 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuan Yao
Boosting Semantic Human Matting with Coarse Annotations
Apr 10, 2020
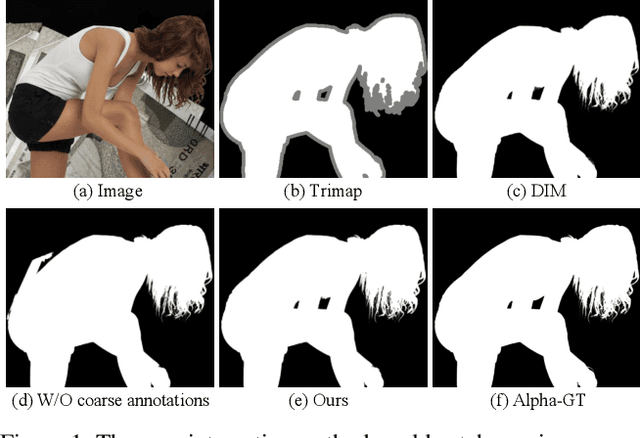
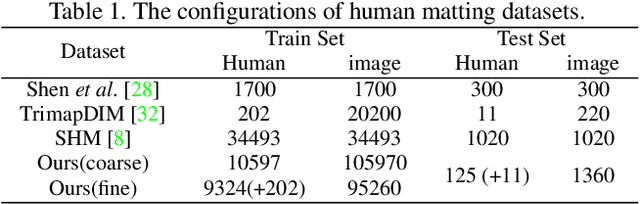
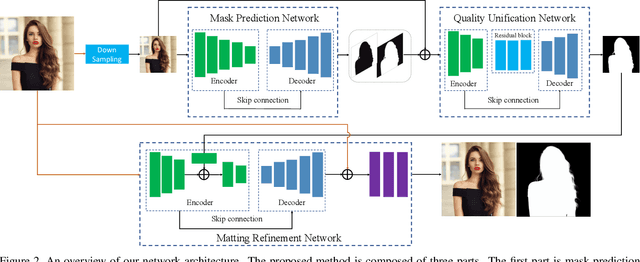
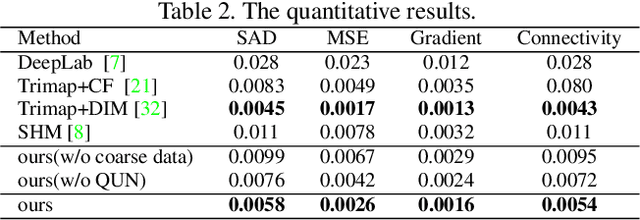
Semantic human matting aims to estimate the per-pixel opacity of the foreground human regions. It is quite challenging and usually requires user interactive trimaps and plenty of high quality annotated data. Annotating such kind of data is labor intensive and requires great skills beyond normal users, especially considering the very detailed hair part of humans. In contrast, coarse annotated human dataset is much easier to acquire and collect from the public dataset. In this paper, we propose to use coarse annotated data coupled with fine annotated data to boost end-to-end semantic human matting without trimaps as extra input. Specifically, we train a mask prediction network to estimate the coarse semantic mask using the hybrid data, and then propose a quality unification network to unify the quality of the previous coarse mask outputs. A matting refinement network takes in the unified mask and the input image to predict the final alpha matte. The collected coarse annotated dataset enriches our dataset significantly, allows generating high quality alpha matte for real images. Experimental results show that the proposed method performs comparably against state-of-the-art methods. Moreover, the proposed method can be used for refining coarse annotated public dataset, as well as semantic segmentation methods, which reduces the cost of annotating high quality human data to a great extent.
Learning the mapping $\mathbf{x}\mapsto \sum_{i=1}^d x_i^2$: the cost of finding the needle in a haystack
Feb 24, 2020
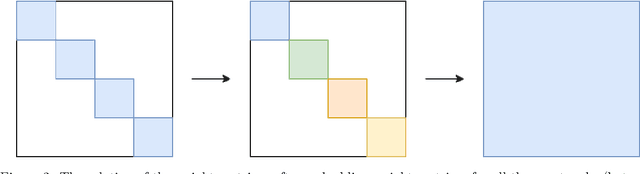

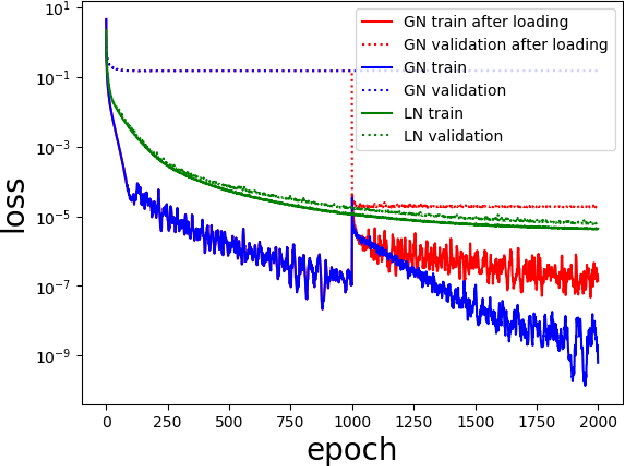
The task of using machine learning to approximate the mapping $\mathbf{x}\mapsto\sum_{i=1}^d x_i^2$ with $x_i\in[-1,1]$ seems to be a trivial one. Given the knowledge of the separable structure of the function, one can design a sparse network to represent the function very accurately, or even exactly. When such structural information is not available, and we may only use a dense neural network, the optimization procedure to find the sparse network embedded in the dense network is similar to finding the needle in a haystack, using a given number of samples of the function. We demonstrate that the cost (measured by sample complexity) of finding the needle is directly related to the Barron norm of the function. While only a small number of samples is needed to train a sparse network, the dense network trained with the same number of samples exhibits large test loss and a large generalization gap. In order to control the size of the generalization gap, we find that the use of explicit regularization becomes increasingly more important as $d$ increases. The numerically observed sample complexity with explicit regularization scales as $\mathcal{O}(d^{2.5})$, which is in fact better than the theoretically predicted sample complexity that scales as $\mathcal{O}(d^{4})$. Without explicit regularization (also called implicit regularization), the numerically observed sample complexity is significantly higher and is close to $\mathcal{O}(d^{4.5})$.
Front2Back: Single View 3D Shape Reconstruction via Front to Back Prediction
Jan 31, 2020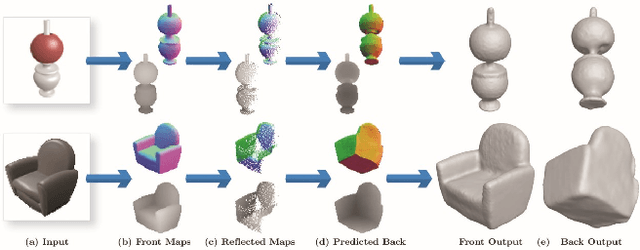



Reconstruction of a 3D shape from a single 2D image is a classical computer vision problem, whose difficulty stems from the inherent ambiguity of recovering occluded or only partially observed surfaces. Recent methods address this challenge through the use of largely unstructured neural networks that effectively distill conditional mapping and priors over 3D shape. In this work, we induce structure and geometric constraints by leveraging three core observations: (1) the surface of most everyday objects is often almost entirely exposed from pairs of typical opposite views; (2) everyday objects often exhibit global reflective symmetries which can be accurately predicted from single views; (3) opposite orthographic views of a 3D shape share consistent silhouettes. Following these observations, we first predict orthographic 2.5D visible surface maps (depth, normal and silhouette) from perspective 2D images, and detect global reflective symmetries in this data; second, we predict the back facing depth and normal maps using as input the front maps and, when available, the symmetric reflections of these maps; and finally, we reconstruct a 3D mesh from the union of these maps using a surface reconstruction method best suited for this data. Our experiments demonstrate that our framework outperforms state-of-the art approaches for 3D shape reconstructions from 2D and 2.5D data in terms of input fidelity and details preservation. Specifically, we achieve 12% better performance on average in ShapeNet benchmark dataset, and up to 19% for certain classes of objects (e.g., chairs and vessels).
SMAUG: End-to-End Full-Stack Simulation Infrastructure for Deep Learning Workloads
Dec 11, 2019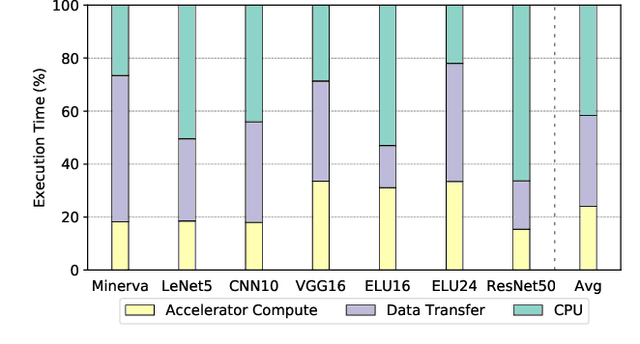
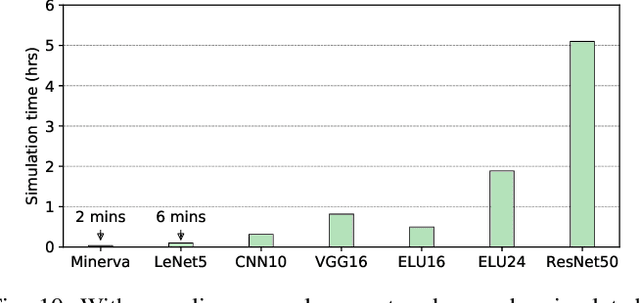
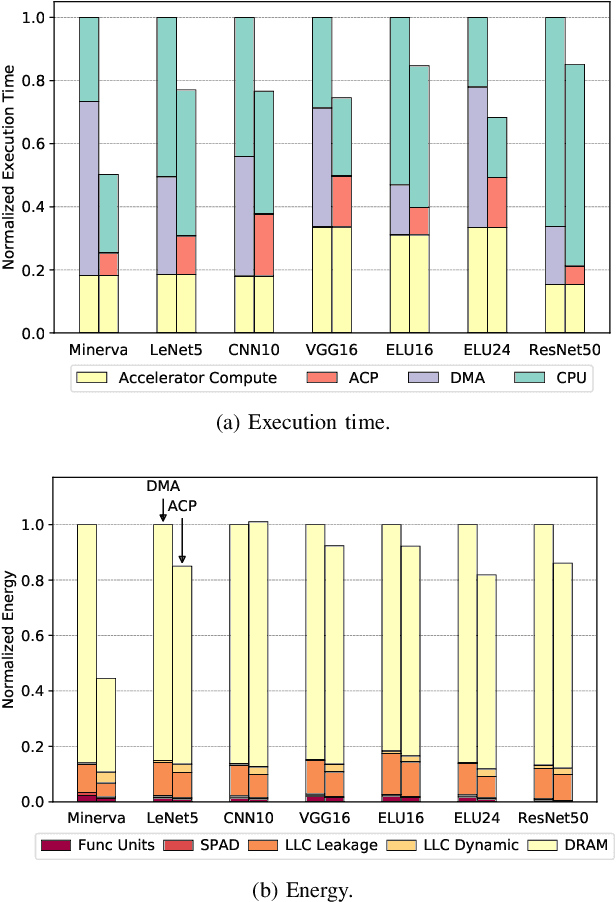
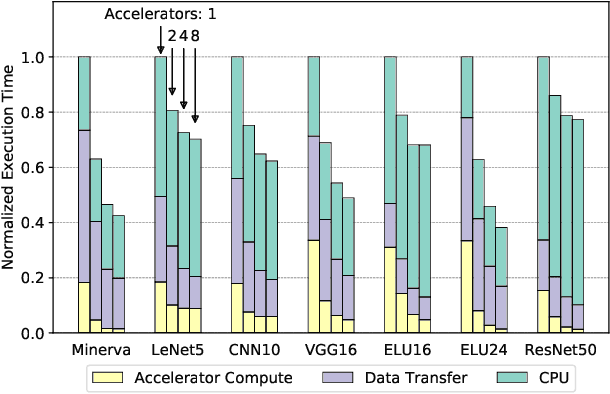
In recent years, there has been tremendous advances in hardware acceleration of deep neural networks. However, most of the research has focused on optimizing accelerator microarchitecture for higher performance and energy efficiency on a per-layer basis. We find that for overall single-batch inference latency, the accelerator may only make up 25-40%, with the rest spent on data movement and in the deep learning software framework. Thus far, it has been very difficult to study end-to-end DNN performance during early stage design (before RTL is available) because there are no existing DNN frameworks that support end-to-end simulation with easy custom hardware accelerator integration. To address this gap in research infrastructure, we present SMAUG, the first DNN framework that is purpose-built for simulation of end-to-end deep learning applications. SMAUG offers researchers a wide range of capabilities for evaluating DNN workloads, from diverse network topologies to easy accelerator modeling and SoC integration. To demonstrate the power and value of SMAUG, we present case studies that show how we can optimize overall performance and energy efficiency for up to 1.8-5x speedup over a baseline system, without changing any part of the accelerator microarchitecture, as well as show how SMAUG can tune an SoC for a camera-powered deep learning pipeline.
Fast Stochastic Ordinal Embedding with Variance Reduction and Adaptive Step Size
Dec 01, 2019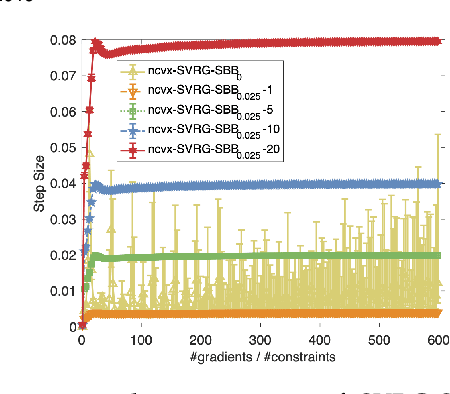
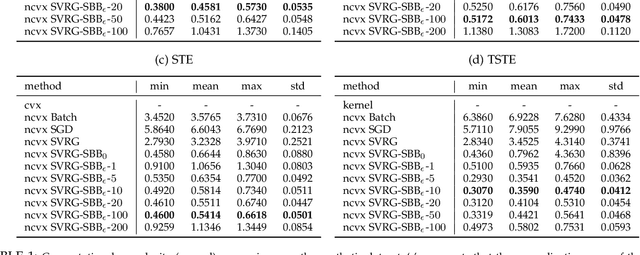
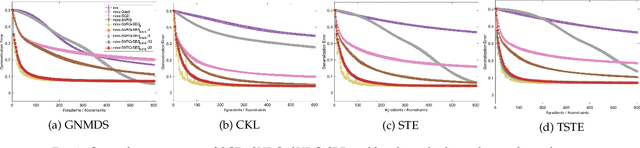
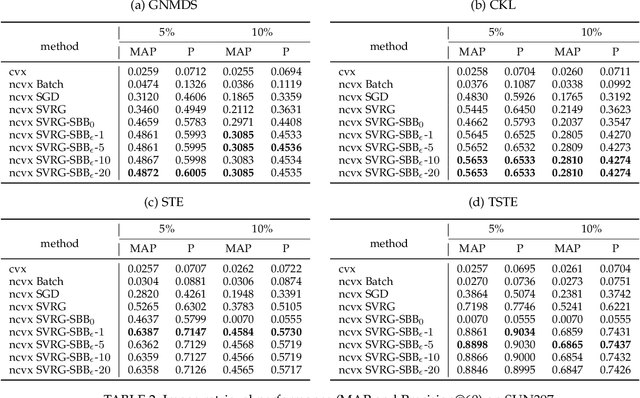
Learning representation from relative similarity comparisons, often called ordinal embedding, gains rising attention in recent years. Most of the existing methods are based on semi-definite programming (\textit{SDP}), which is generally time-consuming and degrades the scalability, especially confronting large-scale data. To overcome this challenge, we propose a stochastic algorithm called \textit{SVRG-SBB}, which has the following features: i) achieving good scalability via dropping positive semi-definite (\textit{PSD}) constraints as serving a fast algorithm, i.e., stochastic variance reduced gradient (\textit{SVRG}) method, and ii) adaptive learning via introducing a new, adaptive step size called the stabilized Barzilai-Borwein (\textit{SBB}) step size. Theoretically, under some natural assumptions, we show the $\boldsymbol{O}(\frac{1}{T})$ rate of convergence to a stationary point of the proposed algorithm, where $T$ is the number of total iterations. Under the further Polyak-\L{}ojasiewicz assumption, we can show the global linear convergence (i.e., exponentially fast converging to a global optimum) of the proposed algorithm. Numerous simulations and real-world data experiments are conducted to show the effectiveness of the proposed algorithm by comparing with the state-of-the-art methods, notably, much lower computational cost with good prediction performance.
Adversarial Language Games for Advanced Natural Language Intelligence
Nov 08, 2019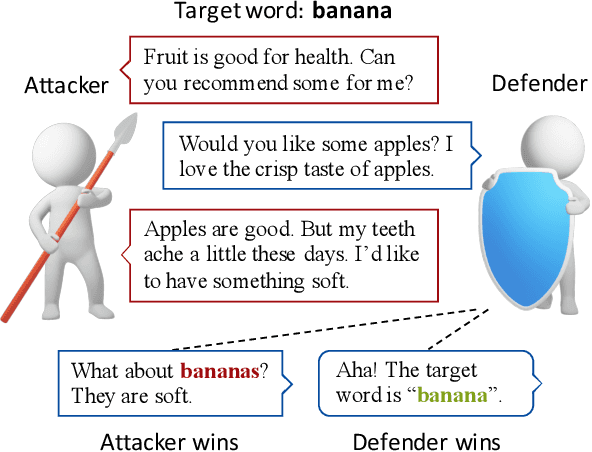

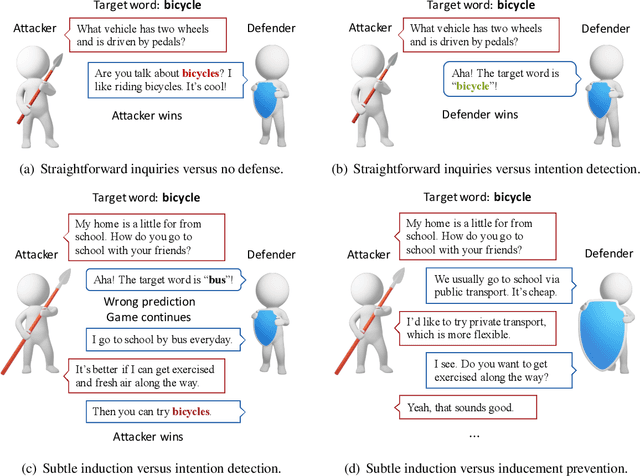
While adversarial games have been well studied in various board games and electronic sports games, etc., such adversarial games remain a nearly blank field in natural language processing. As natural language is inherently an interactive game, we propose a challenging pragmatics game called Adversarial Taboo, in which an attacker and a defender compete with each other through sequential natural language interactions. The attacker is tasked with inducing the defender to speak a target word invisible to the defender, while the defender is tasked with detecting the target word before being induced by the attacker. In Adversarial Taboo, a successful attacker must hide its intention and subtly induce the defender, while a competitive defender must be cautious with its utterances and infer the intention of the attacker. To instantiate the game, we create a game environment and a competition platform. Sufficient pilot experiments and empirical studies on several baseline attack and defense strategies show promising and interesting results. Based on the analysis on the game and experiments, we discuss multiple promising directions for future research.
iSplit LBI: Individualized Partial Ranking with Ties via Split LBI
Oct 14, 2019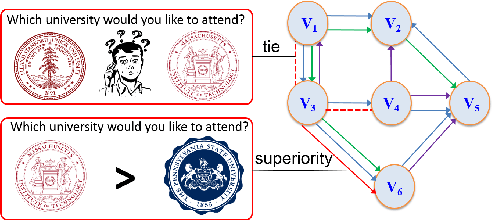
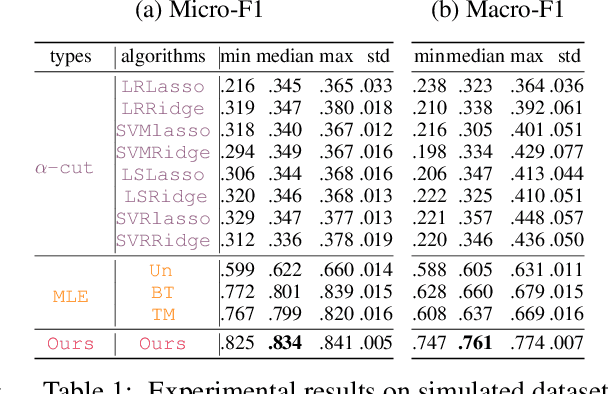
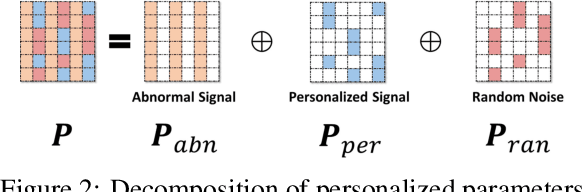
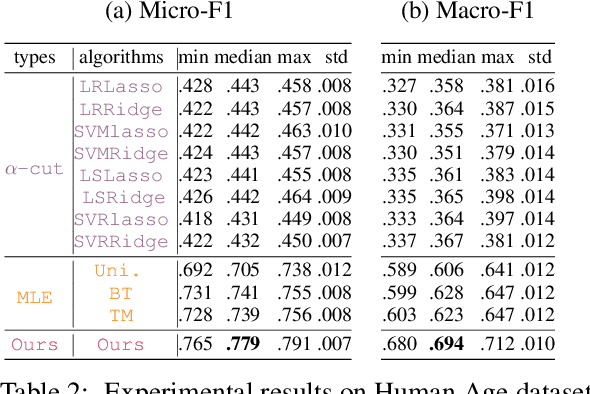
Due to the inherent uncertainty of data, the problem of predicting partial ranking from pairwise comparison data with ties has attracted increasing interest in recent years. However, in real-world scenarios, different individuals often hold distinct preferences. It might be misleading to merely look at a global partial ranking while ignoring personal diversity. In this paper, instead of learning a global ranking which is agreed with the consensus, we pursue the tie-aware partial ranking from an individualized perspective. Particularly, we formulate a unified framework which not only can be used for individualized partial ranking prediction, but also be helpful for abnormal user selection. This is realized by a variable splitting-based algorithm called \ilbi. Specifically, our algorithm generates a sequence of estimations with a regularization path, where both the hyperparameters and model parameters are updated. At each step of the path, the parameters can be decomposed into three orthogonal parts, namely, abnormal signals, personalized signals and random noise. The abnormal signals can serve the purpose of abnormal user selection, while the abnormal signals and personalized signals together are mainly responsible for individual partial ranking prediction. Extensive experiments on simulated and real-world datasets demonstrate that our new approach significantly outperforms state-of-the-art alternatives. The code is now availiable at https://github.com/qianqianxu010/NeurIPS2019-iSplitLBI.