 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYashar Mehdad
NeurIPS 2020 EfficientQA Competition: Systems, Analyses and Lessons Learned
Jan 01, 2021
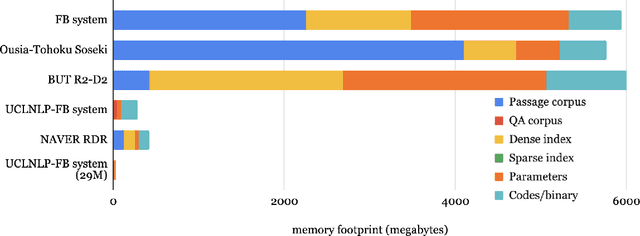
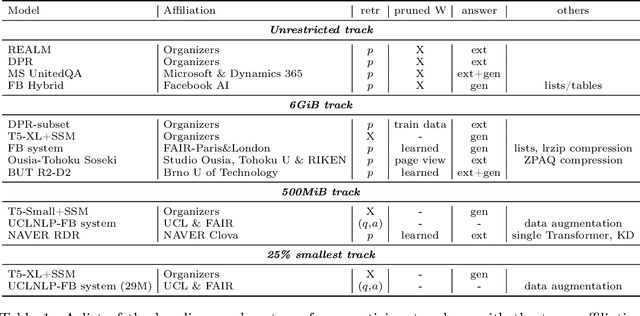
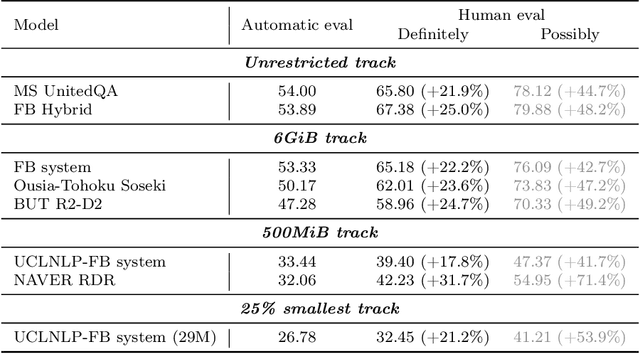
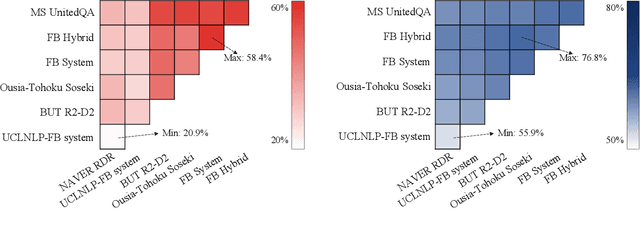
We review the EfficientQA competition from NeurIPS 2020. The competition focused on open-domain question answering (QA), where systems take natural language questions as input and return natural language answers. The aim of the competition was to build systems that can predict correct answers while also satisfying strict on-disk memory budgets. These memory budgets were designed to encourage contestants to explore the trade-off between storing large, redundant, retrieval corpora or the parameters of large learned models. In this report, we describe the motivation and organization of the competition, review the best submissions, and analyze system predictions to inform a discussion of evaluation for open-domain QA.
FiD-Ex: Improving Sequence-to-Sequence Models for Extractive Rationale Generation
Dec 31, 2020
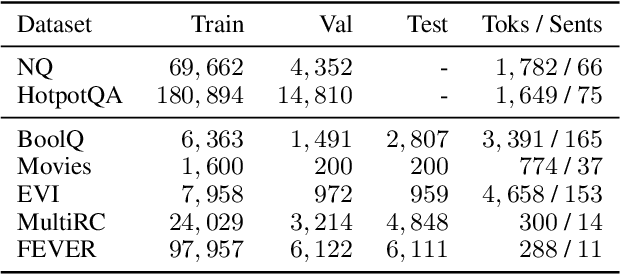
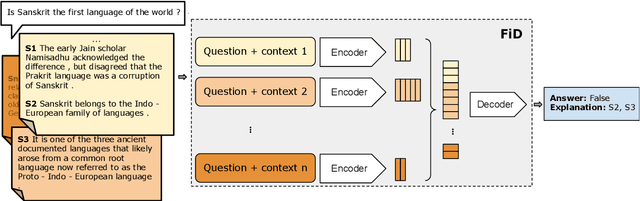
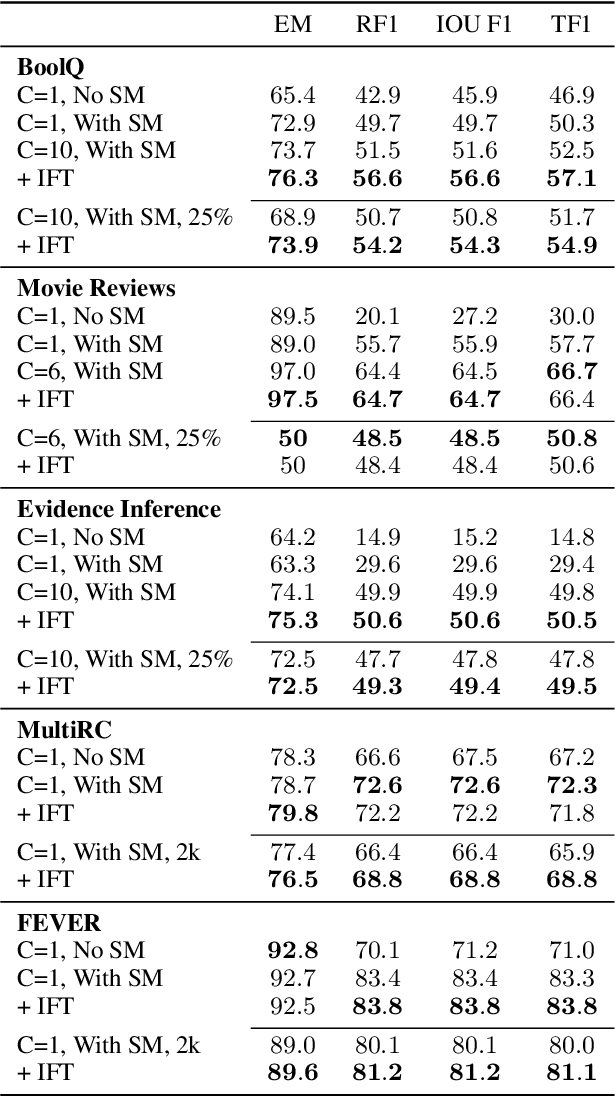
Natural language (NL) explanations of model predictions are gaining popularity as a means to understand and verify decisions made by large black-box pre-trained models, for NLP tasks such as Question Answering (QA) and Fact Verification. Recently, pre-trained sequence to sequence (seq2seq) models have proven to be very effective in jointly making predictions, as well as generating NL explanations. However, these models have many shortcomings; they can fabricate explanations even for incorrect predictions, they are difficult to adapt to long input documents, and their training requires a large amount of labeled data. In this paper, we develop FiD-Ex, which addresses these shortcomings for seq2seq models by: 1) introducing sentence markers to eliminate explanation fabrication by encouraging extractive generation, 2) using the fusion-in-decoder architecture to handle long input contexts, and 3) intermediate fine-tuning on re-structured open domain QA datasets to improve few-shot performance. FiD-Ex significantly improves over prior work in terms of explanation metrics and task accuracy, on multiple tasks from the ERASER explainability benchmark, both in the fully supervised and in the few-shot settings.
Human Evaluation of Spoken vs. Visual Explanations for Open-Domain QA
Dec 30, 2020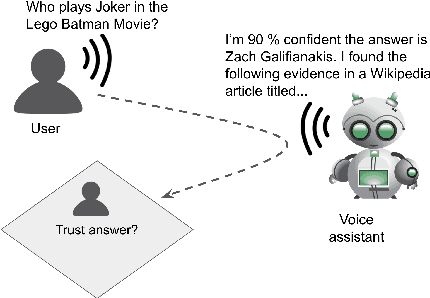
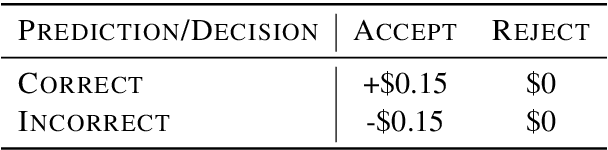


While research on explaining predictions of open-domain QA systems (ODQA) to users is gaining momentum, most works have failed to evaluate the extent to which explanations improve user trust. While few works evaluate explanations using user studies, they employ settings that may deviate from the end-user's usage in-the-wild: ODQA is most ubiquitous in voice-assistants, yet current research only evaluates explanations using a visual display, and may erroneously extrapolate conclusions about the most performant explanations to other modalities. To alleviate these issues, we conduct user studies that measure whether explanations help users correctly decide when to accept or reject an ODQA system's answer. Unlike prior work, we control for explanation modality, e.g., whether they are communicated to users through a spoken or visual interface, and contrast effectiveness across modalities. Our results show that explanations derived from retrieved evidence passages can outperform strong baselines (calibrated confidence) across modalities but the best explanation strategy in fact changes with the modality. We show common failure cases of current explanations, emphasize end-to-end evaluation of explanations, and caution against evaluating them in proxy modalities that are different from deployment.
Towards Understanding the Optimal Behaviors of Deep Active Learning Algorithms
Dec 29, 2020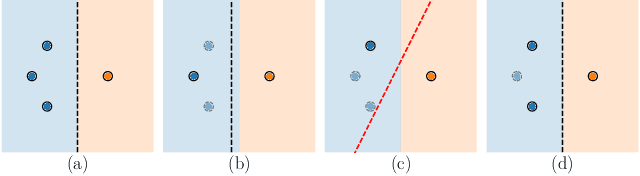

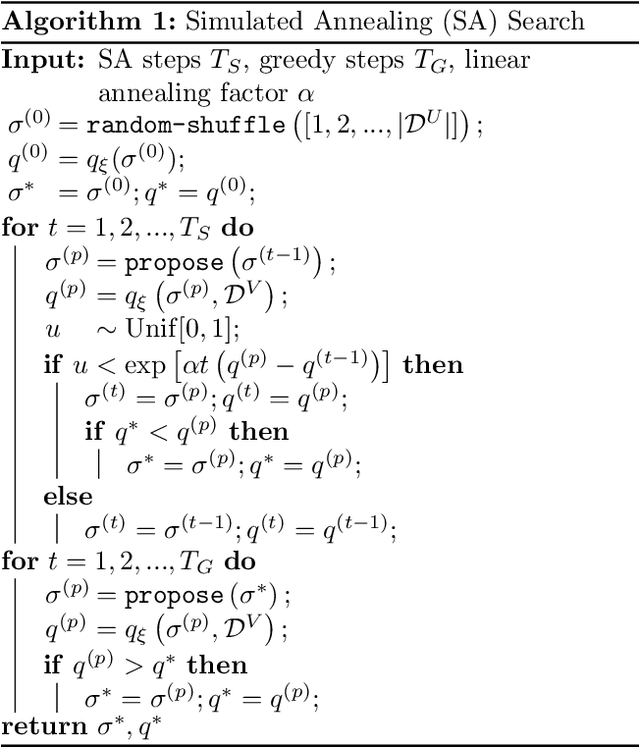
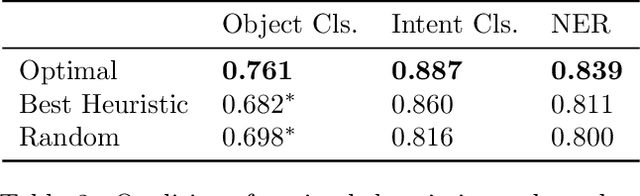
Active learning (AL) algorithms may achieve better performance with fewer data because the model guides the data selection process. While many algorithms have been proposed, there is little study on what the optimal AL algorithm looks like, which would help researchers understand where their models fall short and iterate on the design. In this paper, we present a simulated annealing algorithm to search for this optimal oracle and analyze it for several different tasks. We present several qualitative and quantitative insights into the optimal behavior and contrast this behavior with those of various heuristics. When augmented by with one particular insight, heuristics perform consistently better. We hope that our findings can better inform future active learning research. The code for the experiments is available at https://github.com/YilunZhou/optimal-active-learning.
Unified Open-Domain Question Answering with Structured and Unstructured Knowledge
Dec 29, 2020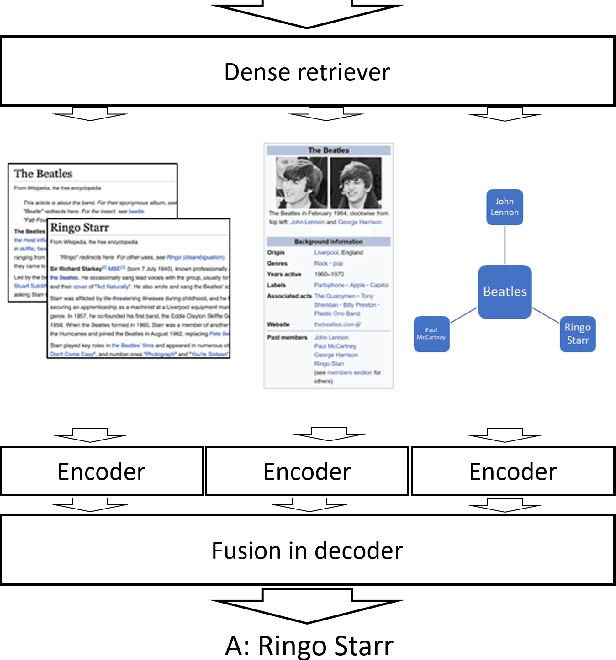

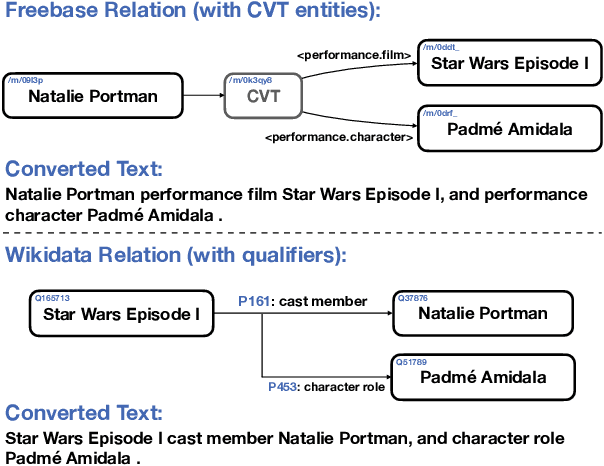
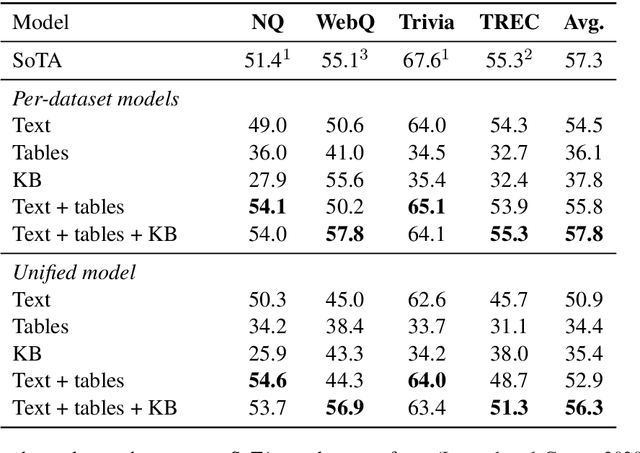
We study open-domain question answering (ODQA) with structured, unstructured and semi-structured knowledge sources, including text, tables, lists, and knowledge bases. Our approach homogenizes all sources by reducing them to text, and applies recent, powerful retriever-reader models which have so far been limited to text sources only. We show that knowledge-base QA can be greatly improved when reformulated in this way. Contrary to previous work, we find that combining sources always helps, even for datasets which target a single source by construction. As a result, our unified model produces state-of-the-art results on 3 popular ODQA benchmarks.
Improving Zero and Few-Shot Abstractive Summarization with Intermediate Fine-tuning and Data Augmentation
Oct 24, 2020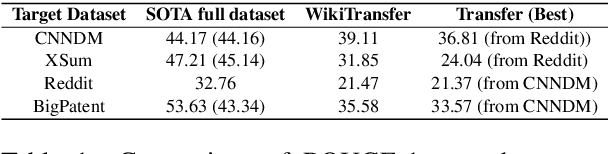
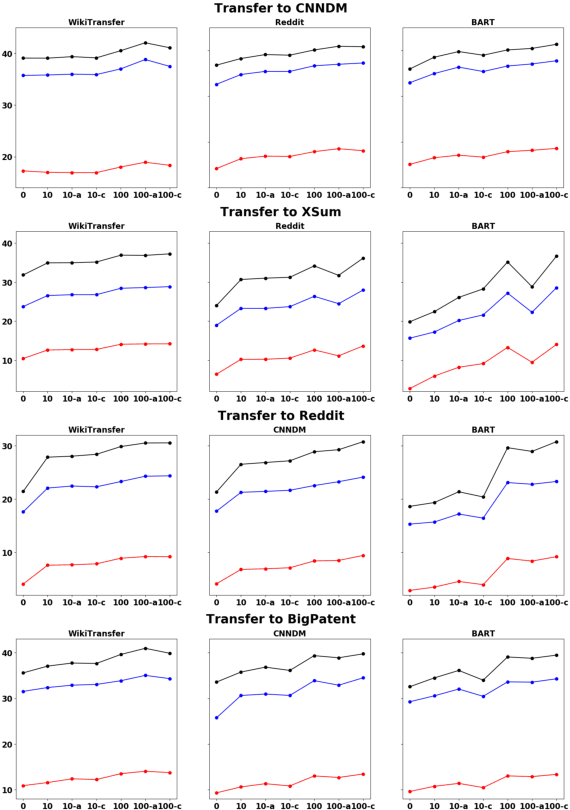

Models pretrained with self-supervised objectives on large text corpora achieve state-of-the-art performance on text summarization tasks. However, these models are typically fine-tuned on hundreds of thousands of data points, an infeasible requirement when applying summarization to new, niche domains. In this work, we introduce a general method, called WikiTransfer, for fine-tuning pretrained models for summarization in an unsupervised, dataset-specific manner which makes use of characteristics of the target dataset such as the length and abstractiveness of the desired summaries. We achieve state-of-the-art, zero-shot abstractive summarization performance on the CNN-DailyMail dataset and demonstrate the effectiveness of our approach on three additional, diverse datasets. The models fine-tuned in this unsupervised manner are more robust to noisy data and also achieve better few-shot performance using 10 and 100 training examples. We perform ablation studies on the effect of the components of our unsupervised fine-tuning data and analyze the performance of these models in few-shot scenarios along with data augmentation techniques using both automatic and human evaluation.
RECONSIDER: Re-Ranking using Span-Focused Cross-Attention for Open Domain Question Answering
Oct 21, 2020
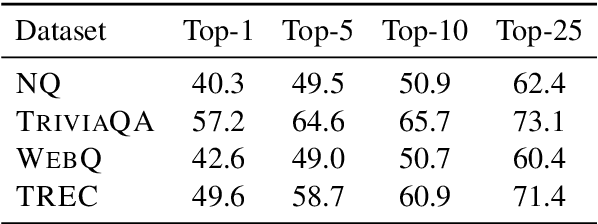
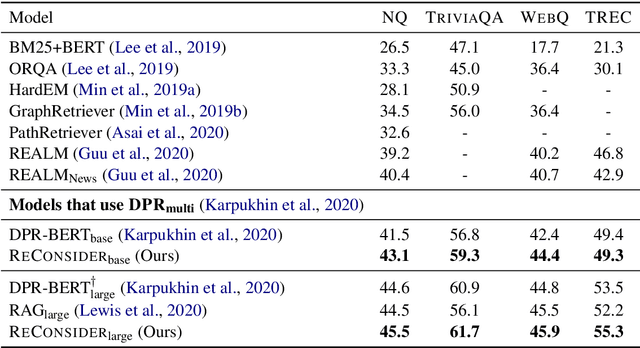
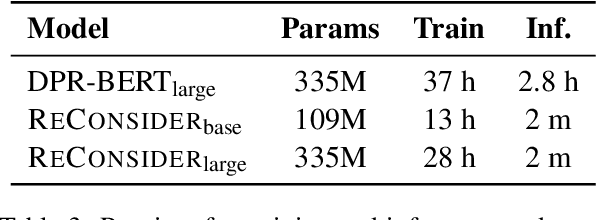
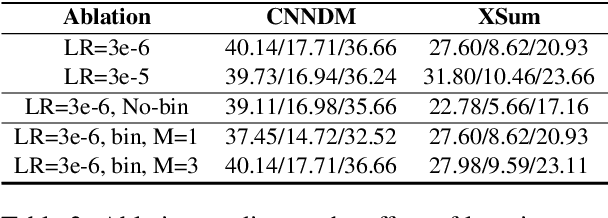
State-of-the-art Machine Reading Comprehension (MRC) models for Open-domain Question Answering (QA) are typically trained for span selection using distantly supervised positive examples and heuristically retrieved negative examples. This training scheme possibly explains empirical observations that these models achieve a high recall amongst their top few predictions, but a low overall accuracy, motivating the need for answer re-ranking. We develop a simple and effective re-ranking approach (RECONSIDER) for span-extraction tasks, that improves upon the performance of large pre-trained MRC models. RECONSIDER is trained on positive and negative examples extracted from high confidence predictions of MRC models, and uses in-passage span annotations to perform span-focused re-ranking over a smaller candidate set. As a result, RECONSIDER learns to eliminate close false positive passages, and achieves a new state of the art on four QA tasks, including 45.5% Exact Match accuracy on Natural Questions with real user questions, and 61.7% on TriviaQA.
Low-Resource Domain Adaptation for Compositional Task-Oriented Semantic Parsing
Oct 07, 2020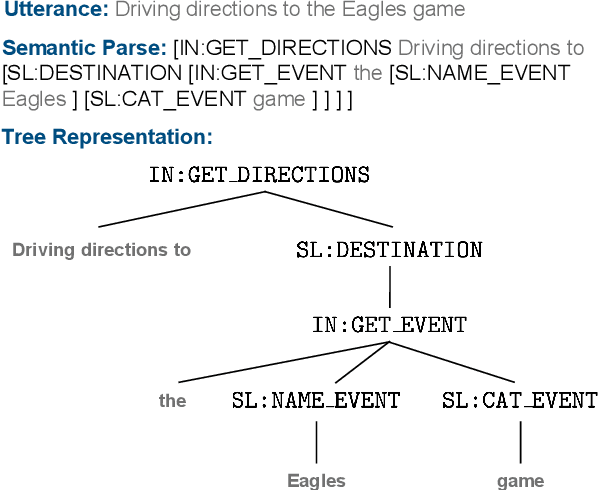
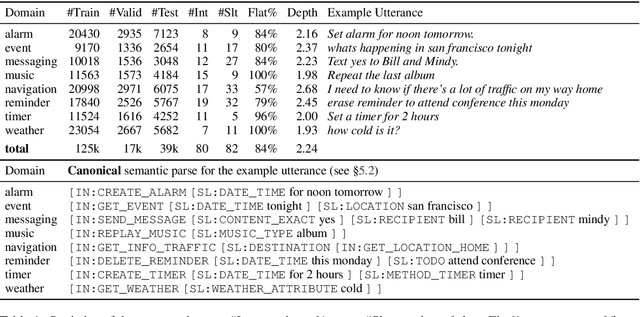
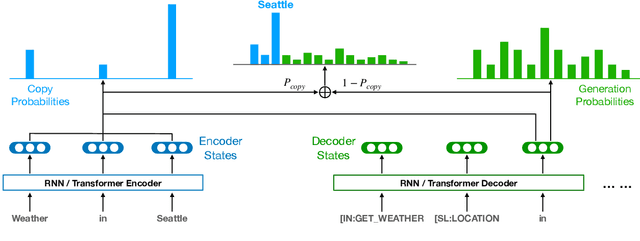
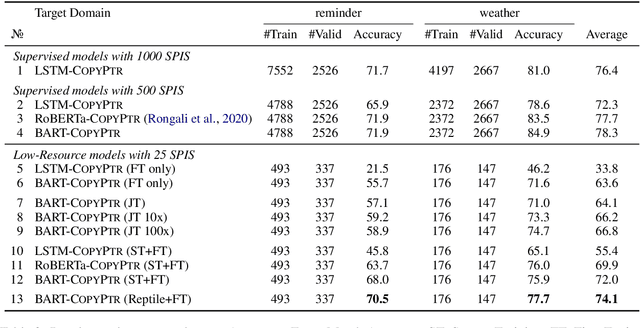
Task-oriented semantic parsing is a critical component of virtual assistants, which is responsible for understanding the user's intents (set reminder, play music, etc.). Recent advances in deep learning have enabled several approaches to successfully parse more complex queries (Gupta et al., 2018; Rongali et al.,2020), but these models require a large amount of annotated training data to parse queries on new domains (e.g. reminder, music). In this paper, we focus on adapting task-oriented semantic parsers to low-resource domains, and propose a novel method that outperforms a supervised neural model at a 10-fold data reduction. In particular, we identify two fundamental factors for low-resource domain adaptation: better representation learning and better training techniques. Our representation learning uses BART (Lewis et al., 2019) to initialize our model which outperforms encoder-only pre-trained representations used in previous work. Furthermore, we train with optimization-based meta-learning (Finn et al., 2017) to improve generalization to low-resource domains. This approach significantly outperforms all baseline methods in the experiments on a newly collected multi-domain task-oriented semantic parsing dataset (TOPv2), which we release to the public.
Efficient One-Pass End-to-End Entity Linking for Questions
Oct 06, 2020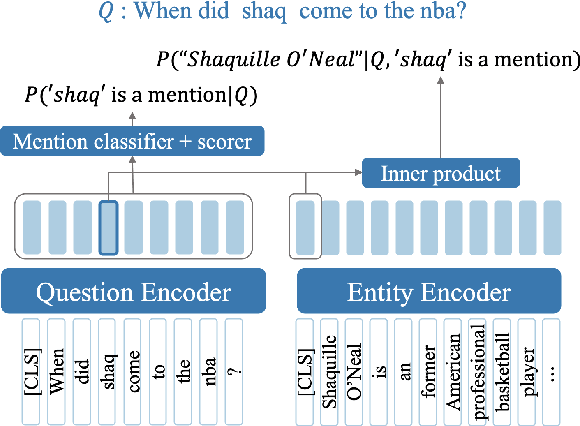
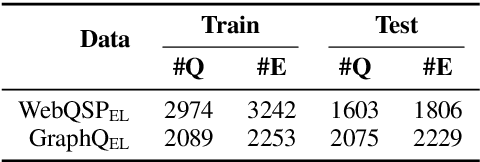
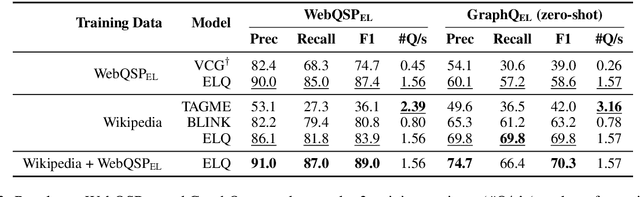
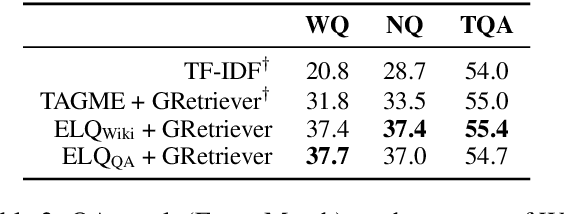
We present ELQ, a fast end-to-end entity linking model for questions, which uses a biencoder to jointly perform mention detection and linking in one pass. Evaluated on WebQSP and GraphQuestions with extended annotations that cover multiple entities per question, ELQ outperforms the previous state of the art by a large margin of +12.7% and +19.6% F1, respectively. With a very fast inference time (1.57 examples/s on a single CPU), ELQ can be useful for downstream question answering systems. In a proof-of-concept experiment, we demonstrate that using ELQ significantly improves the downstream QA performance of GraphRetriever (arXiv:1911.03868). Code and data available at https://github.com/facebookresearch/BLINK/tree/master/elq
Conversational Semantic Parsing
Sep 28, 2020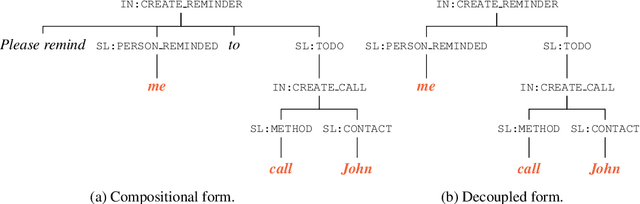
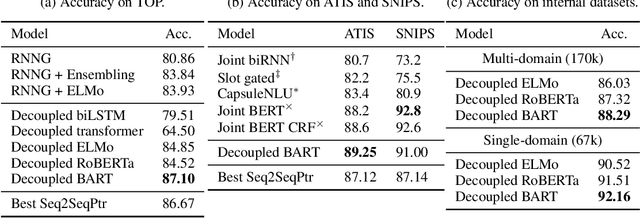
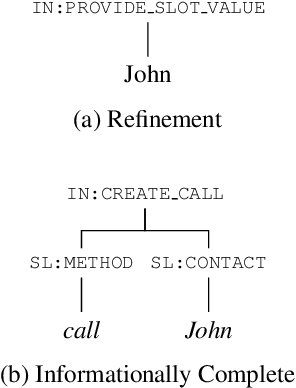
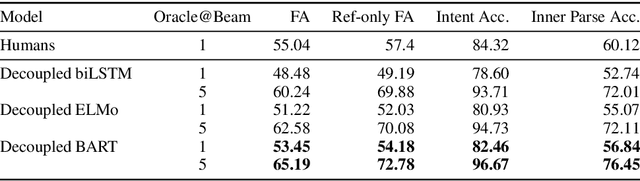
The structured representation for semantic parsing in task-oriented assistant systems is geared towards simple understanding of one-turn queries. Due to the limitations of the representation, the session-based properties such as co-reference resolution and context carryover are processed downstream in a pipelined system. In this paper, we propose a semantic representation for such task-oriented conversational systems that can represent concepts such as co-reference and context carryover, enabling comprehensive understanding of queries in a session. We release a new session-based, compositional task-oriented parsing dataset of 20k sessions consisting of 60k utterances. Unlike Dialog State Tracking Challenges, the queries in the dataset have compositional forms. We propose a new family of Seq2Seq models for the session-based parsing above, which achieve better or comparable performance to the current state-of-the-art on ATIS, SNIPS, TOP and DSTC2. Notably, we improve the best known results on DSTC2 by up to 5 points for slot-carryover.