 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYongdong Zhang
Causal Intervention for Leveraging Popularity Bias in Recommendation
May 13, 2021
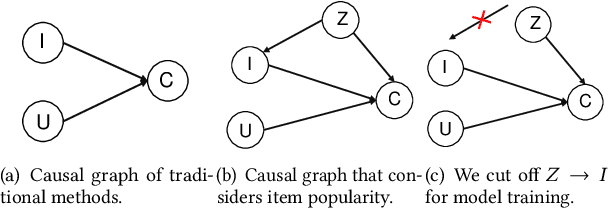
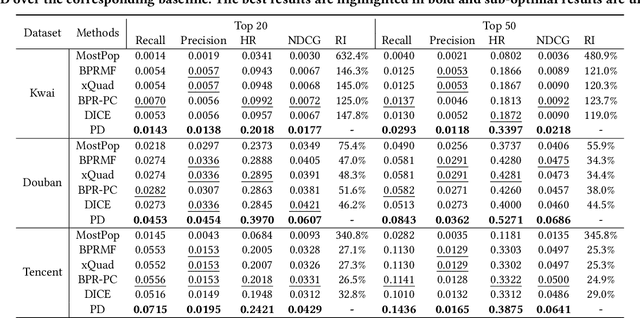
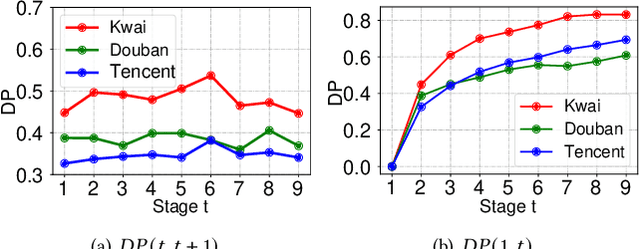
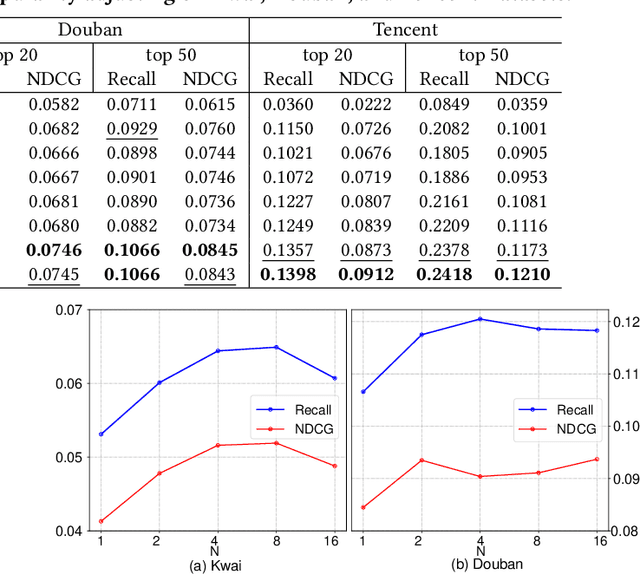
Recommender system usually faces popularity bias issues: from the data perspective, items exhibit uneven (long-tail) distribution on the interaction frequency; from the method perspective, collaborative filtering methods are prone to amplify the bias by over-recommending popular items. It is undoubtedly critical to consider popularity bias in recommender systems, and existing work mainly eliminates the bias effect. However, we argue that not all biases in the data are bad -- some items demonstrate higher popularity because of their better intrinsic quality. Blindly pursuing unbiased learning may remove the beneficial patterns in the data, degrading the recommendation accuracy and user satisfaction. This work studies an unexplored problem in recommendation -- how to leverage popularity bias to improve the recommendation accuracy. The key lies in two aspects: how to remove the bad impact of popularity bias during training, and how to inject the desired popularity bias in the inference stage that generates top-K recommendations. This questions the causal mechanism of the recommendation generation process. Along this line, we find that item popularity plays the role of confounder between the exposed items and the observed interactions, causing the bad effect of bias amplification. To achieve our goal, we propose a new training and inference paradigm for recommendation named Popularity-bias Deconfounding and Adjusting (PDA). It removes the confounding popularity bias in model training and adjusts the recommendation score with desired popularity bias via causal intervention. We demonstrate the new paradigm on latent factor model and perform extensive experiments on three real-world datasets. Empirical studies validate that the deconfounded training is helpful to discover user real interests and the inference adjustment with popularity bias could further improve the recommendation accuracy.
Action Unit Memory Network for Weakly Supervised Temporal Action Localization
Apr 29, 2021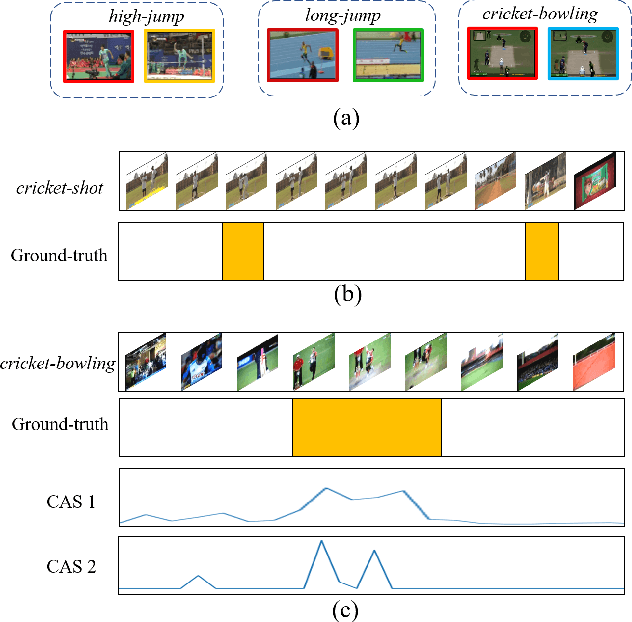
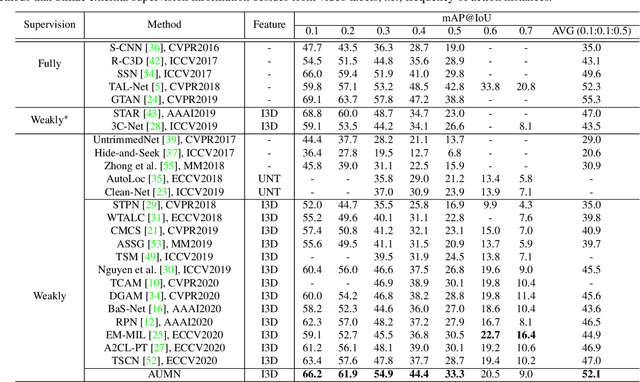
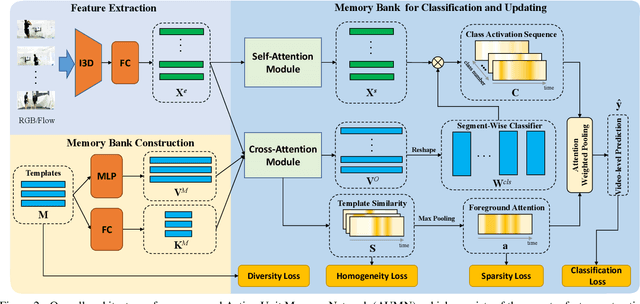
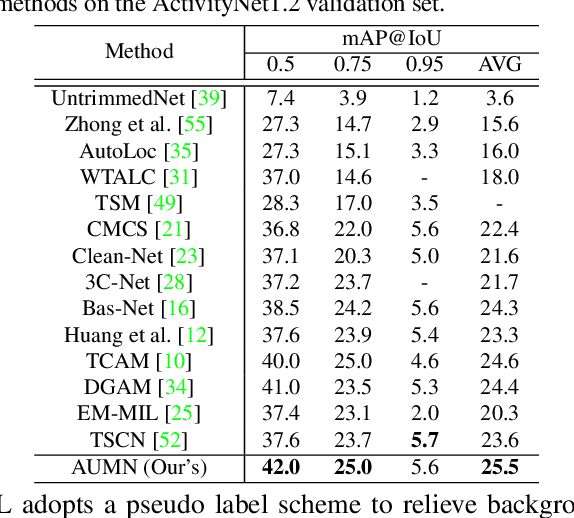
Weakly supervised temporal action localization aims to detect and localize actions in untrimmed videos with only video-level labels during training. However, without frame-level annotations, it is challenging to achieve localization completeness and relieve background interference. In this paper, we present an Action Unit Memory Network (AUMN) for weakly supervised temporal action localization, which can mitigate the above two challenges by learning an action unit memory bank. In the proposed AUMN, two attention modules are designed to update the memory bank adaptively and learn action units specific classifiers. Furthermore, three effective mechanisms (diversity, homogeneity and sparsity) are designed to guide the updating of the memory network. To the best of our knowledge, this is the first work to explicitly model the action units with a memory network. Extensive experimental results on two standard benchmarks (THUMOS14 and ActivityNet) demonstrate that our AUMN performs favorably against state-of-the-art methods. Specifically, the average mAP of IoU thresholds from 0.1 to 0.5 on the THUMOS14 dataset is significantly improved from 47.0% to 52.1%.
Frequency-aware Discriminative Feature Learning Supervised by Single-Center Loss for Face Forgery Detection
Mar 16, 2021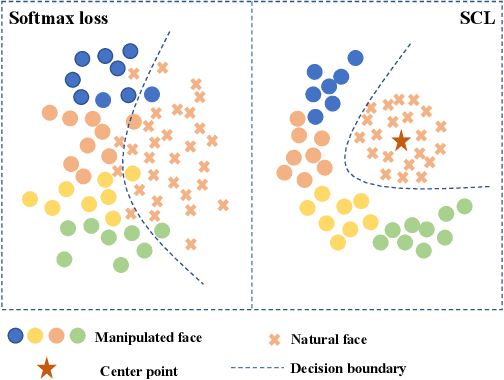
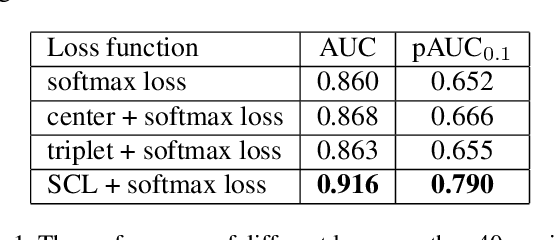
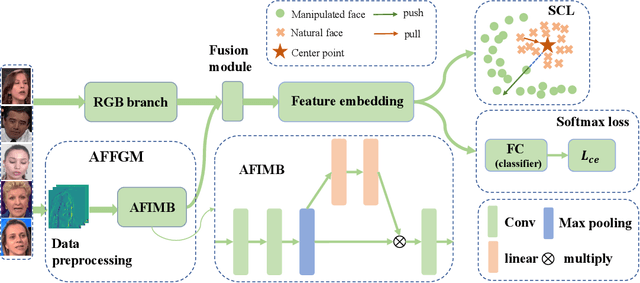
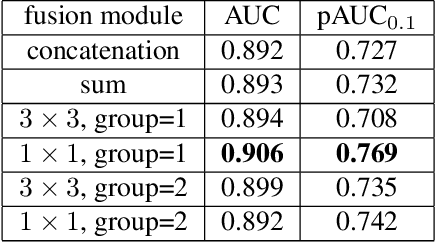
Face forgery detection is raising ever-increasing interest in computer vision since facial manipulation technologies cause serious worries. Though recent works have reached sound achievements, there are still unignorable problems: a) learned features supervised by softmax loss are separable but not discriminative enough, since softmax loss does not explicitly encourage intra-class compactness and interclass separability; and b) fixed filter banks and hand-crafted features are insufficient to capture forgery patterns of frequency from diverse inputs. To compensate for such limitations, a novel frequency-aware discriminative feature learning framework is proposed in this paper. Specifically, we design a novel single-center loss (SCL) that only compresses intra-class variations of natural faces while boosting inter-class differences in the embedding space. In such a case, the network can learn more discriminative features with less optimization difficulty. Besides, an adaptive frequency feature generation module is developed to mine frequency clues in a completely data-driven fashion. With the above two modules, the whole framework can learn more discriminative features in an end-to-end manner. Extensive experiments demonstrate the effectiveness and superiority of our framework on three versions of the FF++ dataset.
Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition
Mar 11, 2021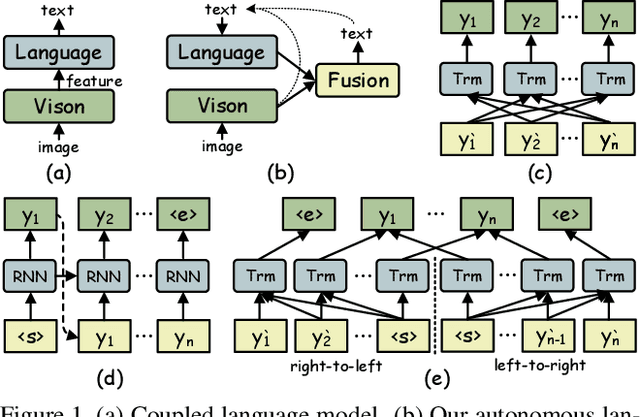
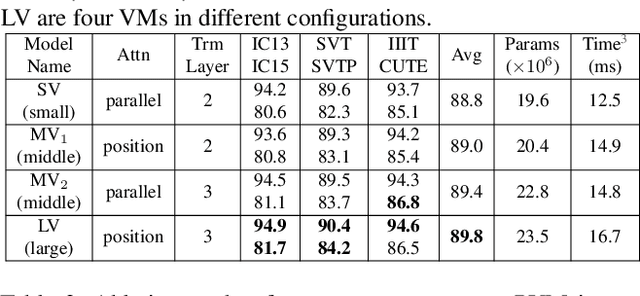
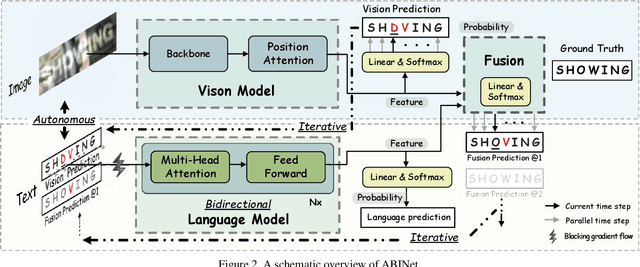
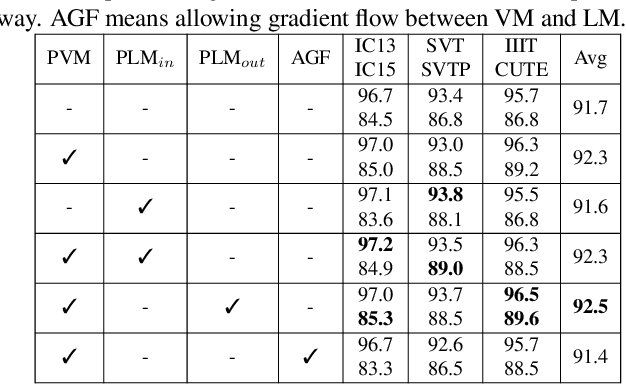
Linguistic knowledge is of great benefit to scene text recognition. However, how to effectively model linguistic rules in end-to-end deep networks remains a research challenge. In this paper, we argue that the limited capacity of language models comes from: 1) implicitly language modeling; 2) unidirectional feature representation; and 3) language model with noise input. Correspondingly, we propose an autonomous, bidirectional and iterative ABINet for scene text recognition. Firstly, the autonomous suggests to block gradient flow between vision and language models to enforce explicitly language modeling. Secondly, a novel bidirectional cloze network (BCN) as the language model is proposed based on bidirectional feature representation. Thirdly, we propose an execution manner of iterative correction for language model which can effectively alleviate the impact of noise input. Additionally, based on the ensemble of iterative predictions, we propose a self-training method which can learn from unlabeled images effectively. Extensive experiments indicate that ABINet has superiority on low-quality images and achieves state-of-the-art results on several mainstream benchmarks. Besides, the ABINet trained with ensemble self-training shows promising improvement in realizing human-level recognition. Code is available at https://github.com/FangShancheng/ABINet.
AttriMeter: An Attribute-guided Metric Interpreter for Person Re-Identification
Mar 02, 2021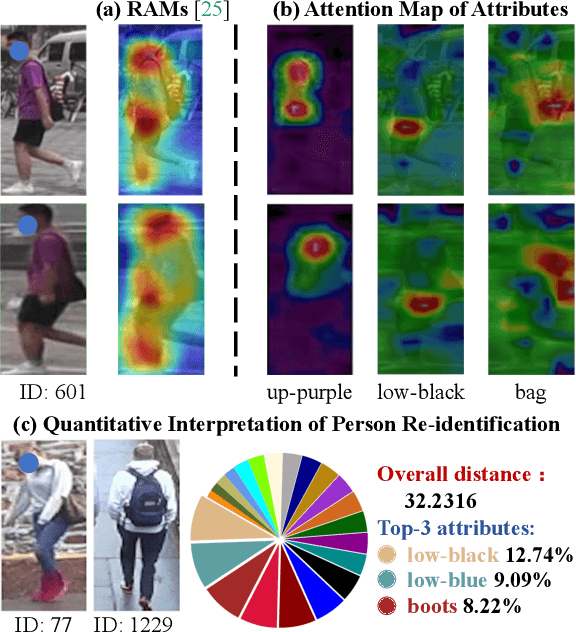

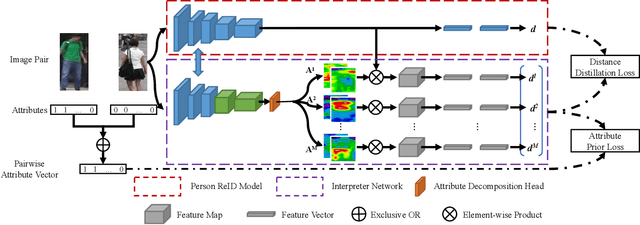
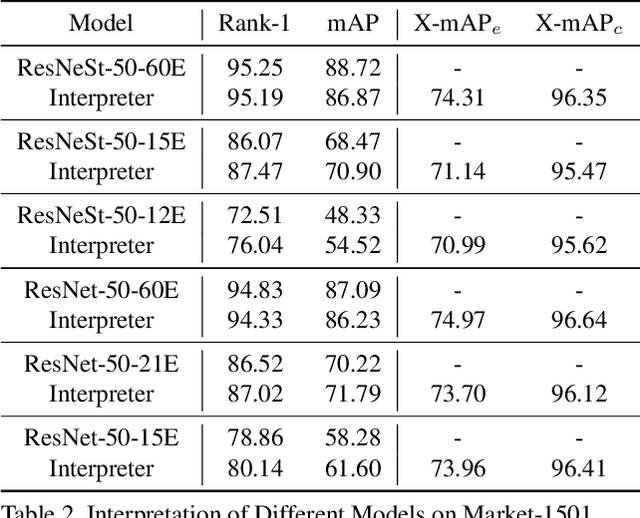
Person Re-identification (ReID) has achieved significant improvement due to the adoption of Convolutional Neural Networks (CNNs). However, person ReID systems only provide a distance or similarity when matching two persons, which makes users hardly understand why they are similar or not. Therefore, we propose an Attribute-guided Metric Interpreter, named AttriMeter, to semantically and quantitatively explain the results of CNN-based ReID models. The AttriMeter has a pluggable structure that can be grafted on arbitrary target models, i.e., the ReID models that need to be interpreted. With an attribute decomposition head, it can learn to generate a group of attribute-guided attention maps (AAMs) from the target model. By applying AAMs to features of two persons from the target model, their distance will be decomposed into a set of attribute-guided components that can measure the contributions of individual attributes. Moreover, we design a distance distillation loss to guarantee the consistency between the results from the target model and the decomposed components from AttriMeter, and an attribute prior loss to eliminate the biases caused by the unbalanced distribution of attributes. Finally, extensive experiments and analysis on a variety of ReID models and datasets show the effectiveness of AttriMeter.
Overcoming Language Priors with Self-supervised Learning for Visual Question Answering
Dec 17, 2020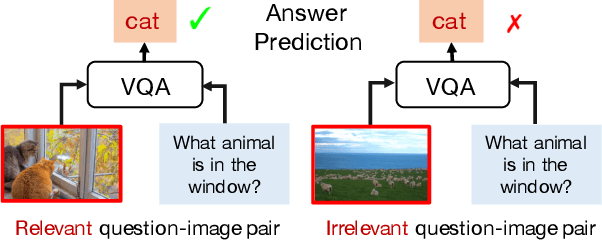
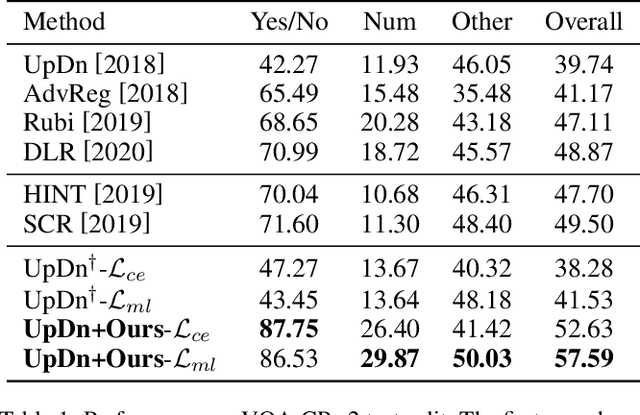
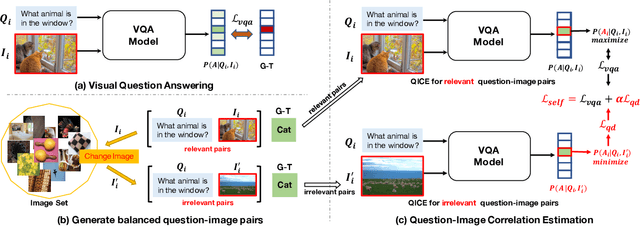
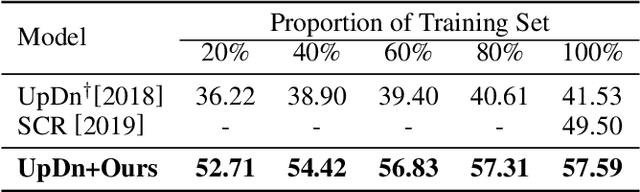
Most Visual Question Answering (VQA) models suffer from the language prior problem, which is caused by inherent data biases. Specifically, VQA models tend to answer questions (e.g., what color is the banana?) based on the high-frequency answers (e.g., yellow) ignoring image contents. Existing approaches tackle this problem by creating delicate models or introducing additional visual annotations to reduce question dependency while strengthening image dependency. However, they are still subject to the language prior problem since the data biases have not been even alleviated. In this paper, we introduce a self-supervised learning framework to solve this problem. Concretely, we first automatically generate labeled data to balance the biased data, and propose a self-supervised auxiliary task to utilize the balanced data to assist the base VQA model to overcome language priors. Our method can compensate for the data biases by generating balanced data without introducing external annotations. Experimental results show that our method can significantly outperform the state-of-the-art, improving the overall accuracy from 49.50% to 57.59% on the most commonly used benchmark VQA-CP v2. In other words, we can increase the performance of annotation-based methods by 16% without using external annotations.
CatGCN: Graph Convolutional Networks with Categorical Node Features
Sep 17, 2020
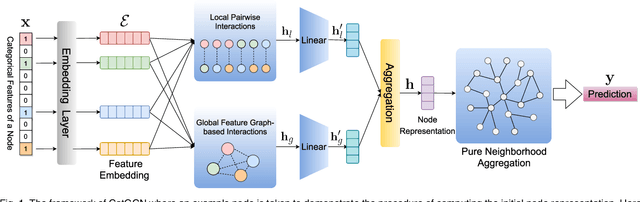
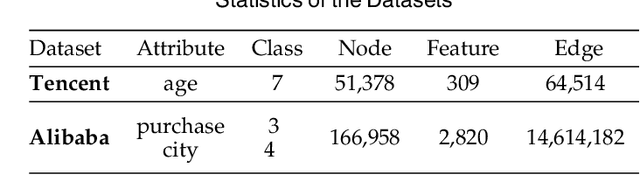
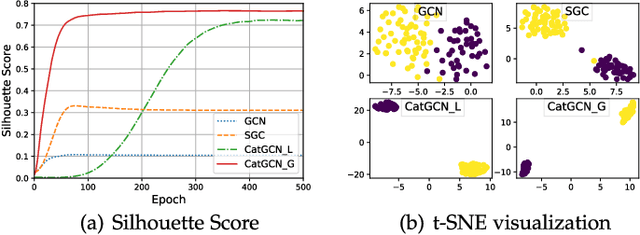
Recent studies on Graph Convolutional Networks (GCNs) reveal that the initial node representations (i.e., the node representations before the first-time graph convolution) largely affect the final model performance. However, when learning the initial representation for a node, most existing work linearly combines the embeddings of node features, without considering the interactions among the features (or feature embeddings). We argue that when the node features are categorical, e.g., in many real-world applications like user profiling and recommender system, feature interactions usually carry important signals for predictive analytics. Ignoring them will result in suboptimal initial node representation and thus weaken the effectiveness of the follow-up graph convolution. In this paper, we propose a new GCN model named CatGCN, which is tailored for graph learning when the node features are categorical. Specifically, we integrate two ways of explicit interaction modeling into the learning of initial node representation, i.e., local interaction modeling on each pair of node features and global interaction modeling on an artificial feature graph. We then refine the enhanced initial node representations with the neighborhood aggregation-based graph convolution. We train CatGCN in an end-to-end fashion and demonstrate it on semi-supervised node classification. Extensive experiments on three tasks of user profiling (the prediction of user age, city, and purchase level) from Tencent and Alibaba datasets validate the effectiveness of CatGCN, especially the positive effect of performing feature interaction modeling before graph convolution.
Depth image denoising using nuclear norm and learning graph model
Aug 09, 2020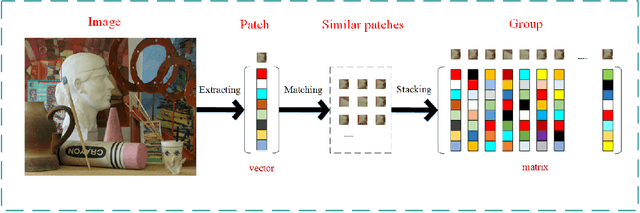
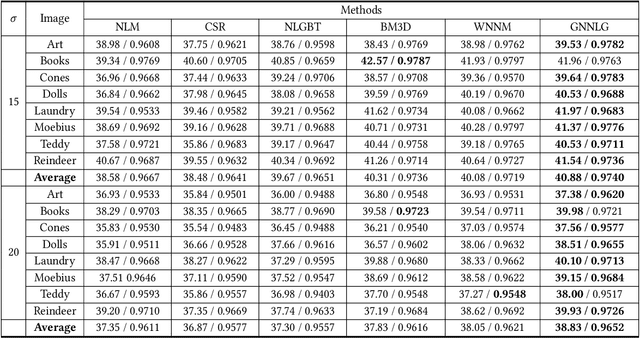
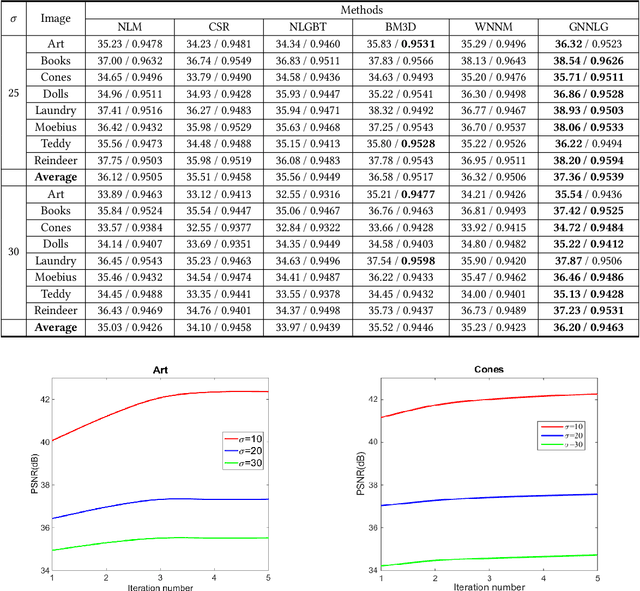
The depth images denoising are increasingly becoming the hot research topic nowadays because they reflect the three-dimensional (3D) scene and can be applied in various fields of computer vision. But the depth images obtained from depth camera usually contain stains such as noise, which greatly impairs the performance of depth related applications. In this paper, considering that group-based image restoration methods are more effective in gathering the similarity among patches, a group based nuclear norm and learning graph (GNNLG) model was proposed. For each patch, we find and group the most similar patches within a searching window. The intrinsic low-rank property of the grouped patches is exploited in our model. In addition, we studied the manifold learning method and devised an effective optimized learning strategy to obtain the graph Laplacian matrix, which reflects the topological structure of image, to further impose the smoothing priors to the denoised depth image. To achieve fast speed and high convergence, the alternating direction method of multipliers (ADMM) is proposed to solve our GNNLG. The experimental results show that the proposed method is superior to other current state-of-the-art denoising methods in both subjective and objective criterion.
Attribute-Induced Bias Eliminating for Transductive Zero-Shot Learning
May 31, 2020
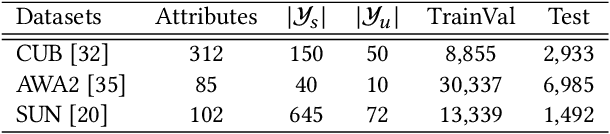
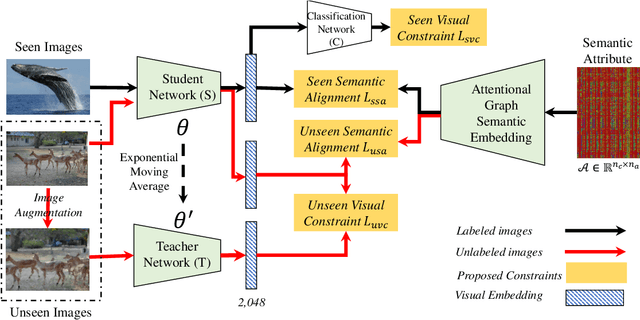
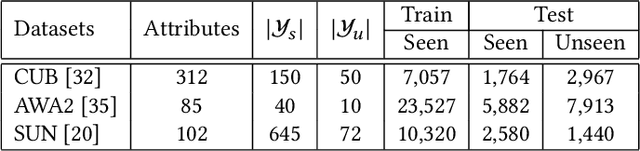
Transductive Zero-shot learning (ZSL) targets to recognize the unseen categories by aligning the visual and semantic information in a joint embedding space. There exist four kinds of domain biases in Transductive ZSL, i.e., visual bias and semantic bias between two domains and two visual-semantic biases in respective seen and unseen domains, but existing work only focuses on the part of them, which leads to severe semantic ambiguity during the knowledge transfer. To solve the above problem, we propose a novel Attribute-Induced Bias Eliminating (AIBE) module for Transductive ZSL. Specifically, for the visual bias between two domains, the Mean-Teacher module is first leveraged to bridge the visual representation discrepancy between two domains with unsupervised learning and unlabelled images. Then, an attentional graph attribute embedding is proposed to reduce the semantic bias between seen and unseen categories, which utilizes the graph operation to capture the semantic relationship between categories. Besides, to reduce the semantic-visual bias in the seen domain, we align the visual center of each category, instead of the individual visual data point, with the corresponding semantic attributes, which further preserves the semantic relationship in the embedding space. Finally, for the semantic-visual bias in the unseen domain, an unseen semantic alignment constraint is designed to align visual and semantic space in an unsupervised manner. The evaluations on several benchmarks demonstrate the effectiveness of the proposed method, e.g., obtaining the 82.8%/75.5%, 97.1%/82.5%, and 73.2%/52.1% for Conventional/Generalized ZSL settings for CUB, AwA2, and SUN datasets, respectively.