 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYash Chandak
On Optimizing Interventions in Shared Autonomy
Jan 01, 2022
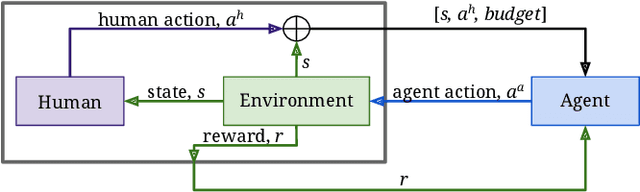
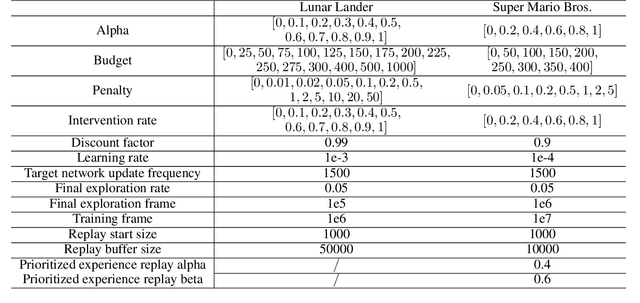

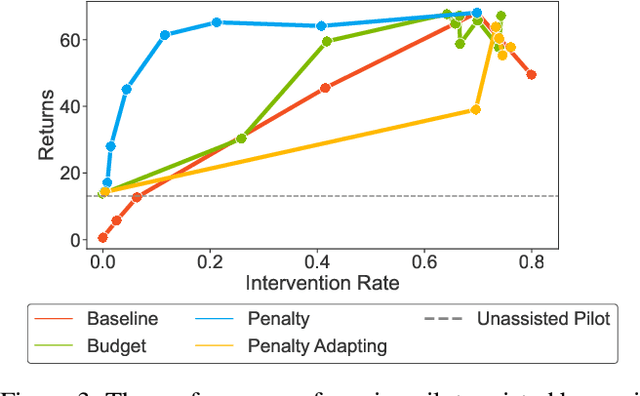
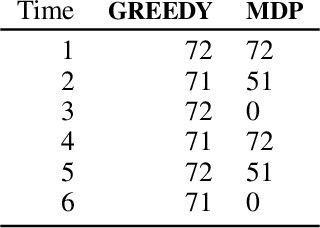
Shared autonomy refers to approaches for enabling an autonomous agent to collaborate with a human with the aim of improving human performance. However, besides improving performance, it may often also be beneficial that the agent concurrently accounts for preserving the user's experience or satisfaction of collaboration. In order to address this additional goal, we examine approaches for improving the user experience by constraining the number of interventions by the autonomous agent. We propose two model-free reinforcement learning methods that can account for both hard and soft constraints on the number of interventions. We show that not only does our method outperform the existing baseline, but also eliminates the need to manually tune a black-box hyperparameter for controlling the level of assistance. We also provide an in-depth analysis of intervention scenarios in order to further illuminate system understanding.
SOPE: Spectrum of Off-Policy Estimators
Dec 02, 2021

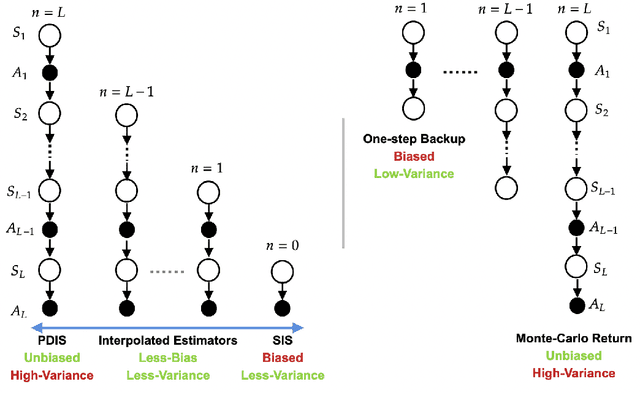
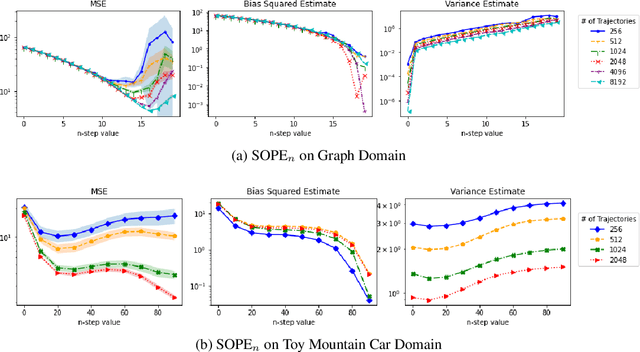
Many sequential decision making problems are high-stakes and require off-policy evaluation (OPE) of a new policy using historical data collected using some other policy. One of the most common OPE techniques that provides unbiased estimates is trajectory based importance sampling (IS). However, due to the high variance of trajectory IS estimates, importance sampling methods based on state-action visitation distributions (SIS) have recently been adopted. Unfortunately, while SIS often provides lower variance estimates for long horizons, estimating the state-action distribution ratios can be challenging and lead to biased estimates. In this paper, we present a new perspective on this bias-variance trade-off and show the existence of a spectrum of estimators whose endpoints are SIS and IS. Additionally, we also establish a spectrum for doubly-robust and weighted version of these estimators. We provide empirical evidence that estimators in this spectrum can be used to trade-off between the bias and variance of IS and SIS and can achieve lower mean-squared error than both IS and SIS.
Universal Off-Policy Evaluation
Apr 26, 2021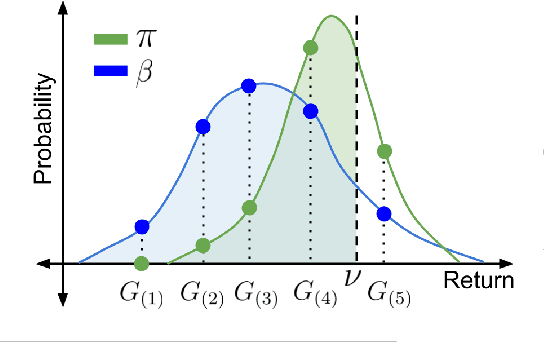

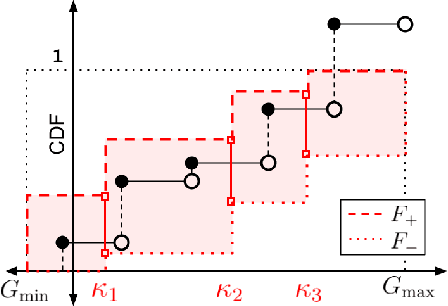
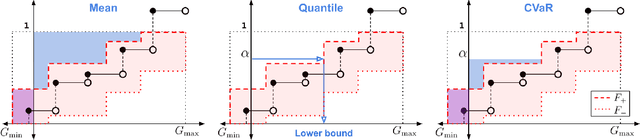
When faced with sequential decision-making problems, it is often useful to be able to predict what would happen if decisions were made using a new policy. Those predictions must often be based on data collected under some previously used decision-making rule. Many previous methods enable such off-policy (or counterfactual) estimation of the expected value of a performance measure called the return. In this paper, we take the first steps towards a universal off-policy estimator (UnO) -- one that provides off-policy estimates and high-confidence bounds for any parameter of the return distribution. We use UnO for estimating and simultaneously bounding the mean, variance, quantiles/median, inter-quantile range, CVaR, and the entire cumulative distribution of returns. Finally, we also discuss Uno's applicability in various settings, including fully observable, partially observable (i.e., with unobserved confounders), Markovian, non-Markovian, stationary, smoothly non-stationary, and discrete distribution shifts.
High-Confidence Off-Policy (or Counterfactual) Variance Estimation
Jan 25, 2021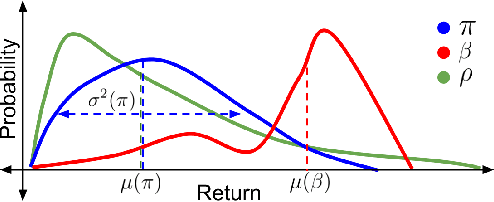
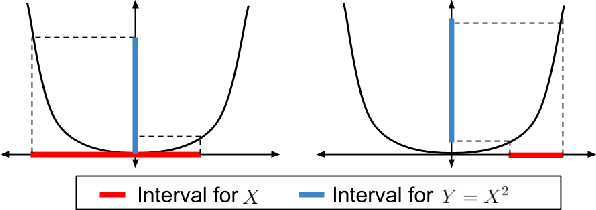
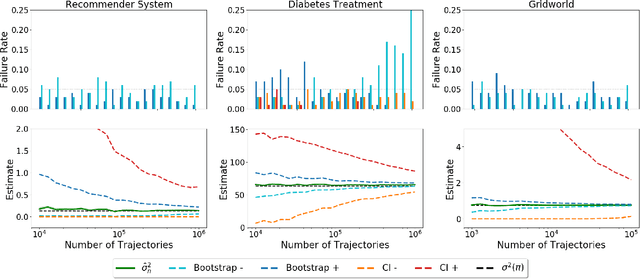
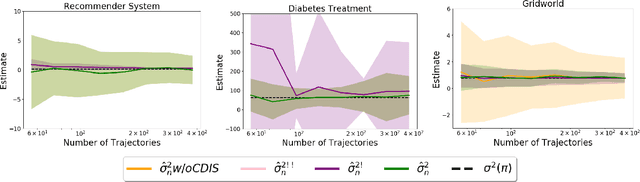
Many sequential decision-making systems leverage data collected using prior policies to propose a new policy. For critical applications, it is important that high-confidence guarantees on the new policy's behavior are provided before deployment, to ensure that the policy will behave as desired. Prior works have studied high-confidence off-policy estimation of the expected return, however, high-confidence off-policy estimation of the variance of returns can be equally critical for high-risk applications. In this paper, we tackle the previously open problem of estimating and bounding, with high confidence, the variance of returns from off-policy data
Towards Safe Policy Improvement for Non-Stationary MDPs
Oct 23, 2020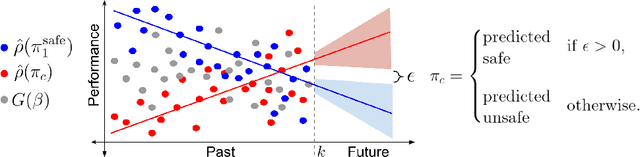
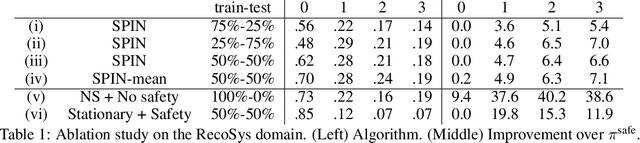
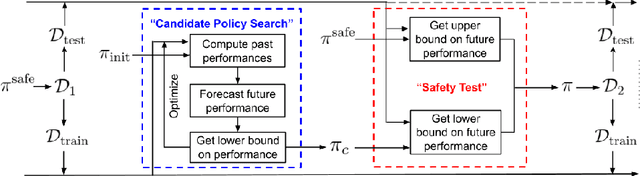

Many real-world sequential decision-making problems involve critical systems with financial risks and human-life risks. While several works in the past have proposed methods that are safe for deployment, they assume that the underlying problem is stationary. However, many real-world problems of interest exhibit non-stationarity, and when stakes are high, the cost associated with a false stationarity assumption may be unacceptable. We take the first steps towards ensuring safety, with high confidence, for smoothly-varying non-stationary decision problems. Our proposed method extends a type of safe algorithm, called a Seldonian algorithm, through a synthesis of model-free reinforcement learning with time-series analysis. Safety is ensured using sequential hypothesis testing of a policy's forecasted performance, and confidence intervals are obtained using wild bootstrap.
Reinforcement Learning for Strategic Recommendations
Sep 15, 2020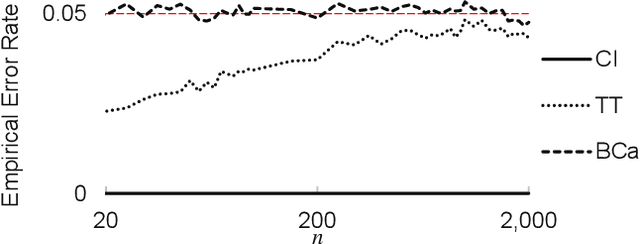

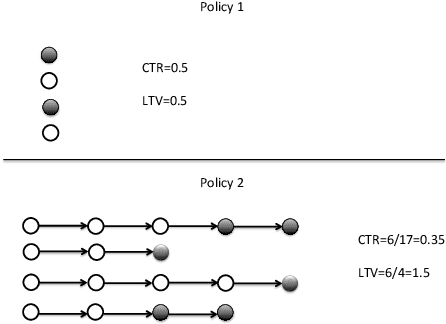
Strategic recommendations (SR) refer to the problem where an intelligent agent observes the sequential behaviors and activities of users and decides when and how to interact with them to optimize some long-term objectives, both for the user and the business. These systems are in their infancy in the industry and in need of practical solutions to some fundamental research challenges. At Adobe research, we have been implementing such systems for various use-cases, including points of interest recommendations, tutorial recommendations, next step guidance in multi-media editing software, and ad recommendation for optimizing lifetime value. There are many research challenges when building these systems, such as modeling the sequential behavior of users, deciding when to intervene and offer recommendations without annoying the user, evaluating policies offline with high confidence, safe deployment, non-stationarity, building systems from passive data that do not contain past recommendations, resource constraint optimization in multi-user systems, scaling to large and dynamic actions spaces, and handling and incorporating human cognitive biases. In this paper we cover various use-cases and research challenges we solved to make these systems practical.
Evaluating the Performance of Reinforcement Learning Algorithms
Jun 30, 2020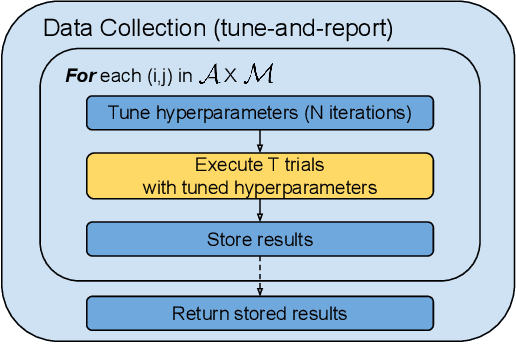
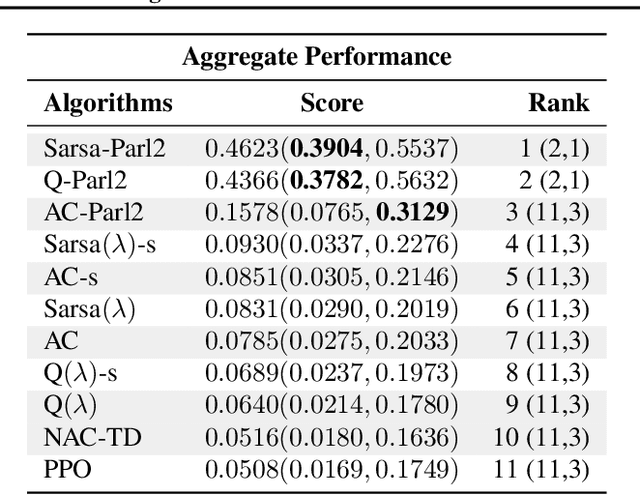
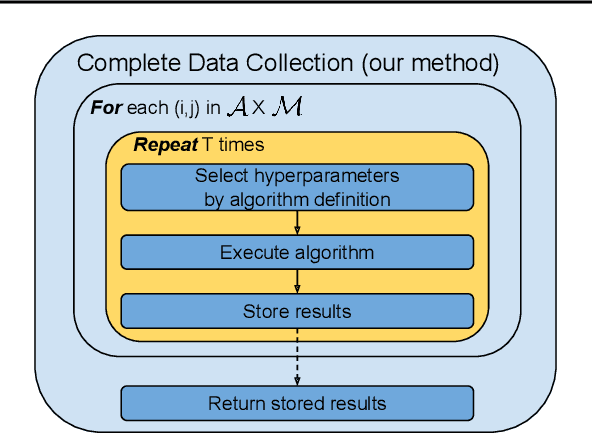
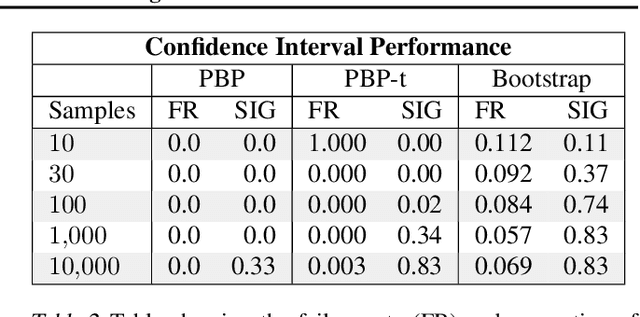
Performance evaluations are critical for quantifying algorithmic advances in reinforcement learning. Recent reproducibility analyses have shown that reported performance results are often inconsistent and difficult to replicate. In this work, we argue that the inconsistency of performance stems from the use of flawed evaluation metrics. Taking a step towards ensuring that reported results are consistent, we propose a new comprehensive evaluation methodology for reinforcement learning algorithms that produces reliable measurements of performance both on a single environment and when aggregated across environments. We demonstrate this method by evaluating a broad class of reinforcement learning algorithms on standard benchmark tasks.