 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYefeng Zheng
Label Propagation for Annotation-Efficient Nuclei Segmentation from Pathology Images
Feb 16, 2022

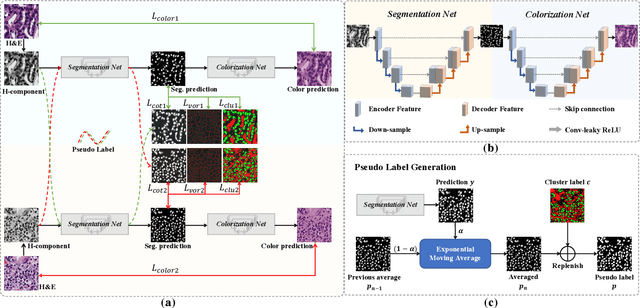
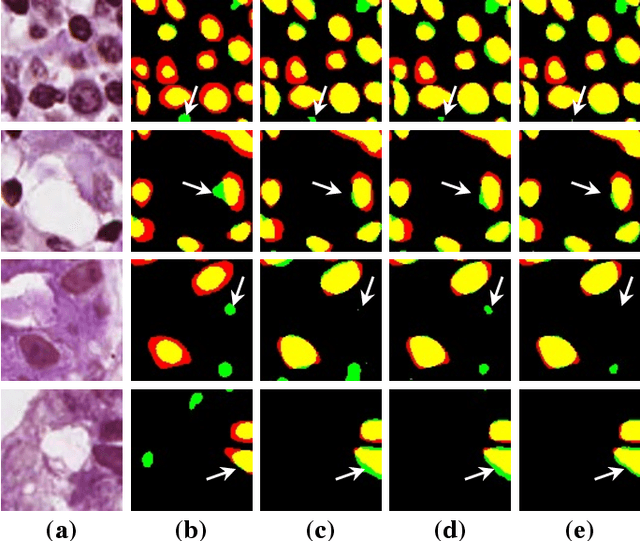

Nuclei segmentation is a crucial task for whole slide image analysis in digital pathology. Generally, the segmentation performance of fully-supervised learning heavily depends on the amount and quality of the annotated data. However, it is time-consuming and expensive for professional pathologists to provide accurate pixel-level ground truth, while it is much easier to get coarse labels such as point annotations. In this paper, we propose a weakly-supervised learning method for nuclei segmentation that only requires point annotations for training. The proposed method achieves label propagation in a coarse-to-fine manner as follows. First, coarse pixel-level labels are derived from the point annotations based on the Voronoi diagram and the k-means clustering method to avoid overfitting. Second, a co-training strategy with an exponential moving average method is designed to refine the incomplete supervision of the coarse labels. Third, a self-supervised visual representation learning method is tailored for nuclei segmentation of pathology images that transforms the hematoxylin component images into the H\&E stained images to gain better understanding of the relationship between the nuclei and cytoplasm. We comprehensively evaluate the proposed method using two public datasets. Both visual and quantitative results demonstrate the superiority of our method to the state-of-the-art methods, and its competitive performance compared to the fully-supervised methods. The source codes for implementing the experiments will be released after acceptance.
FedMed-ATL: Misaligned Unpaired Brain Image Synthesis via Affine Transform Loss
Feb 16, 2022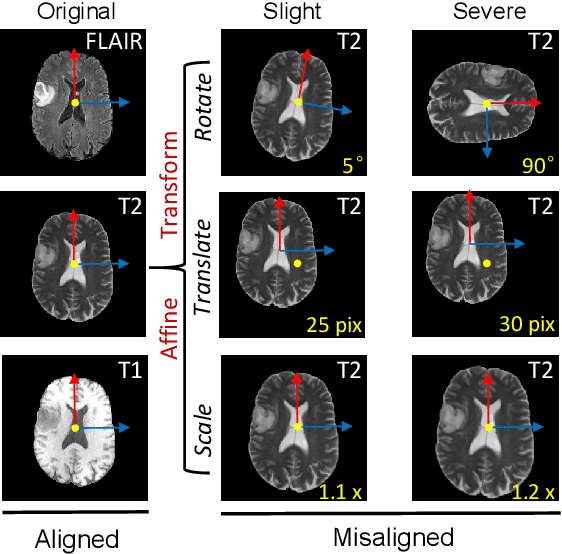
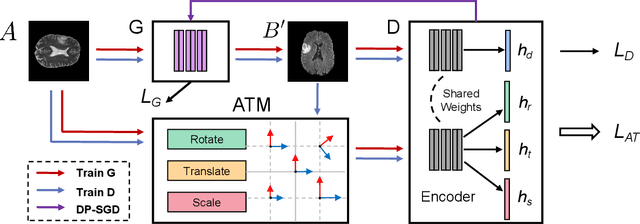
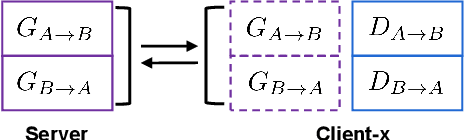
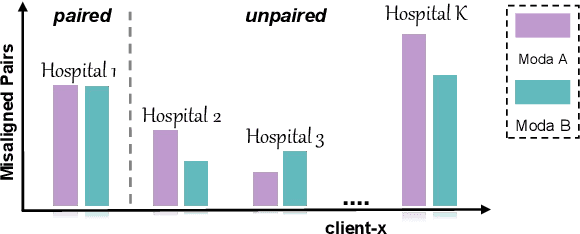
The existence of completely aligned and paired multi-modal neuroimaging data has proved its effectiveness in the diagnosis of brain diseases. However, collecting the full set of well-aligned and paired data is impractical or even luxurious, since the practical difficulties may include high cost, long time acquisition, image corruption, and privacy issues. Previously, the misaligned unpaired neuroimaging data (termed as MUD) are generally treated as noisy label. However, such a noisy label-based method could not work very well when misaligned data occurs distortions severely, for example, different angles of rotation. In this paper, we propose a novel federated self-supervised learning (FedMed) for brain image synthesis. An affine transform loss (ATL) was formulated to make use of severely distorted images without violating privacy legislation for the hospital. We then introduce a new data augmentation procedure for self-supervised training and fed it into three auxiliary heads, namely auxiliary rotation, auxiliary translation, and auxiliary scaling heads. The proposed method demonstrates advanced performance in both the quality of synthesized results under a severely misaligned and unpaired data setting, and better stability than other GAN-based algorithms. The proposed method also reduces the demand for deformable registration while encouraging to realize the usage of those misaligned and unpaired data. Experimental results verify the outstanding ability of our learning paradigm compared to other state-of-the-art approaches. Our code is available on the website: https://github.com/FedMed-Meta/FedMed-ATL
A Survey of Cross-Modality Brain Image Synthesis
Feb 16, 2022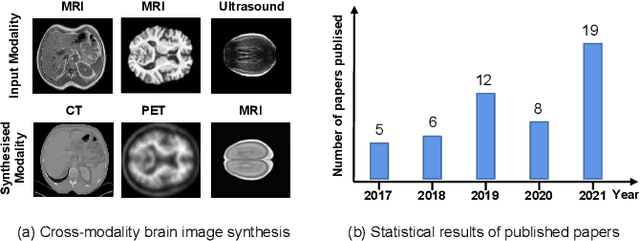
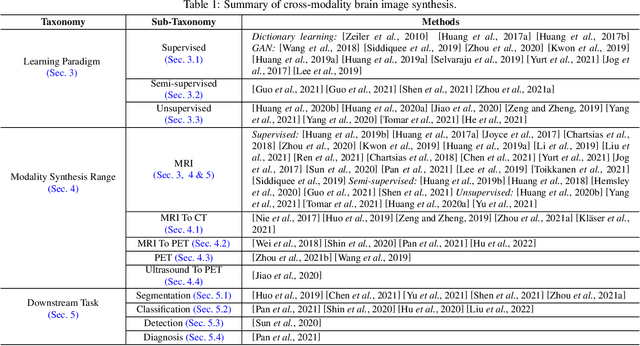
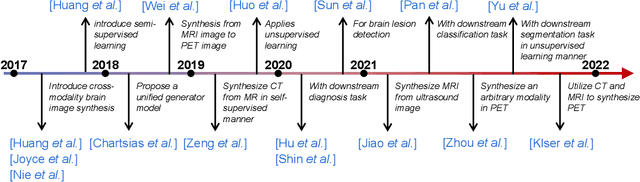
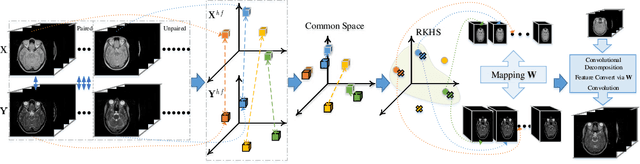
The existence of completely aligned and paired multi-modal neuroimaging data has proved its effectiveness in diagnosis of brain diseases. However, collecting the full set of well-aligned and paired data is impractical or even luxurious, since the practical difficulties may include high cost, long time acquisition, image corruption, and privacy issues. A realistic solution is to explore either an unsupervised learning or a semi-supervised learning to synthesize the absent neuroimaging data. In this paper, we tend to approach multi-modality brain image synthesis task from different perspectives, which include the level of supervision, the range of modality synthesis, and the synthesis-based downstream tasks. Particularly, we provide in-depth analysis on how cross-modality brain image synthesis can improve the performance of different downstream tasks. Finally, we evaluate the challenges and provide several open directions for this community. All resources are available at https://github.com/M-3LAB/awesome-multimodal-brain-image-systhesis
FedMed-GAN: Federated Multi-Modal Unsupervised Brain Image Synthesis
Jan 22, 2022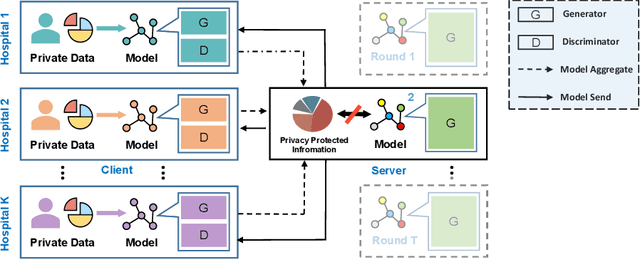

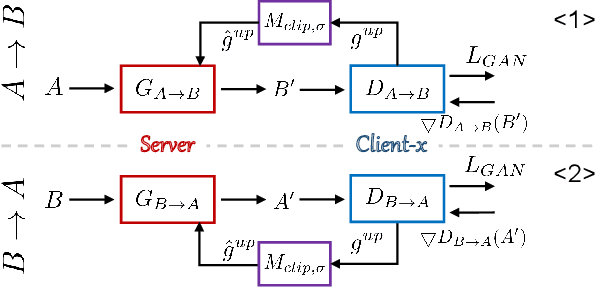
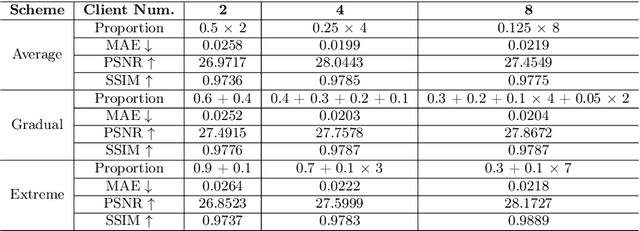
Utilizing the paired multi-modal neuroimaging data has been proved to be effective to investigate human cognitive activities and certain pathologies. However, it is not practical to obtain the full set of paired neuroimaging data centrally since the collection faces several constraints, e.g., high examination costs, long acquisition time, and even image corruption. In addition, most of the paired neuroimaging data are dispersed into different medical institutions and cannot group together for centralized training considering the privacy issues. Under the circumstance, there is a clear need to launch federated learning and facilitate the integration of other unpaired data from different hospitals or data owners. In this paper, we build up a new benchmark for federated multi-modal unsupervised brain image synthesis (termed as FedMed-GAN) to bridge the gap between federated learning and medical GAN. Moreover, based on the similarity of edge information across multi-modal neuroimaging data, we propose a novel edge loss to solve the generative mode collapse issue of FedMed-GAN and mitigate the performance drop resulting from differential privacy. Compared with the state-of-the-art method shown in our built benchmark, our novel edge loss could significantly speed up the generator convergence rate without sacrificing performance under different unpaired data distribution settings.
Revisiting Experience Replay: Continual Learning by Adaptively Tuning Task-wise Relationship
Jan 06, 2022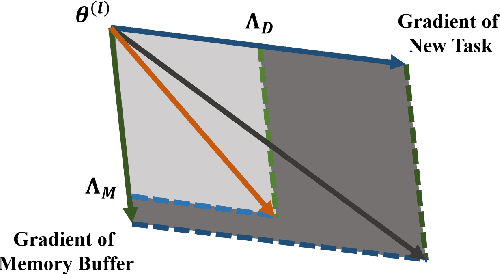
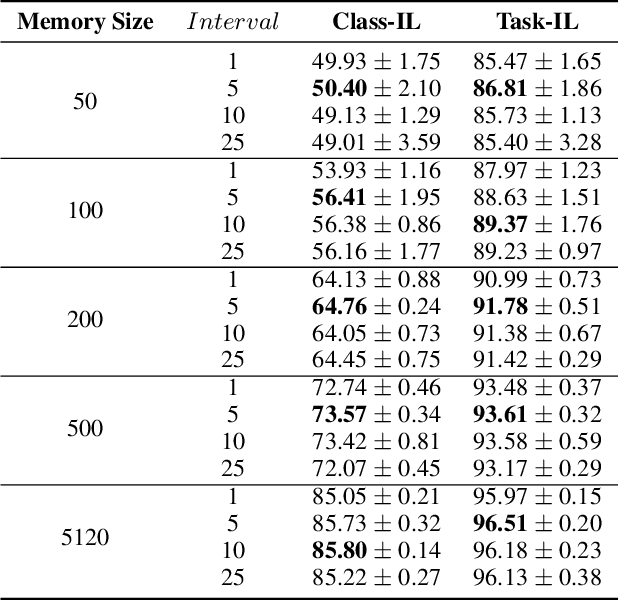
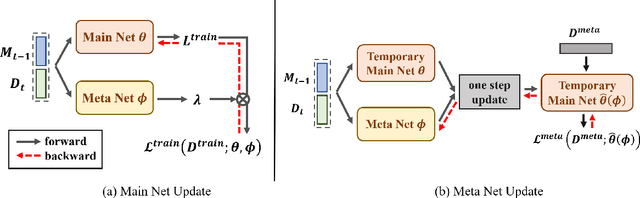
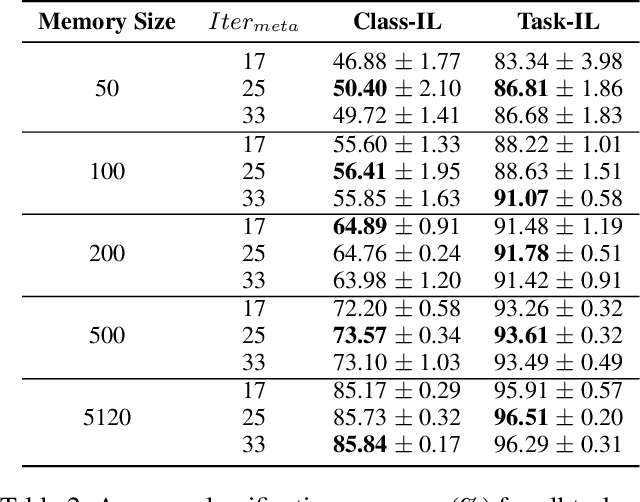
Continual learning requires models to learn new tasks while maintaining previously learned knowledge. Various algorithms have been proposed to address this real challenge. Till now, rehearsal-based methods, such as experience replay, have achieved state-of-the-art performance. These approaches save a small part of the data of the past tasks as a memory buffer to prevent models from forgetting previously learned knowledge. However, most of them treat every new task equally, i.e., fixed the hyperparameters of the framework while learning different new tasks. Such a setting lacks the consideration of the relationship/similarity between past and new tasks. For example, the previous knowledge/features learned from dogs are more beneficial for the identification of cats (new task), compared to those learned from buses. In this regard, we propose a meta learning algorithm based on bi-level optimization to adaptively tune the relationship between the knowledge extracted from the past and new tasks. Therefore, the model can find an appropriate direction of gradient during continual learning and avoid the serious overfitting problem on memory buffer. Extensive experiments are conducted on three publicly available datasets (i.e., CIFAR-10, CIFAR-100, and Tiny ImageNet). The experimental results demonstrate that the proposed method can consistently improve the performance of all baselines.
InDuDoNet+: A Model-Driven Interpretable Dual Domain Network for Metal Artifact Reduction in CT Images
Dec 23, 2021



During the computed tomography (CT) imaging process, metallic implants within patients always cause harmful artifacts, which adversely degrade the visual quality of reconstructed CT images and negatively affect the subsequent clinical diagnosis. For the metal artifact reduction (MAR) task, current deep learning based methods have achieved promising performance. However, most of them share two main common limitations: 1) the CT physical imaging geometry constraint is not comprehensively incorporated into deep network structures; 2) the entire framework has weak interpretability for the specific MAR task; hence, the role of every network module is difficult to be evaluated. To alleviate these issues, in the paper, we construct a novel interpretable dual domain network, termed InDuDoNet+, into which CT imaging process is finely embedded. Concretely, we derive a joint spatial and Radon domain reconstruction model and propose an optimization algorithm with only simple operators for solving it. By unfolding the iterative steps involved in the proposed algorithm into the corresponding network modules, we easily build the InDuDoNet+ with clear interpretability. Furthermore, we analyze the CT values among different tissues, and merge the prior observations into a prior network for our InDuDoNet+, which significantly improve its generalization performance. Comprehensive experiments on synthesized data and clinical data substantiate the superiority of the proposed methods as well as the superior generalization performance beyond the current state-of-the-art (SOTA) MAR methods. Code is available at \url{https://github.com/hongwang01/InDuDoNet_plus}.
Alleviating Noisy-label Effects in Image Classification via Probability Transition Matrix
Oct 19, 2021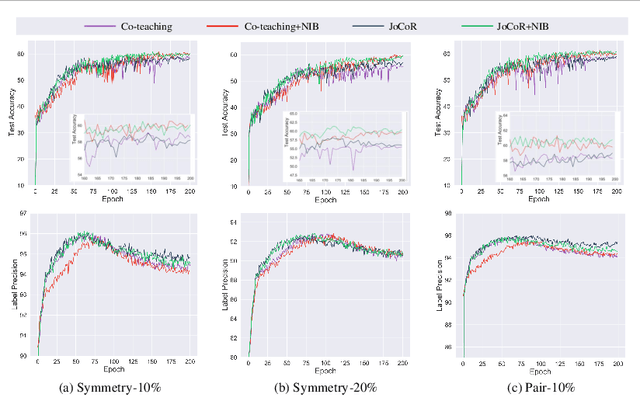
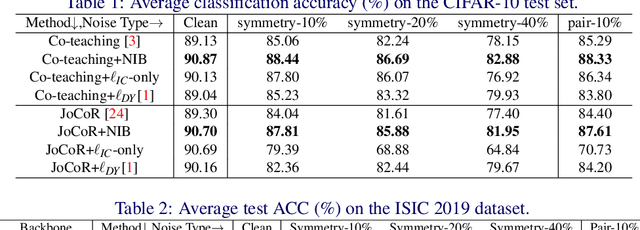
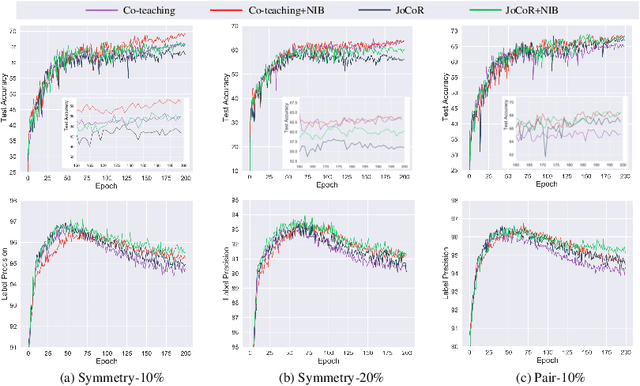
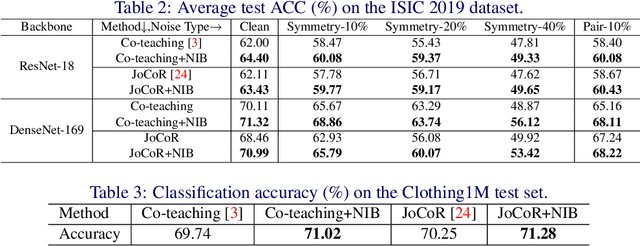
Deep-learning-based image classification frameworks often suffer from the noisy label problem caused by the inter-observer variation. Recent studies employed learning-to-learn paradigms (e.g., Co-teaching and JoCoR) to filter the samples with noisy labels from the training set. However, most of them use a simple cross-entropy loss as the criterion for noisy label identification. The hard samples, which are beneficial for classifier learning, are often mistakenly treated as noises in such a setting since both the hard samples and ones with noisy labels lead to a relatively larger loss value than the easy cases. In this paper, we propose a plugin module, namely noise ignoring block (NIB), consisting of a probability transition matrix and an inter-class correlation (IC) loss, to separate the hard samples from the mislabeled ones, and further boost the accuracy of image classification network trained with noisy labels. Concretely, our IC loss is calculated as Kullback-Leibler divergence between the network prediction and the accumulative soft label generated by the probability transition matrix. Such that, with the lower value of IC loss, the hard cases can be easily distinguished from mislabeled cases. Extensive experiments are conducted on natural and medical image datasets (CIFAR-10 and ISIC 2019). The experimental results show that our NIB module consistently improves the performances of the state-of-the-art robust training methods.
A Unified Framework for Generalized Low-Shot Medical Image Segmentation with Scarce Data
Oct 18, 2021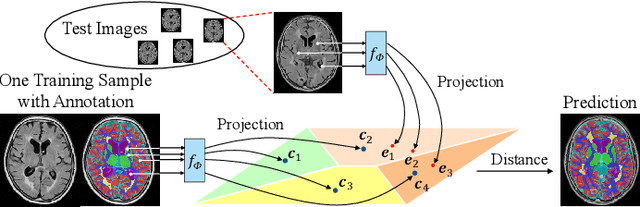
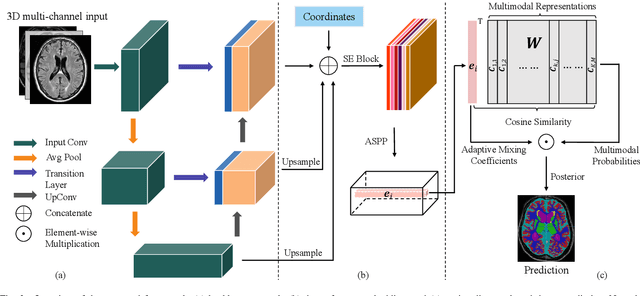
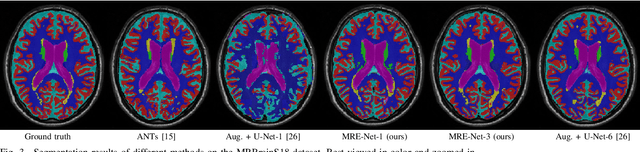

Medical image segmentation has achieved remarkable advancements using deep neural networks (DNNs). However, DNNs often need big amounts of data and annotations for training, both of which can be difficult and costly to obtain. In this work, we propose a unified framework for generalized low-shot (one- and few-shot) medical image segmentation based on distance metric learning (DML). Unlike most existing methods which only deal with the lack of annotations while assuming abundance of data, our framework works with extreme scarcity of both, which is ideal for rare diseases. Via DML, the framework learns a multimodal mixture representation for each category, and performs dense predictions based on cosine distances between the pixels' deep embeddings and the category representations. The multimodal representations effectively utilize the inter-subject similarities and intraclass variations to overcome overfitting due to extremely limited data. In addition, we propose adaptive mixing coefficients for the multimodal mixture distributions to adaptively emphasize the modes better suited to the current input. The representations are implicitly embedded as weights of the fc layer, such that the cosine distances can be computed efficiently via forward propagation. In our experiments on brain MRI and abdominal CT datasets, the proposed framework achieves superior performances for low-shot segmentation towards standard DNN-based (3D U-Net) and classical registration-based (ANTs) methods, e.g., achieving mean Dice coefficients of 81%/69% for brain tissue/abdominal multiorgan segmentation using a single training sample, as compared to 52%/31% and 72%/35% by the U-Net and ANTs, respectively.