 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Multilingual Amazon Reviews Corpus
Oct 06, 2020
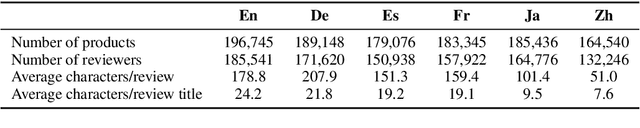
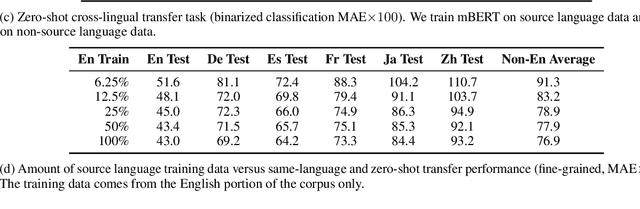
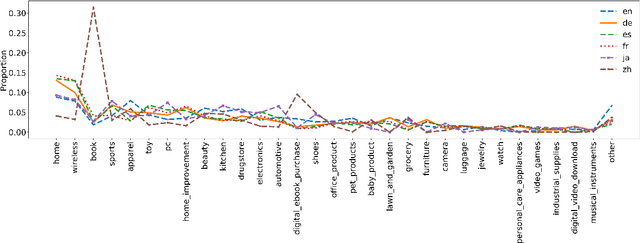
We present the Multilingual Amazon Reviews Corpus (MARC), a large-scale collection of Amazon reviews for multilingual text classification. The corpus contains reviews in English, Japanese, German, French, Spanish, and Chinese, which were collected between 2015 and 2019. Each record in the dataset contains the review text, the review title, the star rating, an anonymized reviewer ID, an anonymized product ID, and the coarse-grained product category (e.g., 'books', 'appliances', etc.) The corpus is balanced across the 5 possible star ratings, so each rating constitutes 20% of the reviews in each language. For each language, there are 200,000, 5,000, and 5,000 reviews in the training, development, and test sets, respectively. We report baseline results for supervised text classification and zero-shot cross-lingual transfer learning by fine-tuning a multilingual BERT model on reviews data. We propose the use of mean absolute error (MAE) instead of classification accuracy for this task, since MAE accounts for the ordinal nature of the ratings.
On the Evaluation of Contextual Embeddings for Zero-Shot Cross-Lingual Transfer Learning
Apr 30, 2020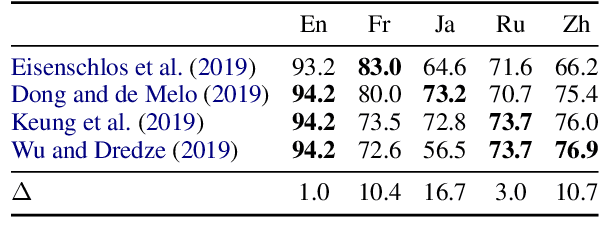
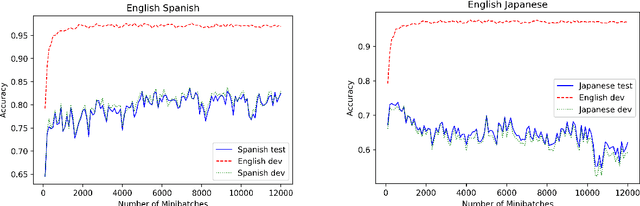
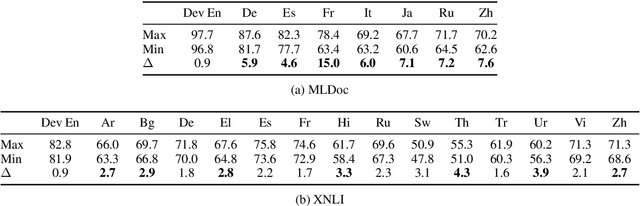
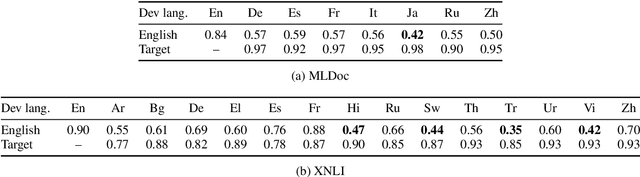
Pre-trained multilingual contextual embeddings have demonstrated state-of-the-art performance in zero-shot cross-lingual transfer learning, where multilingual BERT is fine-tuned on some source language (typically English) and evaluated on a different target language. However, published results for baseline mBERT zero-shot accuracy vary as much as 17 points on the MLDoc classification task across four papers. We show that the standard practice of using English dev accuracy for model selection in the zero-shot setting makes it difficult to obtain reproducible results on the MLDoc and XNLI tasks. English dev accuracy is often uncorrelated (or even anti-correlated) with target language accuracy, and zero-shot cross-lingual performance varies greatly within the same fine-tuning run and between different fine-tuning runs. We recommend providing oracle scores alongside the zero-shot results: still fine-tune using English, but choose a checkpoint with the target dev set. Reporting this upper bound makes results more consistent by avoiding the variation from bad checkpoints.
Attentional Speech Recognition Models Misbehave on Out-of-domain Utterances
Feb 12, 2020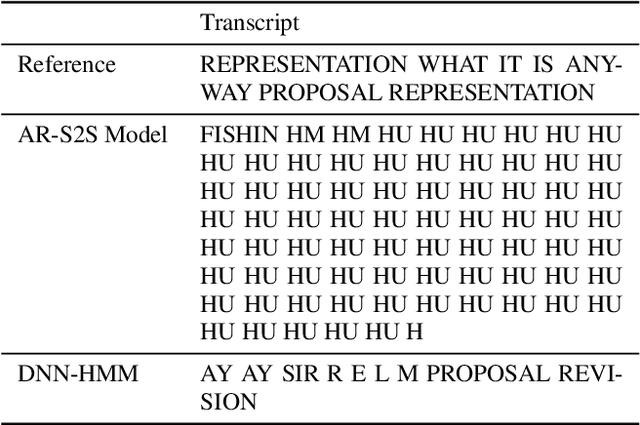
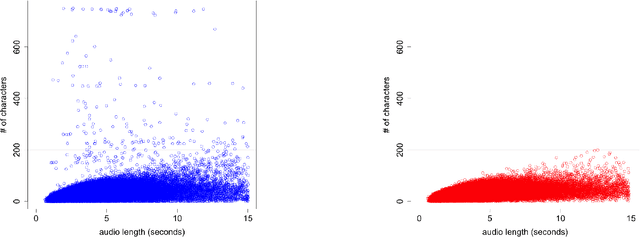
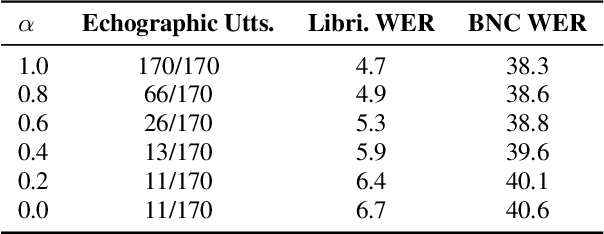
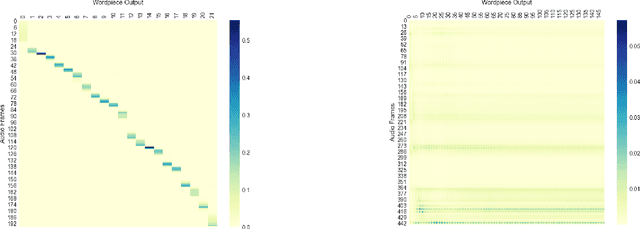
We discuss the problem of echographic transcription in autoregressive sequence-to-sequence attentional architectures for automatic speech recognition, where a model produces very long sequences of repetitive outputs when presented with out-of-domain utterances. We decode audio from the British National Corpus with an attentional encoder-decoder model trained solely on the LibriSpeech corpus. We observe that there are many 5-second recordings that produce more than 500 characters of decoding output (i.e. more than 100 characters per second). A frame-synchronous hybrid (DNN-HMM) model trained on the same data does not produce these unusually long transcripts. These decoding issues are reproducible in a speech transformer model from ESPnet, and to a lesser extent in a self-attention CTC model, suggesting that these issues are intrinsic to the use of the attention mechanism. We create a separate length prediction model to predict the correct number of wordpieces in the output, which allows us to identify and truncate problematic decoding results without increasing word error rates on the LibriSpeech task.
Learning Effective Visual Relationship Detector on 1 GPU
Dec 12, 2019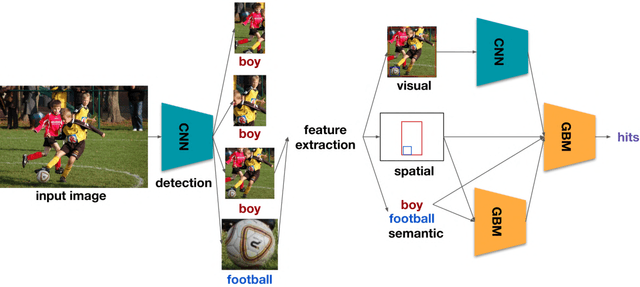
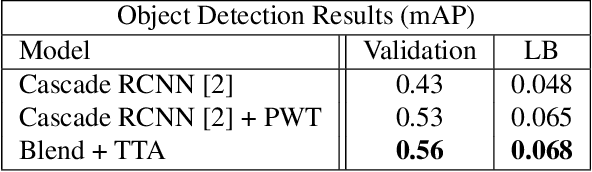
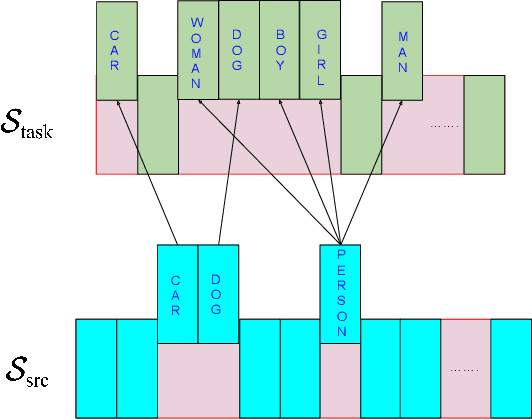
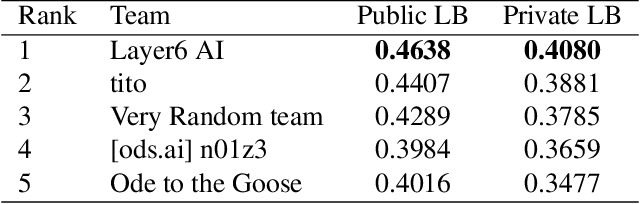
We present our winning solution to the Open Images 2019 Visual Relationship challenge. This is the largest challenge of its kind to date with nearly 9 million training images. Challenge task consists of detecting objects and identifying relationships between them in complex scenes. Our solution has three stages, first object detection model is fine-tuned for the challenge classes using a novel weight transfer approach. Then, spatio-semantic and visual relationship models are trained on candidate object pairs. Finally, features and model predictions are combined to generate the final relationship prediction. Throughout the challenge we focused on minimizing the hardware requirements of our architecture. Specifically, our weight transfer approach enables much faster optimization, allowing the entire architecture to be trained on a single GPU in under two days. In addition to efficient optimization, our approach also achieves superior accuracy winning first place out of over 200 teams, and outperforming the second place team by over $5\%$ on the held-out private leaderboard.
CrevNet: Conditionally Reversible Video Prediction
Oct 25, 2019

Applying resolution-preserving blocks is a common practice to maximize information preservation in video prediction, yet their high memory consumption greatly limits their application scenarios. We propose CrevNet, a Conditionally Reversible Network that uses reversible architectures to build a bijective two-way autoencoder and its complementary recurrent predictor. Our model enjoys the theoretically guaranteed property of no information loss during the feature extraction, much lower memory consumption and computational efficiency.
Adversarial Learning with Contextual Embeddings for Zero-resource Cross-lingual Classification and NER
Sep 13, 2019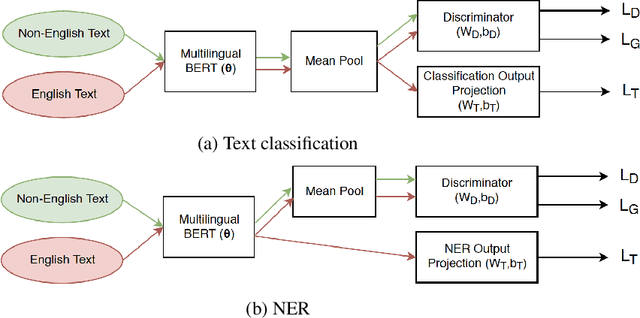
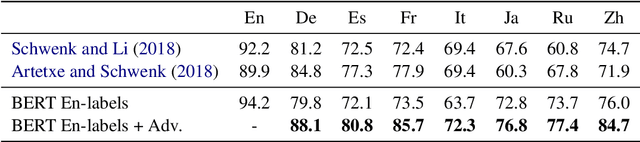
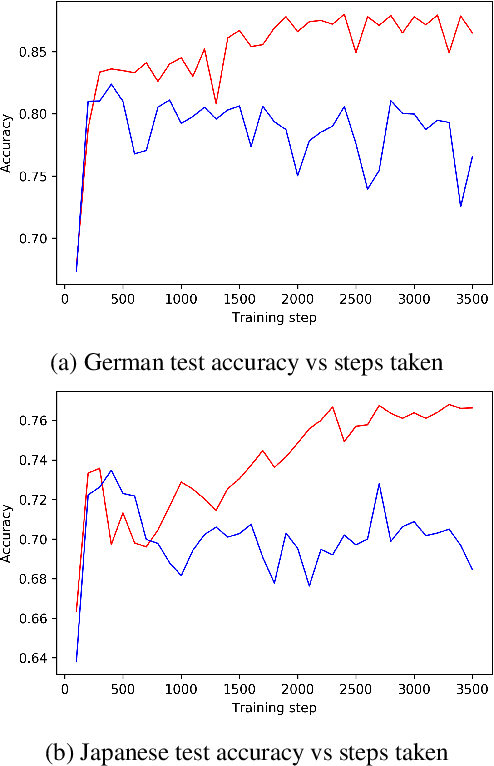
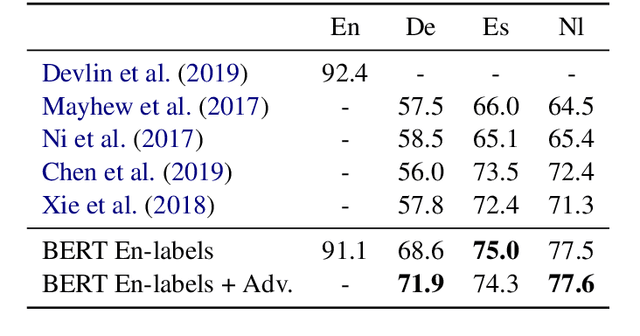
Contextual word embeddings (e.g. GPT, BERT, ELMo, etc.) have demonstrated state-of-the-art performance on various NLP tasks. Recent work with the multilingual version of BERT has shown that the model performs very well in cross-lingual settings, even when only labeled English data is used to finetune the model. We improve upon multilingual BERT's zero-resource cross-lingual performance via adversarial learning. We report the magnitude of the improvement on the multilingual MLDoc text classification and CoNLL 2002/2003 named entity recognition tasks. Furthermore, we show that language-adversarial training encourages BERT to align the embeddings of English documents and their translations, which may be the cause of the observed performance gains.
A neural interlingua for multilingual machine translation
Oct 16, 2018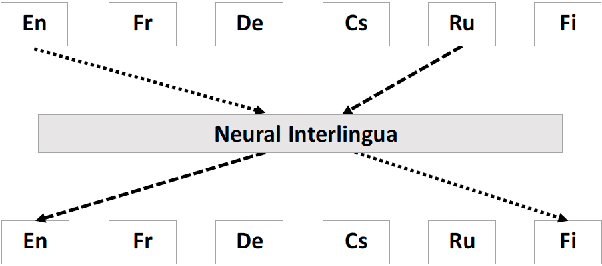
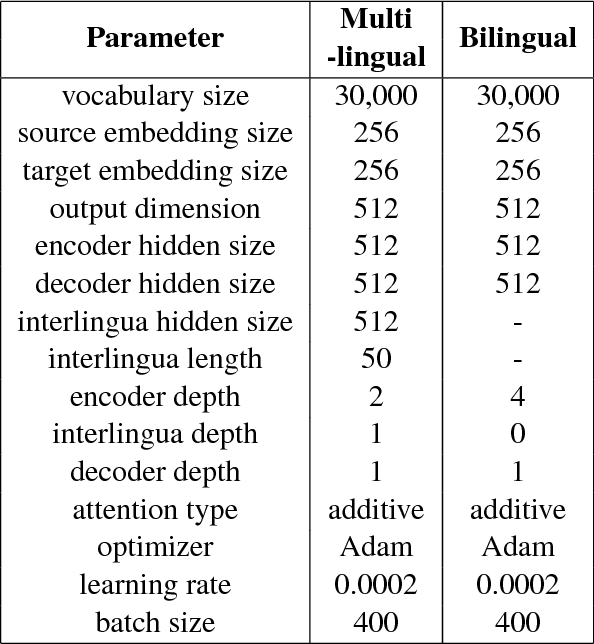
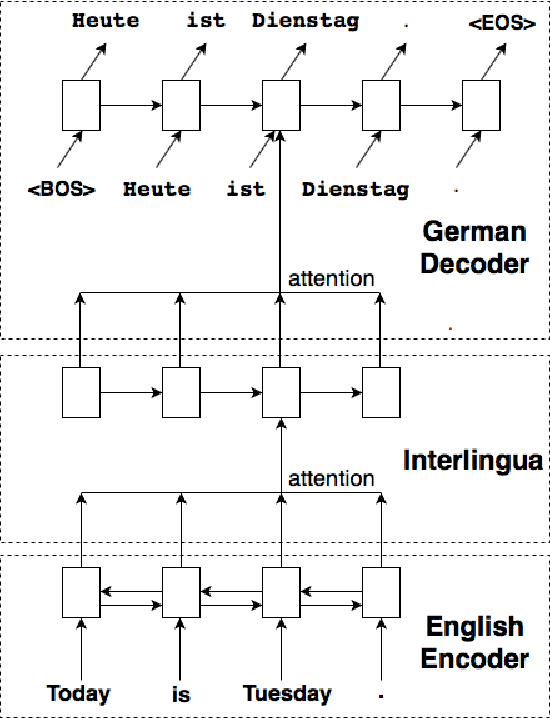
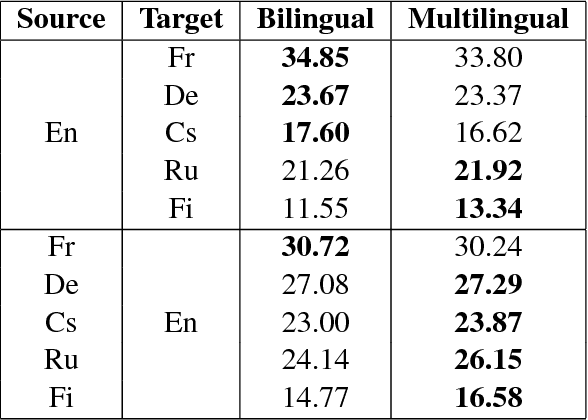
We incorporate an explicit neural interlingua into a multilingual encoder-decoder neural machine translation (NMT) architecture. We demonstrate that our model learns a language-independent representation by performing direct zero-shot translation (without using pivot translation), and by using the source sentence embeddings to create an English Yelp review classifier that, through the mediation of the neural interlingua, can also classify French and German reviews. Furthermore, we show that, despite using a smaller number of parameters than a pairwise collection of bilingual NMT models, our approach produces comparable BLEU scores for each language pair in WMT15.
A practical approach to dialogue response generation in closed domains
Mar 28, 2017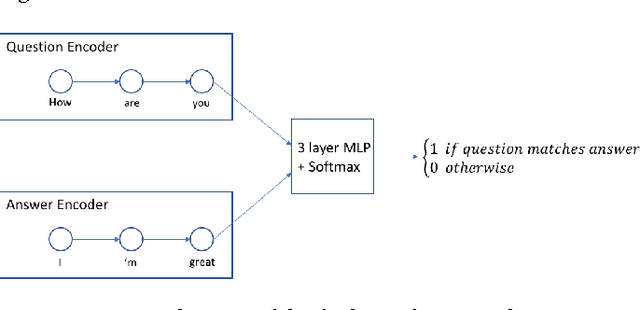


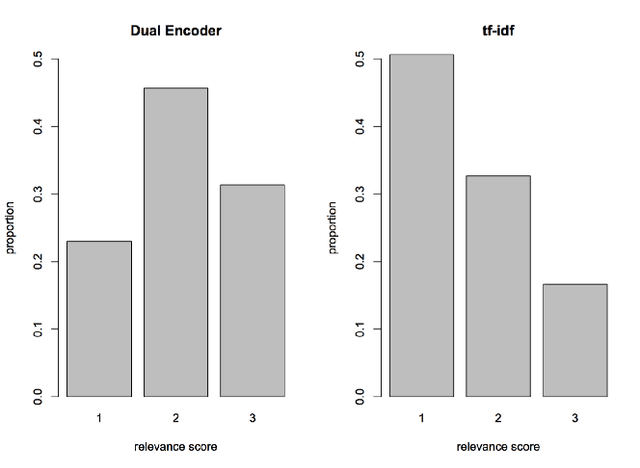
We describe a prototype dialogue response generation model for the customer service domain at Amazon. The model, which is trained in a weakly supervised fashion, measures the similarity between customer questions and agent answers using a dual encoder network, a Siamese-like neural network architecture. Answer templates are extracted from embeddings derived from past agent answers, without turn-by-turn annotations. Responses to customer inquiries are generated by selecting the best template from the final set of templates. We show that, in a closed domain like customer service, the selected templates cover $>$70\% of past customer inquiries. Furthermore, the relevance of the model-selected templates is significantly higher than templates selected by a standard tf-idf baseline.
Finding Linear Structure in Large Datasets with Scalable Canonical Correlation Analysis
Jun 26, 2015
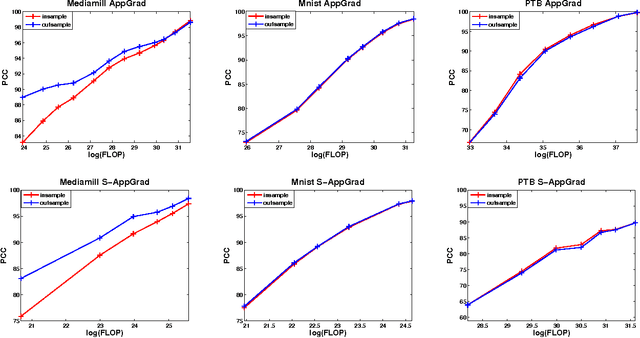
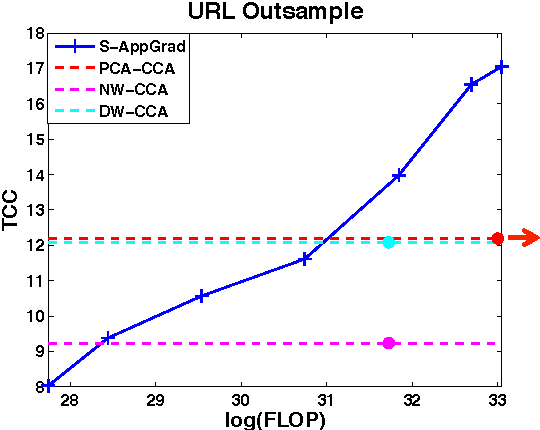
Canonical Correlation Analysis (CCA) is a widely used spectral technique for finding correlation structures in multi-view datasets. In this paper, we tackle the problem of large scale CCA, where classical algorithms, usually requiring computing the product of two huge matrices and huge matrix decomposition, are computationally and storage expensive. We recast CCA from a novel perspective and propose a scalable and memory efficient Augmented Approximate Gradient (AppGrad) scheme for finding top $k$ dimensional canonical subspace which only involves large matrix multiplying a thin matrix of width $k$ and small matrix decomposition of dimension $k\times k$. Further, AppGrad achieves optimal storage complexity $O(k(p_1+p_2))$, compared with classical algorithms which usually require $O(p_1^2+p_2^2)$ space to store two dense whitening matrices. The proposed scheme naturally generalizes to stochastic optimization regime, especially efficient for huge datasets where batch algorithms are prohibitive. The online property of stochastic AppGrad is also well suited to the streaming scenario, where data comes sequentially. To the best of our knowledge, it is the first stochastic algorithm for CCA. Experiments on four real data sets are provided to show the effectiveness of the proposed methods.
Large scale canonical correlation analysis with iterative least squares
Dec 30, 2014
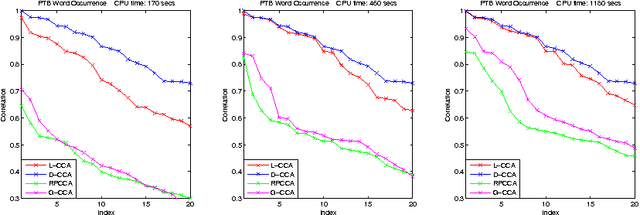
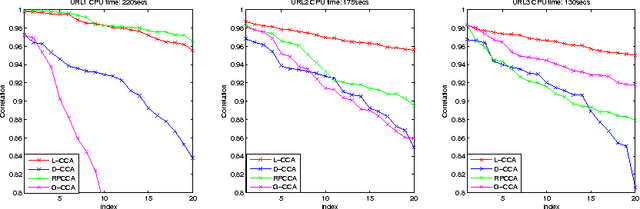
Canonical Correlation Analysis (CCA) is a widely used statistical tool with both well established theory and favorable performance for a wide range of machine learning problems. However, computing CCA for huge datasets can be very slow since it involves implementing QR decomposition or singular value decomposition of huge matrices. In this paper we introduce L-CCA, a iterative algorithm which can compute CCA fast on huge sparse datasets. Theory on both the asymptotic convergence and finite time accuracy of L-CCA are established. The experiments also show that L-CCA outperform other fast CCA approximation schemes on two real datasets.