 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYinjie Lei
Improving Distant Supervised Relation Extraction by Dynamic Neural Network
Dec 13, 2019


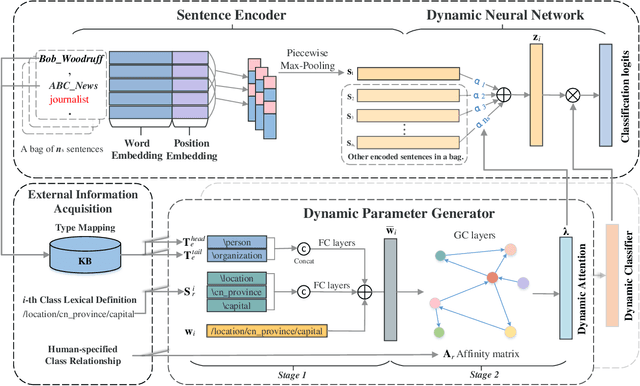
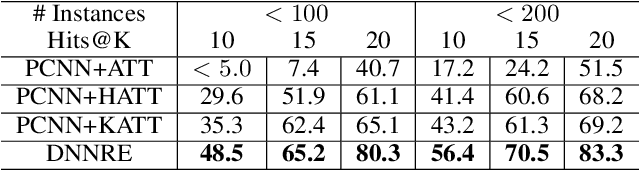
Distant Supervised Relation Extraction (DSRE) is usually formulated as a problem of classifying a bag of sentences that contain two query entities, into the predefined relation classes. Most existing methods consider those relation classes as distinct semantic categories while ignoring their potential connection to query entities. In this paper, we propose to leverage this connection to improve the relation extraction accuracy. Our key ideas are twofold: (1) For sentences belonging to the same relation class, the expression style, i.e. words choice, can vary according to the query entities. To account for this style shift, the model should adjust its parameters in accordance with entity types. (2) Some relation classes are semantically similar, and the entity types appear in one relation may also appear in others. Therefore, it can be trained cross different relation classes and further enhance those classes with few samples, i.e., long-tail classes. To unify these two arguments, we developed a novel Dynamic Neural Network for Relation Extraction (DNNRE). The network adopts a novel dynamic parameter generator that dynamically generates the network parameters according to the query entity types and relation classes. By using this mechanism, the network can simultaneously handle the style shift problem and enhance the prediction accuracy for long-tail classes. Through our experimental study, we demonstrate the effectiveness of the proposed method and show that it can achieve superior performance over the state-of-the-art methods.
DNNRE: A Dynamic Neural Network for Distant Supervised Relation Extraction
Nov 15, 2019Distant Supervised Relation Extraction (DSRE) is usually formulated as a problem of classifying a bag of sentences that contain two query entities, into the predefined relation classes. Most existing methods consider those relation classes as distinct semantic categories while ignoring their potential connections to each other and query entities. In this paper, we propose to leverage those connections to improve the relation extraction accuracy. Our key ideas are twofold: (1) For sentences belonging to the same relation class, the expression style, i.e. words choice, can vary according to the query entities. To account for this style shift, the model should adjust its parameters in accordance with entity types. (2) Some relation classes are semantically similar, and the mutual relationship of classes can be adopted to enhance the relation predictor. This is especially beneficial for those classes with few samples, i.e., long-tail classes. To unify these two ideas, we developed a novel Dynamic Neural Network for Relation Extraction (DNNRE). The network adopts a novel dynamic parameter generator which dynamically generates the network parameters according to the query entity types, relation classes, and the class similarity matrix. By using this mechanism, the network can simultaneously handle the style shift problem and leverage mutual class relationships to enhance the prediction accuracy for long-tail classes. Through our experimental study, we demonstrate the effectiveness of the proposed method and show that it can achieve superior performance over the state-of-the-art methods.
Deep Multiphase Level Set for Scene Parsing
Oct 13, 2019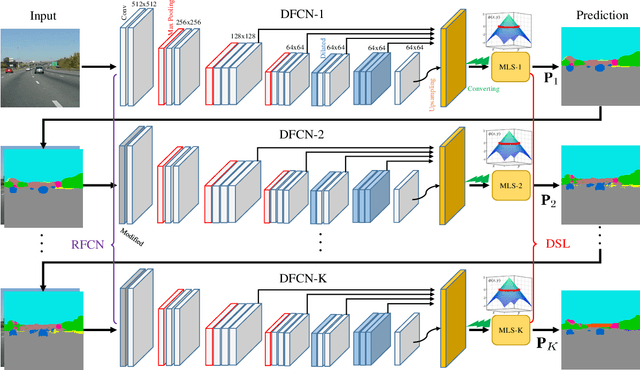
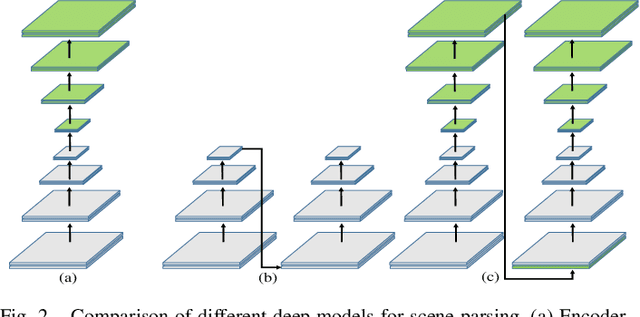
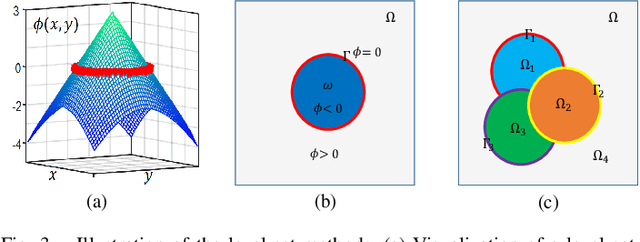
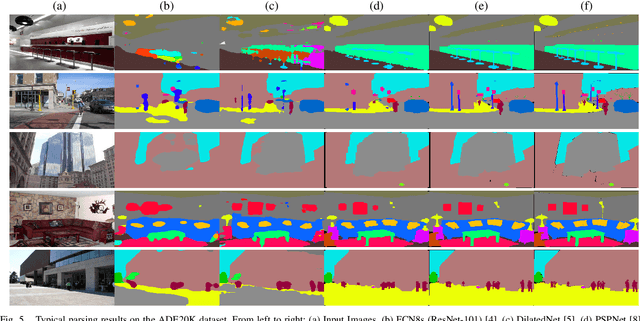
Recently, Fully Convolutional Network (FCN) seems to be the go-to architecture for image segmentation, including semantic scene parsing. However, it is difficult for a generic FCN to discriminate pixels around the object boundaries, thus FCN based methods may output parsing results with inaccurate boundaries. Meanwhile, level set based active contours are superior to the boundary estimation due to the sub-pixel accuracy that they achieve. However, they are quite sensitive to initial settings. To address these limitations, in this paper we propose a novel Deep Multiphase Level Set (DMLS) method for semantic scene parsing, which efficiently incorporates multiphase level sets into deep neural networks. The proposed method consists of three modules, i.e., recurrent FCNs, adaptive multiphase level set, and deeply supervised learning. More specifically, recurrent FCNs learn multi-level representations of input images with different contexts. Adaptive multiphase level set drives the discriminative contour for each semantic class, which makes use of the advantages of both global and local information. In each time-step of the recurrent FCNs, deeply supervised learning is incorporated for model training. Extensive experiments on three public benchmarks have shown that our proposed method achieves new state-of-the-art performances.
Cascaded Context Pyramid for Full-Resolution 3D Semantic Scene Completion
Aug 01, 2019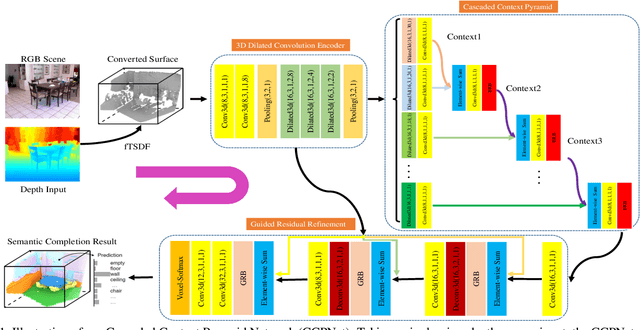
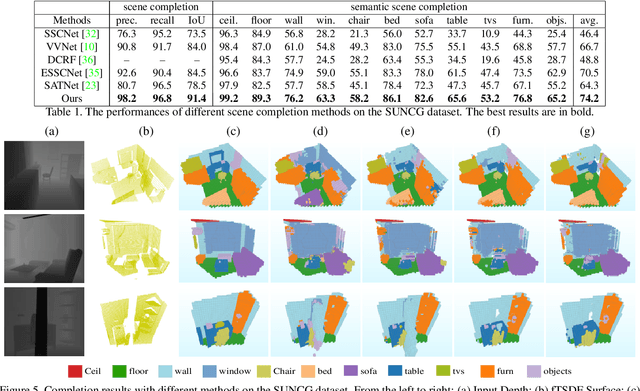
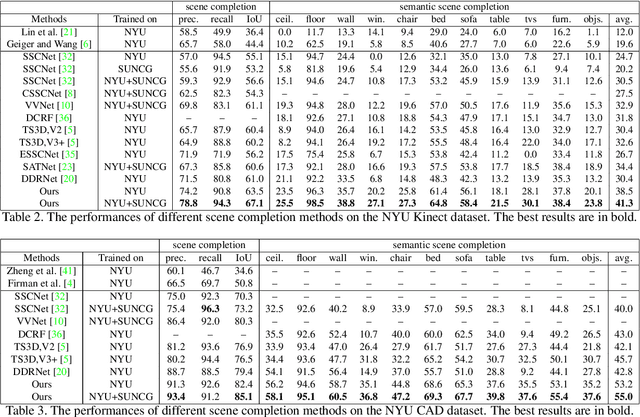
Semantic Scene Completion (SSC) aims to simultaneously predict the volumetric occupancy and semantic category of a 3D scene. It helps intelligent devices to understand and interact with the surrounding scenes. Due to the high-memory requirement, current methods only produce low-resolution completion predictions, and generally lose the object details. Furthermore, they also ignore the multi-scale spatial contexts, which play a vital role for the 3D inference. To address these issues, in this work we propose a novel deep learning framework, named Cascaded Context Pyramid Network (CCPNet), to jointly infer the occupancy and semantic labels of a volumetric 3D scene from a single depth image. The proposed CCPNet improves the labeling coherence with a cascaded context pyramid. Meanwhile, based on the low-level features, it progressively restores the fine-structures of objects with Guided Residual Refinement (GRR) modules. Our proposed framework has three outstanding advantages: (1) it explicitly models the 3D spatial context for performance improvement; (2) full-resolution 3D volumes are produced with structure-preserving details; (3) light-weight models with low-memory requirements are captured with a good extensibility. Extensive experiments demonstrate that in spite of taking a single-view depth map, our proposed framework can generate high-quality SSC results, and outperforms state-of-the-art approaches on both the synthetic SUNCG and real NYU datasets.
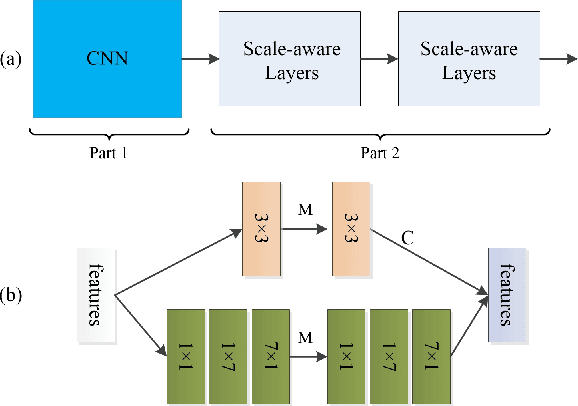
A Sketch Based 3D Shape Retrieval Approach Based on Efficient Deep Point-to-Subspace Metric Learning
Mar 13, 2019
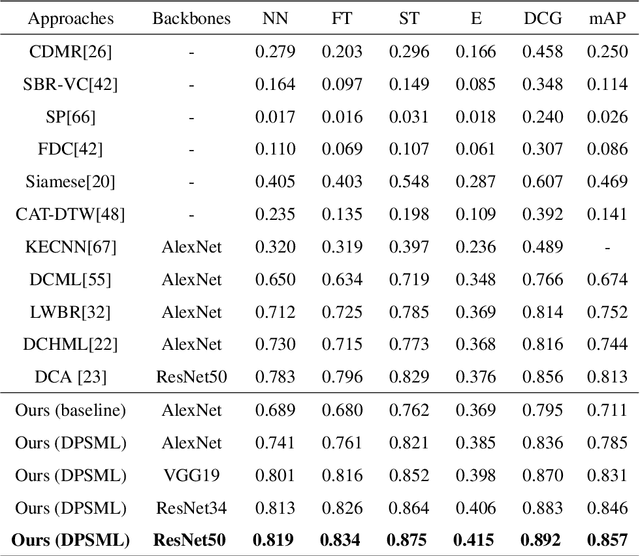
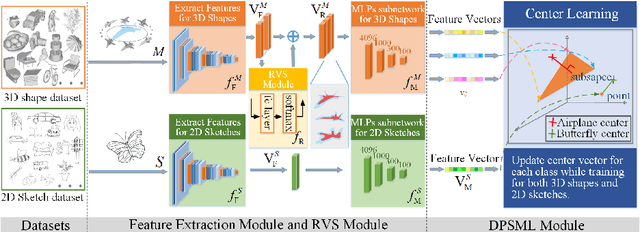
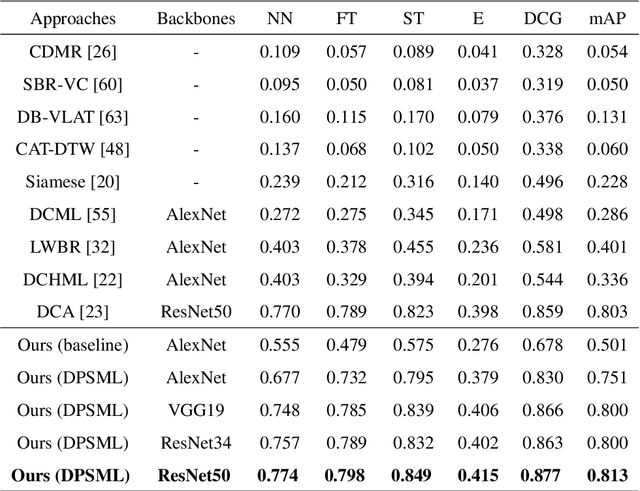
A sketch based 3D shape retrieval
Mask-aware networks for crowd counting
Dec 18, 2018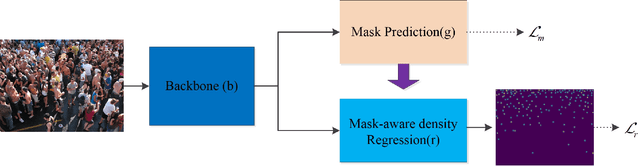
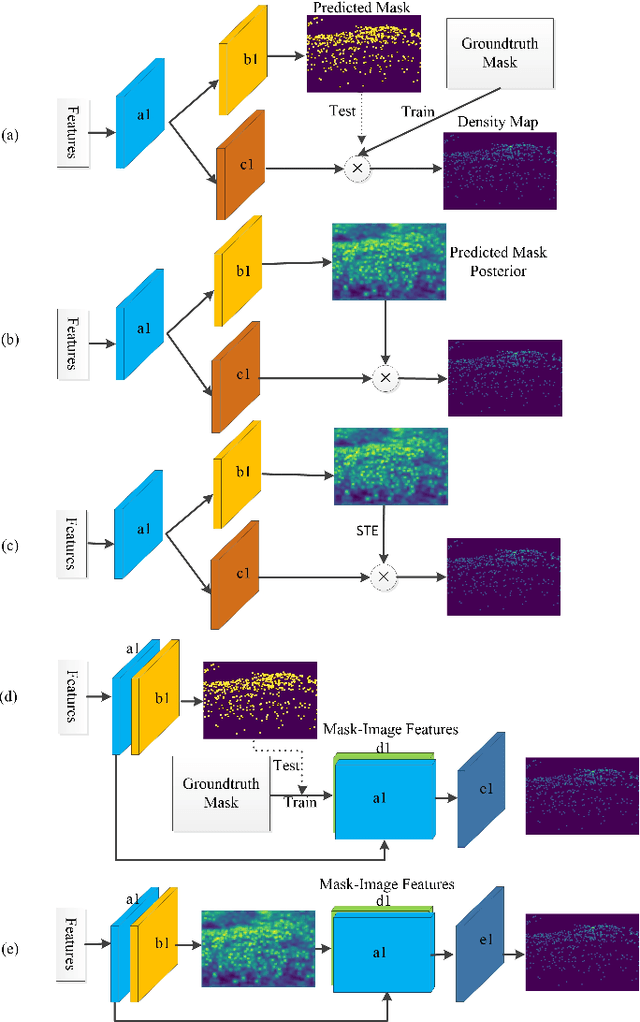

Crowd counting problem aims to count the number of objects within an image or a frame in the videos and is usually solved by estimating the density map generated from the object location annotations. The values in the density map, by nature, take two possible states: zero indicating no object around, a non-zero value indicating the existence of objects and the value denoting the local object density. In contrast to traditional methods which do not differentiate the density prediction of these two states, we propose to use a dedicated network branch to predict the object/non-object mask and then combine its prediction with the input image to produce the density map. Our rationale is that the mask prediction could be better modeled as a binary segmentation problem and the difficulty of estimating the density could be reduced if the mask is known. A key to the proposed scheme is the strategy of incorporating the mask prediction into the density map estimator. To this end, we study five possible solutions, and via analysis and experimental validation we identify the most effective one. Through extensive experiments on five public datasets, we demonstrate the superior performance of the proposed approach over the baselines and show that our network could achieve the state-of-the-art performance.