 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYu Wang
Learning Self-Supervised Low-Rank Network for Single-Stage Weakly and Semi-Supervised Semantic Segmentation
Mar 19, 2022
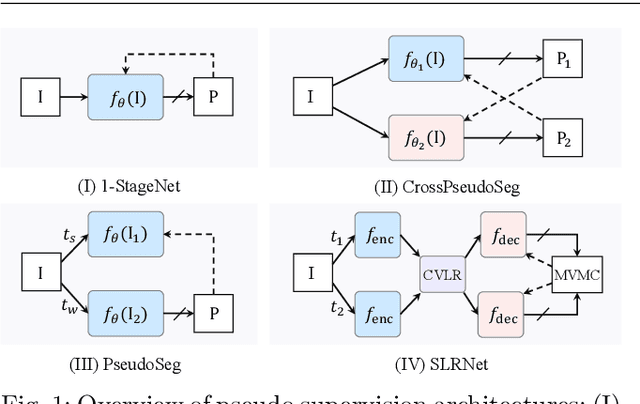
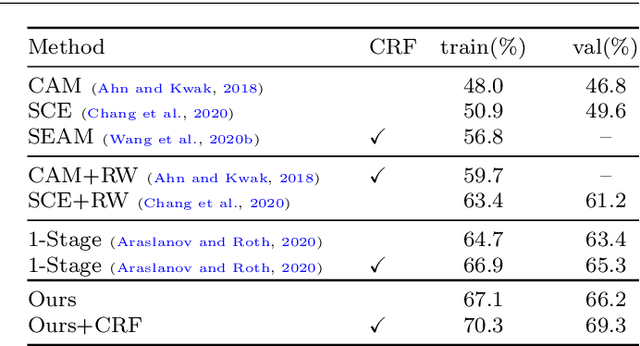
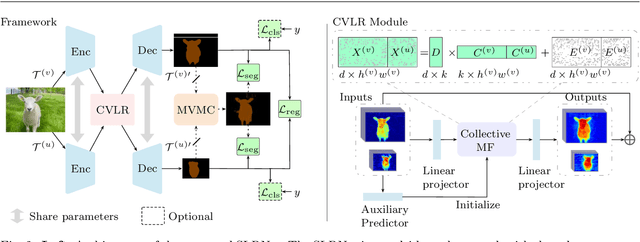
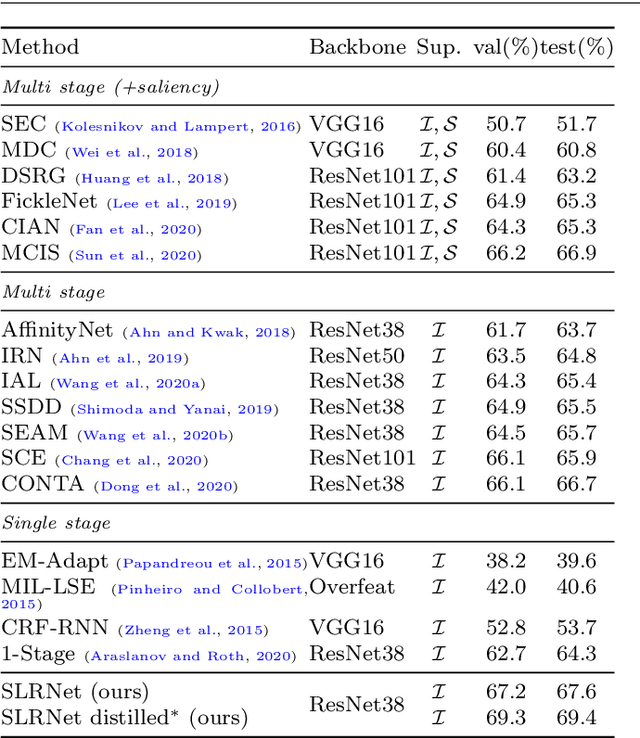
Semantic segmentation with limited annotations, such as weakly supervised semantic segmentation (WSSS) and semi-supervised semantic segmentation (SSSS), is a challenging task that has attracted much attention recently. Most leading WSSS methods employ a sophisticated multi-stage training strategy to estimate pseudo-labels as precise as possible, but they suffer from high model complexity. In contrast, there exists another research line that trains a single network with image-level labels in one training cycle. However, such a single-stage strategy often performs poorly because of the compounding effect caused by inaccurate pseudo-label estimation. To address this issue, this paper presents a Self-supervised Low-Rank Network (SLRNet) for single-stage WSSS and SSSS. The SLRNet uses cross-view self-supervision, that is, it simultaneously predicts several complementary attentive LR representations from different views of an image to learn precise pseudo-labels. Specifically, we reformulate the LR representation learning as a collective matrix factorization problem and optimize it jointly with the network learning in an end-to-end manner. The resulting LR representation deprecates noisy information while capturing stable semantics across different views, making it robust to the input variations, thereby reducing overfitting to self-supervision errors. The SLRNet can provide a unified single-stage framework for various label-efficient semantic segmentation settings: 1) WSSS with image-level labeled data, 2) SSSS with a few pixel-level labeled data, and 3) SSSS with a few pixel-level labeled data and many image-level labeled data. Extensive experiments on the Pascal VOC 2012, COCO, and L2ID datasets demonstrate that our SLRNet outperforms both state-of-the-art WSSS and SSSS methods with a variety of different settings, proving its good generalizability and efficacy.
Explore-Bench: Data Sets, Metrics and Evaluations for Frontier-based and Deep-reinforcement-learning-based Autonomous Exploration
Feb 24, 2022
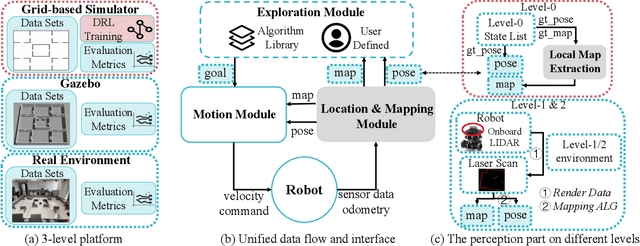
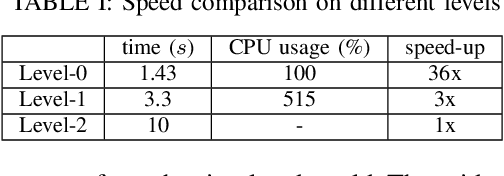
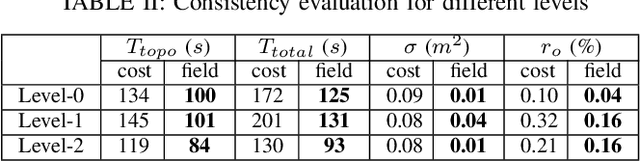
Autonomous exploration and mapping of unknown terrains employing single or multiple robots is an essential task in mobile robotics and has therefore been widely investigated. Nevertheless, given the lack of unified data sets, metrics, and platforms to evaluate the exploration approaches, we develop an autonomous robot exploration benchmark entitled Explore-Bench. The benchmark involves various exploration scenarios and presents two types of quantitative metrics to evaluate exploration efficiency and multi-robot cooperation. Explore-Bench is extremely useful as, recently, deep reinforcement learning (DRL) has been widely used for robot exploration tasks and achieved promising results. However, training DRL-based approaches requires large data sets, and additionally, current benchmarks rely on realistic simulators with a slow simulation speed, which is not appropriate for training exploration strategies. Hence, to support efficient DRL training and comprehensive evaluation, the suggested Explore-Bench designs a 3-level platform with a unified data flow and $12 \times$ speed-up that includes a grid-based simulator for fast evaluation and efficient training, a realistic Gazebo simulator, and a remotely accessible robot testbed for high-accuracy tests in physical environments. The practicality of the proposed benchmark is highlighted with the application of one DRL-based and three frontier-based exploration approaches. Furthermore, we analyze the performance differences and provide some insights about the selection and design of exploration methods. Our benchmark is available at https://github.com/efc-robot/Explore-Bench.
A Data Augmentation Method for Fully Automatic Brain Tumor Segmentation
Feb 18, 2022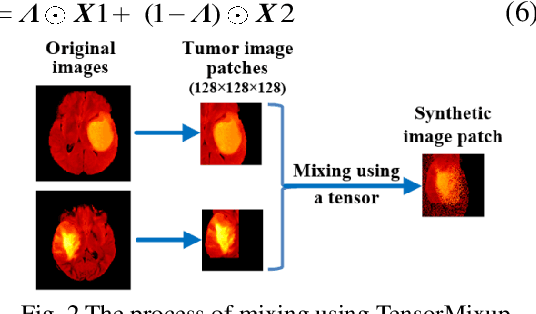

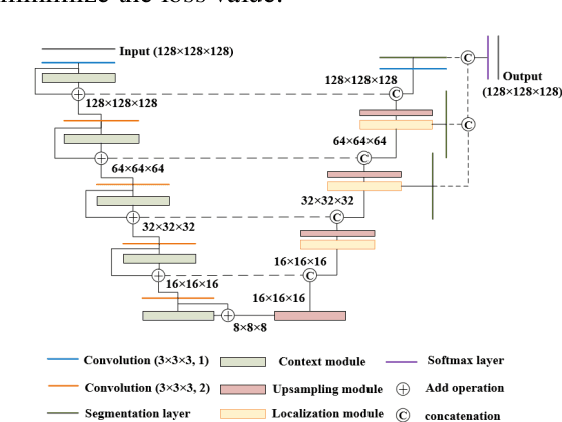
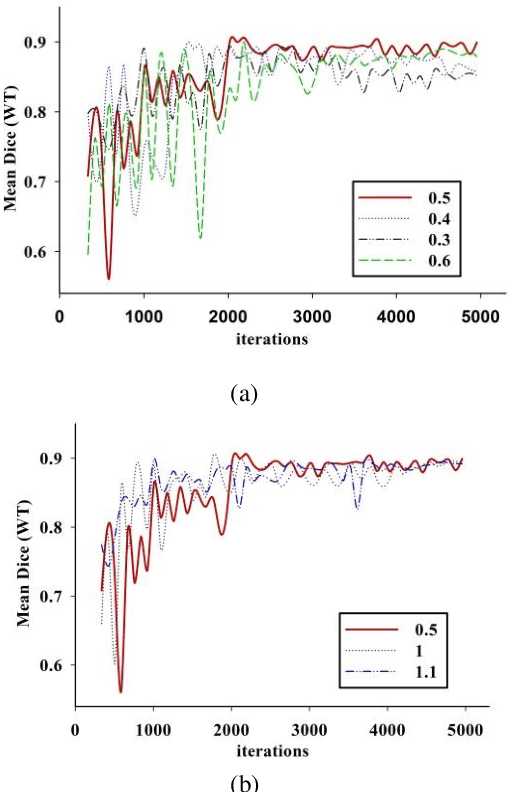
Automatic segmentation of glioma and its subregions is of great significance for diagnosis, treatment and monitoring of disease. In this paper, an augmentation method, called TensorMixup, was proposed and applied to the three dimensional U-Net architecture for brain tumor segmentation. The main ideas included that first, two image patches with size of 128 in three dimensions were selected according to glioma information of ground truth labels from the magnetic resonance imaging data of any two patients with the same modality. Next, a tensor in which all elements were independently sampled from Beta distribution was used to mix the image patches. Then the tensor was mapped to a matrix which was used to mix the one-hot encoded labels of the above image patches. Therefore, a new image and its one-hot encoded label were synthesized. Finally, the new data was used to train the model which could be used to segment glioma. The experimental results show that the mean accuracy of Dice scores are 91.32%, 85.67%, and 82.20% respectively on the whole tumor, tumor core, and enhancing tumor segmentation, which proves that the proposed TensorMixup is feasible and effective for brain tumor segmentation.
ChemicalX: A Deep Learning Library for Drug Pair Scoring
Feb 14, 2022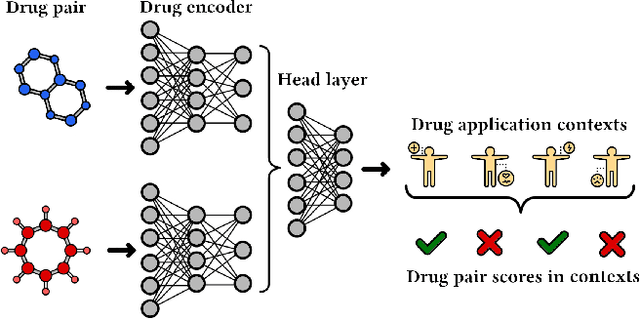
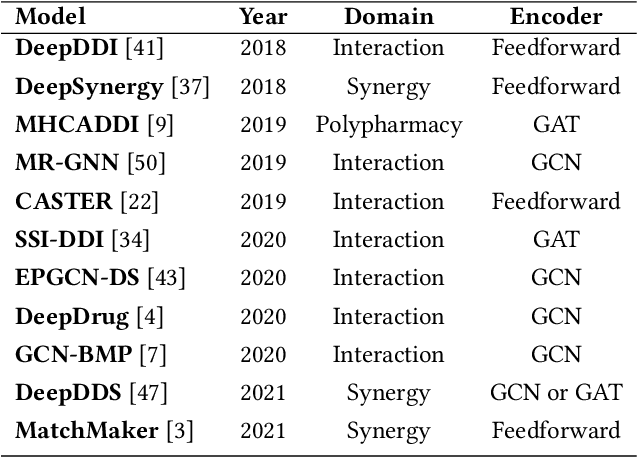
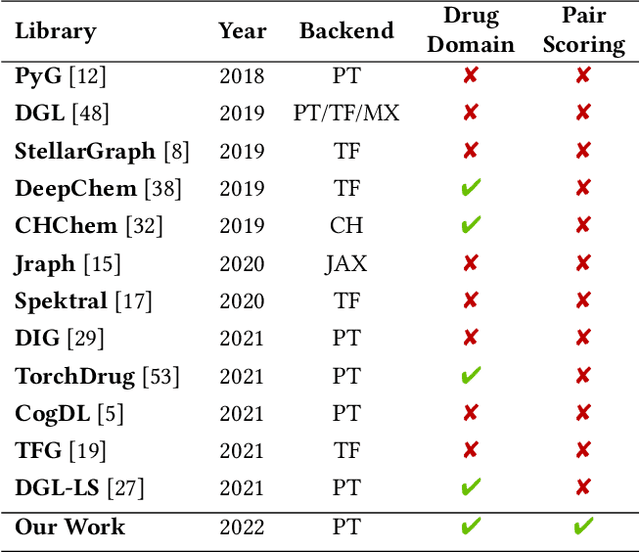
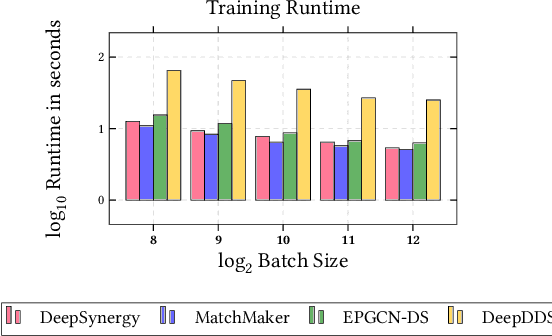
In this paper, we introduce ChemicalX, a PyTorch-based deep learning library designed for providing a range of state of the art models to solve the drug pair scoring task. The primary objective of the library is to make deep drug pair scoring models accessible to machine learning researchers and practitioners in a streamlined framework.The design of ChemicalX reuses existing high level model training utilities, geometric deep learning, and deep chemistry layers from the PyTorch ecosystem. Our system provides neural network layers, custom pair scoring architectures, data loaders, and batch iterators for end users. We showcase these features with example code snippets and case studies to highlight the characteristics of ChemicalX. A range of experiments on real world drug-drug interaction, polypharmacy side effect, and combination synergy prediction tasks demonstrate that the models available in ChemicalX are effective at solving the pair scoring task. Finally, we show that ChemicalX could be used to train and score machine learning models on large drug pair datasets with hundreds of thousands of compounds on commodity hardware.
Large-scale Personalized Video Game Recommendation via Social-aware Contextualized Graph Neural Network
Feb 11, 2022
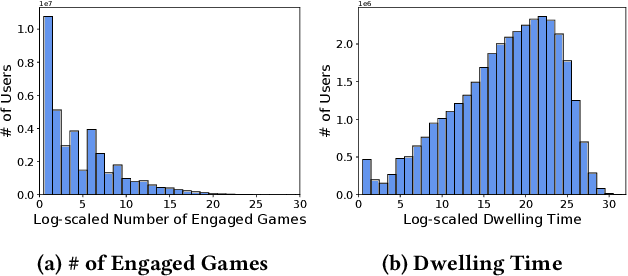
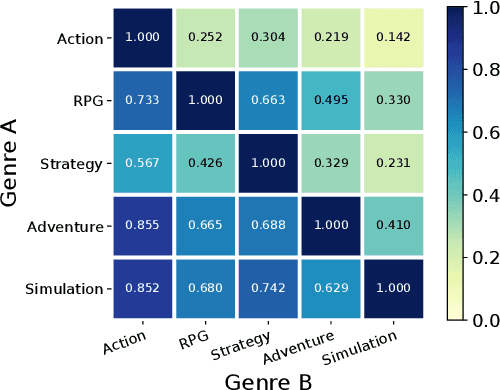
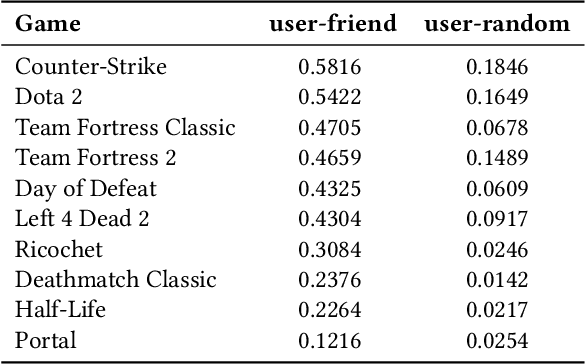
Because of the large number of online games available nowadays, online game recommender systems are necessary for users and online game platforms. The former can discover more potential online games of their interests, and the latter can attract users to dwell longer in the platform. This paper investigates the characteristics of user behaviors with respect to the online games on the Steam platform. Based on the observations, we argue that a satisfying recommender system for online games is able to characterize: personalization, game contextualization and social connection. However, simultaneously solving all is rather challenging for game recommendation. Firstly, personalization for game recommendation requires the incorporation of the dwelling time of engaged games, which are ignored in existing methods. Secondly, game contextualization should reflect the complex and high-order properties of those relations. Last but not least, it is problematic to use social connections directly for game recommendations due to the massive noise within social connections. To this end, we propose a Social-aware Contextualized Graph Neural Recommender System (SCGRec), which harnesses three perspectives to improve game recommendation. We conduct a comprehensive analysis of users' online game behaviors, which motivates the necessity of handling those three characteristics in the online game recommendation.
Multi-UAV Coverage Planning with Limited Endurance in Disaster Environment
Jan 25, 2022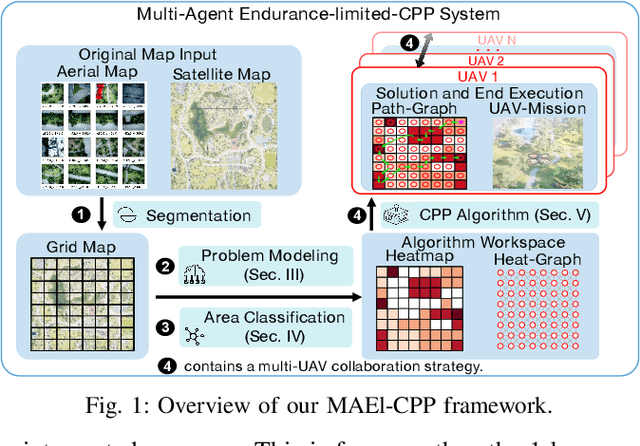
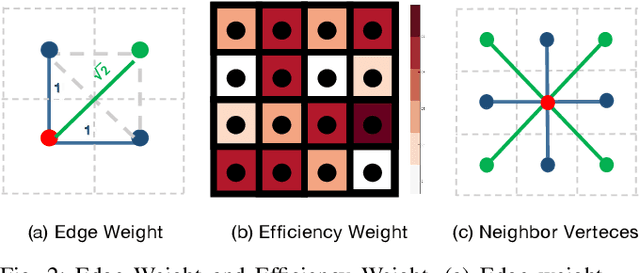
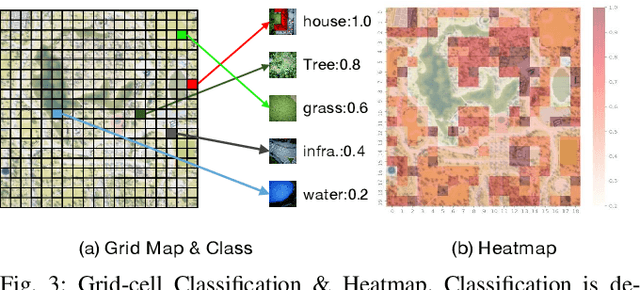

For scenes such as floods and earthquakes, the disaster area is large, and rescue time is tight. Multi-UAV exploration is more efficient than a single UAV. Existing UAV exploration work is modeled as a Coverage Path Planning (CPP) task to achieve full coverage of the area in the presence of obstacles. However, the endurance capability of UAV is limited, and the rescue time is urgent. Thus, even using multiple UAVs cannot achieve complete disaster area coverage in time. Therefore, in this paper we propose a multi-Agent Endurance-limited CPP (MAEl-CPP) problem based on a priori heatmap of the disaster area, which requires the exploration of more valuable areas under limited energy. Furthermore, we propose a path planning algorithm for the MAEl-CPP problem, by ranking the possible disaster areas according to their importance through satellite or remote aerial images and completing path planning according to the importance level. Experimental results show that our proposed algorithm is at least twice as effective as the existing method in terms of search efficiency.
Opencpop: A High-Quality Open Source Chinese Popular Song Corpus for Singing Voice Synthesis
Jan 20, 2022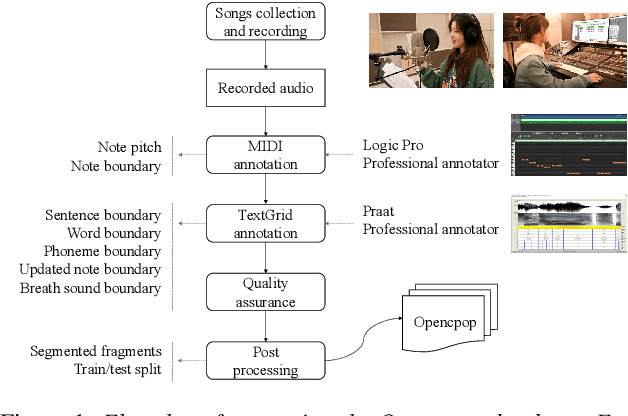
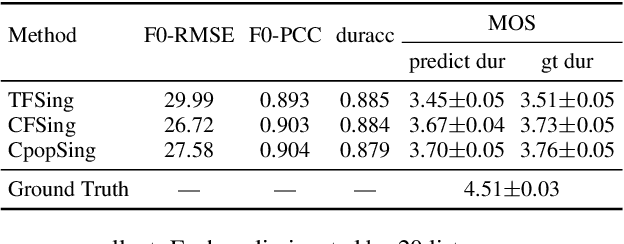


This paper introduces Opencpop, a publicly available high-quality Mandarin singing corpus designed for singing voice synthesis (SVS). The corpus consists of 100 popular Mandarin songs performed by a female professional singer. Audio files are recorded with studio quality at a sampling rate of 44,100 Hz and the corresponding lyrics and musical scores are provided. All singing recordings have been phonetically annotated with phoneme boundaries and syllable (note) boundaries. To demonstrate the reliability of the released data and to provide a baseline for future research, we built baseline deep neural network-based SVS models and evaluated them with both objective metrics and subjective mean opinion score (MOS) measure. Experimental results show that the best SVS model trained on our database achieves 3.70 MOS, indicating the reliability of the provided corpus. Opencpop is released to the open-source community WeNet, and the corpus, as well as synthesized demos, can be found on the project homepage.