 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning for Koopman Spectral Analysis with Short Time-series
Feb 09, 2021
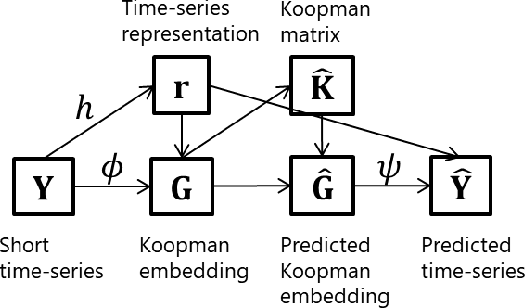
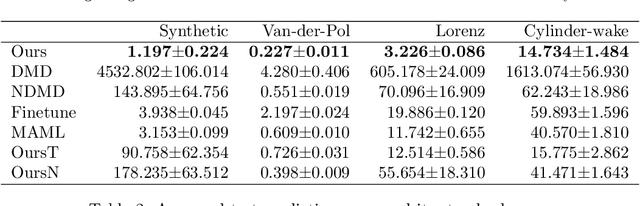
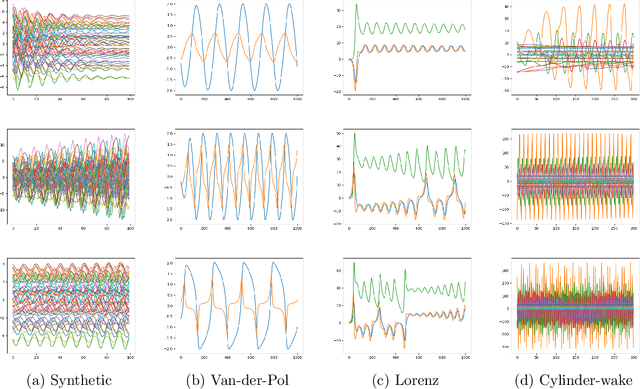
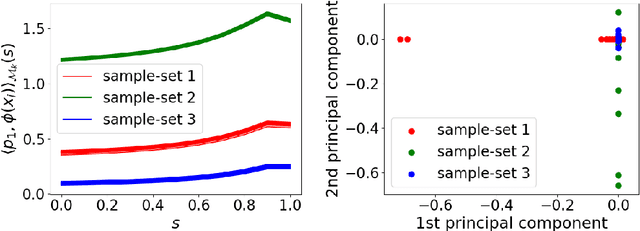
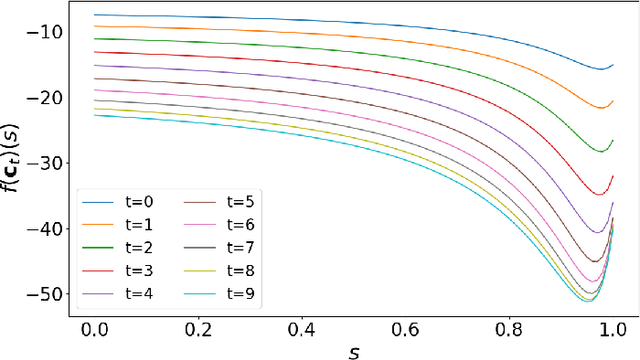
Koopman spectral analysis has attracted attention for nonlinear dynamical systems since we can analyze nonlinear dynamics with a linear regime by embedding data into a Koopman space by a nonlinear function. For the analysis, we need to find appropriate embedding functions. Although several neural network-based methods have been proposed for learning embedding functions, existing methods require long time-series for training neural networks. This limitation prohibits performing Koopman spectral analysis in applications where only short time-series are available. In this paper, we propose a meta-learning method for estimating embedding functions from unseen short time-series by exploiting knowledge learned from related but different time-series. With the proposed method, a representation of a given short time-series is obtained by a bidirectional LSTM for extracting its properties. The embedding function of the short time-series is modeled by a neural network that depends on the time-series representation. By sharing the LSTM and neural networks across multiple time-series, we can learn common knowledge from different time-series while modeling time-series-specific embedding functions with the time-series representation. Our model is trained such that the expected test prediction error is minimized with the episodic training framework. We experimentally demonstrate that the proposed method achieves better performance in terms of eigenvalue estimation and future prediction than existing methods.
Reproducing kernel Hilbert C*-module and kernel mean embeddings
Jan 27, 2021
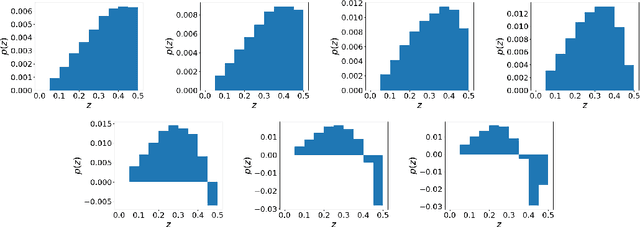
Kernel methods have been among the most popular techniques in machine learning, where learning tasks are solved using the property of reproducing kernel Hilbert space (RKHS). In this paper, we propose a novel data analysis framework with reproducing kernel Hilbert $C^*$-module (RKHM) and kernel mean embedding (KME) in RKHM. Since RKHM contains richer information than RKHS or vector-valued RKHS (vv RKHS), analysis with RKHM enables us to capture and extract structural properties in multivariate data, functional data and other structured data. We show a branch of theories for RKHM to apply to data analysis, including the representer theorem, and the injectivity and universality of the proposed KME. We also show RKHM generalizes RKHS and vv RKHS. Then, we provide concrete procedures for employing RKHM and the proposed KME to data analysis.
Neural Dynamic Mode Decomposition for End-to-End Modeling of Nonlinear Dynamics
Dec 11, 2020

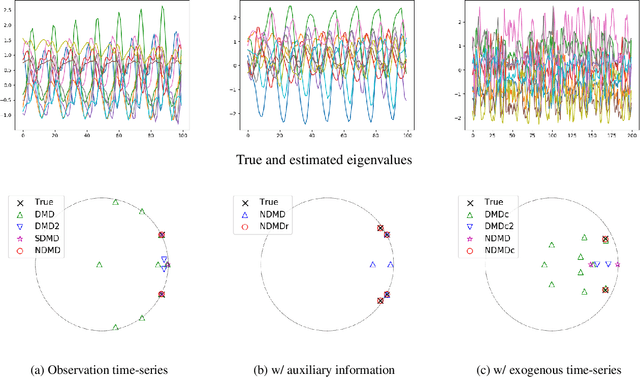
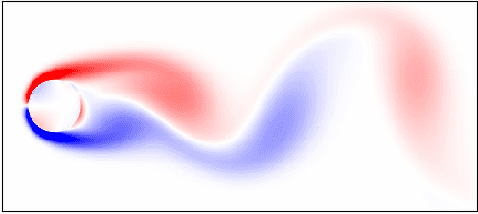
Koopman spectral analysis has attracted attention for understanding nonlinear dynamical systems by which we can analyze nonlinear dynamics with a linear regime by lifting observations using a nonlinear function. For analysis, we need to find an appropriate lift function. Although several methods have been proposed for estimating a lift function based on neural networks, the existing methods train neural networks without spectral analysis. In this paper, we propose neural dynamic mode decomposition, in which neural networks are trained such that the forecast error is minimized when the dynamics is modeled based on spectral decomposition in the lifted space. With our proposed method, the forecast error is backpropagated through the neural networks and the spectral decomposition, enabling end-to-end learning of Koopman spectral analysis. When information is available on the frequencies or the growth rates of the dynamics, the proposed method can exploit it as regularizers for training. We also propose an extension of our approach when observations are influenced by exogenous control time-series. Our experiments demonstrate the effectiveness of our proposed method in terms of eigenvalue estimation and forecast performance.
Kernel Mean Embeddings of Von Neumann-Algebra-Valued Measures
Jul 29, 2020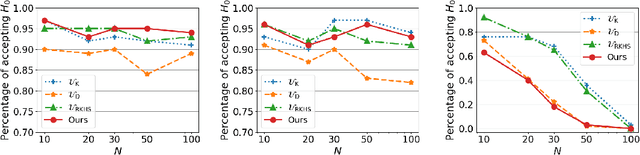

Kernel mean embedding (KME) is a powerful tool to analyze probability measures for data, where the measures are conventionally embedded into a reproducing kernel Hilbert space (RKHS). In this paper, we generalize KME to that of von Neumann-algebra-valued measures into reproducing kernel Hilbert modules (RKHMs), which provides an inner product and distance between von Neumann-algebra-valued measures. Von Neumann-algebra-valued measures can, for example, encode relations between arbitrary pairs of variables in a multivariate distribution or positive operator-valued measures for quantum mechanics. Thus, this allows us to perform probabilistic analyses explicitly reflected with higher-order interactions among variables, and provides a way of applying machine learning frameworks to problems in quantum mechanics. We also show that the injectivity of the existing KME and the universality of RKHS are generalized to RKHM, which confirms many useful features of the existing KME remain in our generalized KME. And, we investigate the empirical performance of our methods using synthetic and real-world data.
Policy learning with partial observation and mechanical constraints for multi-person modeling
Jul 07, 2020
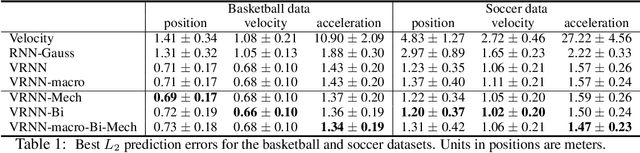
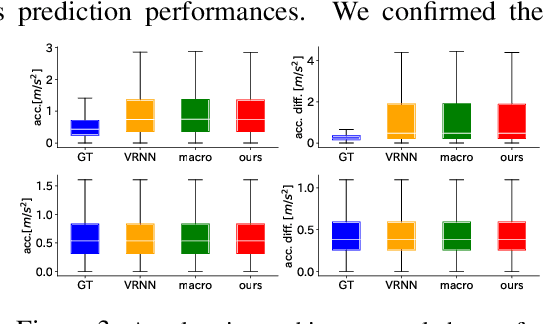
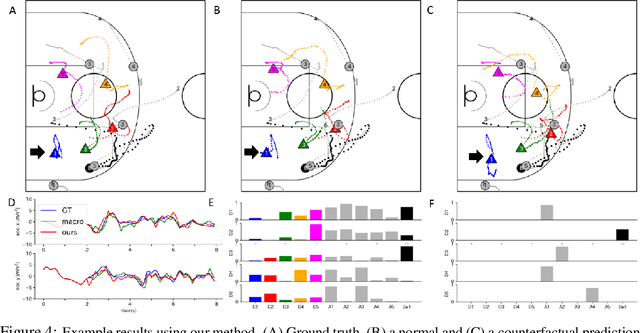
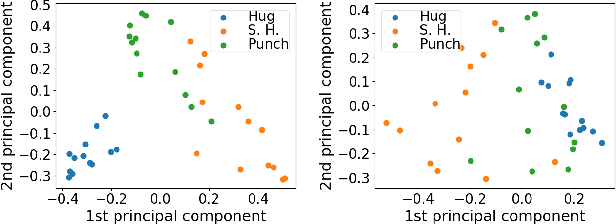
Extracting the rules of real-world biological multi-agent behaviors is a current challenge in various scientific and engineering fields. Biological agents generally have limited observation and mechanical constraints; however, most of the conventional data-driven models ignore such assumptions, resulting in lack of biological plausibility and model interpretability for behavioral analyses in biological and cognitive science. Here we propose sequential generative models with partial observation and mechanical constraints, which can visualize whose information the agents utilize and can generate biologically plausible actions. We formulate this as a decentralized multi-agent imitation learning problem, leveraging binary partial observation models with a Gumbel-Softmax reparameterization and policy models based on hierarchical variational recurrent neural networks with physical and biomechanical constraints. We investigate the empirical performances using real-world multi-person motion datasets from basketball and soccer games.
Learning Dynamics Models with Stable Invariant Sets
Jun 16, 2020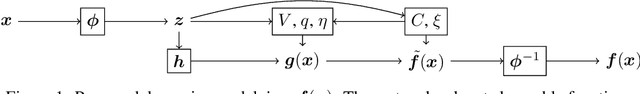
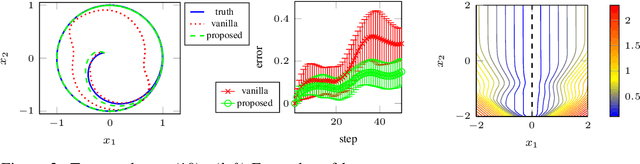
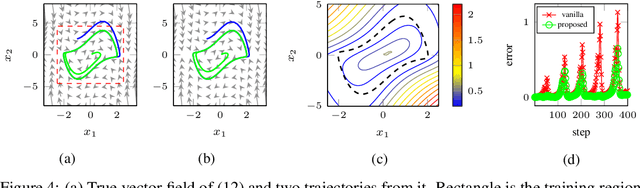
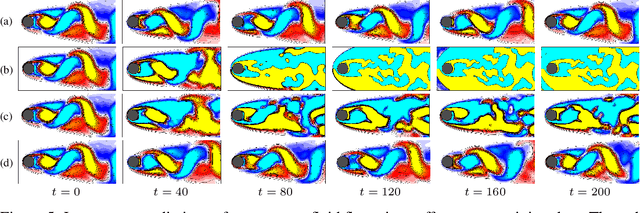
Stable invariant sets are an essential notion in the analysis and application of dynamical systems. It is thus of great interest to learn dynamical systems with provable existence of stable invariant sets. However, existing methods can only deal with the stability of discrete equilibria, which hinders many applications. In this paper, we propose a method to ensure that a learned dynamics model has a stable invariant set of general classes. To this end, we modify a base dynamics model using a learnable Lyapunov-like function so that the modified dynamics attain the invariance and the stability of a specific subset. We model such a subset by transforming primitive shapes (e.g., spheres) via a learnable bijective function. We may specify such a primitive shape following prior knowledge of the dynamics if any, or it can also be learned from data. We introduce an example of the implementation of the proposed dynamics models using neural networks and present experimental results that show the validity of the proposed method.
On Anomaly Interpretation via Shapley Values
Apr 09, 2020
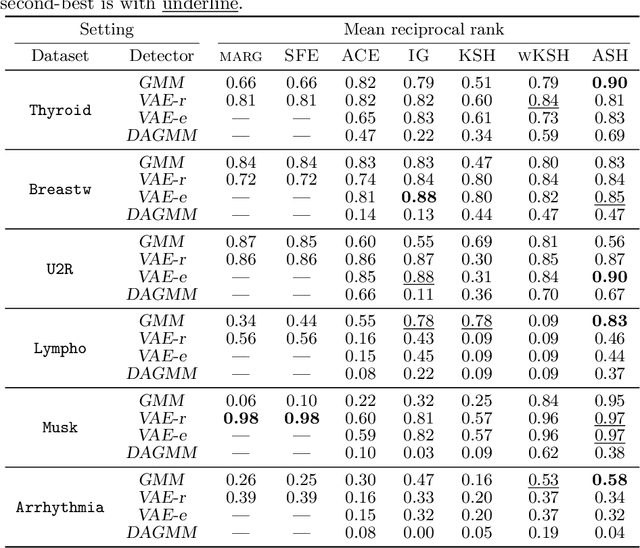
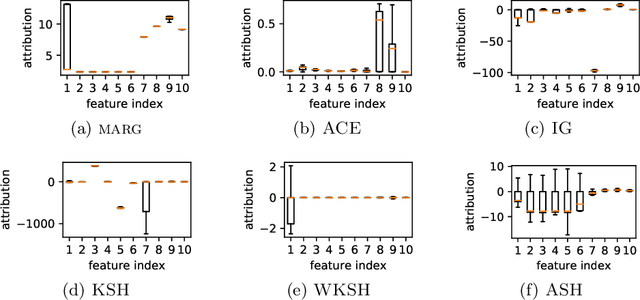
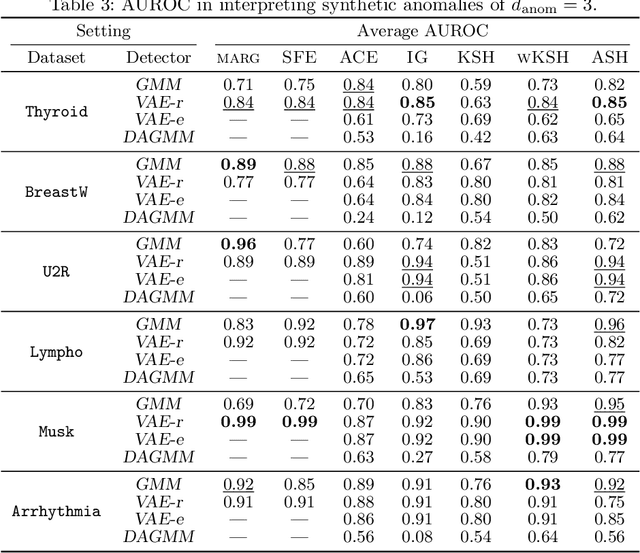
Anomaly localization is an essential problem as anomaly detection is. Because a rigorous localization requires a causal model of a target system, practically we often resort to a relaxed problem of anomaly interpretation, for which we are to obtain meaningful attribution of anomaly scores to input features. In this paper, we investigate the use of the Shapley value for anomaly interpretation. We focus on the semi-supervised anomaly detection and newly propose a characteristic function, on which the Shapley value is computed, specifically for anomaly scores. The idea of the proposed method is approximating the absence of some features by minimizing an anomaly score with regard to them. We examine the performance of the proposed method as well as other general approaches to computing the Shapley value in interpreting anomaly scores. We show the results of experiments on multiple datasets and anomaly detection methods, which indicate the usefulness of the Shapley-based anomaly interpretation toward anomaly localization.
Analysis via Orthonormal Systems in Reproducing Kernel Hilbert $C^*$-Modules and Applications
Mar 02, 2020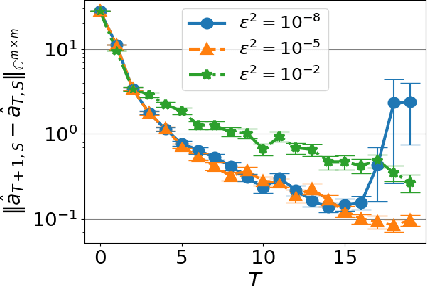

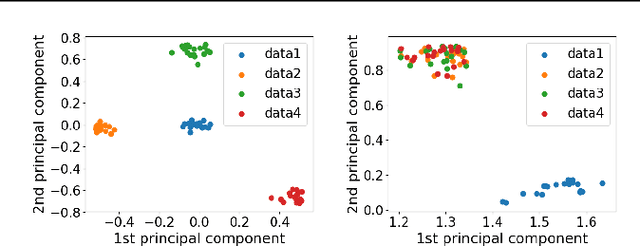
Kernel methods have been among the most popular techniques in machine learning, where learning tasks are solved using the property of reproducing kernel Hilbert space (RKHS). In this paper, we propose a novel data analysis framework with reproducing kernel Hilbert $C^*$-module (RKHM), which is another generalization of RKHS than vector-valued RKHS (vv-RKHS). Analysis with RKHMs enables us to deal with structures among variables more explicitly than vv-RKHS. We show the theoretical validity for the construction of orthonormal systems in Hilbert $C^*$-modules, and derive concrete procedures for orthonormalization in RKHMs with those theoretical properties in numerical computations. Moreover, we apply those to generalize with RKHM kernel principal component analysis and the analysis of dynamical systems with Perron-Frobenius operators. The empirical performance of our methods is also investigated by using synthetic and real-world data.
Krylov Subspace Method for Nonlinear Dynamical Systems with Random Noise
Sep 10, 2019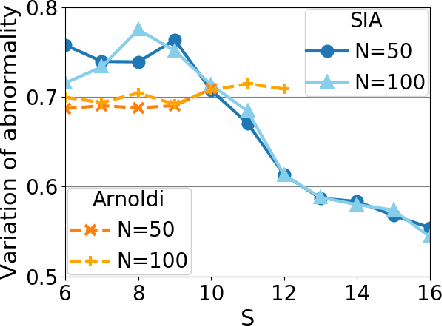
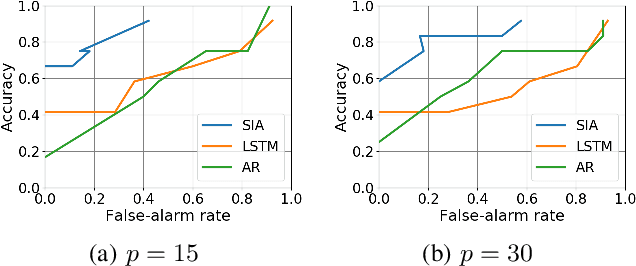
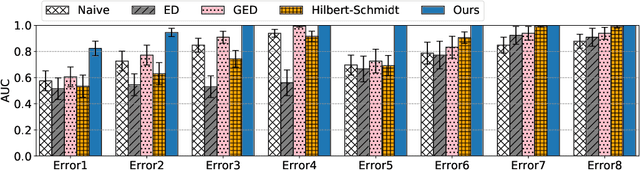
Operator-theoretic analysis of nonlinear dynamical systems has attracted much attention in a variety of engineering and scientific fields, endowed with practical estimation methods using data such as dynamic mode decomposition. In this paper, we address a lifted representation of nonlinear dynamical systems with random noise based on transfer operators, and develop a novel Krylov subspace method for estimating it using finite data, with consideration of the unboundedness of operators. For this purpose, we first consider Perron-Frobenius operators with kernel-mean embeddings for such systems. Then, we extend the Arnoldi method, which is the most classical type of Kryov subspace methods, so that it can be applied to the current case. Meanwhile, the Arnoldi method requires the assumption that the operator is bounded, which is not necessarily satisfied for transfer operators on nonlinear systems. We accordingly develop the shift-invert Arnoldi method for the Perron-Frobenius operators to avoid this problem. Also, we describe a way of evaluating the predictive accuracy by estimated operators on the basis of the maximum mean discrepancy, which is applicable, for example, to anomaly detection in complex systems. The empirical performance of our methods is investigated using synthetic and real-world healthcare data.
Metric on random dynamical systems with vector-valued reproducing kernel Hilbert spaces
Jun 19, 2019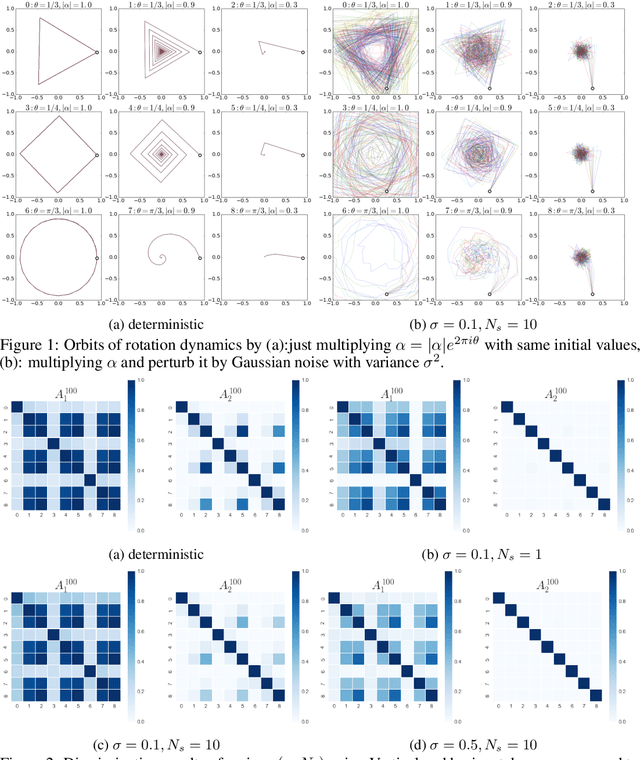
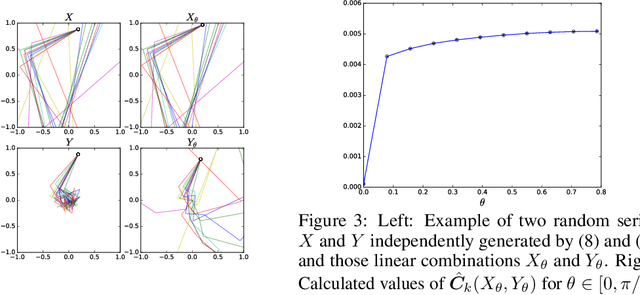
The development of a metric on structural data-generating mechanisms is fundamental in machine learning and the related fields. In this paper, we consider a general framework to construct metrics on {\em random} nonlinear dynamical systems, which are defined with the Perron-Frobenius operators in vector-valued reproducing kernel Hilbert spaces (vvRKHSs). Here, vvRKHSs are employed to design mathematically manageable metrics and also to introduce $L^2(\Omega)$-valued kernels, which are necessary to handle the randomness in systems. Our metric is a natural extension of existing metrics for {\em deterministic} systems, and can give a specification of the kernel maximal mean discrepancy of random processes. Moreover, by considering the time-wise independence of random processes, we discuss the connection between our metric and the independence criteria with kernels such as Hilbert-Schmidt independence criteria. We empirically illustrate our metric with synthetic data, and evaluate it in the context of the independence test for random processes.