 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYongsheng Gao
Distribution-aware Margin Calibration for Semantic Segmentation in Images
Dec 21, 2021
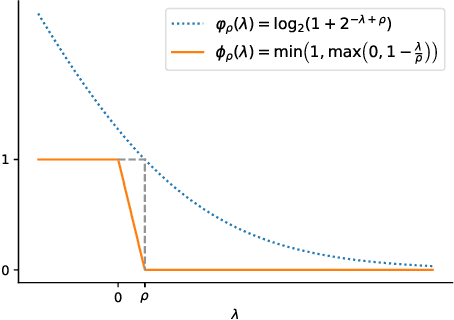
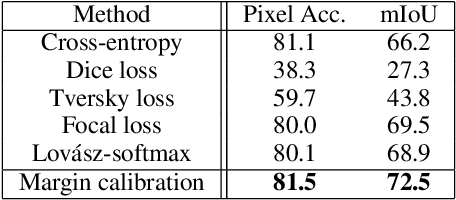

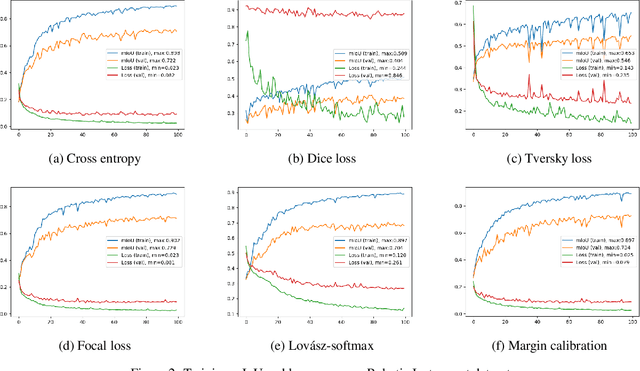
The Jaccard index, also known as Intersection-over-Union (IoU), is one of the most critical evaluation metrics in image semantic segmentation. However, direct optimization of IoU score is very difficult because the learning objective is neither differentiable nor decomposable. Although some algorithms have been proposed to optimize its surrogates, there is no guarantee provided for the generalization ability. In this paper, we propose a margin calibration method, which can be directly used as a learning objective, for an improved generalization of IoU over the data-distribution, underpinned by a rigid lower bound. This scheme theoretically ensures a better segmentation performance in terms of IoU score. We evaluated the effectiveness of the proposed margin calibration method on seven image datasets, showing substantial improvements in IoU score over other learning objectives using deep segmentation models.
A Compositional Feature Embedding and Similarity Metric for Ultra-Fine-Grained Visual Categorization
Oct 06, 2021
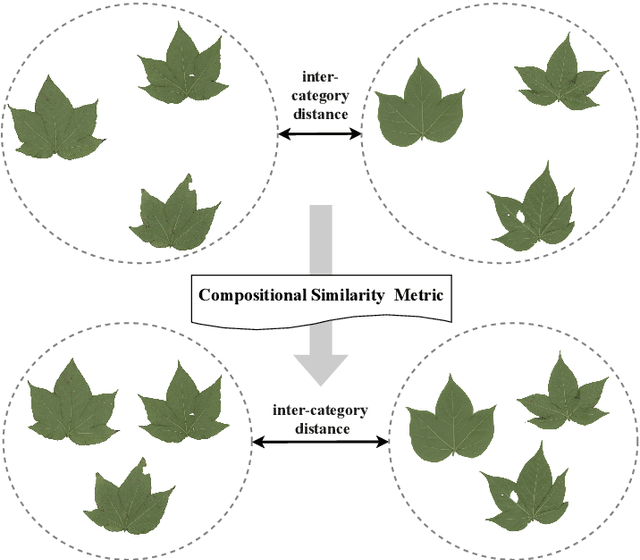
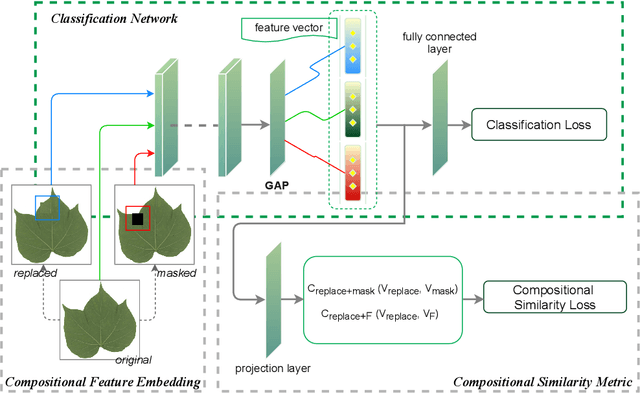
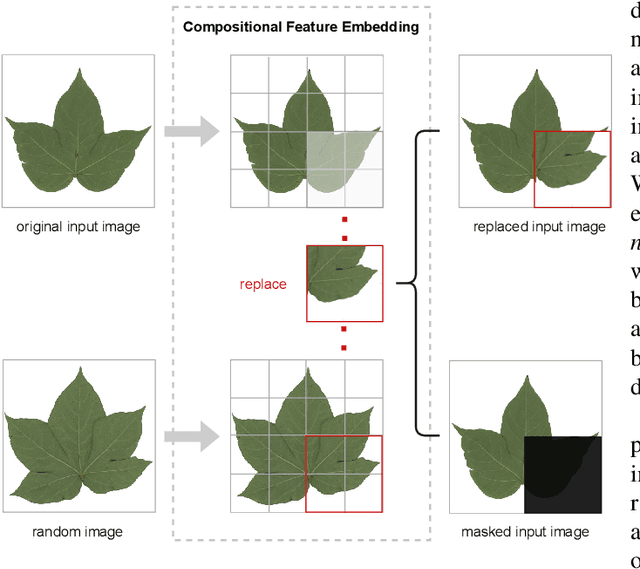
Fine-grained visual categorization (FGVC), which aims at classifying objects with small inter-class variances, has been significantly advanced in recent years. However, ultra-fine-grained visual categorization (ultra-FGVC), which targets at identifying subclasses with extremely similar patterns, has not received much attention. In ultra-FGVC datasets, the samples per category are always scarce as the granularity moves down, which will lead to overfitting problems. Moreover, the difference among different categories is too subtle to distinguish even for professional experts. Motivated by these issues, this paper proposes a novel compositional feature embedding and similarity metric (CECS). Specifically, in the compositional feature embedding module, we randomly select patches in the original input image, and these patches are then replaced by patches from the images of different categories or masked out. Then the replaced and masked images are used to augment the original input images, which can provide more diverse samples and thus largely alleviate overfitting problem resulted from limited training samples. Besides, learning with diverse samples forces the model to learn not only the most discriminative features but also other informative features in remaining regions, enhancing the generalization and robustness of the model. In the compositional similarity metric module, a new similarity metric is developed to improve the classification performance by narrowing the intra-category distance and enlarging the inter-category distance. Experimental results on two ultra-FGVC datasets and one FGVC dataset with recent benchmark methods consistently demonstrate that the proposed CECS method achieves the state of-the-art performance.
Mask-Guided Feature Extraction and Augmentation for Ultra-Fine-Grained Visual Categorization
Sep 16, 2021
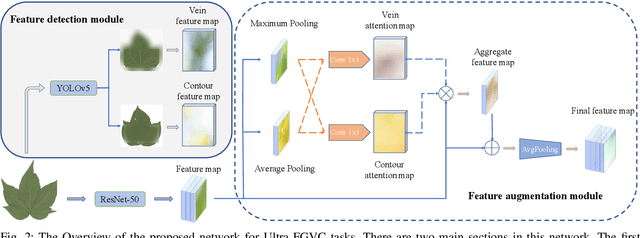
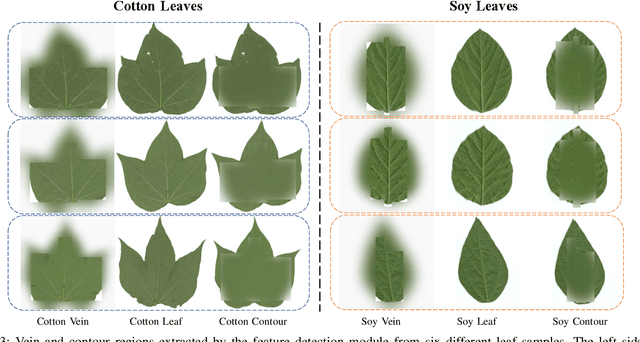
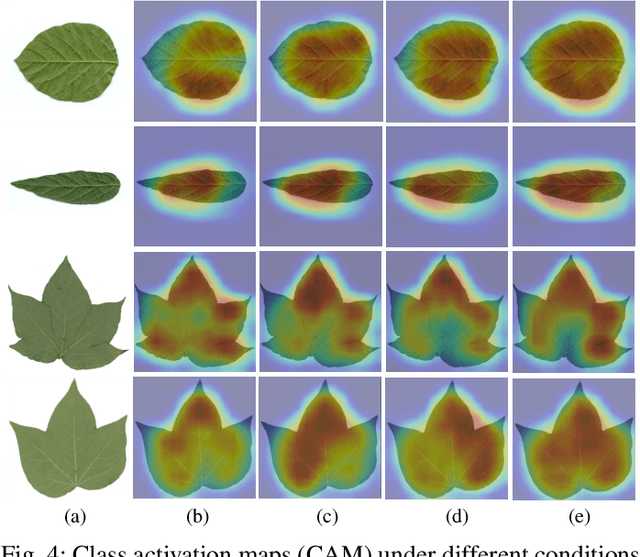
While the fine-grained visual categorization (FGVC) problems have been greatly developed in the past years, the Ultra-fine-grained visual categorization (Ultra-FGVC) problems have been understudied. FGVC aims at classifying objects from the same species (very similar categories), while the Ultra-FGVC targets at more challenging problems of classifying images at an ultra-fine granularity where even human experts may fail to identify the visual difference. The challenges for Ultra-FGVC mainly comes from two aspects: one is that the Ultra-FGVC often arises overfitting problems due to the lack of training samples; and another lies in that the inter-class variance among images is much smaller than normal FGVC tasks, which makes it difficult to learn discriminative features for each class. To solve these challenges, a mask-guided feature extraction and feature augmentation method is proposed in this paper to extract discriminative and informative regions of images which are then used to augment the original feature map. The advantage of the proposed method is that the feature detection and extraction model only requires a small amount of target region samples with bounding boxes for training, then it can automatically locate the target area for a large number of images in the dataset at a high detection accuracy. Experimental results on two public datasets and ten state-of-the-art benchmark methods consistently demonstrate the effectiveness of the proposed method both visually and quantitatively.
Self-Supervised Video Object Segmentation by Motion-Aware Mask Propagation
Jul 27, 2021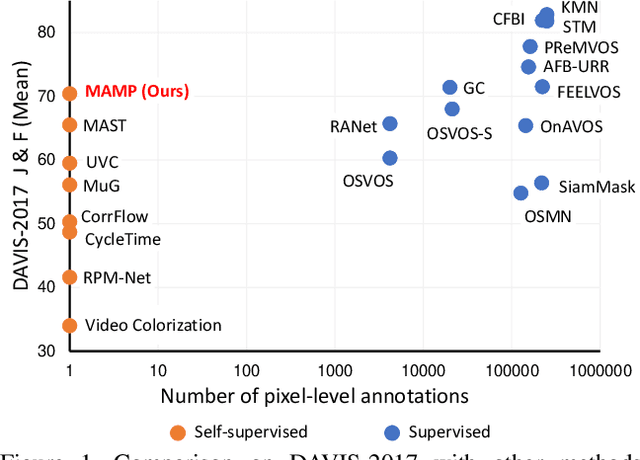

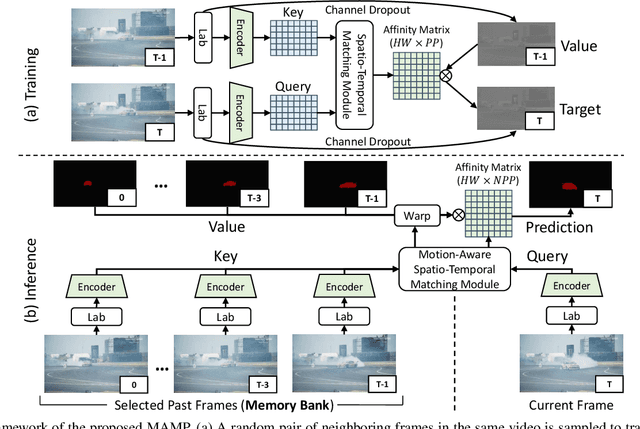
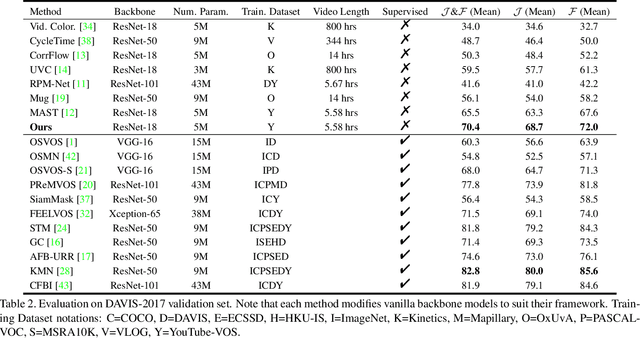
We propose a self-supervised spatio-temporal matching method coined Motion-Aware Mask Propagation (MAMP) for semi-supervised video object segmentation. During training, MAMP leverages the frame reconstruction task to train the model without the need for annotations. During inference, MAMP extracts high-resolution features from each frame to build a memory bank from the features as well as the predicted masks of selected past frames. MAMP then propagates the masks from the memory bank to subsequent frames according to our motion-aware spatio-temporal matching module, also proposed in this paper. Evaluation on DAVIS-2017 and YouTube-VOS datasets show that MAMP achieves state-of-the-art performance with stronger generalization ability compared to existing self-supervised methods, i.e. 4.9\% higher mean $\mathcal{J}\&\mathcal{F}$ on DAVIS-2017 and 4.85\% higher mean $\mathcal{J}\&\mathcal{F}$ on the unseen categories of YouTube-VOS than the nearest competitor. Moreover, MAMP performs on par with many supervised video object segmentation methods. Our code is available at: \url{https://github.com/bo-miao/MAMP}.
NDPNet: A novel non-linear data projection network for few-shot fine-grained image classification
Jul 09, 2021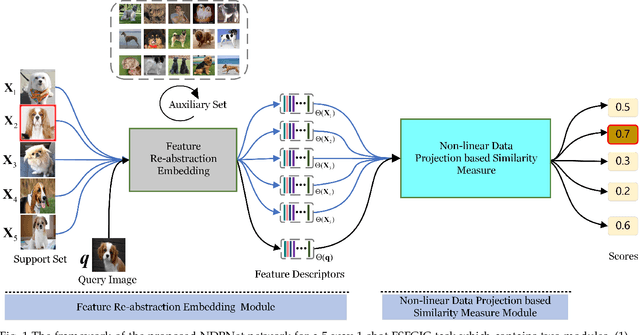
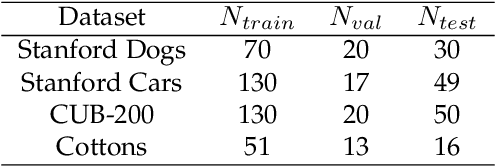
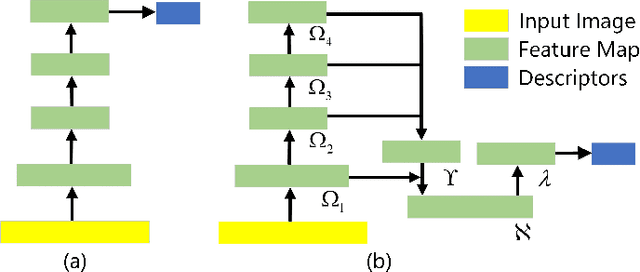
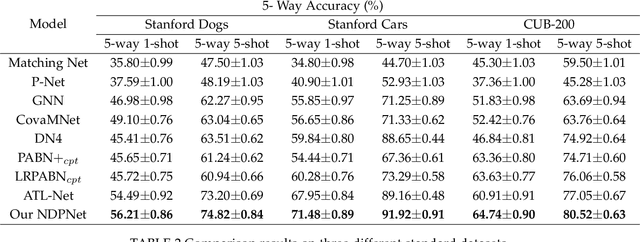
Metric-based few-shot fine-grained image classification (FSFGIC) aims to learn a transferable feature embedding network by estimating the similarities between query images and support classes from very few examples. In this work, we propose, for the first time, to introduce the non-linear data projection concept into the design of FSFGIC architecture in order to address the limited sample problem in few-shot learning and at the same time to increase the discriminability of the model for fine-grained image classification. Specifically, we first design a feature re-abstraction embedding network that has the ability to not only obtain the required semantic features for effective metric learning but also re-enhance such features with finer details from input images. Then the descriptors of the query images and the support classes are projected into different non-linear spaces in our proposed similarity metric learning network to learn discriminative projection factors. This design can effectively operate in the challenging and restricted condition of a FSFGIC task for making the distance between the samples within the same class smaller and the distance between samples from different classes larger and for reducing the coupling relationship between samples from different categories. Furthermore, a novel similarity measure based on the proposed non-linear data project is presented for evaluating the relationships of feature information between a query image and a support set. It is worth to note that our proposed architecture can be easily embedded into any episodic training mechanisms for end-to-end training from scratch. Extensive experiments on FSFGIC tasks demonstrate the superiority of the proposed methods over the state-of-the-art benchmarks.
Feature Fusion Vision Transformer for Fine-Grained Visual Categorization
Jul 07, 2021
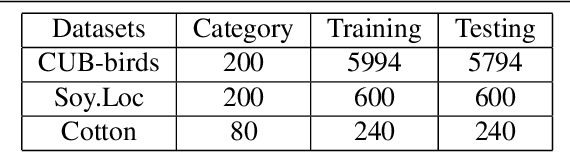
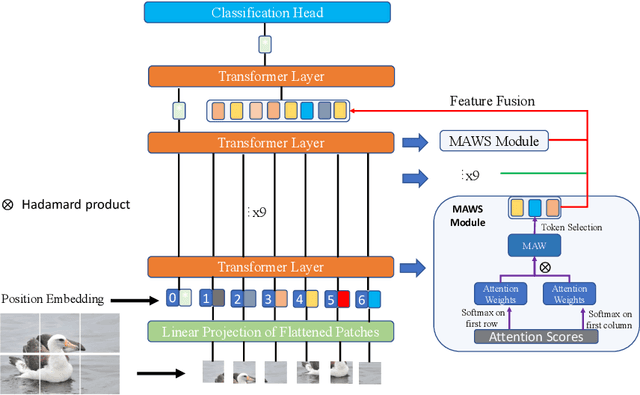
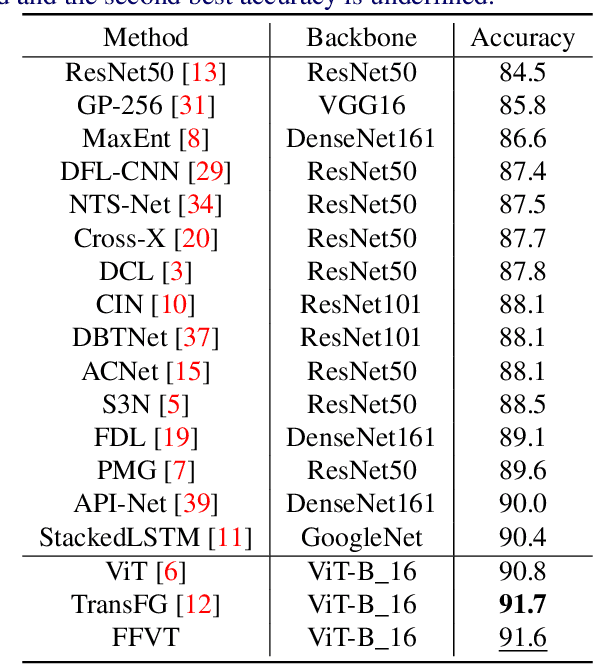
The core for tackling the fine-grained visual categorization (FGVC) is to learn subtle yet discriminative features. Most previous works achieve this by explicitly selecting the discriminative parts or integrating the attention mechanism via CNN-based approaches.However, these methods enhance the computational complexity and make the modeldominated by the regions containing the most of the objects. Recently, vision trans-former (ViT) has achieved SOTA performance on general image recognition tasks. Theself-attention mechanism aggregates and weights the information from all patches to the classification token, making it perfectly suitable for FGVC. Nonetheless, the classifi-cation token in the deep layer pays more attention to the global information, lacking the local and low-level features that are essential for FGVC. In this work, we proposea novel pure transformer-based framework Feature Fusion Vision Transformer (FFVT)where we aggregate the important tokens from each transformer layer to compensate thelocal, low-level and middle-level information. We design a novel token selection mod-ule called mutual attention weight selection (MAWS) to guide the network effectively and efficiently towards selecting discriminative tokens without introducing extra param-eters. We verify the effectiveness of FFVT on three benchmarks where FFVT achieves the state-of-the-art performance.
Image Feature Information Extraction for Interest Point Detection: A Comprehensive Review
Jul 06, 2021
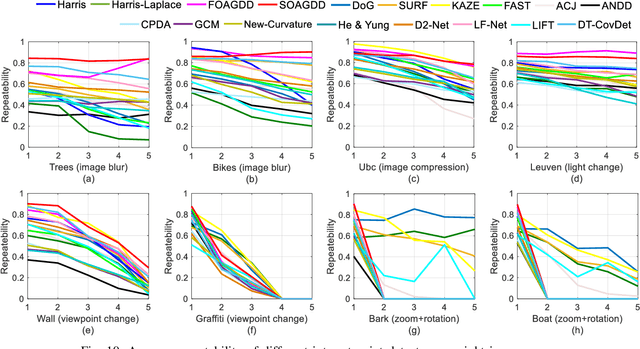

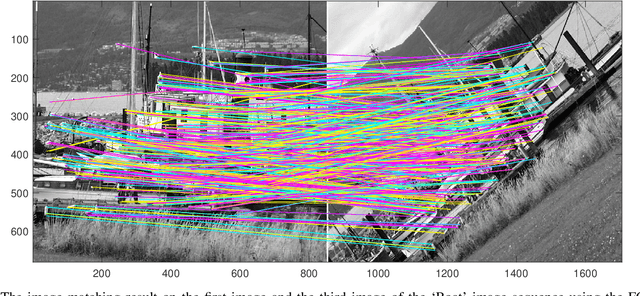
Interest point detection is one of the most fundamental and critical problems in computer vision and image processing. In this paper, we carry out a comprehensive review on image feature information (IFI) extraction techniques for interest point detection. To systematically introduce how the existing interest point detection methods extract IFI from an input image, we propose a taxonomy of the IFI extraction techniques for interest point detection. According to this taxonomy, we discuss different types of IFI extraction techniques for interest point detection. Furthermore, we identify the main unresolved issues related to the existing IFI extraction techniques for interest point detection and any interest point detection methods that have not been discussed before. The existing popular datasets and evaluation standards are provided and the performances for eighteen state-of-the-art approaches are evaluated and discussed. Moreover, future research directions on IFI extraction techniques for interest point detection are elaborated.
Feature Fusion Vision Transformer Fine-Grained Visual Categorization
Jul 06, 2021The core for tackling the fine-grained visual categorization (FGVC) is to learn subtleyet discriminative features. Most previous works achieve this by explicitly selecting thediscriminative parts or integrating the attention mechanism via CNN-based approaches.However, these methods enhance the computational complexity and make the modeldominated by the regions containing the most of the objects. Recently, vision trans-former (ViT) has achieved SOTA performance on general image recognition tasks. Theself-attention mechanism aggregates and weights the information from all patches to theclassification token, making it perfectly suitable for FGVC. Nonetheless, the classifi-cation token in the deep layer pays more attention to the global information, lackingthe local and low-level features that are essential for FGVC. In this work, we proposea novel pure transformer-based framework Feature Fusion Vision Transformer (FFVT)where we aggregate the important tokens from each transformer layer to compensate thelocal, low-level and middle-level information. We design a novel token selection mod-ule called mutual attention weight selection (MAWS) to guide the network effectivelyand efficiently towards selecting discriminative tokens without introducing extra param-eters. We verify the effectiveness of FFVT on three benchmarks where FFVT achievesthe state-of-the-art performance.
EAR-NET: Error Attention Refining Network For Retinal Vessel Segmentation
Jul 03, 2021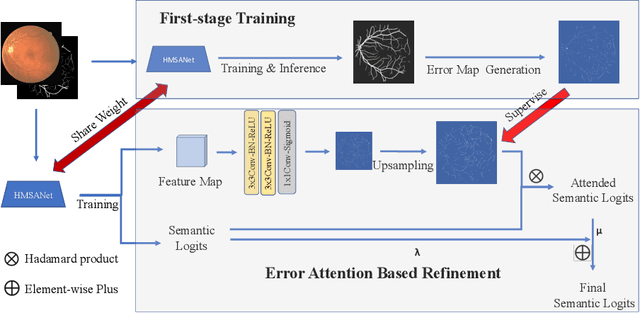
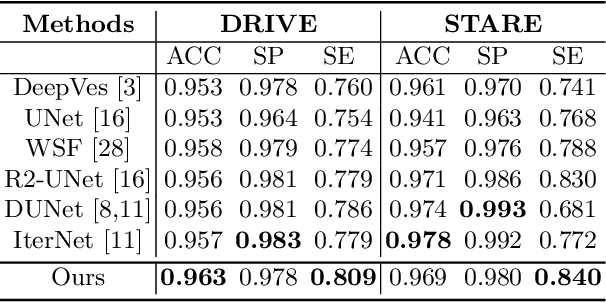

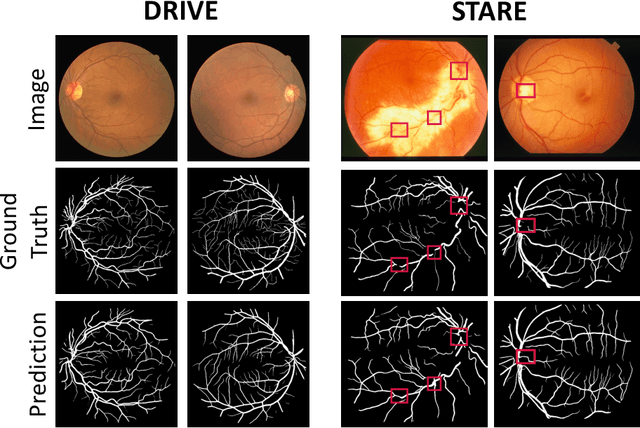
The precise detection of blood vessels in retinal images is crucial to the early diagnosis of the retinal vascular diseases, e.g., diabetic, hypertensive and solar retinopathies. Existing works often fail in predicting the abnormal areas, e.g, sudden brighter and darker areas and are inclined to predict a pixel to background due to the significant class imbalance, leading to high accuracy and specificity while low sensitivity. To that end, we propose a novel error attention refining network (ERA-Net) that is capable of learning and predicting the potential false predictions in a two-stage manner for effective retinal vessel segmentation. The proposed ERA-Net in the refine stage drives the model to focus on and refine the segmentation errors produced in the initial training stage. To achieve this, unlike most previous attention approaches that run in an unsupervised manner, we introduce a novel error attention mechanism which considers the differences between the ground truth and the initial segmentation masks as the ground truth to supervise the attention map learning. Experimental results demonstrate that our method achieves state-of-the-art performance on two common retinal blood vessel datasets.