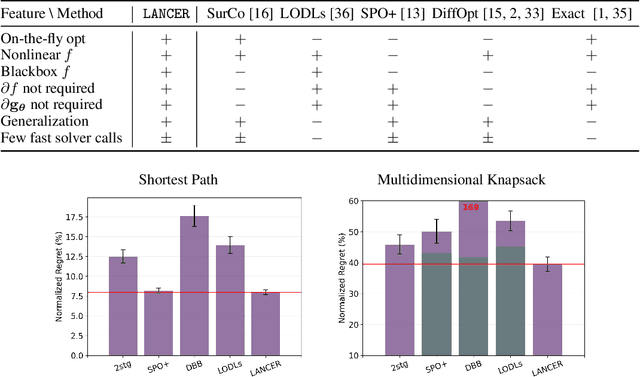
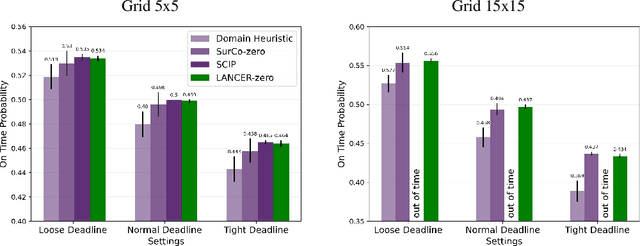

Recent works in learning-integrated optimization have shown promise in settings where the optimization problem is only partially observed or where general-purpose optimizers perform poorly without expert tuning. By learning an optimizer $\mathbf{g}$ to tackle these challenging problems with $f$ as the objective, the optimization process can be substantially accelerated by leveraging past experience. The optimizer can be trained with supervision from known optimal solutions or implicitly by optimizing the compound function $f\circ \mathbf{g}$. The implicit approach may not require optimal solutions as labels and is capable of handling problem uncertainty; however, it is slow to train and deploy due to frequent calls to optimizer $\mathbf{g}$ during both training and testing. The training is further challenged by sparse gradients of $\mathbf{g}$, especially for combinatorial solvers. To address these challenges, we propose using a smooth and learnable Landscape Surrogate $M$ as a replacement for $f\circ \mathbf{g}$. This surrogate, learnable by neural networks, can be computed faster than the solver $\mathbf{g}$, provides dense and smooth gradients during training, can generalize to unseen optimization problems, and is efficiently learned via alternating optimization. We test our approach on both synthetic problems, including shortest path and multidimensional knapsack, and real-world problems such as portfolio optimization, achieving comparable or superior objective values compared to state-of-the-art baselines while reducing the number of calls to $\mathbf{g}$. Notably, our approach outperforms existing methods for computationally expensive high-dimensional problems.
Extending Context Window of Large Language Models via Positional Interpolation
Jun 28, 2023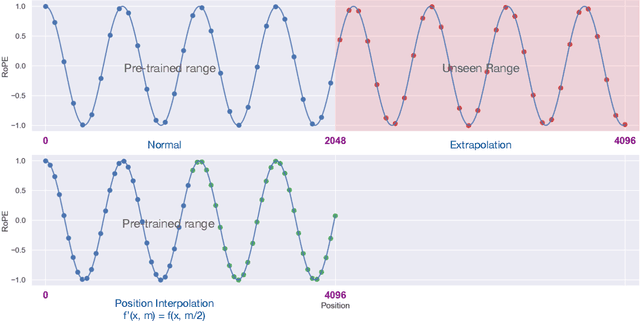
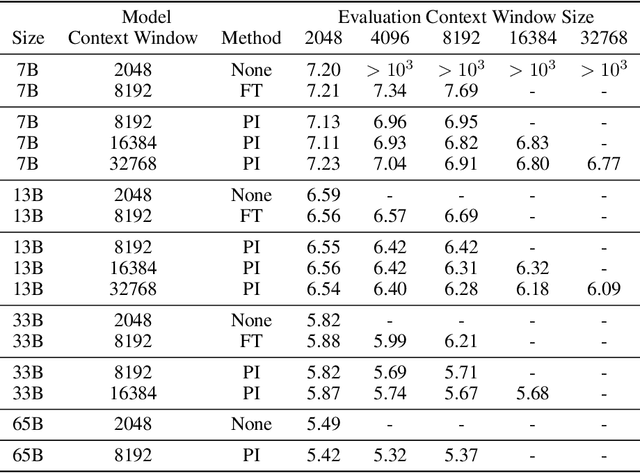
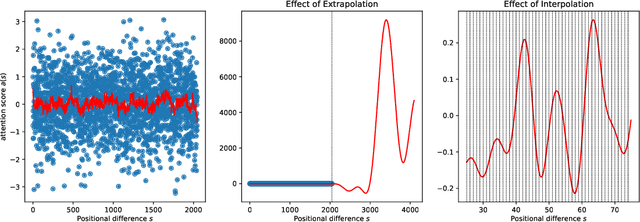
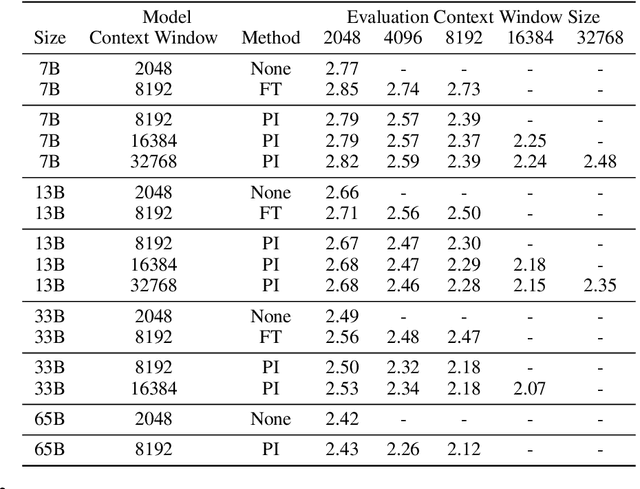
We present Position Interpolation (PI) that extends the context window sizes of RoPE-based pretrained LLMs such as LLaMA models to up to 32768 with minimal fine-tuning (within 1000 steps), while demonstrating strong empirical results on various tasks that require long context, including passkey retrieval, language modeling, and long document summarization from LLaMA 7B to 65B. Meanwhile, the extended model by Position Interpolation preserve quality relatively well on tasks within its original context window. To achieve this goal, Position Interpolation linearly down-scales the input position indices to match the original context window size, rather than extrapolating beyond the trained context length which may lead to catastrophically high attention scores that completely ruin the self-attention mechanism. Our theoretical study shows that the upper bound of interpolation is at least $\sim 600 \times$ smaller than that of extrapolation, further demonstrating its stability. Models extended via Position Interpolation retain its original architecture and can reuse most pre-existing optimization and infrastructure.
Scan and Snap: Understanding Training Dynamics and Token Composition in 1-layer Transformer
May 25, 2023
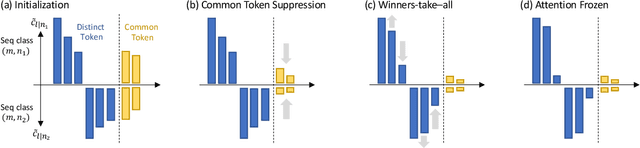
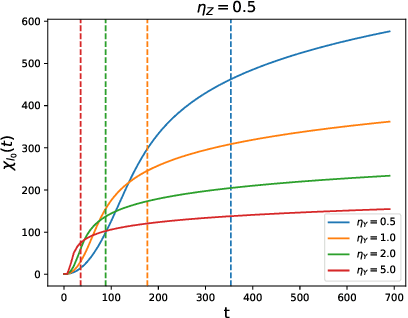
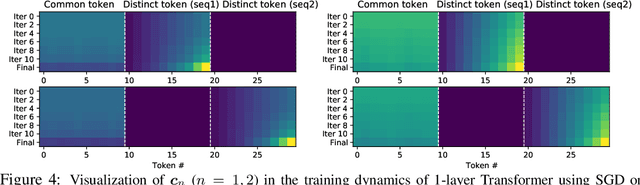
Transformer architecture has shown impressive performance in multiple research domains and has become the backbone of many neural network models. However, there is limited understanding on how it works. In particular, with a simple predictive loss, how the representation emerges from the gradient \emph{training dynamics} remains a mystery. In this paper, for 1-layer transformer with one self-attention layer plus one decoder layer, we analyze its SGD training dynamics for the task of next token prediction in a mathematically rigorous manner. We open the black box of the dynamic process of how the self-attention layer combines input tokens, and reveal the nature of underlying inductive bias. More specifically, with the assumption (a) no positional encoding, (b) long input sequence, and (c) the decoder layer learns faster than the self-attention layer, we prove that self-attention acts as a \emph{discriminative scanning algorithm}: starting from uniform attention, it gradually attends more to distinct key tokens for a specific next token to be predicted, and pays less attention to common key tokens that occur across different next tokens. Among distinct tokens, it progressively drops attention weights, following the order of low to high co-occurrence between the key and the query token in the training set. Interestingly, this procedure does not lead to winner-takes-all, but decelerates due to a \emph{phase transition} that is controllable by the learning rates of the two layers, leaving (almost) fixed token combination. We verify this \textbf{\emph{scan and snap}} dynamics on synthetic and real-world data (WikiText).