Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Word N-Grams
Jul 13, 1996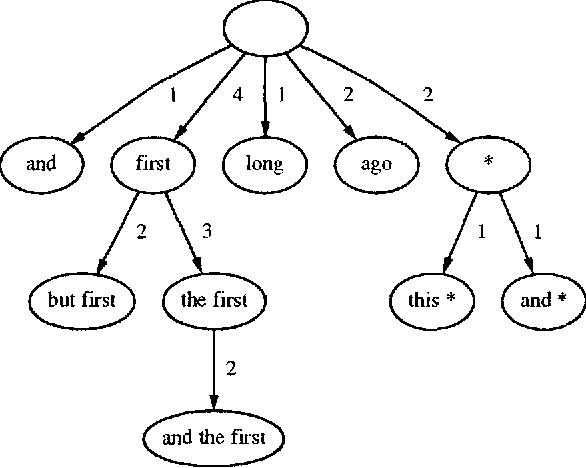
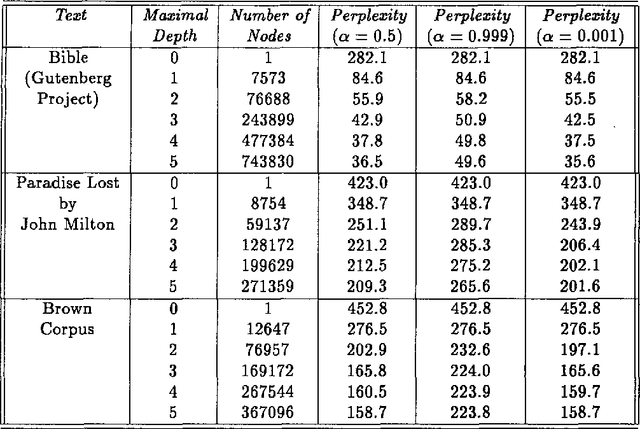
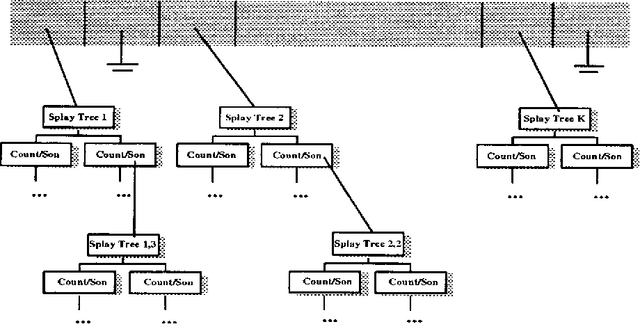
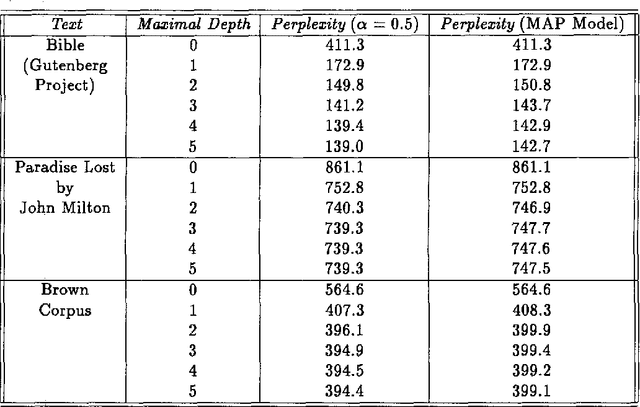
We describe, analyze, and evaluate experimentally a new probabilistic model for word-sequence prediction in natural language based on prediction suffix trees (PSTs). By using efficient data structures, we extend the notion of PST to unbounded vocabularies. We also show how to use a Bayesian approach based on recursive priors over all possible PSTs to efficiently maintain tree mixtures. These mixtures have provably and practically better performance than almost any single model. We evaluate the model on several corpora. The low perplexity achieved by relatively small PST mixture models suggests that they may be an advantageous alternative, both theoretically and practically, to the widely used n-gram models.
* 15 pages, one PostScript figure, uses psfig.sty and fullname.sty.
Revised version of a paper in the Proceedings of the Third Workshop on Very
Large Corpora, MIT, 1995
Via