 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYonghong Tian
Deep recurrent spiking neural networks capture both static and dynamic representations of the visual cortex under movie stimuli
Jun 02, 2023
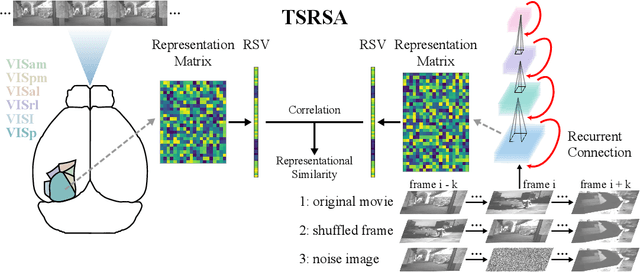
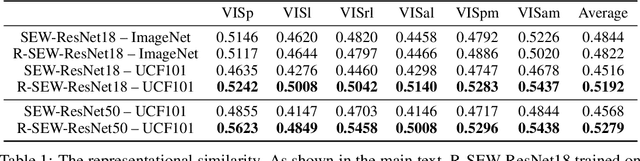
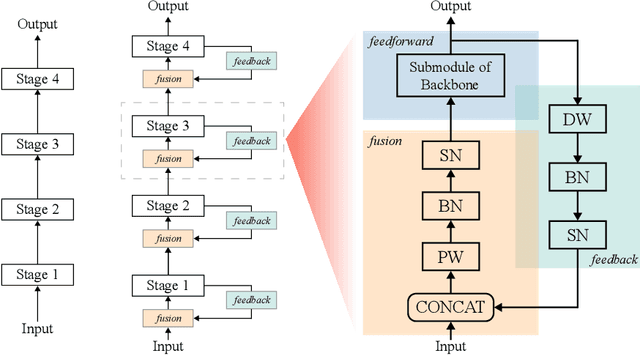
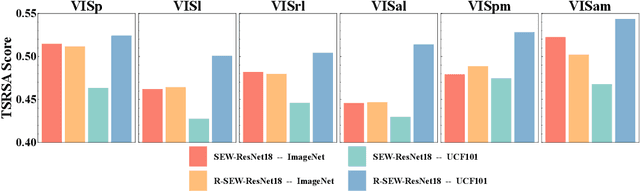
In the real world, visual stimuli received by the biological visual system are predominantly dynamic rather than static. A better understanding of how the visual cortex represents movie stimuli could provide deeper insight into the information processing mechanisms of the visual system. Although some progress has been made in modeling neural responses to natural movies with deep neural networks, the visual representations of static and dynamic information under such time-series visual stimuli remain to be further explored. In this work, considering abundant recurrent connections in the mouse visual system, we design a recurrent module based on the hierarchy of the mouse cortex and add it into Deep Spiking Neural Networks, which have been demonstrated to be a more compelling computational model for the visual cortex. Using Time-Series Representational Similarity Analysis, we measure the representational similarity between networks and mouse cortical regions under natural movie stimuli. Subsequently, we conduct a comparison of the representational similarity across recurrent/feedforward networks and image/video training tasks. Trained on the video action recognition task, recurrent SNN achieves the highest representational similarity and significantly outperforms feedforward SNN trained on the same task by 15% and the recurrent SNN trained on the image classification task by 8%. We investigate how static and dynamic representations of SNNs influence the similarity, as a way to explain the importance of these two forms of representations in biological neural coding. Taken together, our work is the first to apply deep recurrent SNNs to model the mouse visual cortex under movie stimuli and we establish that these networks are competent to capture both static and dynamic representations and make contributions to understanding the movie information processing mechanisms of the visual cortex.
Auto-Spikformer: Spikformer Architecture Search
Jun 01, 2023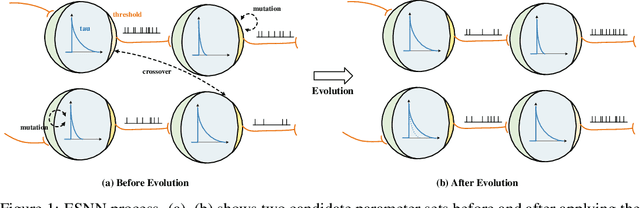

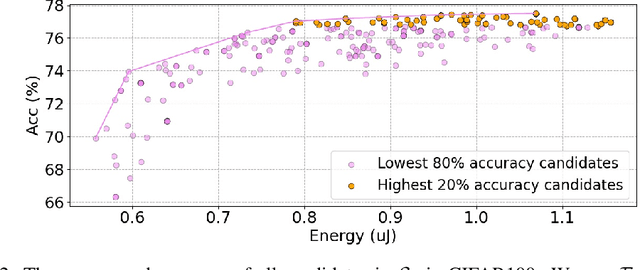
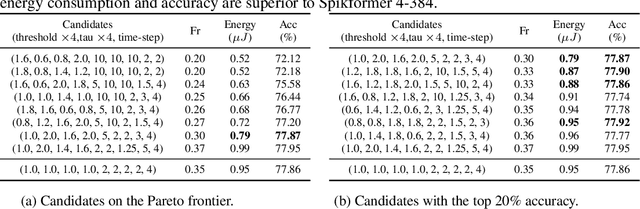
The integration of self-attention mechanisms into Spiking Neural Networks (SNNs) has garnered considerable interest in the realm of advanced deep learning, primarily due to their biological properties. Recent advancements in SNN architecture, such as Spikformer, have demonstrated promising outcomes by leveraging Spiking Self-Attention (SSA) and Spiking Patch Splitting (SPS) modules. However, we observe that Spikformer may exhibit excessive energy consumption, potentially attributable to redundant channels and blocks. To mitigate this issue, we propose Auto-Spikformer, a one-shot Transformer Architecture Search (TAS) method, which automates the quest for an optimized Spikformer architecture. To facilitate the search process, we propose methods Evolutionary SNN neurons (ESNN), which optimizes the SNN parameters, and apply the previous method of weight entanglement supernet training, which optimizes the Vision Transformer (ViT) parameters. Moreover, we propose an accuracy and energy balanced fitness function $\mathcal{F}_{AEB}$ that jointly considers both energy consumption and accuracy, and aims to find a Pareto optimal combination that balances these two objectives. Our experimental results demonstrate the effectiveness of Auto-Spikformer, which outperforms the state-of-the-art method including CNN or ViT models that are manually or automatically designed while significantly reducing energy consumption.
Album Storytelling with Iterative Story-aware Captioning and Large Language Models
May 24, 2023
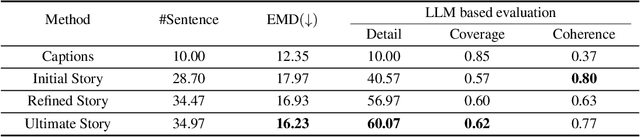
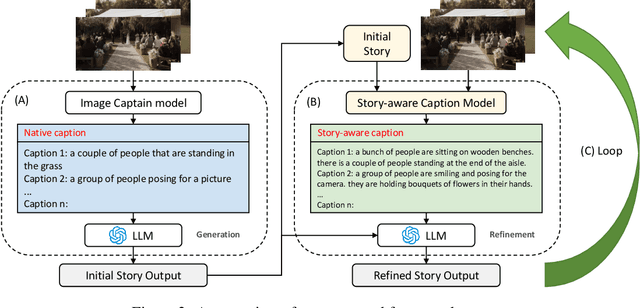

This work studies how to transform an album to vivid and coherent stories, a task we refer to as "album storytelling". While this task can help preserve memories and facilitate experience sharing, it remains an underexplored area in current literature. With recent advances in Large Language Models (LLMs), it is now possible to generate lengthy, coherent text, opening up the opportunity to develop an AI assistant for album storytelling. One natural approach is to use caption models to describe each photo in the album, and then use LLMs to summarize and rewrite the generated captions into an engaging story. However, we find this often results in stories containing hallucinated information that contradicts the images, as each generated caption ("story-agnostic") is not always about the description related to the whole story or miss some necessary information. To address these limitations, we propose a new iterative album storytelling pipeline. Specifically, we start with an initial story and build a story-aware caption model to refine the captions using the whole story as guidance. The polished captions are then fed into the LLMs to generate a new refined story. This process is repeated iteratively until the story contains minimal factual errors while maintaining coherence. To evaluate our proposed pipeline, we introduce a new dataset of image collections from vlogs and a set of systematic evaluation metrics. Our results demonstrate that our method effectively generates more accurate and engaging stories for albums, with enhanced coherence and vividness.
Temporal Contrastive Learning for Spiking Neural Networks
May 23, 2023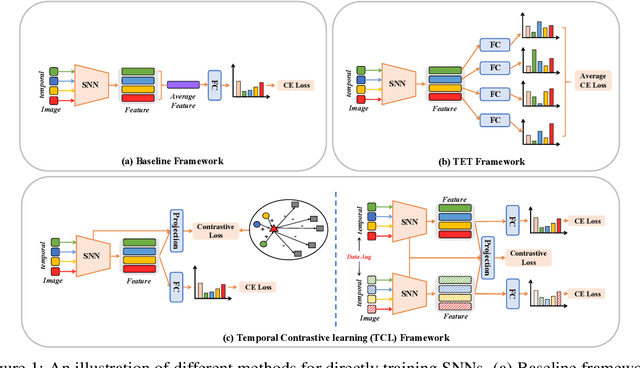
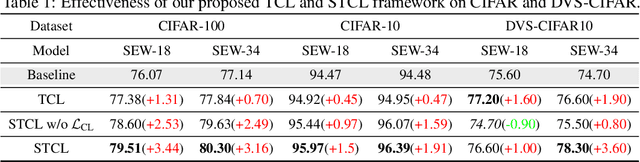
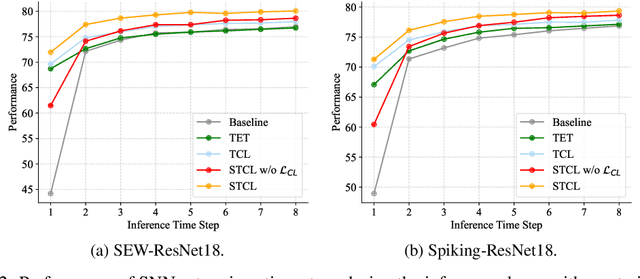
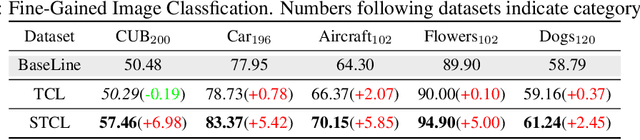
Biologically inspired spiking neural networks (SNNs) have garnered considerable attention due to their low-energy consumption and spatio-temporal information processing capabilities. Most existing SNNs training methods first integrate output information across time steps, then adopt the cross-entropy (CE) loss to supervise the prediction of the average representations. However, in this work, we find the method above is not ideal for the SNNs training as it omits the temporal dynamics of SNNs and degrades the performance quickly with the decrease of inference time steps. One tempting method to model temporal correlations is to apply the same label supervision at each time step and treat them identically. Although it can acquire relatively consistent performance across various time steps, it still faces challenges in obtaining SNNs with high performance. Inspired by these observations, we propose Temporal-domain supervised Contrastive Learning (TCL) framework, a novel method to obtain SNNs with low latency and high performance by incorporating contrastive supervision with temporal domain information. Contrastive learning (CL) prompts the network to discern both consistency and variability in the representation space, enabling it to better learn discriminative and generalizable features. We extend this concept to the temporal domain of SNNs, allowing us to flexibly and fully leverage the correlation between representations at different time steps. Furthermore, we propose a Siamese Temporal-domain supervised Contrastive Learning (STCL) framework to enhance the SNNs via augmentation, temporal and class constraints simultaneously. Extensive experimental results demonstrate that SNNs trained by our TCL and STCL can achieve both high performance and low latency, achieving state-of-the-art performance on a variety of datasets (e.g., CIFAR-10, CIFAR-100, and DVS-CIFAR10).
Probabilistic Modeling: Proving the Lottery Ticket Hypothesis in Spiking Neural Network
May 20, 2023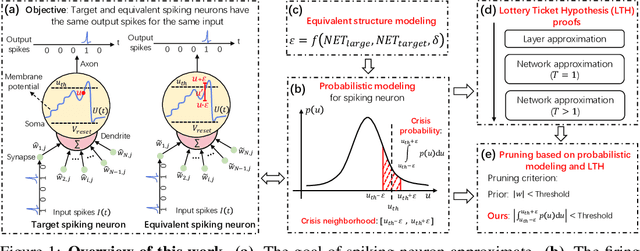

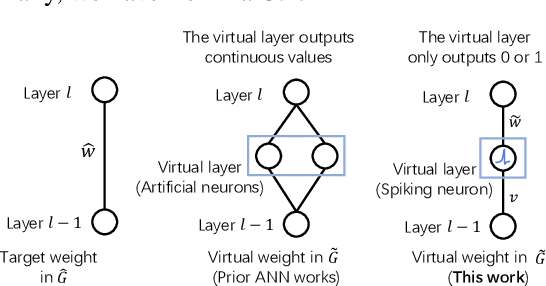
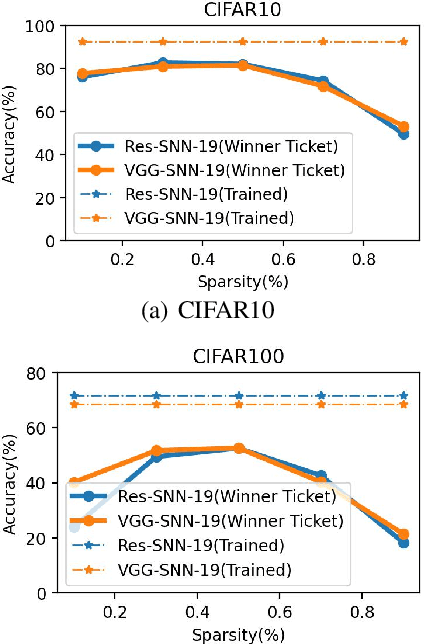
The Lottery Ticket Hypothesis (LTH) states that a randomly-initialized large neural network contains a small sub-network (i.e., winning tickets) which, when trained in isolation, can achieve comparable performance to the large network. LTH opens up a new path for network pruning. Existing proofs of LTH in Artificial Neural Networks (ANNs) are based on continuous activation functions, such as ReLU, which satisfying the Lipschitz condition. However, these theoretical methods are not applicable in Spiking Neural Networks (SNNs) due to the discontinuous of spiking function. We argue that it is possible to extend the scope of LTH by eliminating Lipschitz condition. Specifically, we propose a novel probabilistic modeling approach for spiking neurons with complicated spatio-temporal dynamics. Then we theoretically and experimentally prove that LTH holds in SNNs. According to our theorem, we conclude that pruning directly in accordance with the weight size in existing SNNs is clearly not optimal. We further design a new criterion for pruning based on our theory, which achieves better pruning results than baseline.
Enhancing the Performance of Transformer-based Spiking Neural Networks by SNN-optimized Downsampling with Precise Gradient Backpropagation
May 19, 2023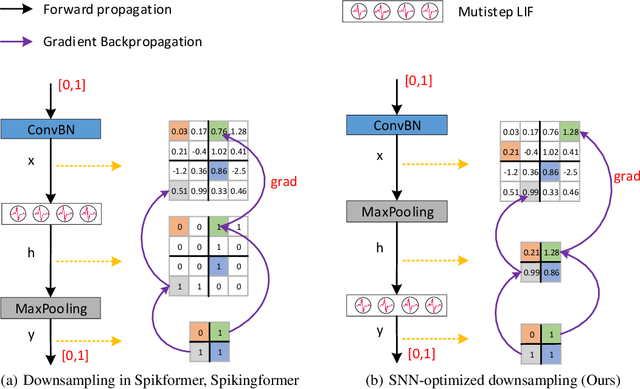

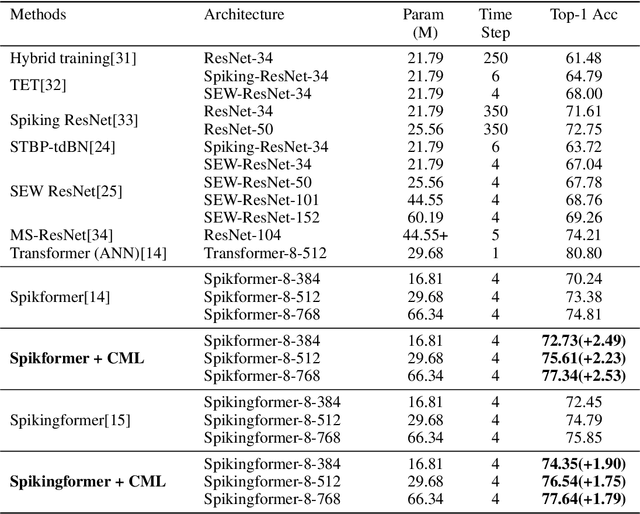
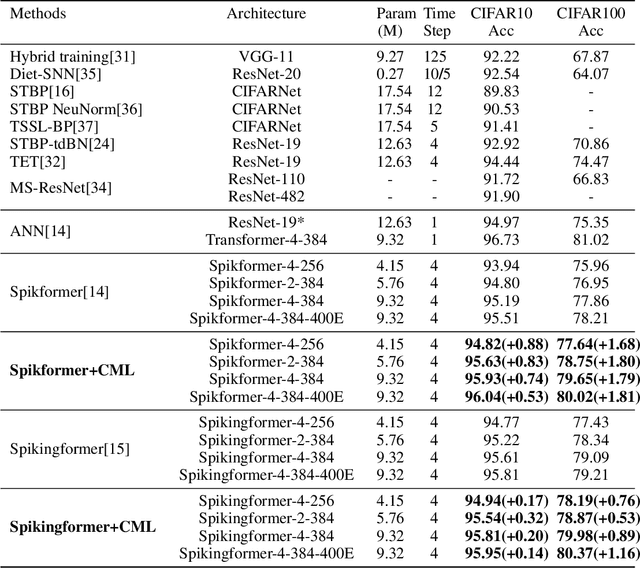
Deep spiking neural networks (SNNs) have drawn much attention in recent years because of their low power consumption, biological rationality and event-driven property. However, state-of-the-art deep SNNs (including Spikformer and Spikingformer) suffer from a critical challenge related to the imprecise gradient backpropagation. This problem arises from the improper design of downsampling modules in these networks, and greatly hampering the overall model performance. In this paper, we propose ConvBN-MaxPooling-LIF (CML), an SNN-optimized downsampling with precise gradient backpropagation. We prove that CML can effectively overcome the imprecision of gradient backpropagation from a theoretical perspective. In addition, we evaluate CML on ImageNet, CIFAR10, CIFAR100, CIFAR10-DVS, DVS128-Gesture datasets, and show state-of-the-art performance on all these datasets with significantly enhanced performances compared with Spikingformer. For instance, our model achieves 77.64 $\%$ on ImageNet, 96.04 $\%$ on CIFAR10, 81.4$\%$ on CIFAR10-DVS, with + 1.79$\%$ on ImageNet, +1.16$\%$ on CIFAR100 compared with Spikingformer.
Enhancing the Performance of Transformer-based Spiking Neural Networks by Improved Downsampling with Precise Gradient Backpropagation
May 10, 2023Deep spiking neural networks (SNNs) have drawn much attention in recent years because of their low power consumption, biological rationality and event-driven property. However, state-of-the-art deep SNNs (including Spikformer and Spikingformer) suffer from a critical challenge related to the imprecise gradient backpropagation. This problem arises from the improper design of downsampling modules in these networks, and greatly hampering the overall model performance. In this paper, we propose ConvBN-MaxPooling-LIF (CML), an improved downsampling with precise gradient backpropagation. We prove that CML can effectively overcome the imprecision of gradient backpropagation from a theoretical perspective. In addition, we evaluate CML on ImageNet, CIFAR10, CIFAR100, CIFAR10-DVS, DVS128-Gesture datasets, and show state-of-the-art performance on all these datasets with significantly enhanced performances compared with Spikingformer. For instance, our model achieves 77.64 $\%$ on ImageNet, 96.04 $\%$ on CIFAR10, 81.4$\%$ on CIFAR10-DVS, with + 1.79$\%$ on ImageNet, +1.54$\%$ on CIFAR100 compared with Spikingformer.
Parallel Spiking Neurons with High Efficiency and Long-term Dependencies Learning Ability
Apr 25, 2023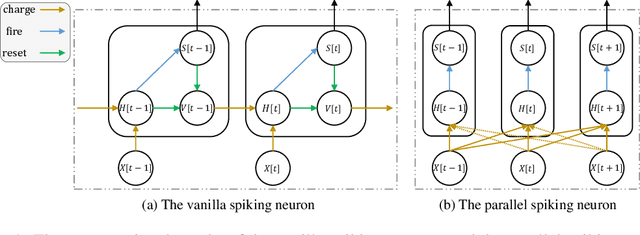

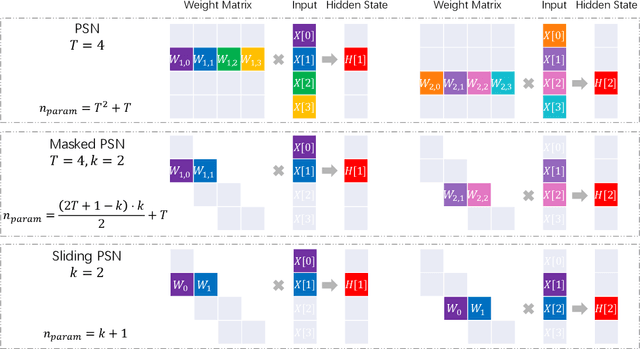
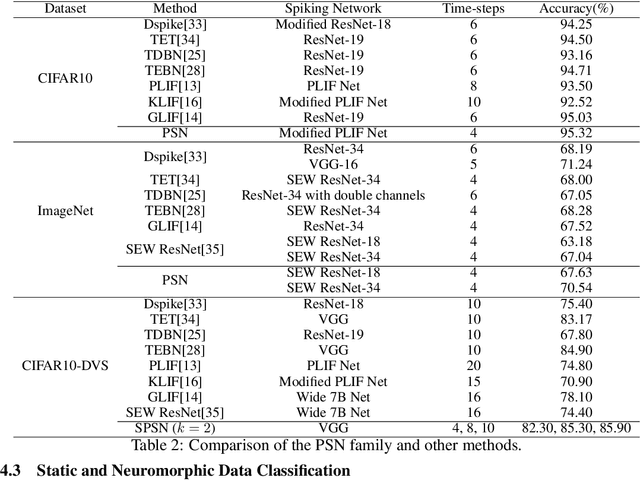
Vanilla spiking neurons in Spiking Neural Networks (SNNs) use charge-fire-reset neuronal dynamics, which can only be simulated in serial and can hardly learn long-time dependencies. We find that when removing reset, the neuronal dynamics are reformulated in a non-iterative form and can be parallelized. By rewriting neuronal dynamics without resetting to a general formulation, we propose the Parallel Spiking Neuron (PSN), which uses dense connections between time-steps to maximize the utilization of temporal information. To avoid the use of future inputs for low-latency inference, we add masks on the weights and obtain the masked PSN. By sharing weights across time-steps, the sliding PSN is proposed with the ability to deal with sequences with variant lengths. We evaluate the PSN family on simulation speed and temporal/static data classification, and the results show the overwhelming advantage of the PSN family in efficiency and accuracy. To our best knowledge, this is the first research about parallelizing spiking neurons and can be a cornerstone for the spiking deep learning community. Our codes are available at \url{https://github.com/fangwei123456/Parallel-Spiking-Neuron}.
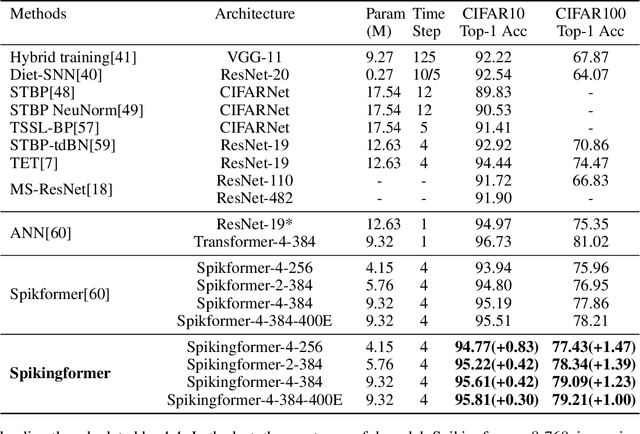
Spikingformer: Spike-driven Residual Learning for Transformer-based Spiking Neural Network
Apr 24, 2023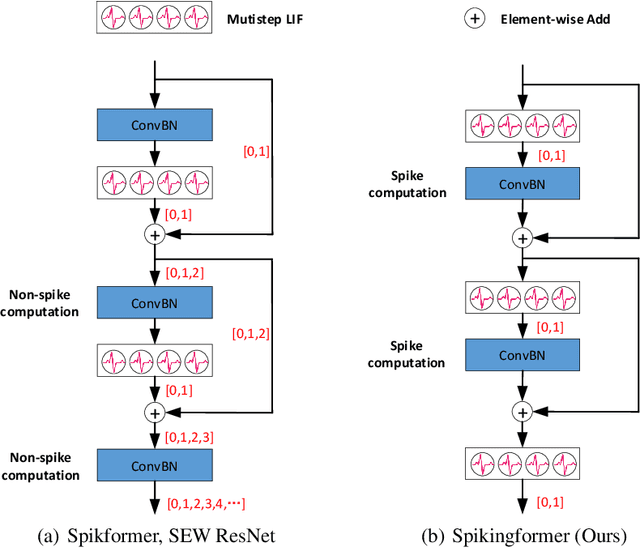
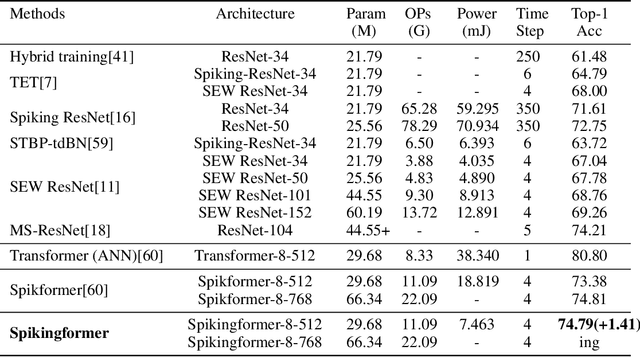
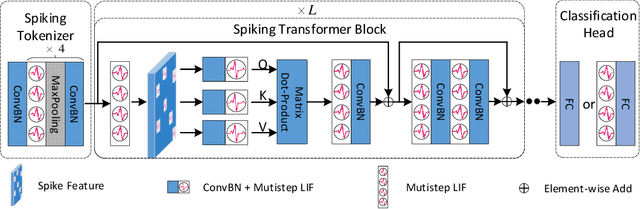
Spiking neural networks (SNNs) offer a promising energy-efficient alternative to artificial neural networks, due to their event-driven spiking computation. However, state-of-the-art deep SNNs (including Spikformer and SEW ResNet) suffer from non-spike computations (integer-float multiplications) caused by the structure of their residual connection. These non-spike computations increase SNNs' power consumption and make them unsuitable for deployment on mainstream neuromorphic hardware, which only supports spike operations. In this paper, we propose a hardware-friendly spike-driven residual learning architecture for SNNs to avoid non-spike computations. Based on this residual design, we develop Spikingformer, a pure transformer-based spiking neural network. We evaluate Spikingformer on ImageNet, CIFAR10, CIFAR100, CIFAR10-DVS and DVS128 Gesture datasets, and demonstrated that Spikingformer outperforms the state-of-the-art in directly trained pure SNNs as a novel advanced backbone (74.79$\%$ top-1 accuracy on ImageNet, + 1.41$\%$ compared with Spikformer). Furthermore, our experiments verify that Spikingformer effectively avoids non-spike computations and reduces energy consumption by 60.34$\%$ compared with Spikformer on ImageNet. To our best knowledge, this is the first time that a pure event-driven transformer-based SNN has been developed.
Picking Up Quantization Steps for Compressed Image Classification
Apr 21, 2023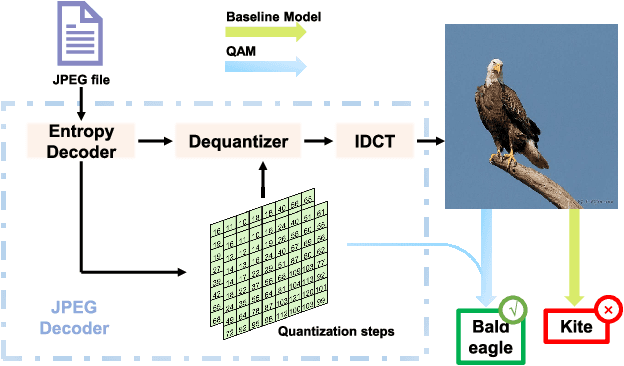
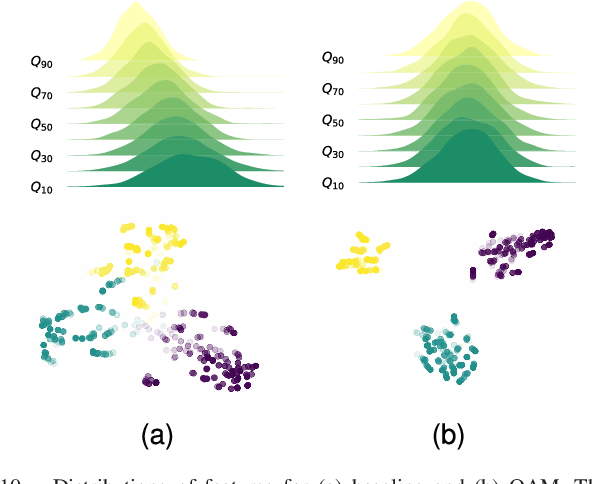
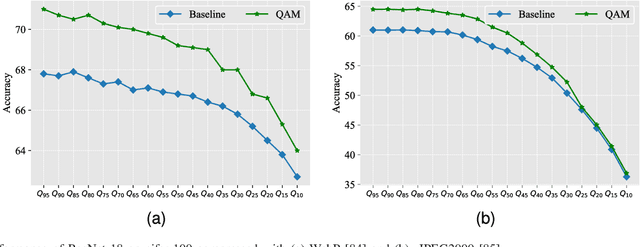
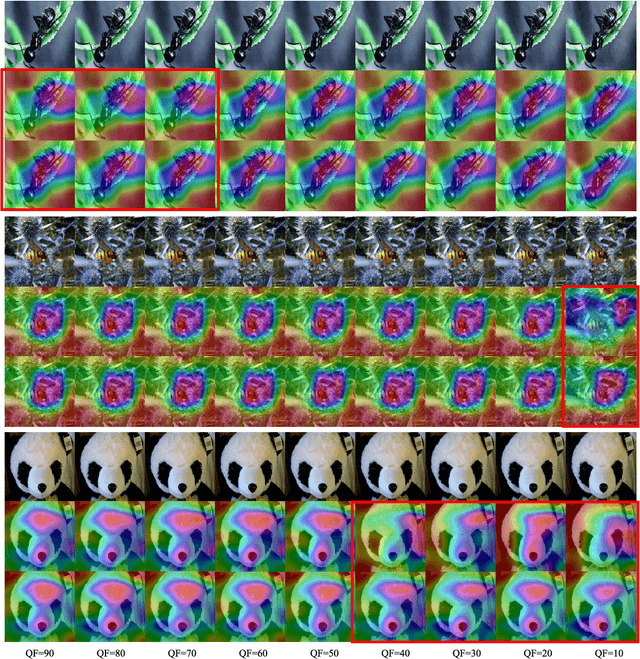
The sensitivity of deep neural networks to compressed images hinders their usage in many real applications, which means classification networks may fail just after taking a screenshot and saving it as a compressed file. In this paper, we argue that neglected disposable coding parameters stored in compressed files could be picked up to reduce the sensitivity of deep neural networks to compressed images. Specifically, we resort to using one of the representative parameters, quantization steps, to facilitate image classification. Firstly, based on quantization steps, we propose a novel quantization aware confidence (QAC), which is utilized as sample weights to reduce the influence of quantization on network training. Secondly, we utilize quantization steps to alleviate the variance of feature distributions, where a quantization aware batch normalization (QABN) is proposed to replace batch normalization of classification networks. Extensive experiments show that the proposed method significantly improves the performance of classification networks on CIFAR-10, CIFAR-100, and ImageNet. The code is released on https://github.com/LiMaPKU/QSAM.git