 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYu Qiao
ControlLLM: Augment Language Models with Tools by Searching on Graphs
Oct 30, 2023
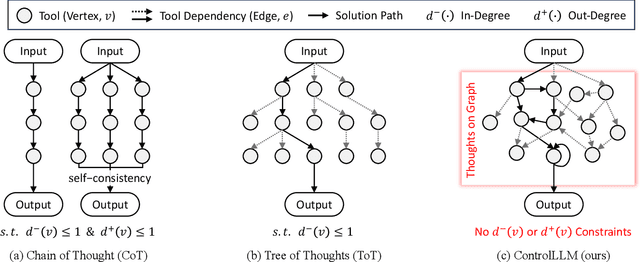

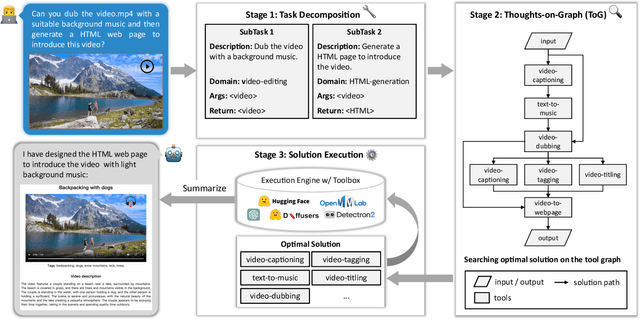

We present ControlLLM, a novel framework that enables large language models (LLMs) to utilize multi-modal tools for solving complex real-world tasks. Despite the remarkable performance of LLMs, they still struggle with tool invocation due to ambiguous user prompts, inaccurate tool selection and parameterization, and inefficient tool scheduling. To overcome these challenges, our framework comprises three key components: (1) a \textit{task decomposer} that breaks down a complex task into clear subtasks with well-defined inputs and outputs; (2) a \textit{Thoughts-on-Graph (ToG) paradigm} that searches the optimal solution path on a pre-built tool graph, which specifies the parameter and dependency relations among different tools; and (3) an \textit{execution engine with a rich toolbox} that interprets the solution path and runs the tools efficiently on different computational devices. We evaluate our framework on diverse tasks involving image, audio, and video processing, demonstrating its superior accuracy, efficiency, and versatility compared to existing methods. The code is at https://github.com/OpenGVLab/ControlLLM .
Harvest Video Foundation Models via Efficient Post-Pretraining
Oct 30, 2023Building video-language foundation models is costly and difficult due to the redundant nature of video data and the lack of high-quality video-language datasets. In this paper, we propose an efficient framework to harvest video foundation models from image ones. Our method is intuitively simple by randomly dropping input video patches and masking out input text during the post-pretraining procedure. The patch dropping boosts the training efficiency significantly and text masking enforces the learning of cross-modal fusion. We conduct extensive experiments to validate the effectiveness of our method on a wide range of video-language downstream tasks including various zero-shot tasks, video question answering, and video-text retrieval. Despite its simplicity, our method achieves state-of-the-art performances, which are comparable to some heavily pretrained video foundation models. Our method is extremely efficient and can be trained in less than one day on 8 GPUs, requiring only WebVid-10M as pretraining data. We hope our method can serve as a simple yet strong counterpart for prevalent video foundation models, provide useful insights when building them, and make large pretrained models more accessible and sustainable. This is part of the InternVideo project \url{https://github.com/OpenGVLab/InternVideo}.
SAM-Med3D
Oct 29, 2023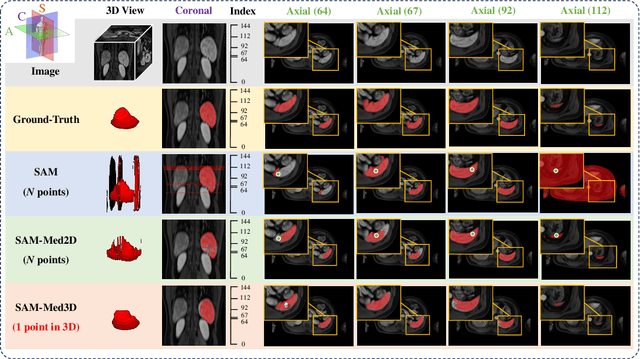
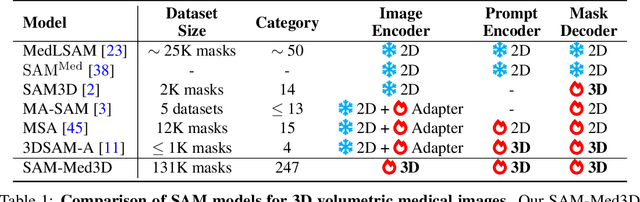
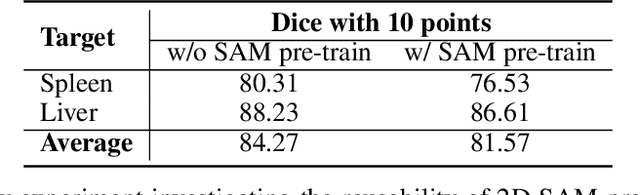
Although the Segment Anything Model (SAM) has demonstrated impressive performance in 2D natural image segmentation, its application to 3D volumetric medical images reveals significant shortcomings, namely suboptimal performance and unstable prediction, necessitating an excessive number of prompt points to attain the desired outcomes. These issues can hardly be addressed by fine-tuning SAM on medical data because the original 2D structure of SAM neglects 3D spatial information. In this paper, we introduce SAM-Med3D, the most comprehensive study to modify SAM for 3D medical images. Our approach is characterized by its comprehensiveness in two primary aspects: firstly, by comprehensively reformulating SAM to a thorough 3D architecture trained on a comprehensively processed large-scale volumetric medical dataset; and secondly, by providing a comprehensive evaluation of its performance. Specifically, we train SAM-Med3D with over 131K 3D masks and 247 categories. Our SAM-Med3D excels at capturing 3D spatial information, exhibiting competitive performance with significantly fewer prompt points than the top-performing fine-tuned SAM in the medical domain. We then evaluate its capabilities across 15 datasets and analyze it from multiple perspectives, including anatomical structures, modalities, targets, and generalization abilities. Our approach, compared with SAM, showcases pronouncedly enhanced efficiency and broad segmentation capabilities for 3D volumetric medical images. Our code is released at https://github.com/uni-medical/SAM-Med3D.
Leveraging Vision-Centric Multi-Modal Expertise for 3D Object Detection
Oct 24, 2023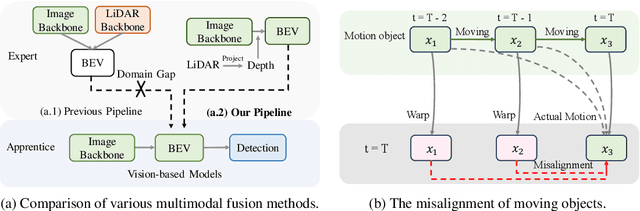
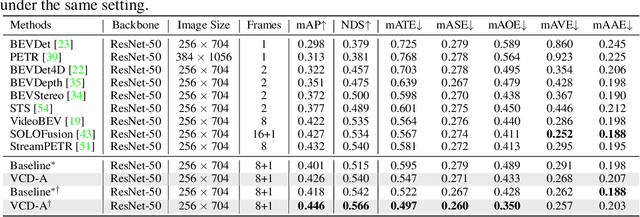
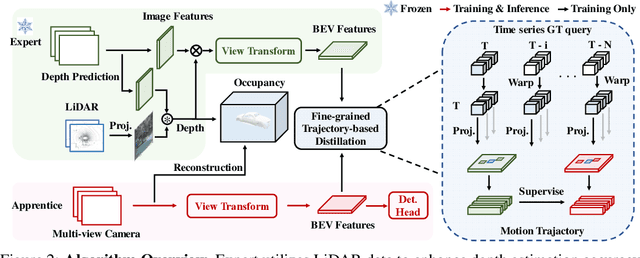
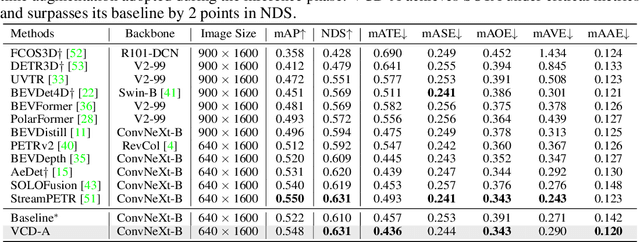
Current research is primarily dedicated to advancing the accuracy of camera-only 3D object detectors (apprentice) through the knowledge transferred from LiDAR- or multi-modal-based counterparts (expert). However, the presence of the domain gap between LiDAR and camera features, coupled with the inherent incompatibility in temporal fusion, significantly hinders the effectiveness of distillation-based enhancements for apprentices. Motivated by the success of uni-modal distillation, an apprentice-friendly expert model would predominantly rely on camera features, while still achieving comparable performance to multi-modal models. To this end, we introduce VCD, a framework to improve the camera-only apprentice model, including an apprentice-friendly multi-modal expert and temporal-fusion-friendly distillation supervision. The multi-modal expert VCD-E adopts an identical structure as that of the camera-only apprentice in order to alleviate the feature disparity, and leverages LiDAR input as a depth prior to reconstruct the 3D scene, achieving the performance on par with other heterogeneous multi-modal experts. Additionally, a fine-grained trajectory-based distillation module is introduced with the purpose of individually rectifying the motion misalignment for each object in the scene. With those improvements, our camera-only apprentice VCD-A sets new state-of-the-art on nuScenes with a score of 63.1% NDS.
A Comparative Study of Image Restoration Networks for General Backbone Network Design
Oct 18, 2023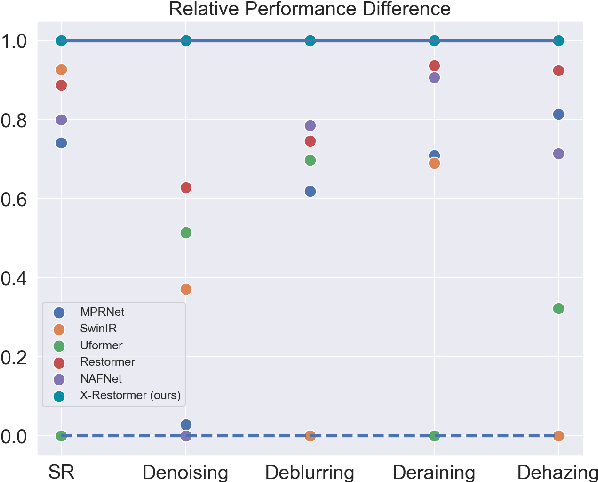
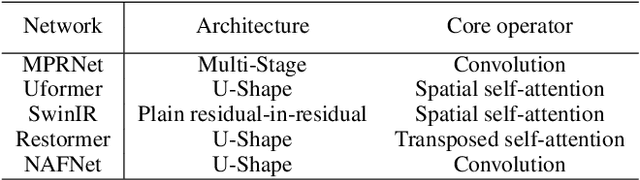


Despite the significant progress made by deep models in various image restoration tasks, existing image restoration networks still face challenges in terms of task generality. An intuitive manifestation is that networks which excel in certain tasks often fail to deliver satisfactory results in others. To illustrate this point, we select five representative image restoration networks and conduct a comparative study on five classic image restoration tasks. First, we provide a detailed explanation of the characteristics of different image restoration tasks and backbone networks. Following this, we present the benchmark results and analyze the reasons behind the performance disparity of different models across various tasks. Drawing from this comparative study, we propose that a general image restoration backbone network needs to meet the functional requirements of diverse tasks. Based on this principle, we design a new general image restoration backbone network, X-Restormer. Extensive experiments demonstrate that X-Restormer possesses good task generality and achieves state-of-the-art performance across a variety of tasks.
Beyond One-Preference-for-All: Multi-Objective Direct Preference Optimization for Language Models
Oct 17, 2023A single language model (LM), despite aligning well with an average labeler through reinforcement learning from human feedback (RLHF), may not universally suit diverse human preferences. Recent approaches thus pursue customization, training separate principle-based reward models to represent different alignment objectives (e.g. helpfulness, harmlessness, or honesty). Different LMs can then be trained for different preferences through multi-objective RLHF (MORLHF) with different objective weightings. Yet, RLHF is unstable and resource-heavy, especially for MORLHF with diverse and usually conflicting objectives. In this paper, we present Multi-Objective Direct Preference Optimization (MODPO), an RL-free algorithm that extends Direct Preference Optimization (DPO) for multiple alignment objectives. Essentially, MODPO folds LM learning directly into reward modeling, aligning LMs with the weighted sum of all principle-based rewards using pure cross-entropy loss. While theoretically guaranteed to produce the same optimal solutions as MORLHF, MODPO is practically more stable and computationally efficient, obviating value function modeling and online sample collection. Empirical results in safety alignment and long-form question answering confirm that MODPO matches or outperforms existing methods, consistently producing one of the most competitive LM fronts that cater to diverse preferences with 3 times fewer computations compared with MORLHF.
Unifying Image Processing as Visual Prompting Question Answering
Oct 16, 2023
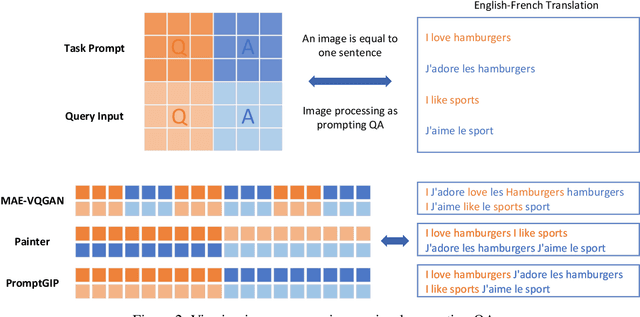

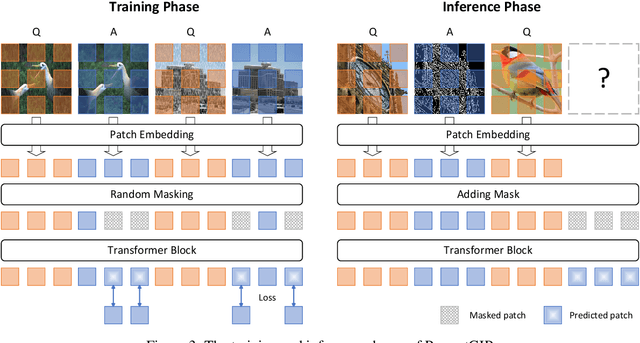
Image processing is a fundamental task in computer vision, which aims at enhancing image quality and extracting essential features for subsequent vision applications. Traditionally, task-specific models are developed for individual tasks and designing such models requires distinct expertise. Building upon the success of large language models (LLMs) in natural language processing (NLP), there is a similar trend in computer vision, which focuses on developing large-scale models through pretraining and in-context learning. This paradigm shift reduces the reliance on task-specific models, yielding a powerful unified model to deal with various tasks. However, these advances have predominantly concentrated on high-level vision tasks, with less attention paid to low-level vision tasks. To address this issue, we propose a universal model for general image processing that covers image restoration, image enhancement, image feature extraction tasks, \textit{etc}. Our proposed framework, named PromptGIP, unifies these diverse image processing tasks within a universal framework. Inspired by NLP question answering (QA) techniques, we employ a visual prompting question answering paradigm. Specifically, we treat the input-output image pair as a structured question-answer sentence, thereby reprogramming the image processing task as a prompting QA problem. PromptGIP can undertake diverse \textbf{cross-domain} tasks using provided visual prompts, eliminating the need for task-specific finetuning. Our methodology offers a universal and adaptive solution to general image processing. While PromptGIP has demonstrated a certain degree of out-of-domain task generalization capability, further research is expected to fully explore its more powerful emergent generalization.
PonderV2: Pave the Way for 3D Foundation Model with A Universal Pre-training Paradigm
Oct 13, 2023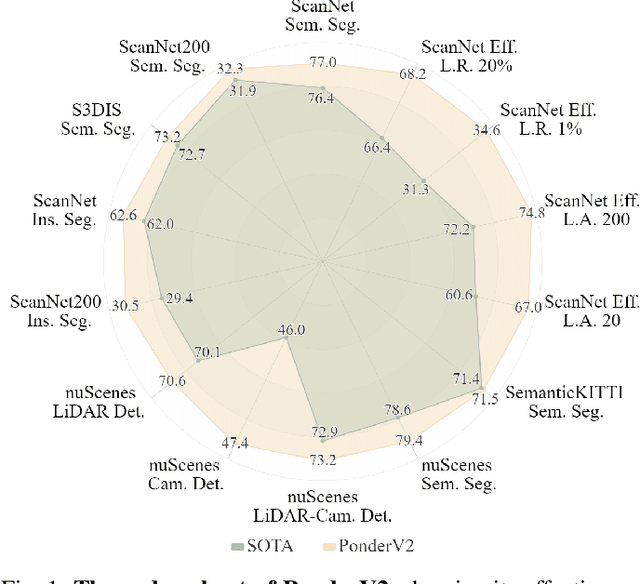
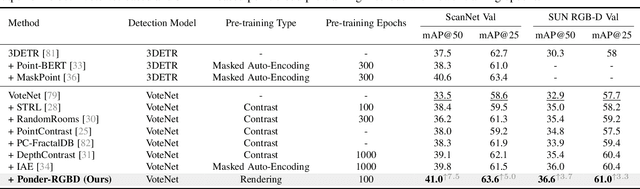
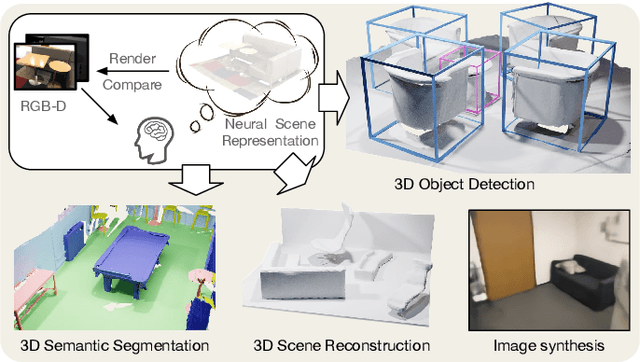

In contrast to numerous NLP and 2D computer vision foundational models, the learning of a robust and highly generalized 3D foundational model poses considerably greater challenges. This is primarily due to the inherent data variability and the diversity of downstream tasks. In this paper, we introduce a comprehensive 3D pre-training framework designed to facilitate the acquisition of efficient 3D representations, thereby establishing a pathway to 3D foundational models. Motivated by the fact that informative 3D features should be able to encode rich geometry and appearance cues that can be utilized to render realistic images, we propose a novel universal paradigm to learn point cloud representations by differentiable neural rendering, serving as a bridge between 3D and 2D worlds. We train a point cloud encoder within a devised volumetric neural renderer by comparing the rendered images with the real images. Notably, our approach demonstrates the seamless integration of the learned 3D encoder into diverse downstream tasks. These tasks encompass not only high-level challenges such as 3D detection and segmentation but also low-level objectives like 3D reconstruction and image synthesis, spanning both indoor and outdoor scenarios. Besides, we also illustrate the capability of pre-training a 2D backbone using the proposed universal methodology, surpassing conventional pre-training methods by a large margin. For the first time, PonderV2 achieves state-of-the-art performance on 11 indoor and outdoor benchmarks. The consistent improvements in various settings imply the effectiveness of the proposed method. Code and models will be made available at https://github.com/OpenGVLab/PonderV2.
Tree-Planner: Efficient Close-loop Task Planning with Large Language Models
Oct 12, 2023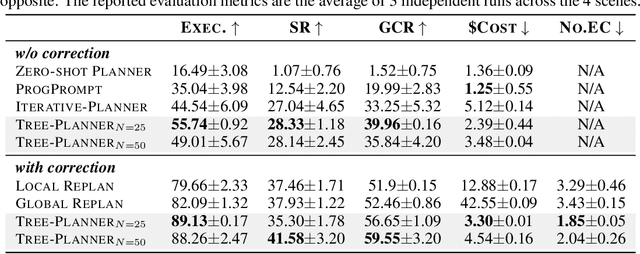
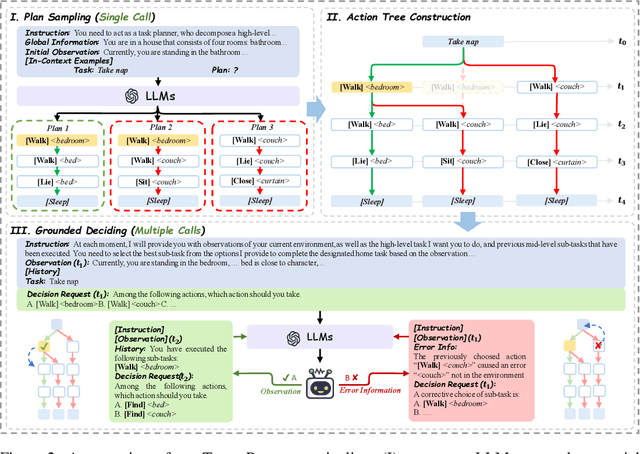
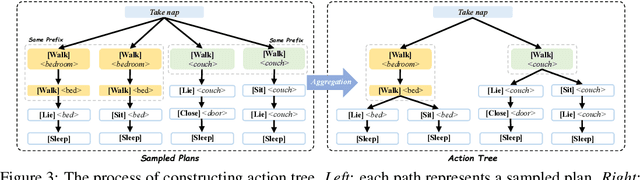

This paper studies close-loop task planning, which refers to the process of generating a sequence of skills (a plan) to accomplish a specific goal while adapting the plan based on real-time observations. Recently, prompting Large Language Models (LLMs) to generate actions iteratively has become a prevalent paradigm due to its superior performance and user-friendliness. However, this paradigm is plagued by two inefficiencies: high token consumption and redundant error correction, both of which hinder its scalability for large-scale testing and applications. To address these issues, we propose Tree-Planner, which reframes task planning with LLMs into three distinct phases: plan sampling, action tree construction, and grounded deciding. Tree-Planner starts by using an LLM to sample a set of potential plans before execution, followed by the aggregation of them to form an action tree. Finally, the LLM performs a top-down decision-making process on the tree, taking into account real-time environmental information. Experiments show that Tree-Planner achieves state-of-the-art performance while maintaining high efficiency. By decomposing LLM queries into a single plan-sampling call and multiple grounded-deciding calls, a considerable part of the prompt are less likely to be repeatedly consumed. As a result, token consumption is reduced by 92.2% compared to the previously best-performing model. Additionally, by enabling backtracking on the action tree as needed, the correction process becomes more flexible, leading to a 40.5% decrease in error corrections. Project page: https://tree-planner.github.io/