 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuan Qi
SpellGCN: Incorporating Phonological and Visual Similarities into Language Models for Chinese Spelling Check
Apr 26, 2020

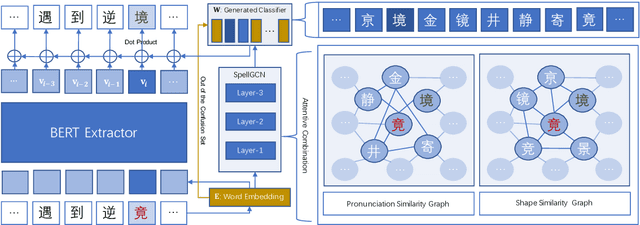
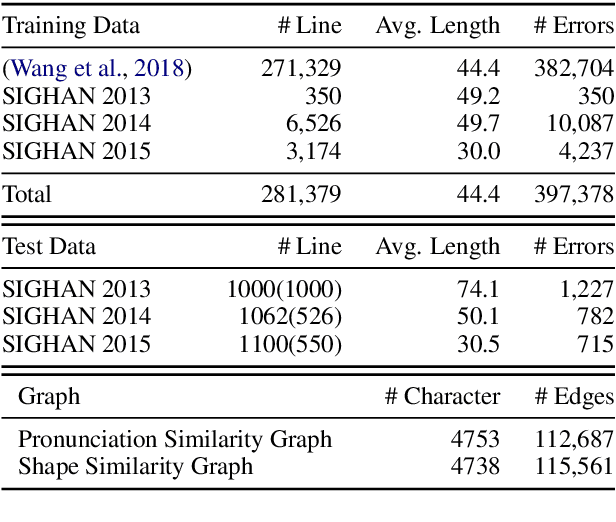
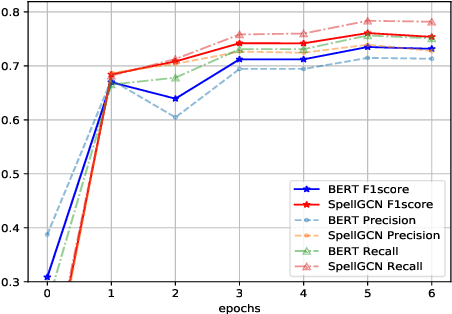
Chinese Spelling Check (CSC) is a task to detect and correct spelling errors in Chinese natural language. Existing methods have made attempts to incorporate the similarity knowledge between Chinese characters. However, they take the similarity knowledge as either an external input resource or just heuristic rules. This paper proposes to incorporate phonological and visual similarity knowledge into language models for CSC via a specialized graph convolutional network (SpellGCN). The model builds a graph over the characters, and SpellGCN is learned to map this graph into a set of inter-dependent character classifiers. These classifiers are applied to the representations extracted by another network, such as BERT, enabling the whole network to be end-to-end trainable. Experiments~\footnote{The dataset and all code for this paper are available at https://github.com/ACL2020SpellGCN/SpellGCN } are conducted on three human-annotated datasets. Our method achieves superior performance against previous models by a large margin.
Intention Propagation for Multi-agent Reinforcement Learning
Apr 19, 2020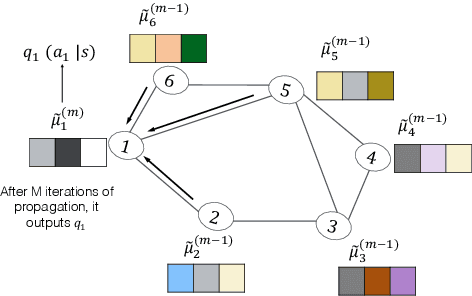

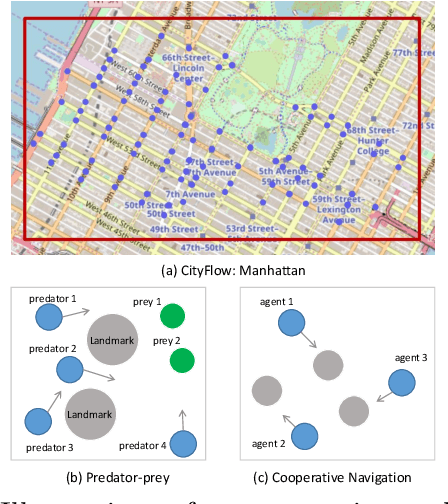
A hallmark of an AI agent is to mimic human beings to understand and interact with others. In this paper, we propose a collaborative multi-agent reinforcement learning algorithm to learn a \emph{joint} policy through the interactions over agents. To make a joint decision over the group, each agent makes an initial decision and tells its policy to its neighbors. Then each agent modifies its own policy properly based on received messages and spreads out its plan. As this intention propagation procedure goes on, we prove that it converges to a mean-field approximation of the joint policy with the framework of neural embedded probabilistic inference. We evaluate our algorithm on several large scale challenging tasks and demonstrate that it outperforms previous state-of-the-arts.
RNE: A Scalable Network Embedding for Billion-scale Recommendation
Apr 09, 2020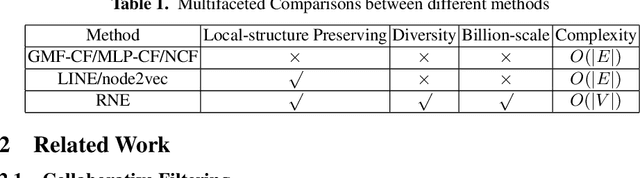
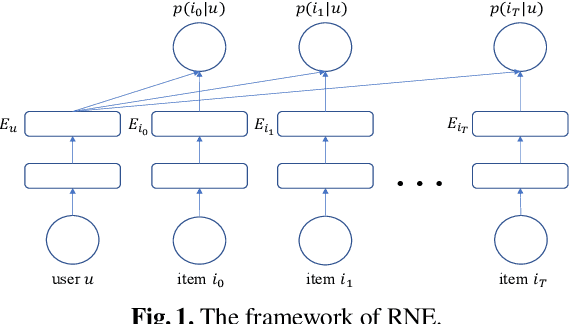


Nowadays designing a real recommendation system has been a critical problem for both academic and industry. However, due to the huge number of users and items, the diversity and dynamic property of the user interest, how to design a scalable recommendation system, which is able to efficiently produce effective and diverse recommendation results on billion-scale scenarios, is still a challenging and open problem for existing methods. In this paper, given the user-item interaction graph, we propose RNE, a data-efficient Recommendation-based Network Embedding method, to give personalized and diverse items to users. Specifically, we propose a diversity- and dynamics-aware neighbor sampling method for network embedding. On the one hand, the method is able to preserve the local structure between the users and items while modeling the diversity and dynamic property of the user interest to boost the recommendation quality. On the other hand the sampling method can reduce the complexity of the whole method theoretically to make it possible for billion-scale recommendation. We also implement the designed algorithm in a distributed way to further improves its scalability. Experimentally, we deploy RNE on a recommendation scenario of Taobao, the largest E-commerce platform in China, and train it on a billion-scale user-item graph. As is shown on several online metrics on A/B testing, RNE is able to achieve both high-quality and diverse results compared with CF-based methods. We also conduct the offline experiments on Pinterest dataset comparing with several state-of-the-art recommendation methods and network embedding methods. The results demonstrate that our method is able to produce a good result while runs much faster than the baseline methods.
NetDP: An Industrial-Scale Distributed Network Representation Framework for Default Prediction in Ant Credit Pay
Apr 01, 2020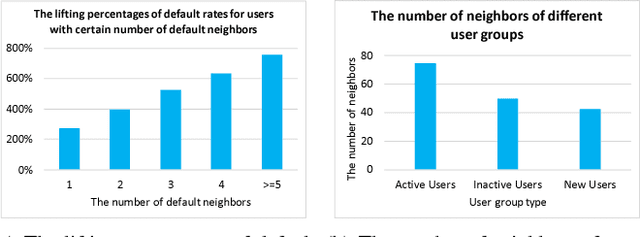
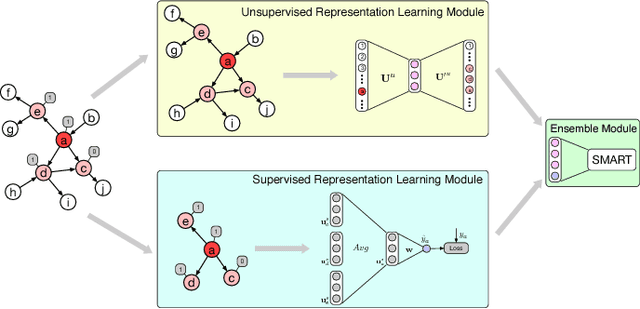

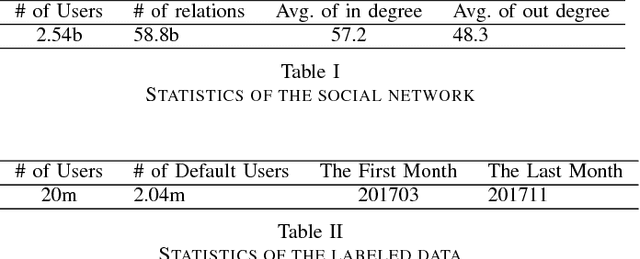
Ant Credit Pay is a consumer credit service in Ant Financial Service Group. Similar to credit card, loan default is one of the major risks of this credit product. Hence, effective algorithm for default prediction is the key to losses reduction and profits increment for the company. However, the challenges facing in our scenario are different from those in conventional credit card service. The first one is scalability. The huge volume of users and their behaviors in Ant Financial requires the ability to process industrial-scale data and perform model training efficiently. The second challenges is the cold-start problem. Different from the manual review for credit card application in conventional banks, the credit limit of Ant Credit Pay is automatically offered to users based on the knowledge learned from big data. However, default prediction for new users is suffered from lack of enough credit behaviors. It requires that the proposal should leverage other new data source to alleviate the cold-start problem. Considering the above challenges and the special scenario in Ant Financial, we try to incorporate default prediction with network information to alleviate the cold-start problem. In this paper, we propose an industrial-scale distributed network representation framework, termed NetDP, for default prediction in Ant Credit Pay. The proposal explores network information generated by various interaction between users, and blends unsupervised and supervised network representation in a unified framework for default prediction problem. Moreover, we present a parameter-server-based distributed implement of our proposal to handle the scalability challenge. Experimental results demonstrate the effectiveness of our proposal, especially in cold-start problem, as well as the efficiency for industrial-scale dataset.
Local Contextual Attention with Hierarchical Structure for Dialogue Act Recognition
Mar 12, 2020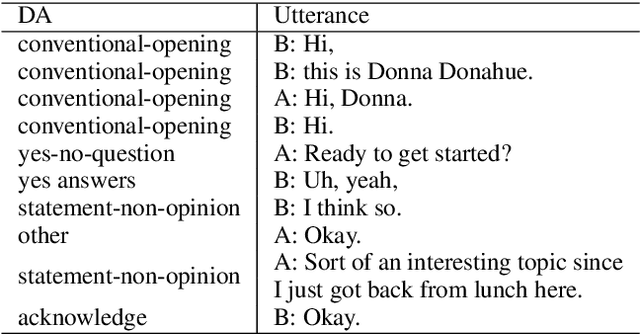
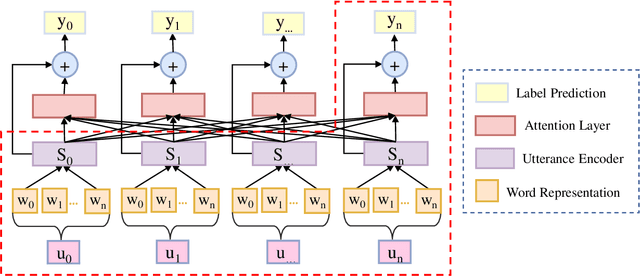
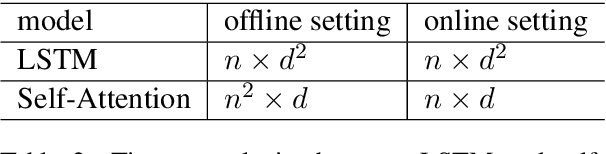
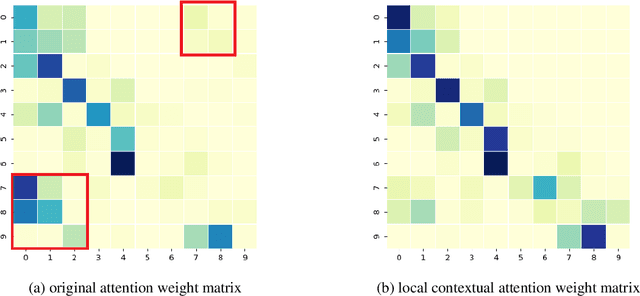
Dialogue act recognition is a fundamental task for an intelligent dialogue system. Previous work models the whole dialog to predict dialog acts, which may bring the noise from unrelated sentences. In this work, we design a hierarchical model based on self-attention to capture intra-sentence and inter-sentence information. We revise the attention distribution to focus on the local and contextual semantic information by incorporating the relative position information between utterances. Based on the found that the length of dialog affects the performance, we introduce a new dialog segmentation mechanism to analyze the effect of dialog length and context padding length under online and offline settings. The experiment shows that our method achieves promising performance on two datasets: Switchboard Dialogue Act and DailyDialog with the accuracy of 80.34\% and 85.81\% respectively. Visualization of the attention weights shows that our method can learn the context dependency between utterances explicitly.
InfDetect: a Large Scale Graph-based Fraud Detection System for E-Commerce Insurance
Mar 12, 2020
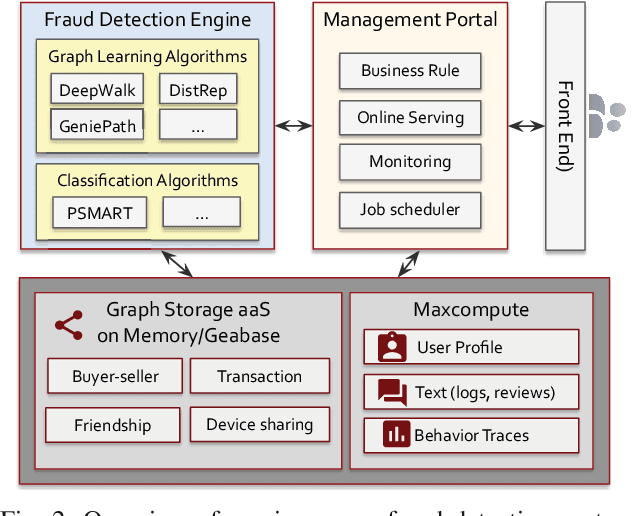
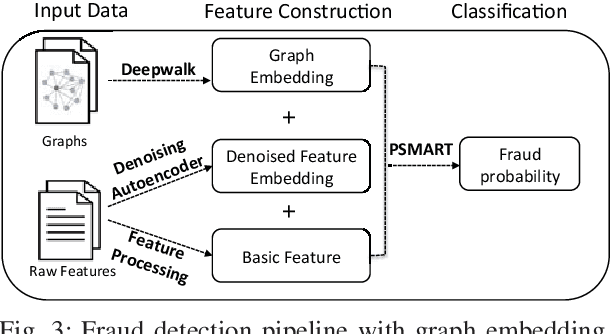
The insurance industry has been creating innovative products around the emerging online shopping activities. Such e-commerce insurance is designed to protect buyers from potential risks such as impulse purchases and counterfeits. Fraudulent claims towards online insurance typically involve multiple parties such as buyers, sellers, and express companies, and they could lead to heavy financial losses. In order to uncover the relations behind organized fraudsters and detect fraudulent claims, we developed a large-scale insurance fraud detection system, i.e., InfDetect, which provides interfaces for commonly used graphs, standard data processing procedures, and a uniform graph learning platform. InfDetect is able to process big graphs containing up to 100 millions of nodes and billions of edges. In this paper, we investigate different graphs to facilitate fraudster mining, such as a device-sharing graph, a transaction graph, a friendship graph, and a buyer-seller graph. These graphs are fed to a uniform graph learning platform containing supervised and unsupervised graph learning algorithms. Cases on widely applied e-commerce insurance are described to demonstrate the usage and capability of our system. InfDetect has successfully detected thousands of fraudulent claims and saved over tens of thousands of dollars daily.
Generating Natural Language Adversarial Examples on a Large Scale with Generative Models
Mar 10, 2020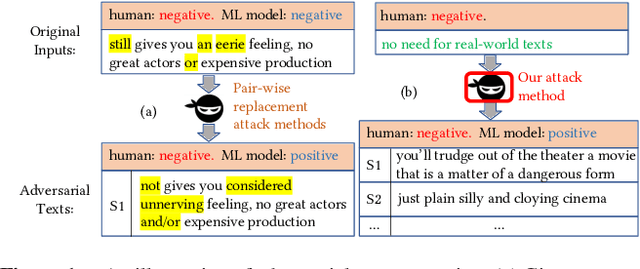

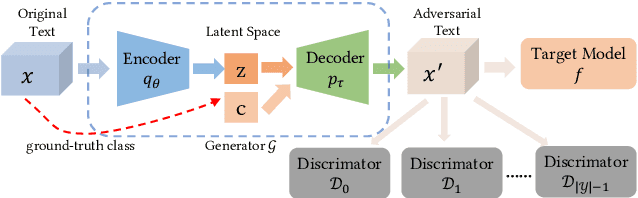

Today text classification models have been widely used. However, these classifiers are found to be easily fooled by adversarial examples. Fortunately, standard attacking methods generate adversarial texts in a pair-wise way, that is, an adversarial text can only be created from a real-world text by replacing a few words. In many applications, these texts are limited in numbers, therefore their corresponding adversarial examples are often not diverse enough and sometimes hard to read, thus can be easily detected by humans and cannot create chaos at a large scale. In this paper, we propose an end to end solution to efficiently generate adversarial texts from scratch using generative models, which are not restricted to perturbing the given texts. We call it unrestricted adversarial text generation. Specifically, we train a conditional variational autoencoder (VAE) with an additional adversarial loss to guide the generation of adversarial examples. Moreover, to improve the validity of adversarial texts, we utilize discrimators and the training framework of generative adversarial networks (GANs) to make adversarial texts consistent with real data. Experimental results on sentiment analysis demonstrate the scalability and efficiency of our method. It can attack text classification models with a higher success rate than existing methods, and provide acceptable quality for humans in the meantime.
Practical Privacy Preserving POI Recommendation
Mar 05, 2020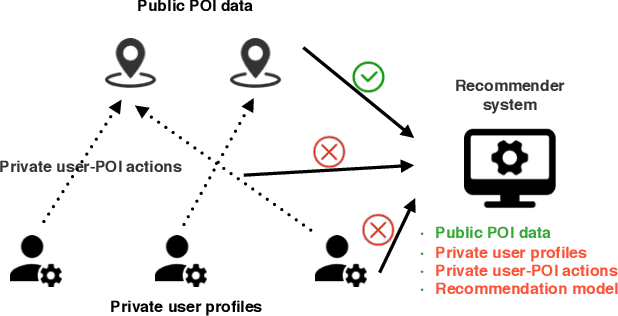

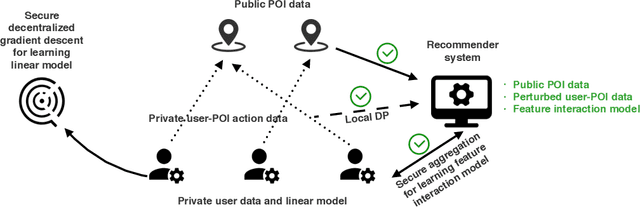

Point-of-Interest (POI) recommendation has been extensively studied and successfully applied in industry recently. However, most existing approaches build centralized models on the basis of collecting users' data. Both private data and models are held by the recommender, which causes serious privacy concerns. In this paper, we propose a novel Privacy preserving POI Recommendation (PriRec) framework. First, to protect data privacy, users' private data (features and actions) are kept on their own side, e.g., Cellphone or Pad. Meanwhile, the public data need to be accessed by all the users are kept by the recommender to reduce the storage costs of users' devices. Those public data include: (1) static data only related to the status of POI, such as POI categories, and (2) dynamic data depend on user-POI actions such as visited counts. The dynamic data could be sensitive, and we develop local differential privacy techniques to release such data to public with privacy guarantees. Second, PriRec follows the representations of Factorization Machine (FM) that consists of linear model and the feature interaction model. To protect the model privacy, the linear models are saved on users' side, and we propose a secure decentralized gradient descent protocol for users to learn it collaboratively. The feature interaction model is kept by the recommender since there is no privacy risk, and we adopt secure aggregation strategy in federated learning paradigm to learn it. To this end, PriRec keeps users' private raw data and models in users' own hands, and protects user privacy to a large extent. We apply PriRec in real-world datasets, and comprehensive experiments demonstrate that, compared with FM, PriRec achieves comparable or even better recommendation accuracy.