 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural LiDAR Fields for Novel View Synthesis
May 02, 2023



We present Neural Fields for LiDAR (NFL), a method to optimise a neural field scene representation from LiDAR measurements, with the goal of synthesizing realistic LiDAR scans from novel viewpoints. NFL combines the rendering power of neural fields with a detailed, physically motivated model of the LiDAR sensing process, thus enabling it to accurately reproduce key sensor behaviors like beam divergence, secondary returns, and ray dropping. We evaluate NFL on synthetic and real LiDAR scans and show that it outperforms explicit reconstruct-then-simulate methods as well as other NeRF-style methods on LiDAR novel view synthesis task. Moreover, we show that the improved realism of the synthesized views narrows the domain gap to real scans and translates to better registration and semantic segmentation performance.
CALM: Conditional Adversarial Latent Models for Directable Virtual Characters
May 02, 2023



In this work, we present Conditional Adversarial Latent Models (CALM), an approach for generating diverse and directable behaviors for user-controlled interactive virtual characters. Using imitation learning, CALM learns a representation of movement that captures the complexity and diversity of human motion, and enables direct control over character movements. The approach jointly learns a control policy and a motion encoder that reconstructs key characteristics of a given motion without merely replicating it. The results show that CALM learns a semantic motion representation, enabling control over the generated motions and style-conditioning for higher-level task training. Once trained, the character can be controlled using intuitive interfaces, akin to those found in video games.
Neural Congealing: Aligning Images to a Joint Semantic Atlas
Feb 08, 2023



We present Neural Congealing -- a zero-shot self-supervised framework for detecting and jointly aligning semantically-common content across a given set of images. Our approach harnesses the power of pre-trained DINO-ViT features to learn: (i) a joint semantic atlas -- a 2D grid that captures the mode of DINO-ViT features in the input set, and (ii) dense mappings from the unified atlas to each of the input images. We derive a new robust self-supervised framework that optimizes the atlas representation and mappings per image set, requiring only a few real-world images as input without any additional input information (e.g., segmentation masks). Notably, we design our losses and training paradigm to account only for the shared content under severe variations in appearance, pose, background clutter or other distracting objects. We demonstrate results on a plethora of challenging image sets including sets of mixed domains (e.g., aligning images depicting sculpture and artwork of cats), sets depicting related yet different object categories (e.g., dogs and tigers), or domains for which large-scale training data is scarce (e.g., coffee mugs). We thoroughly evaluate our method and show that our test-time optimization approach performs favorably compared to a state-of-the-art method that requires extensive training on large-scale datasets.
SceneScape: Text-Driven Consistent Scene Generation
Feb 02, 2023



We propose a method for text-driven perpetual view generation -- synthesizing long videos of arbitrary scenes solely from an input text describing the scene and camera poses. We introduce a novel framework that generates such videos in an online fashion by combining the generative power of a pre-trained text-to-image model with the geometric priors learned by a pre-trained monocular depth prediction model. To achieve 3D consistency, i.e., generating videos that depict geometrically-plausible scenes, we deploy an online test-time training to encourage the predicted depth map of the current frame to be geometrically consistent with the synthesized scene; the depth maps are used to construct a unified mesh representation of the scene, which is updated throughout the generation and is used for rendering. In contrast to previous works, which are applicable only for limited domains (e.g., landscapes), our framework generates diverse scenes, such as walkthroughs in spaceships, caves, or ice castles. Project page: https://scenescape.github.io/
Text2LIVE: Text-Driven Layered Image and Video Editing
Apr 05, 2022


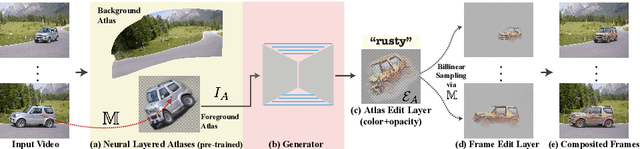
We present a method for zero-shot, text-driven appearance manipulation in natural images and videos. Given an input image or video and a target text prompt, our goal is to edit the appearance of existing objects (e.g., object's texture) or augment the scene with visual effects (e.g., smoke, fire) in a semantically meaningful manner. We train a generator using an internal dataset of training examples, extracted from a single input (image or video and target text prompt), while leveraging an external pre-trained CLIP model to establish our losses. Rather than directly generating the edited output, our key idea is to generate an edit layer (color+opacity) that is composited over the original input. This allows us to constrain the generation process and maintain high fidelity to the original input via novel text-driven losses that are applied directly to the edit layer. Our method neither relies on a pre-trained generator nor requires user-provided edit masks. We demonstrate localized, semantic edits on high-resolution natural images and videos across a variety of objects and scenes.
Layered Neural Atlases for Consistent Video Editing
Sep 23, 2021
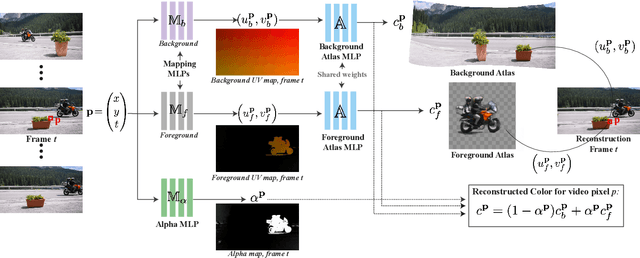
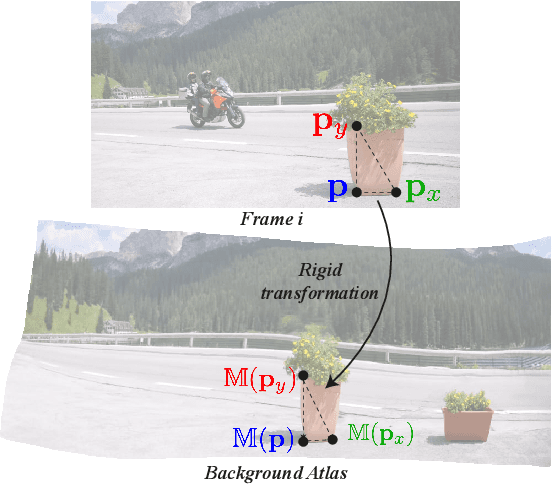
We present a method that decomposes, or "unwraps", an input video into a set of layered 2D atlases, each providing a unified representation of the appearance of an object (or background) over the video. For each pixel in the video, our method estimates its corresponding 2D coordinate in each of the atlases, giving us a consistent parameterization of the video, along with an associated alpha (opacity) value. Importantly, we design our atlases to be interpretable and semantic, which facilitates easy and intuitive editing in the atlas domain, with minimal manual work required. Edits applied to a single 2D atlas (or input video frame) are automatically and consistently mapped back to the original video frames, while preserving occlusions, deformation, and other complex scene effects such as shadows and reflections. Our method employs a coordinate-based Multilayer Perceptron (MLP) representation for mappings, atlases, and alphas, which are jointly optimized on a per-video basis, using a combination of video reconstruction and regularization losses. By operating purely in 2D, our method does not require any prior 3D knowledge about scene geometry or camera poses, and can handle complex dynamic real world videos. We demonstrate various video editing applications, including texture mapping, video style transfer, image-to-video texture transfer, and segmentation/labeling propagation, all automatically produced by editing a single 2D atlas image.
Volume Rendering of Neural Implicit Surfaces
Jun 22, 2021
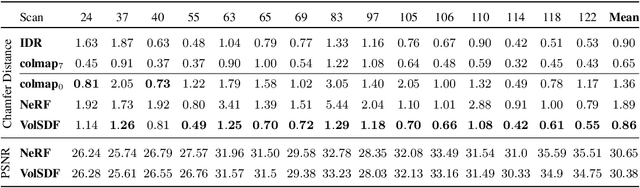
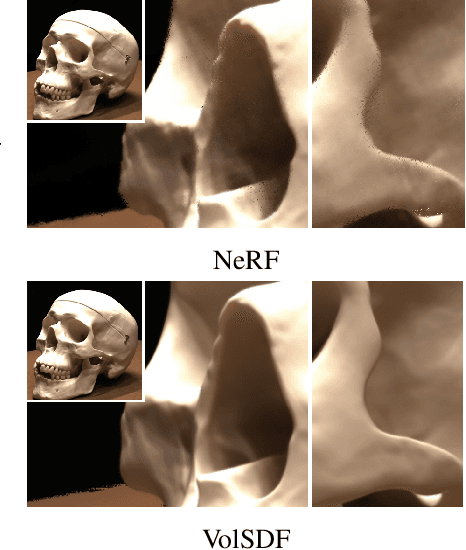

Neural volume rendering became increasingly popular recently due to its success in synthesizing novel views of a scene from a sparse set of input images. So far, the geometry learned by neural volume rendering techniques was modeled using a generic density function. Furthermore, the geometry itself was extracted using an arbitrary level set of the density function leading to a noisy, often low fidelity reconstruction. The goal of this paper is to improve geometry representation and reconstruction in neural volume rendering. We achieve that by modeling the volume density as a function of the geometry. This is in contrast to previous work modeling the geometry as a function of the volume density. In more detail, we define the volume density function as Laplace's cumulative distribution function (CDF) applied to a signed distance function (SDF) representation. This simple density representation has three benefits: (i) it provides a useful inductive bias to the geometry learned in the neural volume rendering process; (ii) it facilitates a bound on the opacity approximation error, leading to an accurate sampling of the viewing ray. Accurate sampling is important to provide a precise coupling of geometry and radiance; and (iii) it allows efficient unsupervised disentanglement of shape and appearance in volume rendering. Applying this new density representation to challenging scene multiview datasets produced high quality geometry reconstructions, outperforming relevant baselines. Furthermore, switching shape and appearance between scenes is possible due to the disentanglement of the two.
Deep Permutation Equivariant Structure from Motion
Apr 14, 2021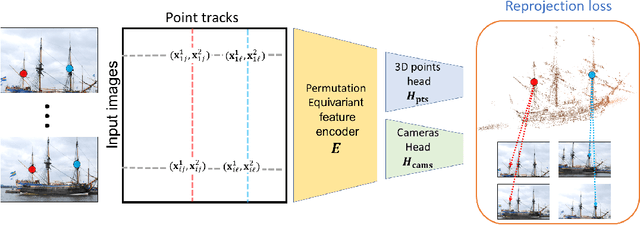
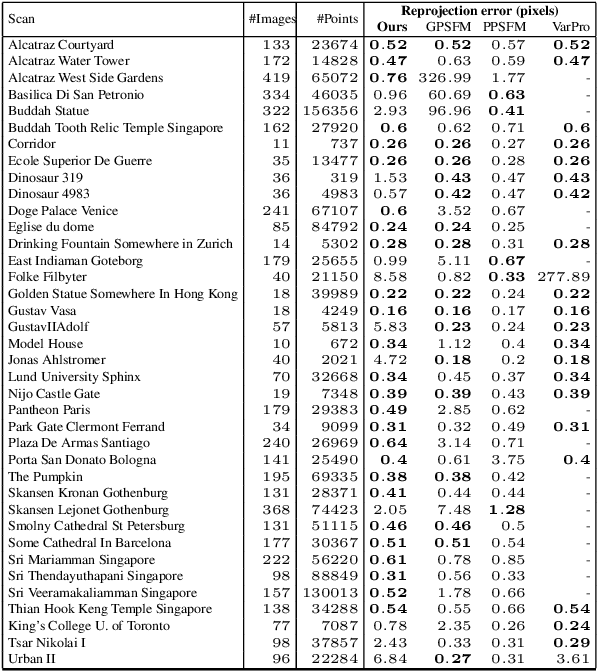
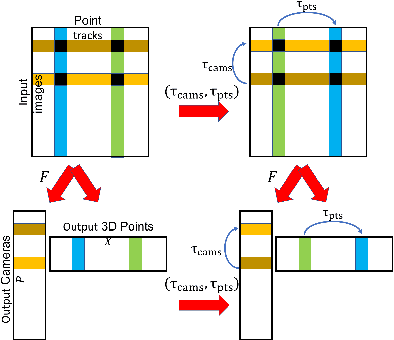
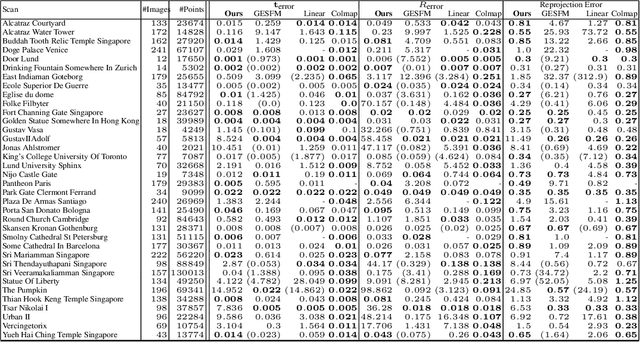
Existing deep methods produce highly accurate 3D reconstructions in stereo and multiview stereo settings, i.e., when cameras are both internally and externally calibrated. Nevertheless, the challenge of simultaneous recovery of camera poses and 3D scene structure in multiview settings with deep networks is still outstanding. Inspired by projective factorization for Structure from Motion (SFM) and by deep matrix completion techniques, we propose a neural network architecture that, given a set of point tracks in multiple images of a static scene, recovers both the camera parameters and a (sparse) scene structure by minimizing an unsupervised reprojection loss. Our network architecture is designed to respect the structure of the problem: the sought output is equivariant to permutations of both cameras and scene points. Notably, our method does not require initialization of camera parameters or 3D point locations. We test our architecture in two setups: (1) single scene reconstruction and (2) learning from multiple scenes. Our experiments, conducted on a variety of datasets in both internally calibrated and uncalibrated settings, indicate that our method accurately recovers pose and structure, on par with classical state of the art methods. Additionally, we show that a pre-trained network can be used to reconstruct novel scenes using inexpensive fine-tuning with no loss of accuracy.
On the Similarity between the Laplace and Neural Tangent Kernels
Jul 03, 2020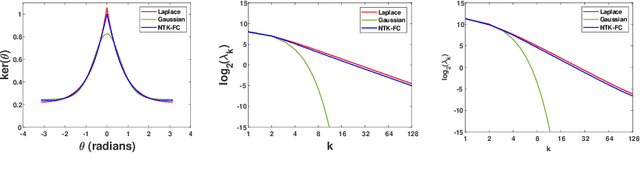
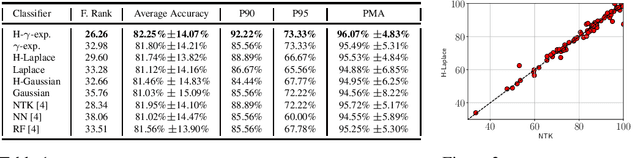
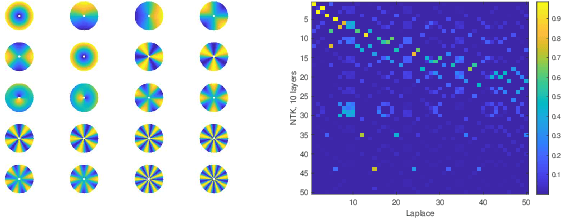
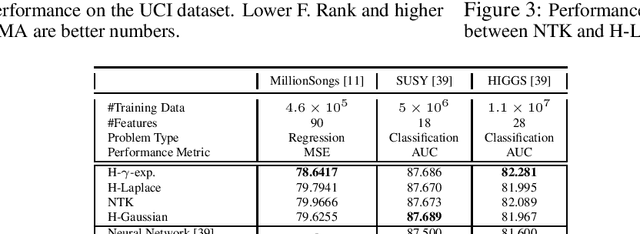
Recent theoretical work has shown that massively overparameterized neural networks are equivalent to kernel regressors that use Neural Tangent Kernels(NTK). Experiments show that these kernel methods perform similarly to real neural networks. Here we show that NTK for fully connected networks is closely related to the standard Laplace kernel. We show theoretically that for normalized data on the hypersphere both kernels have the same eigenfunctions and their eigenvalues decay polynomially at the same rate, implying that their Reproducing Kernel Hilbert Spaces (RKHS) include the same sets of functions. This means that both kernels give rise to classes of functions with the same smoothness properties. The two kernels differ for data off the hypersphere, but experiments indicate that when data is properly normalized these differences are not significant. Finally, we provide experiments on real data comparing NTK and the Laplace kernel, along with a larger class of{\gamma}-exponential kernels. We show that these perform almost identically. Our results suggest that much insight about neural networks can be obtained from analysis of the well-known Laplace kernel, which has a simple closed-form.
End-To-End Convolutional Neural Network for 3D Reconstruction of Knee Bones From Bi-Planar X-Ray Images
Apr 02, 2020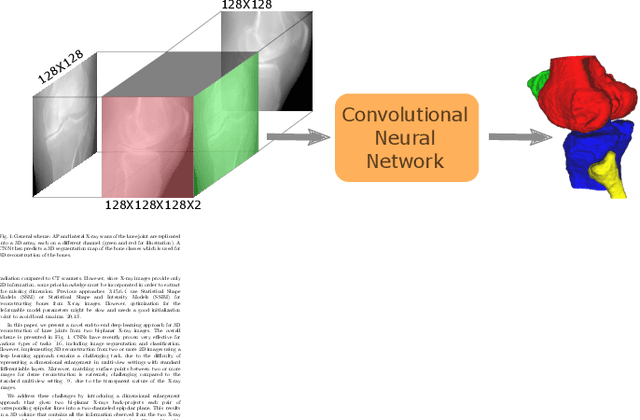


We present an end-to-end Convolutional Neural Network (CNN) approach for 3D reconstruction of knee bones directly from two bi-planar X-ray images. Clinically, capturing the 3D models of the bones is crucial for surgical planning, implant fitting, and postoperative evaluation. X-ray imaging significantly reduces the exposure of patients to ionizing radiation compared to Computer Tomography (CT) imaging, and is much more common and inexpensive compared to Magnetic Resonance Imaging (MRI) scanners. However, retrieving 3D models from such 2D scans is extremely challenging. In contrast to the common approach of statistically modeling the shape of each bone, our deep network learns the distribution of the bones' shapes directly from the training images. We train our model with both supervised and unsupervised losses using Digitally Reconstructed Radiograph (DRR) images generated from CT scans. To apply our model to X-Ray data, we use style transfer to transform between X-Ray and DRR modalities. As a result, at test time, without further optimization, our solution directly outputs a 3D reconstruction from a pair of bi-planar X-ray images, while preserving geometric constraints. Our results indicate that our deep learning model is very efficient, generalizes well and produces high quality reconstructions.