 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYang Li
Wind Power Forecasting Considering Data Privacy Protection: A Federated Deep Reinforcement Learning Approach
Nov 02, 2022
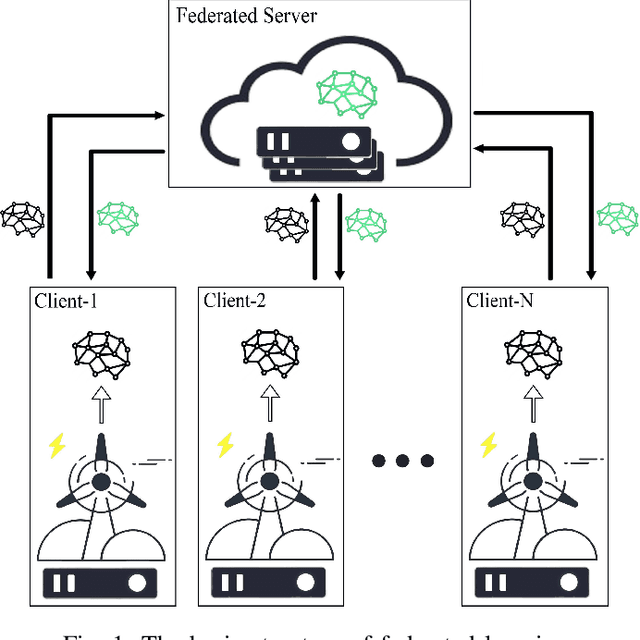
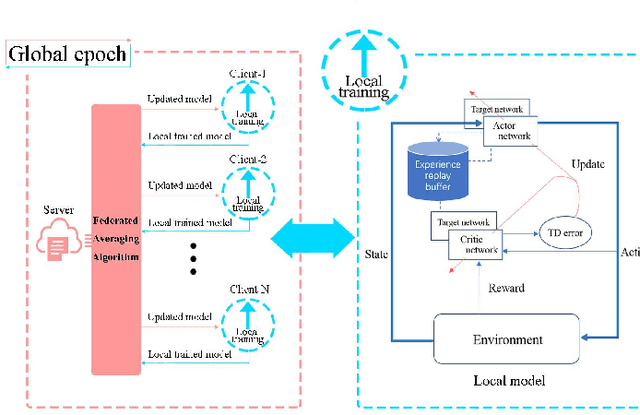
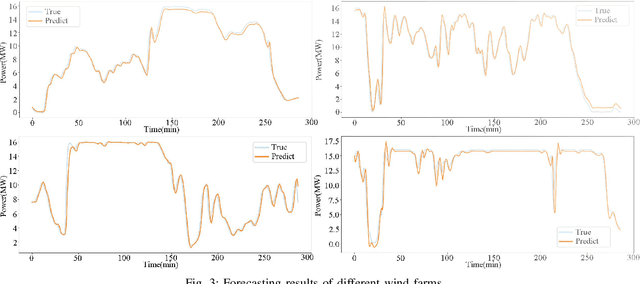
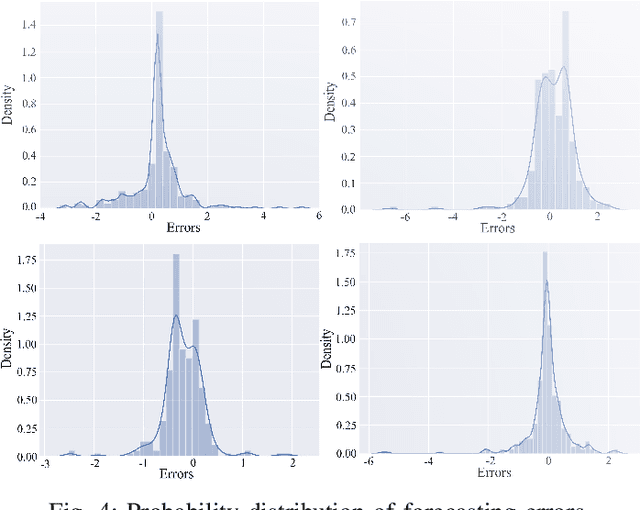
In a modern power system with an increasing proportion of renewable energy, wind power prediction is crucial to the arrangement of power grid dispatching plans due to the volatility of wind power. However, traditional centralized forecasting methods raise concerns regarding data privacy-preserving and data islands problem. To handle the data privacy and openness, we propose a forecasting scheme that combines federated learning and deep reinforcement learning (DRL) for ultra-short-term wind power forecasting, called federated deep reinforcement learning (FedDRL). Firstly, this paper uses the deep deterministic policy gradient (DDPG) algorithm as the basic forecasting model to improve prediction accuracy. Secondly, we integrate the DDPG forecasting model into the framework of federated learning. The designed FedDRL can obtain an accurate prediction model in a decentralized way by sharing model parameters instead of sharing private data which can avoid sensitive privacy issues. The simulation results show that the proposed FedDRL outperforms the traditional prediction methods in terms of forecasting accuracy. More importantly, while ensuring the forecasting performance, FedDRL can effectively protect the data privacy and relieve the communication pressure compared with the traditional centralized forecasting method. In addition, a simulation with different federated learning parameters is conducted to confirm the robustness of the proposed scheme.
Factorized Blank Thresholding for Improved Runtime Efficiency of Neural Transducers
Nov 02, 2022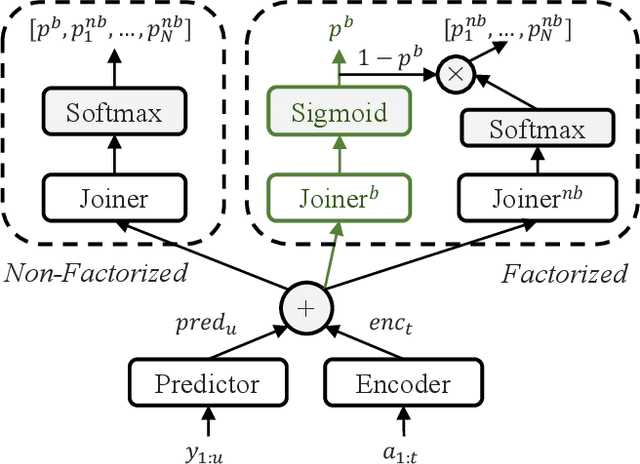
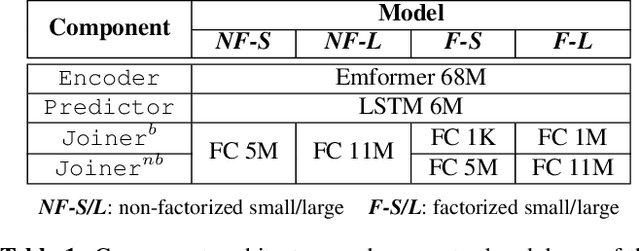
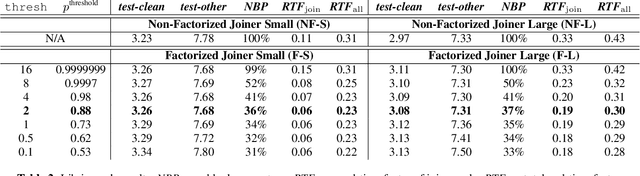
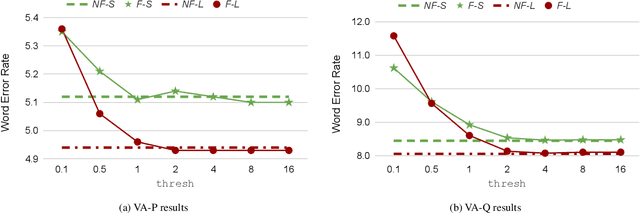
We show how factoring the RNN-T's output distribution can significantly reduce the computation cost and power consumption for on-device ASR inference with no loss in accuracy. With the rise in popularity of neural-transducer type models like the RNN-T for on-device ASR, optimizing RNN-T's runtime efficiency is of great interest. While previous work has primarily focused on the optimization of RNN-T's acoustic encoder and predictor, this paper focuses the attention on the joiner. We show that despite being only a small part of RNN-T, the joiner has a large impact on the overall model's runtime efficiency. We propose to factorize the joiner into blank and non-blank portions for the purpose of skipping the more expensive non-blank computation when the blank probability exceeds a certain threshold. Since the blank probability can be computed very efficiently and the RNN-T output is dominated by blanks, our proposed method leads to a 26-30% decoding speed-up and 43-53% reduction in on-device power consumption, all the while incurring no accuracy degradation and being relatively simple to implement.
Review on Monitoring, Operation and Maintenance of Smart Offshore Wind Farms
Nov 01, 2022



In recent years, with the development of wind energy, the number and scale of wind farms are developing rapidly. Since offshore wind farm has the advantages of stable wind speed, clean, renewable, non-polluting and no occupation of cultivated land, which has gradually become a new trend of wind power industry all over the world. The operation and maintenance mode of offshore wind power is developing in the direction of digitization and intelligence. It is of great significance to carry out the research on the monitoring, operation and maintenance of offshore wind farm, which will be of benefits to reduce the operation and maintenance cost, improve the power generation efficiency, improve the stability of offshore wind farm system and build smart offshore wind farm. This paper will mainly analyze and summarize the monitoring, operation and maintenance of offshore wind farm, especially from the following points: monitoring of "offshore wind power engineering & biological & environment", the monitoring of power equipment and the operation & maintenance of smart offshore wind farms. Finally, the future research challenges about monitoring, operation and maintenance of smart offshore wind farm are proposed, and the future research directions in this field are prospected.
* accepted by Sensors
GammaE: Gamma Embeddings for Logical Queries on Knowledge Graphs
Oct 27, 2022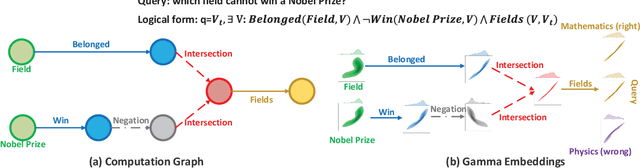

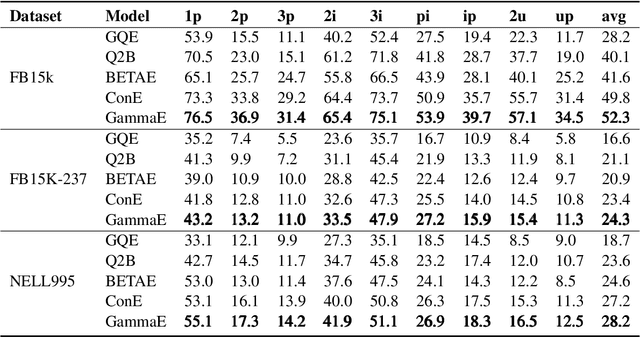
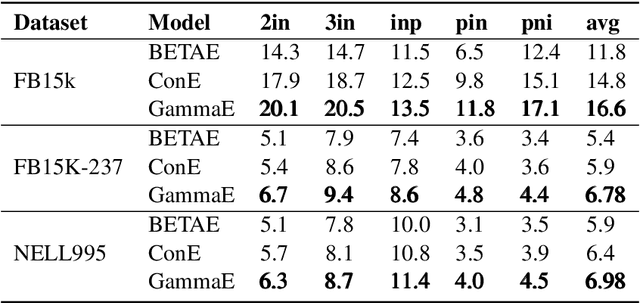
Embedding knowledge graphs (KGs) for multi-hop logical reasoning is a challenging problem due to massive and complicated structures in many KGs. Recently, many promising works projected entities and queries into a geometric space to efficiently find answers. However, it remains challenging to model the negation and union operator. The negation operator has no strict boundaries, which generates overlapped embeddings and leads to obtaining ambiguous answers. An additional limitation is that the union operator is non-closure, which undermines the model to handle a series of union operators. To address these problems, we propose a novel probabilistic embedding model, namely Gamma Embeddings (GammaE), for encoding entities and queries to answer different types of FOL queries on KGs. We utilize the linear property and strong boundary support of the Gamma distribution to capture more features of entities and queries, which dramatically reduces model uncertainty. Furthermore, GammaE implements the Gamma mixture method to design the closed union operator. The performance of GammaE is validated on three large logical query datasets. Experimental results show that GammaE significantly outperforms state-of-the-art models on public benchmarks.
Self-supervised Graph-based Point-of-interest Recommendation
Oct 22, 2022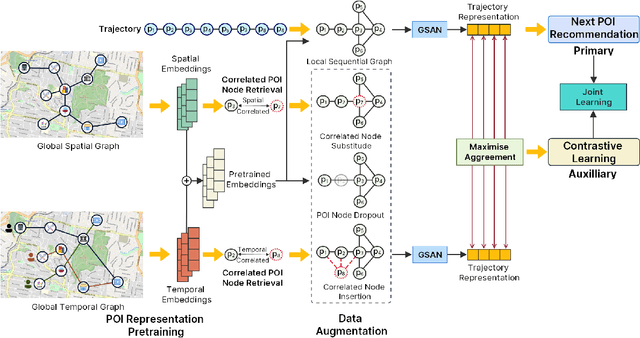

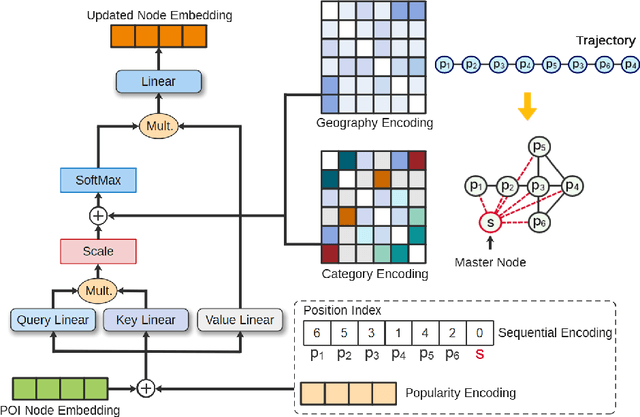
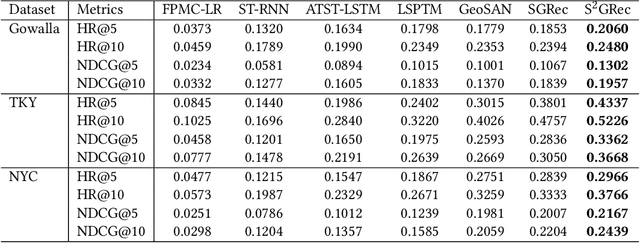
The exponential growth of Location-based Social Networks (LBSNs) has greatly stimulated the demand for precise location-based recommendation services. Next Point-of-Interest (POI) recommendation, which aims to provide personalised POI suggestions for users based on their visiting histories, has become a prominent component in location-based e-commerce. Recent POI recommenders mainly employ self-attention mechanism or graph neural networks to model complex high-order POI-wise interactions. However, most of them are merely trained on the historical check-in data in a standard supervised learning manner, which fail to fully explore each user's multi-faceted preferences, and suffer from data scarcity and long-tailed POI distribution, resulting in sub-optimal performance. To this end, we propose a Self-s}upervised Graph-enhanced POI Recommender (S2GRec) for next POI recommendation. In particular, we devise a novel Graph-enhanced Self-attentive layer to incorporate the collaborative signals from both global transition graph and local trajectory graphs to uncover the transitional dependencies among POIs and capture a user's temporal interests. In order to counteract the scarcity and incompleteness of POI check-ins, we propose a novel self-supervised learning paradigm in \ssgrec, where the trajectory representations are contrastively learned from two augmented views on geolocations and temporal transitions. Extensive experiments are conducted on three real-world LBSN datasets, demonstrating the effectiveness of our model against state-of-the-art methods.
Understanding Embodied Reference with Touch-Line Transformer
Oct 12, 2022
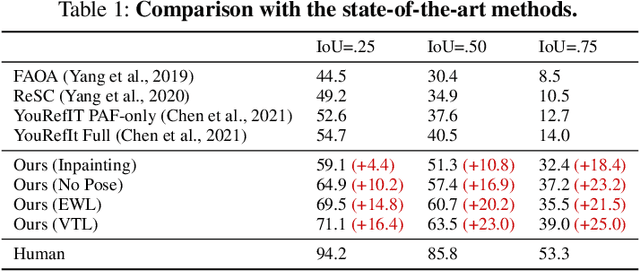
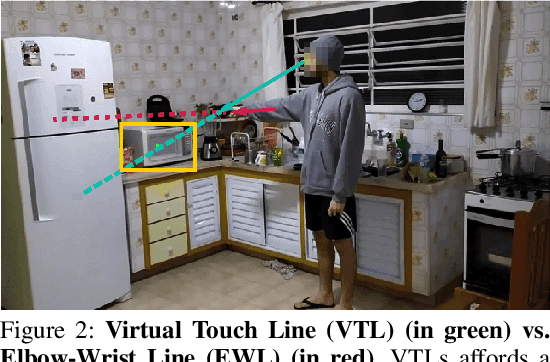
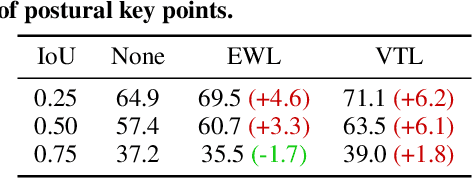
We study embodied reference understanding, the task of locating referents using embodied gestural signals and language references. Human studies have revealed that objects referred to or pointed to do not lie on the elbow-wrist line, a common misconception; instead, they lie on the so-called virtual touch line. However, existing human pose representations fail to incorporate the virtual touch line. To tackle this problem, we devise the touch-line transformer: It takes as input tokenized visual and textual features and simultaneously predicts the referent's bounding box and a touch-line vector. Leveraging this touch-line prior, we further devise a geometric consistency loss that encourages the co-linearity between referents and touch lines. Using the touch-line as gestural information improves model performances significantly. Experiments on the YouRefIt dataset show our method achieves a +25.0% accuracy improvement under the 0.75 IoU criterion, closing 63.6% of the gap between model and human performances. Furthermore, we computationally verify prior human studies by showing that computational models more accurately locate referents when using the virtual touch line than when using the elbow-wrist line.
Contrastive Bayesian Analysis for Deep Metric Learning
Oct 10, 2022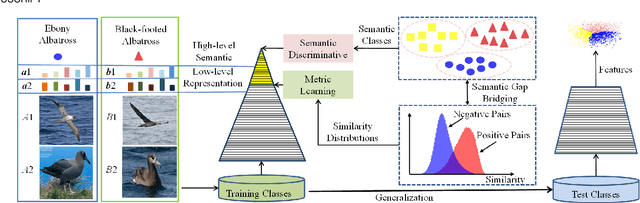
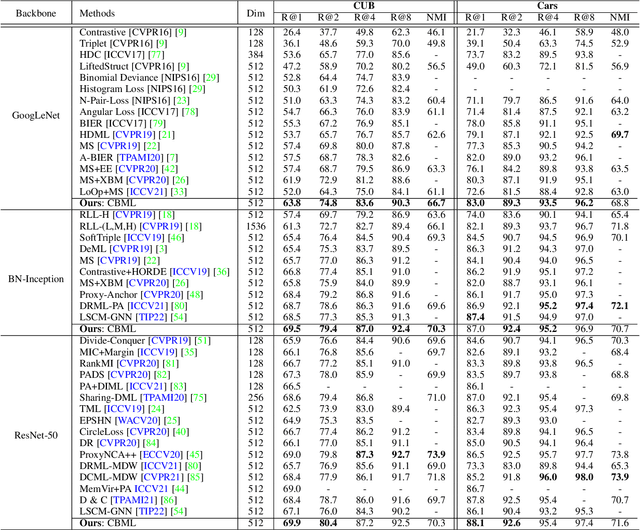
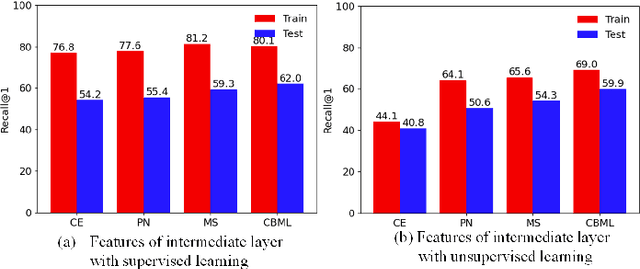
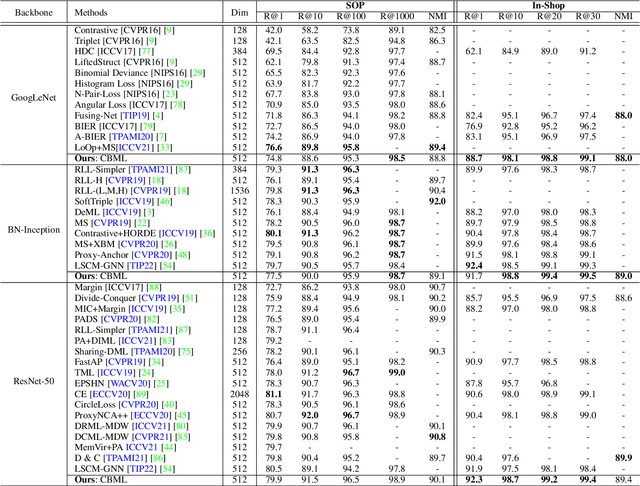
Recent methods for deep metric learning have been focusing on designing different contrastive loss functions between positive and negative pairs of samples so that the learned feature embedding is able to pull positive samples of the same class closer and push negative samples from different classes away from each other. In this work, we recognize that there is a significant semantic gap between features at the intermediate feature layer and class labels at the final output layer. To bridge this gap, we develop a contrastive Bayesian analysis to characterize and model the posterior probabilities of image labels conditioned by their features similarity in a contrastive learning setting. This contrastive Bayesian analysis leads to a new loss function for deep metric learning. To improve the generalization capability of the proposed method onto new classes, we further extend the contrastive Bayesian loss with a metric variance constraint. Our experimental results and ablation studies demonstrate that the proposed contrastive Bayesian metric learning method significantly improves the performance of deep metric learning in both supervised and pseudo-supervised scenarios, outperforming existing methods by a large margin.
Asynchronous Activity Detection for Cell-Free Massive MIMO: From Centralized to Distributed Algorithms
Oct 02, 2022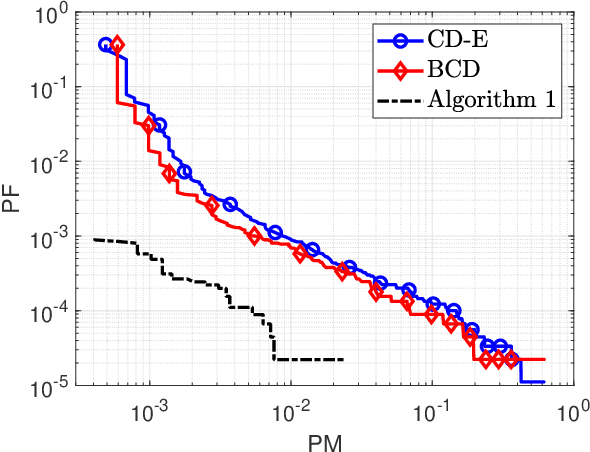

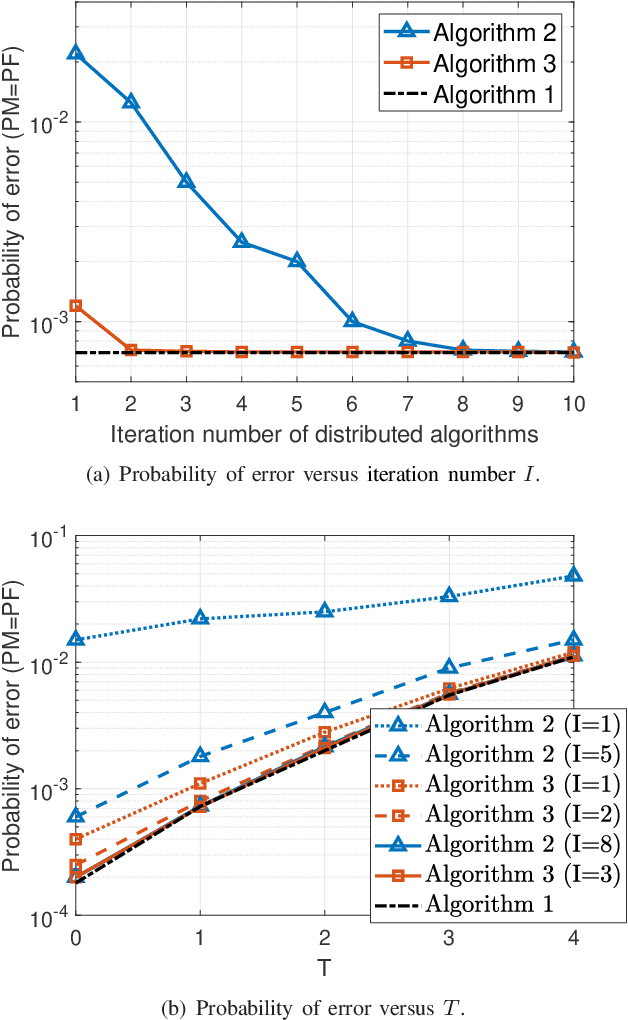
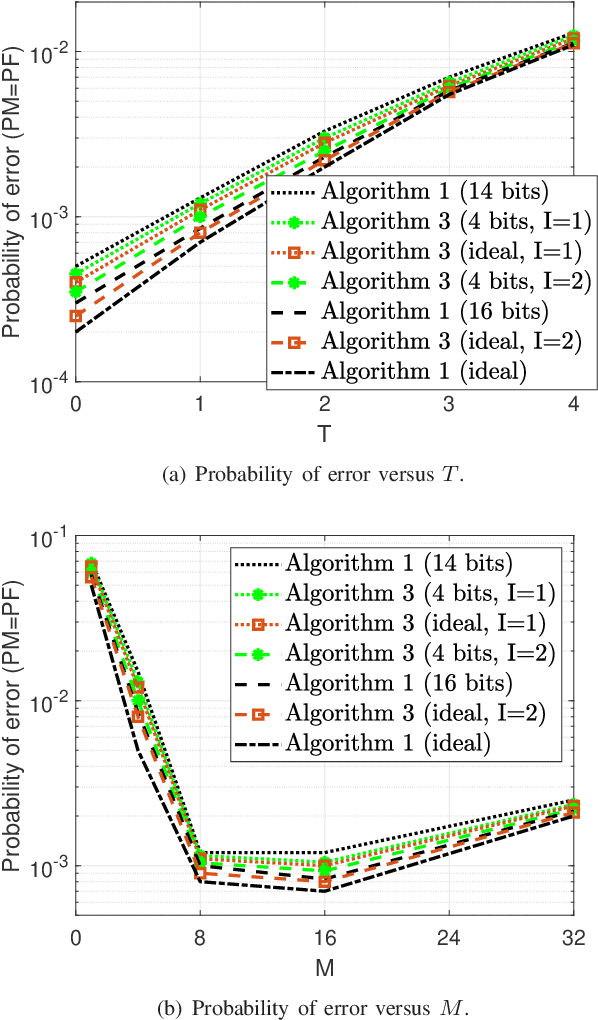
Device activity detection in the emerging cell-free massive multiple-input multiple-output (MIMO) systems has been recognized as a crucial task in machine-type communications, in which multiple access points (APs) jointly identify the active devices from a large number of potential devices based on the received signals. Most of the existing works addressing this problem rely on the impractical assumption that different active devices transmit signals synchronously. However, in practice, synchronization cannot be guaranteed due to the low-cost oscillators, which brings additional discontinuous and nonconvex constraints to the detection problem. To address this challenge, this paper reveals an equivalent reformulation to the asynchronous activity detection problem, which facilitates the development of a centralized algorithm and a distributed algorithm that satisfy the highly nonconvex constraints in a gentle fashion as the iteration number increases, so that the sequence generated by the proposed algorithms can get around bad stationary points. To reduce the capacity requirements of the fronthauls, we further design a communication-efficient accelerated distributed algorithm. Simulation results demonstrate that the proposed centralized and distributed algorithms outperform state-of-the-art approaches, and the proposed accelerated distributed algorithm achieves a close detection performance to that of the centralized algorithm but with a much smaller number of bits to be transmitted on the fronthaul links.
MUG: Interactive Multimodal Grounding on User Interfaces
Sep 29, 2022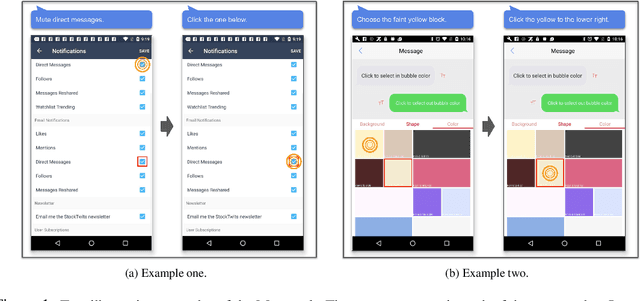
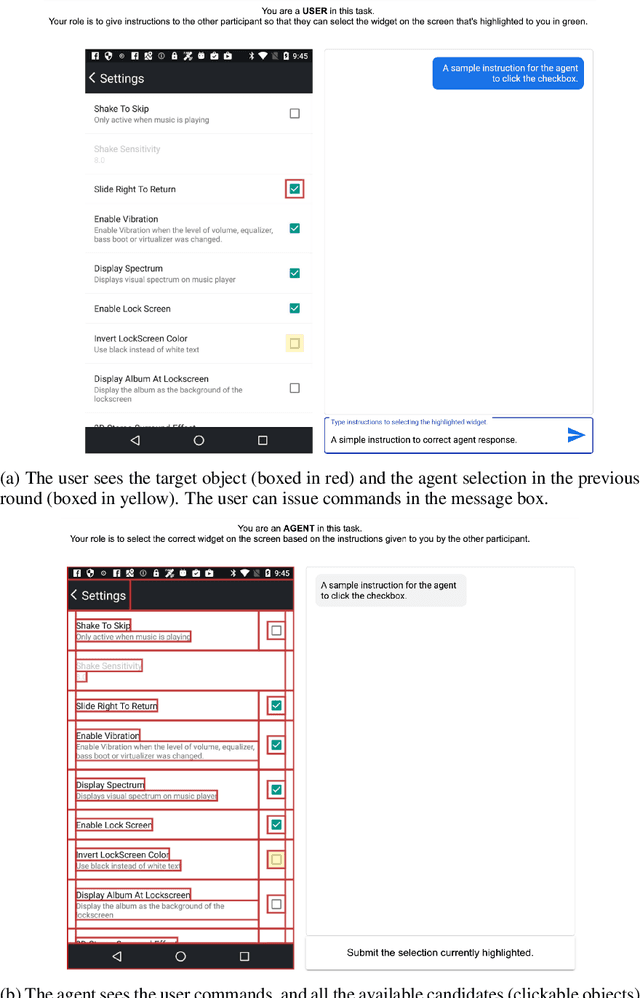
We present MUG, a novel interactive task for multimodal grounding where a user and an agent work collaboratively on an interface screen. Prior works modeled multimodal UI grounding in one round: the user gives a command and the agent responds to the command. Yet, in a realistic scenario, a user command can be ambiguous when the target action is inherently difficult to articulate in natural language. MUG allows multiple rounds of interactions such that upon seeing the agent responses, the user can give further commands for the agent to refine or even correct its actions. Such interaction is critical for improving grounding performances in real-world use cases. To investigate the problem, we create a new dataset that consists of 77,820 sequences of human user-agent interaction on mobile interfaces in which 20% involves multiple rounds of interactions. To establish our benchmark, we experiment with a range of modeling variants and evaluation strategies, including both offline and online evaluation-the online strategy consists of both human evaluation and automatic with simulators. Our experiments show that allowing iterative interaction significantly improves the absolute task completion by 18% over the entire test dataset and 31% over the challenging subset. Our results lay the foundation for further investigation of the problem.
Spotlight: Mobile UI Understanding using Vision-Language Models with a Focus
Sep 29, 2022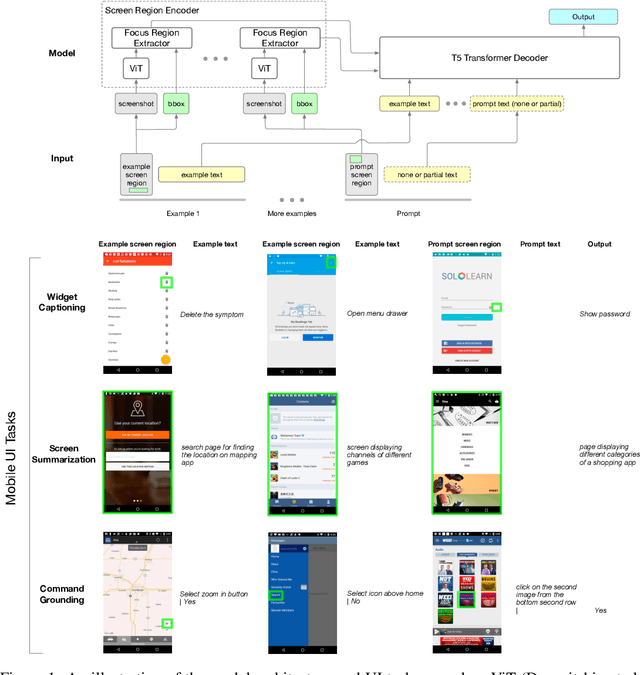

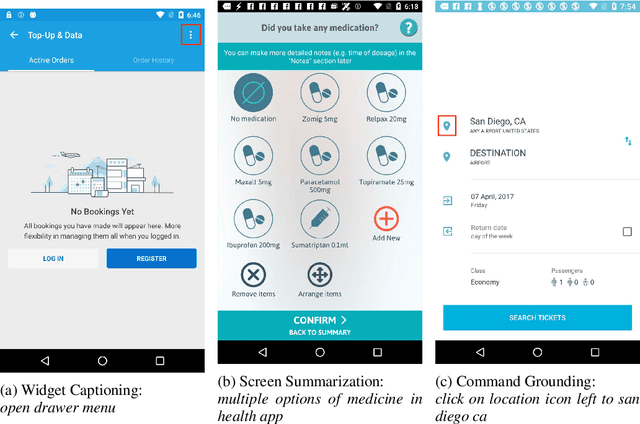

Mobile UI understanding is important for enabling various interaction tasks such as UI automation and accessibility. Previous mobile UI modeling often depends on the view hierarchy information of a screen, which directly provides the structural data of the UI, with the hope to bypass challenging tasks of visual modeling from screen pixels. However, view hierarchy is not always available, and is often corrupted with missing object descriptions or misaligned bounding box positions. As a result, although using view hierarchy offers some short-term gains, it may ultimately hinder the applicability and performance of the model. In this paper, we propose Spotlight, a vision-only approach for mobile UI understanding. Specifically, we enhance a vision-language model that only takes the screenshot of the UI and a region of interest on the screen -- the focus -- as the input. This general architecture is easily scalable and capable of performing a range of UI modeling tasks. Our experiments show that our model obtains SoTA results on several representative UI tasks and outperforms previous methods that use both screenshots and view hierarchies as input. Furthermore, we explore the multi-task learning and few-shot prompting capacity of the proposed models, demonstrating promising results in the multi-task learning direction.