 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCasting graph isomorphism as a point set registration problem using a simplex embedding and sampling
Nov 15, 2021Graph isomorphism is an important problem as its worst-case time complexity is not yet fully understood. In this study, we try to draw parallels between a related optimization problem called point set registration. A graph can be represented as a point set in enough dimensions using a simplex embedding and sampling. Given two graphs, the isomorphism of them corresponds to the existence of a perfect registration between the point set forms of the graphs. In the case of non-isomorphism, the point set form optimization result can be used as a distance measure between two graphs having the same number of vertices and edges. The related idea of equivalence classes suggests that graph canonization may be an important tool in tackling graph isomorphism problem and an orthogonal transformation invariant feature extraction based on this high dimensional point set representation may be fruitful. The concepts presented can also be extended to automorphism, and subgraph isomorphism problems and can also be applied on hypergraphs with certain modifications.
On the Preservation of Spatio-temporal Information in Machine Learning Applications
Jun 15, 2020
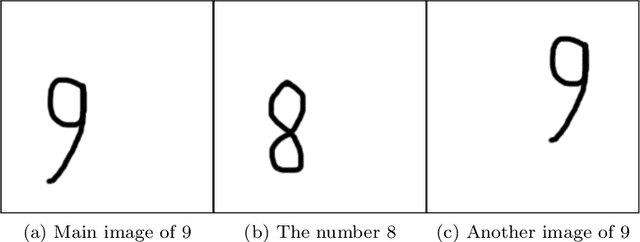
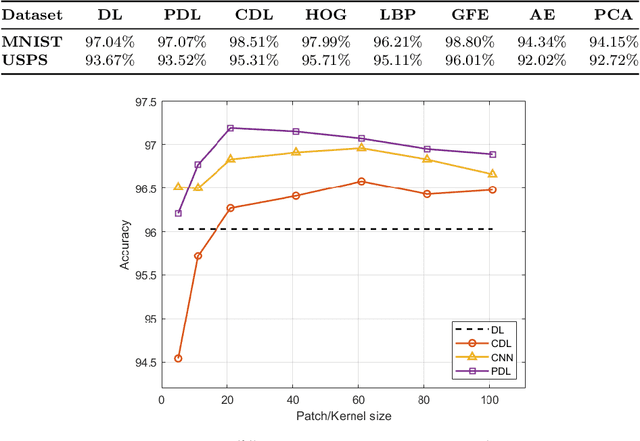
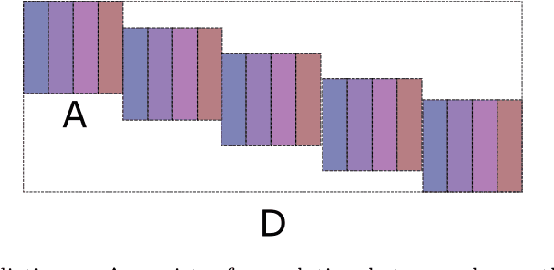
In conventional machine learning applications, each data attribute is assumed to be orthogonal to others. Namely, every pair of dimension is orthogonal to each other and thus there is no distinction of in-between relations of dimensions. However, this is certainly not the case in real world signals which naturally originate from a spatio-temporal configuration. As a result, the conventional vectorization process disrupts all of the spatio-temporal information about the order/place of data whether it be $1$D, $2$D, $3$D, or $4$D. In this paper, the problem of orthogonality is first investigated through conventional $k$-means of images, where images are to be processed as vectors. As a solution, shift-invariant $k$-means is proposed in a novel framework with the help of sparse representations. A generalization of shift-invariant $k$-means, convolutional dictionary learning, is then utilized as an unsupervised feature extraction method for classification. Experiments suggest that Gabor feature extraction as a simulation of shallow convolutional neural networks provides a little better performance compared to convolutional dictionary learning. Many alternatives of convolutional-logic are also discussed for spatio-temporal information preservation, including a spatio-temporal hypercomplex encoding scheme.
Evolutionary Simplicial Learning as a Generative and Compact Sparse Framework for Classification
May 14, 2020

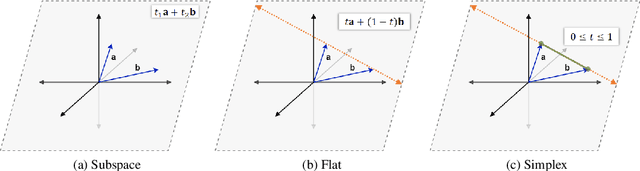
Dictionary learning for sparse representations has been successful in many reconstruction tasks. Simplicial learning is an adaptation of dictionary learning, where subspaces become clipped and acquire arbitrary offsets, taking the form of simplices. Such adaptation is achieved through additional constraints on sparse codes. Furthermore, an evolutionary approach can be chosen to determine the number and the dimensionality of simplices composing the simplicial, in which most generative and compact simplicials are favored. This paper proposes an evolutionary simplicial learning method as a generative and compact sparse framework for classification. The proposed approach is first applied on a one-class classification task and it appears as the most reliable method within the considered benchmark. Most surprising results are observed when evolutionary simplicial learning is considered within a multi-class classification task. Since sparse representations are generative in nature, they bear a fundamental problem of not being capable of distinguishing two classes lying on the same subspace. This claim is validated through synthetic experiments and superiority of simplicial learning even as a generative-only approach is demonstrated. Simplicial learning loses its superiority over discriminative methods in high-dimensional cases but can further be modified with discriminative elements to achieve state-of-the-art performance in classification tasks.
The Mimicry Game: Towards Self-recognition in Chatbots
Feb 06, 2020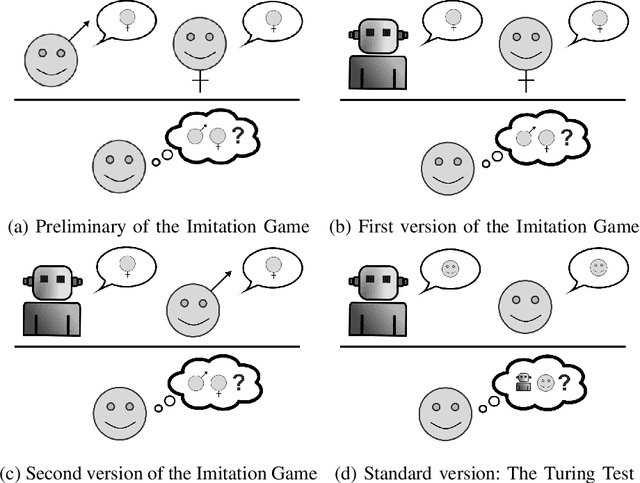
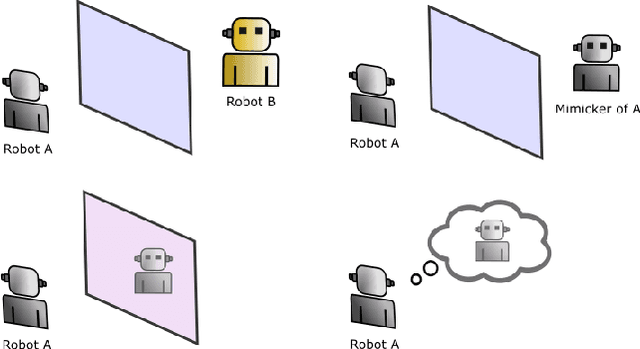
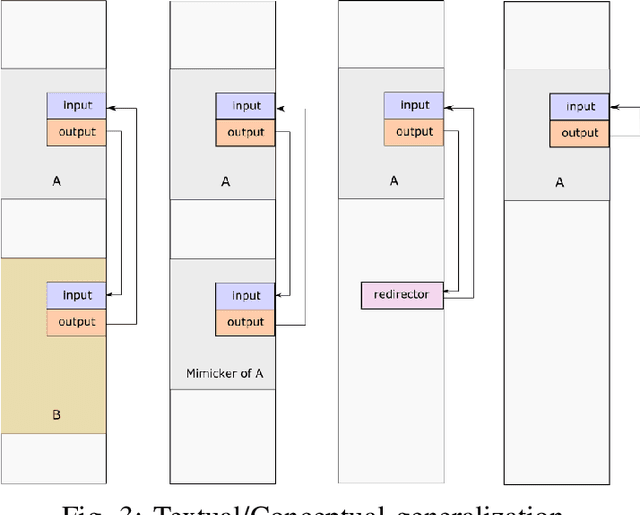

In standard Turing test, a machine has to prove its humanness to the judges. By successfully imitating a thinking entity such as a human, this machine then proves that it can also think. However, many objections are raised against the validity of this argument. Such objections claim that Turing test is not a tool to demonstrate existence of general intelligence or thinking activity. In this light, alternatives to Turing test are to be investigated. Self-recognition tests applied on animals through mirrors appear to be a viable alternative to demonstrate the existence of a type of general intelligence. Methodology here constructs a textual version of the mirror test by placing the chatbot (in this context) as the one and only judge to figure out whether the contacted one is an other, a mimicker, or oneself in an unsupervised manner. This textual version of the mirror test is objective, self-contained, and is mostly immune to objections raised against the Turing test. Any chatbot passing this textual mirror test should have or acquire a thought mechanism that can be referred to as the inner-voice, answering the original and long lasting question of Turing "Can machines think?" in a constructive manner.
Convolutional Neural Networks: A Binocular Vision Perspective
Dec 21, 2019
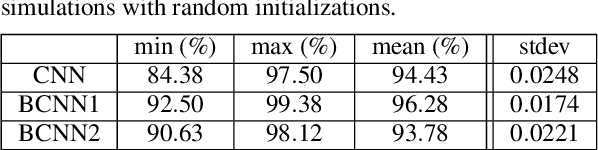
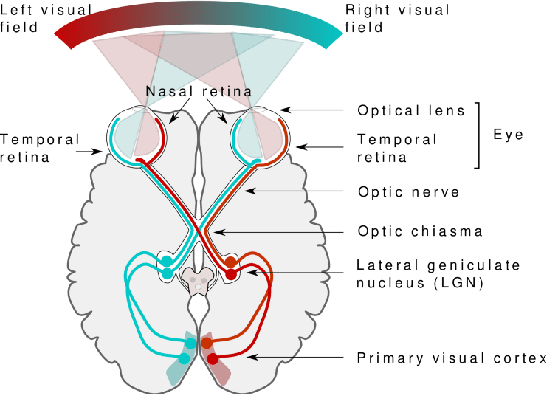

It is arguable that whether the single camera captured (monocular) image datasets are sufficient enough to train and test convolutional neural networks (CNNs) for imitating the biological neural network structures of the human brain. As human visual system works in binocular, the collaboration of the eyes with the two brain lobes needs more investigation for improvements in such CNN-based visual imagery analysis applications. It is indeed questionable that if respective visual fields of each eye and the associated brain lobes are responsible for different learning abilities of the same scene. There are such open questions in this field of research which need rigorous investigation in order to further understand the nature of the human visual system, hence improve the currently available deep learning applications. This position paper analyses a binocular CNNs architecture that is more analogous to the biological structure of the human visual system than the conventional deep learning techniques. While taking a structure called optic chiasma into account, this architecture consists of basically two parallel CNN structures associated with each visual field and the brain lobe, fully connected later possibly as in the primary visual cortex (V1). Experimental results demonstrate that binocular learning of two different visual fields leads to better classification rates on average, when compared to classical CNN architectures.
Boosting Dictionary Learning with Error Codes
Jan 15, 2017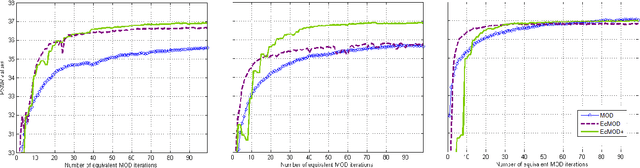
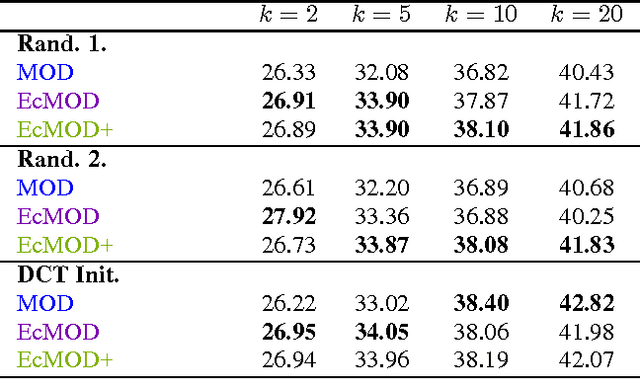
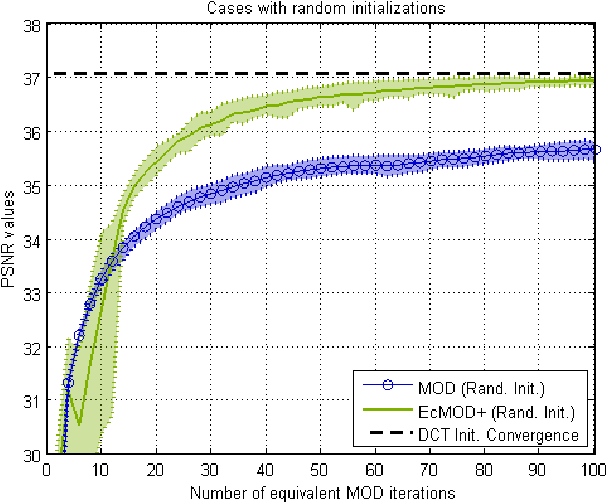
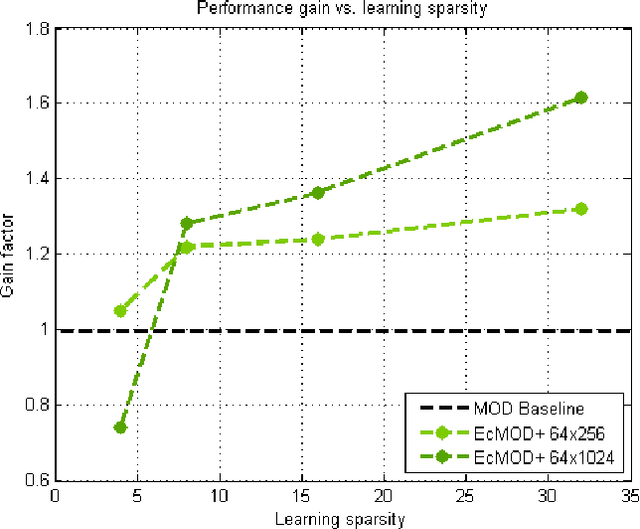
In conventional sparse representations based dictionary learning algorithms, initial dictionaries are generally assumed to be proper representatives of the system at hand. However, this may not be the case, especially in some systems restricted to random initializations. Therefore, a supposedly optimal state-update based on such an improper model might lead to undesired effects that will be conveyed to successive iterations. In this paper, we propose a dictionary learning method which includes a general feedback process that codes the intermediate error left over from a less intensive initial learning attempt, and then adjusts sparse codes accordingly. Experimental observations show that such an additional step vastly improves rates of convergence in high-dimensional cases, also results in better converged states in the case of random initializations. Improvements also scale up with more lenient sparsity constraints.
Depth Estimation from Single Image using Sparse Representations
Jun 27, 2016Monocular depth estimation is an interesting and challenging problem as there is no analytic mapping known between an intensity image and its depth map. Recently there has been a lot of data accumulated through depth-sensing cameras, in parallel to that researchers started to tackle this task using various learning algorithms. In this paper, a deep sparse coding method is proposed for monocular depth estimation along with an approach for deterministic dictionary initialization.