 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYi Yang
Action Keypoint Network for Efficient Video Recognition
Jan 17, 2022

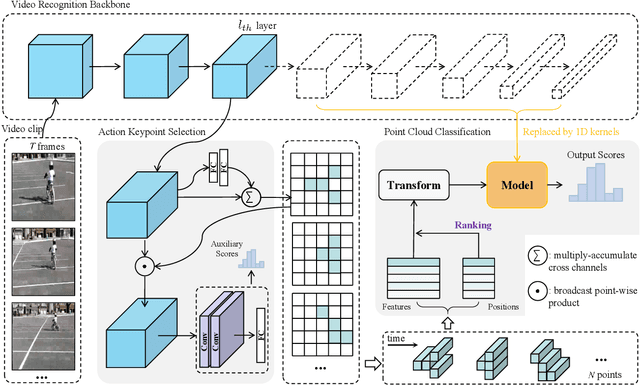
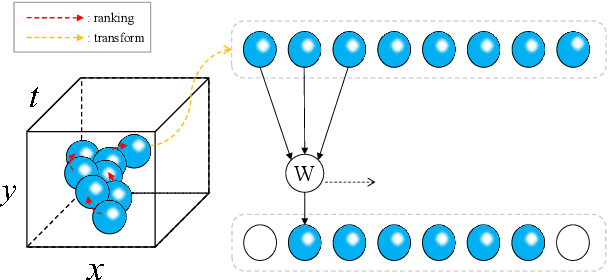
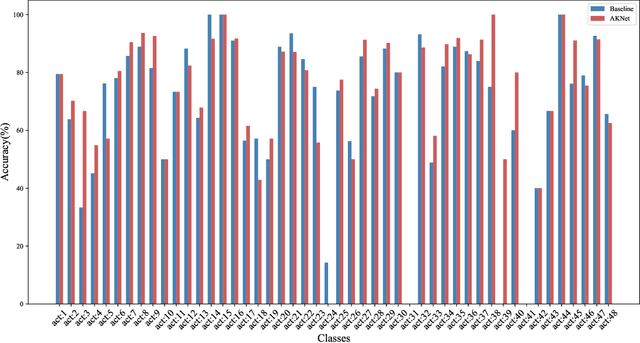
Reducing redundancy is crucial for improving the efficiency of video recognition models. An effective approach is to select informative content from the holistic video, yielding a popular family of dynamic video recognition methods. However, existing dynamic methods focus on either temporal or spatial selection independently while neglecting a reality that the redundancies are usually spatial and temporal, simultaneously. Moreover, their selected content is usually cropped with fixed shapes, while the realistic distribution of informative content can be much more diverse. With these two insights, this paper proposes to integrate temporal and spatial selection into an Action Keypoint Network (AK-Net). From different frames and positions, AK-Net selects some informative points scattered in arbitrary-shaped regions as a set of action keypoints and then transforms the video recognition into point cloud classification. AK-Net has two steps, i.e., the keypoint selection and the point cloud classification. First, it inputs the video into a baseline network and outputs a feature map from an intermediate layer. We view each pixel on this feature map as a spatial-temporal point and select some informative keypoints using self-attention. Second, AK-Net devises a ranking criterion to arrange the keypoints into an ordered 1D sequence. Consequentially, AK-Net brings two-fold benefits for efficiency: The keypoint selection step collects informative content within arbitrary shapes and increases the efficiency for modeling spatial-temporal dependencies, while the point cloud classification step further reduces the computational cost by compacting the convolutional kernels. Experimental results show that AK-Net can consistently improve the efficiency and performance of baseline methods on several video recognition benchmarks.
Boosting RGB-D Saliency Detection by Leveraging Unlabeled RGB Images
Jan 01, 2022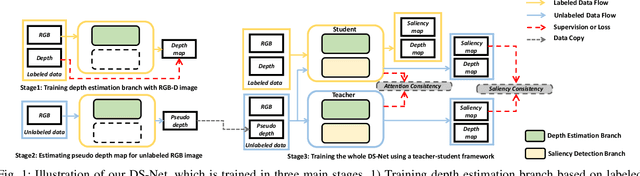
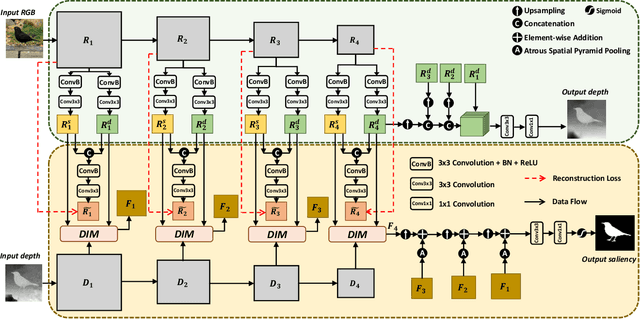
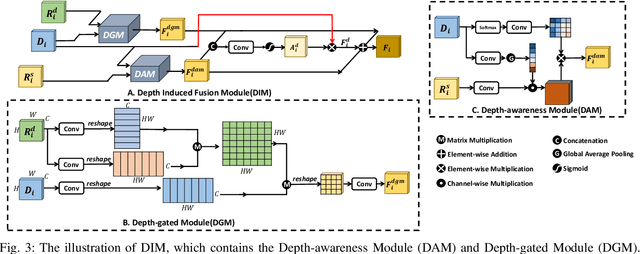

Training deep models for RGB-D salient object detection (SOD) often requires a large number of labeled RGB-D images. However, RGB-D data is not easily acquired, which limits the development of RGB-D SOD techniques. To alleviate this issue, we present a Dual-Semi RGB-D Salient Object Detection Network (DS-Net) to leverage unlabeled RGB images for boosting RGB-D saliency detection. We first devise a depth decoupling convolutional neural network (DDCNN), which contains a depth estimation branch and a saliency detection branch. The depth estimation branch is trained with RGB-D images and then used to estimate the pseudo depth maps for all unlabeled RGB images to form the paired data. The saliency detection branch is used to fuse the RGB feature and depth feature to predict the RGB-D saliency. Then, the whole DDCNN is assigned as the backbone in a teacher-student framework for semi-supervised learning. Moreover, we also introduce a consistency loss on the intermediate attention and saliency maps for the unlabeled data, as well as a supervised depth and saliency loss for labeled data. Experimental results on seven widely-used benchmark datasets demonstrate that our DDCNN outperforms state-of-the-art methods both quantitatively and qualitatively. We also demonstrate that our semi-supervised DS-Net can further improve the performance, even when using an RGB image with the pseudo depth map.
D$^2$LV: A Data-Driven and Local-Verification Approach for Image Copy Detection
Dec 04, 2021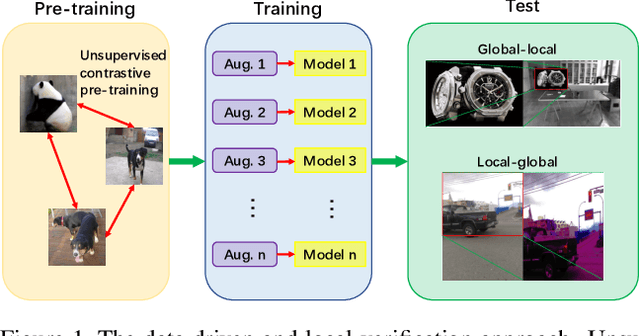
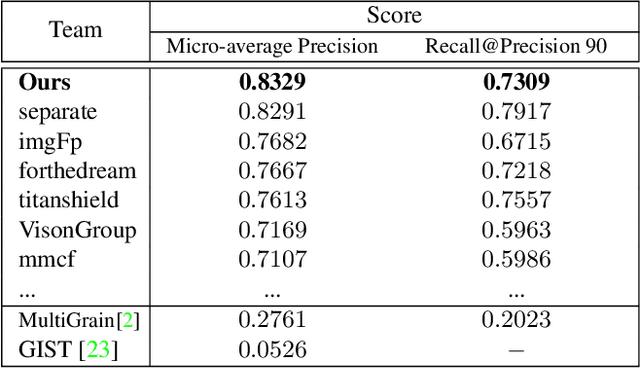
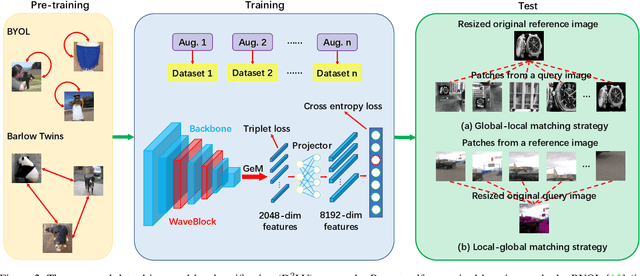
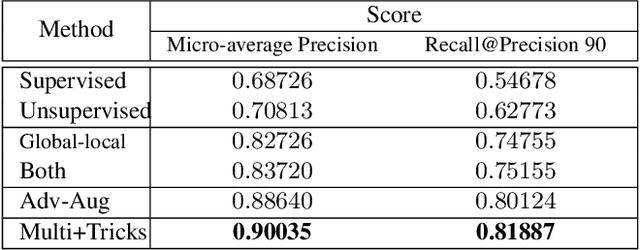
Image copy detection is of great importance in real-life social media. In this paper, a data-driven and local-verification (D$^2$LV) approach is proposed to compete for Image Similarity Challenge: Matching Track at NeurIPS'21. In D$^2$LV, unsupervised pre-training substitutes the commonly-used supervised one. When training, we design a set of basic and six advanced transformations, and a simple but effective baseline learns robust representation. During testing, a global-local and local-global matching strategy is proposed. The strategy performs local-verification between reference and query images. Experiments demonstrate that the proposed method is effective. The proposed approach ranks first out of 1,103 participants on the Facebook AI Image Similarity Challenge: Matching Track. The code and trained models are available at https://github.com/WangWenhao0716/ISC-Track1-Submission.
Bag of Tricks and A Strong baseline for Image Copy Detection
Dec 04, 2021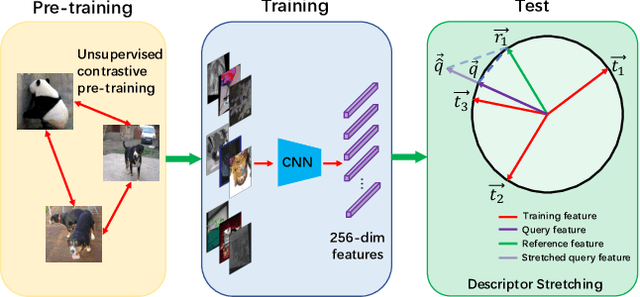
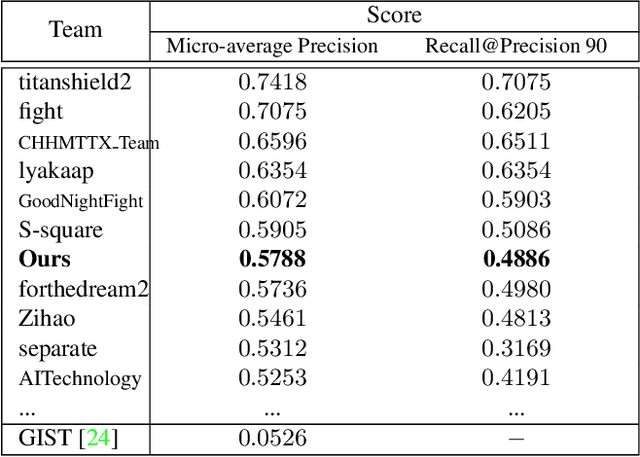
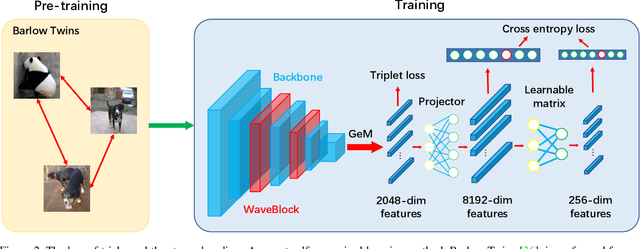
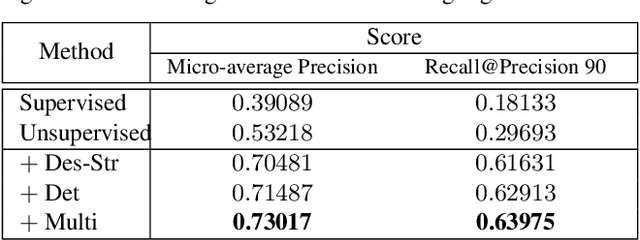
Image copy detection is of great importance in real-life social media. In this paper, a bag of tricks and a strong baseline are proposed for image copy detection. Unsupervised pre-training substitutes the commonly-used supervised one. Beyond that, we design a descriptor stretching strategy to stabilize the scores of different queries. Experiments demonstrate that the proposed method is effective. The proposed baseline ranks third out of 526 participants on the Facebook AI Image Similarity Challenge: Descriptor Track. The code and trained models are available at https://github.com/WangWenhao0716/ISC-Track2-Submission.
D^2LV: A Data-Driven and Local-Verification Approach for Image Copy Detection
Nov 13, 2021Image copy detection is of great importance in real-life social media. In this paper, a data-driven and local-verification (D^2LV) approach is proposed to compete for Image Similarity Challenge: Matching Track at NeurIPS'21. In D^2LV, unsupervised pre-training substitutes the commonly-used supervised one. When training, we design a set of basic and six advanced transformations, and a simple but effective baseline learns robust representation. During testing, a global-local and local-global matching strategy is proposed. The strategy performs local-verification between reference and query images. Experiments demonstrate that the proposed method is effective. The proposed approach ranks first out of 1,103 participants on the Facebook AI Image Similarity Challenge: Matching Track. The code and trained models are available at https://github.com/WangWenhao0716/ISC-Track1-Submission.
Arch-Net: Model Distillation for Architecture Agnostic Model Deployment
Nov 01, 2021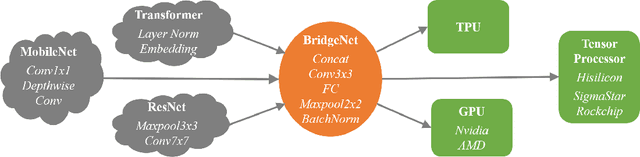
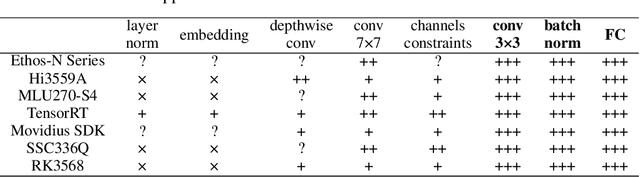
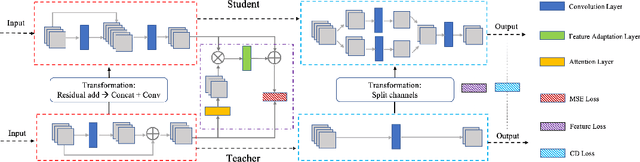

Vast requirement of computation power of Deep Neural Networks is a major hurdle to their real world applications. Many recent Application Specific Integrated Circuit (ASIC) chips feature dedicated hardware support for Neural Network Acceleration. However, as ASICs take multiple years to develop, they are inevitably out-paced by the latest development in Neural Architecture Research. For example, Transformer Networks do not have native support on many popular chips, and hence are difficult to deploy. In this paper, we propose Arch-Net, a family of Neural Networks made up of only operators efficiently supported across most architectures of ASICs. When a Arch-Net is produced, less common network constructs, like Layer Normalization and Embedding Layers, are eliminated in a progressive manner through label-free Blockwise Model Distillation, while performing sub-eight bit quantization at the same time to maximize performance. Empirical results on machine translation and image classification tasks confirm that we can transform latest developed Neural Architectures into fast running and as-accurate Arch-Net, ready for deployment on multiple mass-produced ASIC chips. The code will be available at https://github.com/megvii-research/Arch-Net.
Sub-bit Neural Networks: Learning to Compress and Accelerate Binary Neural Networks
Oct 18, 2021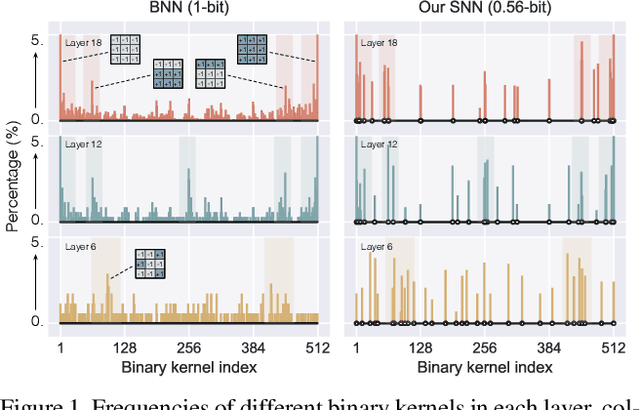
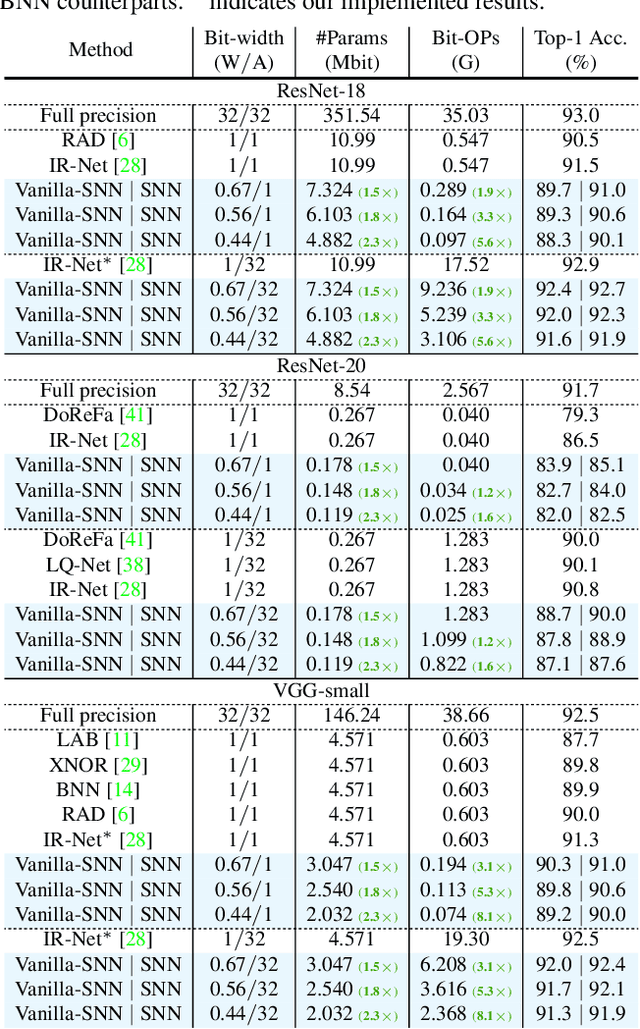
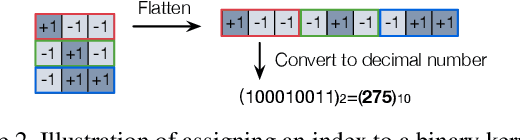
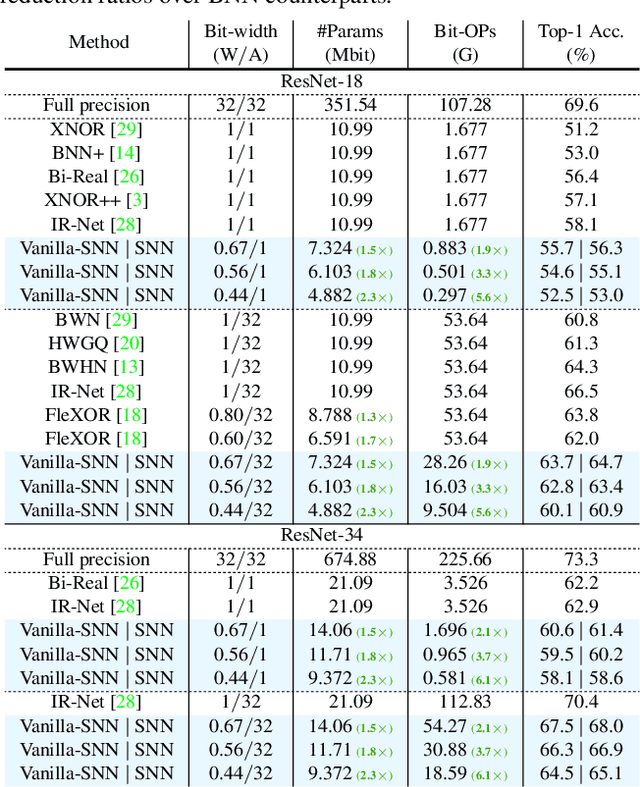
In the low-bit quantization field, training Binary Neural Networks (BNNs) is the extreme solution to ease the deployment of deep models on resource-constrained devices, having the lowest storage cost and significantly cheaper bit-wise operations compared to 32-bit floating-point counterparts. In this paper, we introduce Sub-bit Neural Networks (SNNs), a new type of binary quantization design tailored to compress and accelerate BNNs. SNNs are inspired by an empirical observation, showing that binary kernels learnt at convolutional layers of a BNN model are likely to be distributed over kernel subsets. As a result, unlike existing methods that binarize weights one by one, SNNs are trained with a kernel-aware optimization framework, which exploits binary quantization in the fine-grained convolutional kernel space. Specifically, our method includes a random sampling step generating layer-specific subsets of the kernel space, and a refinement step learning to adjust these subsets of binary kernels via optimization. Experiments on visual recognition benchmarks and the hardware deployment on FPGA validate the great potentials of SNNs. For instance, on ImageNet, SNNs of ResNet-18/ResNet-34 with 0.56-bit weights achieve 3.13/3.33 times runtime speed-up and 1.8 times compression over conventional BNNs with moderate drops in recognition accuracy. Promising results are also obtained when applying SNNs to binarize both weights and activations. Our code is available at https://github.com/yikaiw/SNN.
Dynamic Slimmable Denoising Network
Oct 17, 2021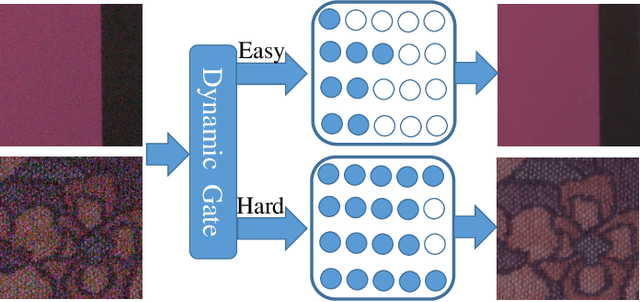

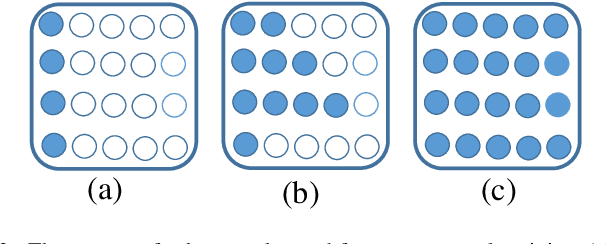
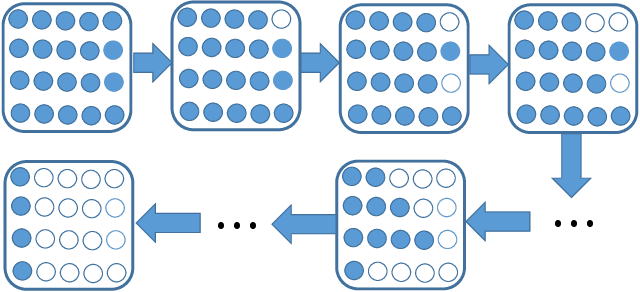
Recently, tremendous human-designed and automatically searched neural networks have been applied to image denoising. However, previous works intend to handle all noisy images in a pre-defined static network architecture, which inevitably leads to high computational complexity for good denoising quality. Here, we present dynamic slimmable denoising network (DDS-Net), a general method to achieve good denoising quality with less computational complexity, via dynamically adjusting the channel configurations of networks at test time with respect to different noisy images. Our DDS-Net is empowered with the ability of dynamic inference by a dynamic gate, which can predictively adjust the channel configuration of networks with negligible extra computation cost. To ensure the performance of each candidate sub-network and the fairness of the dynamic gate, we propose a three-stage optimization scheme. In the first stage, we train a weight-shared slimmable super network. In the second stage, we evaluate the trained slimmable super network in an iterative way and progressively tailor the channel numbers of each layer with minimal denoising quality drop. By a single pass, we can obtain several sub-networks with good performance under different channel configurations. In the last stage, we identify easy and hard samples in an online way and train a dynamic gate to predictively select the corresponding sub-network with respect to different noisy images. Extensive experiments demonstrate our DDS-Net consistently outperforms the state-of-the-art individually trained static denoising networks.
Contrastive Video-Language Segmentation
Sep 29, 2021
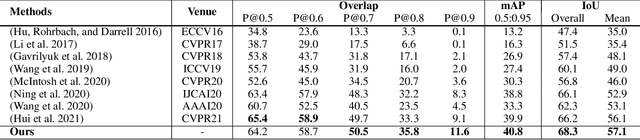
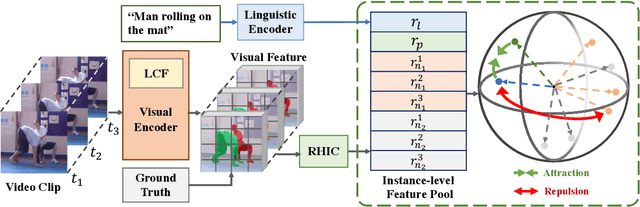
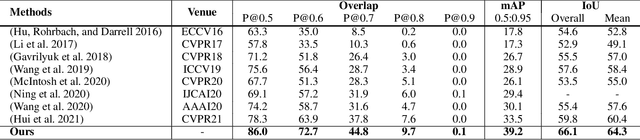
We focus on the problem of segmenting a certain object referred by a natural language sentence in video content, at the core of formulating a pinpoint vision-language relation. While existing attempts mainly construct such relation in an implicit way, i.e., grid-level multi-modal feature fusion, it has been proven problematic to distinguish semantically similar objects under this paradigm. In this work, we propose to interwind the visual and linguistic modalities in an explicit way via the contrastive learning objective, which directly aligns the referred object and the language description and separates the unreferred content apart across frames. Moreover, to remedy for the degradation problem, we present two complementary hard instance mining strategies, i.e., Language-relevant Channel Filter and Relative Hard Instance Construction. They encourage the network to exclude visual-distinguishable feature and to focus on easy-confused objects during the contrastive training. Extensive experiments on two benchmarks, i.e., A2D Sentences and J-HMDB Sentences, quantitatively demonstrate the state-of-the-arts performance of our method and qualitatively show the more accurate distinguishment between semantically similar objects over baselines.