 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYan Xia
Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models
Apr 04, 2024
Large language models (LLMs) have exhibited impressive performance in language comprehension and various reasoning tasks. However, their abilities in spatial reasoning, a crucial aspect of human cognition, remain relatively unexplored. Human possess a remarkable ability to create mental images of unseen objects and actions through a process known as \textbf{the Mind's Eye}, enabling the imagination of the unseen world. Inspired by this cognitive capacity, we propose Visualization-of-Thought (\textbf{VoT}) prompting. VoT aims to elicit spatial reasoning of LLMs by visualizing their reasoning traces, thereby guiding subsequent reasoning steps. We employed VoT for multi-hop spatial reasoning tasks, including natural language navigation, visual navigation, and visual tiling in 2D grid worlds. Experimental results demonstrated that VoT significantly enhances the spatial reasoning abilities of LLMs. Notably, VoT outperformed existing multimodal large language models (MLLMs) in these tasks. While VoT works surprisingly well on LLMs, the ability to generate \textit{mental images} to facilitate spatial reasoning resembles the mind's eye process, suggesting its potential viability in MLLMs.
LLM as a Mastermind: A Survey of Strategic Reasoning with Large Language Models
Apr 01, 2024This paper presents a comprehensive survey of the current status and opportunities for Large Language Models (LLMs) in strategic reasoning, a sophisticated form of reasoning that necessitates understanding and predicting adversary actions in multi-agent settings while adjusting strategies accordingly. Strategic reasoning is distinguished by its focus on the dynamic and uncertain nature of interactions among multi-agents, where comprehending the environment and anticipating the behavior of others is crucial. We explore the scopes, applications, methodologies, and evaluation metrics related to strategic reasoning with LLMs, highlighting the burgeoning development in this area and the interdisciplinary approaches enhancing their decision-making performance. It aims to systematize and clarify the scattered literature on this subject, providing a systematic review that underscores the importance of strategic reasoning as a critical cognitive capability and offers insights into future research directions and potential improvements.
VXP: Voxel-Cross-Pixel Large-scale Image-LiDAR Place Recognition
Mar 21, 2024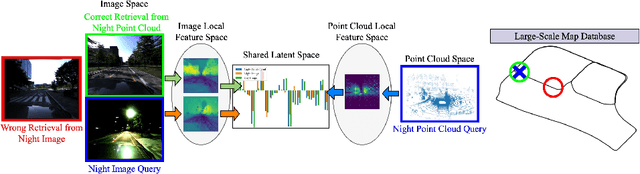

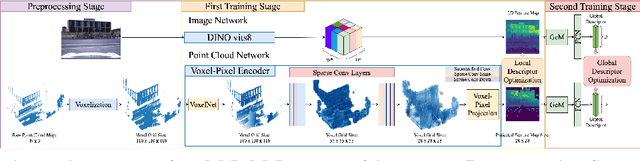
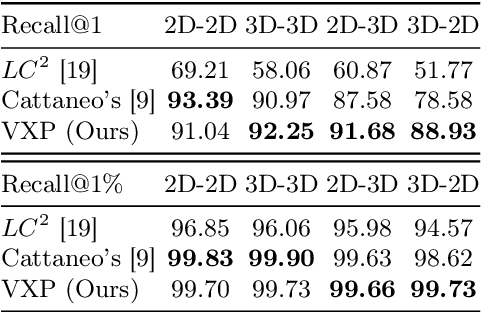
Recent works on the global place recognition treat the task as a retrieval problem, where an off-the-shelf global descriptor is commonly designed in image-based and LiDAR-based modalities. However, it is non-trivial to perform accurate image-LiDAR global place recognition since extracting consistent and robust global descriptors from different domains (2D images and 3D point clouds) is challenging. To address this issue, we propose a novel Voxel-Cross-Pixel (VXP) approach, which establishes voxel and pixel correspondences in a self-supervised manner and brings them into a shared feature space. Specifically, VXP is trained in a two-stage manner that first explicitly exploits local feature correspondences and enforces similarity of global descriptors. Extensive experiments on the three benchmarks (Oxford RobotCar, ViViD++ and KITTI) demonstrate our method surpasses the state-of-the-art cross-modal retrieval by a large margin.
Unlocking the Potential of Multimodal Unified Discrete Representation through Training-Free Codebook Optimization and Hierarchical Alignment
Mar 08, 2024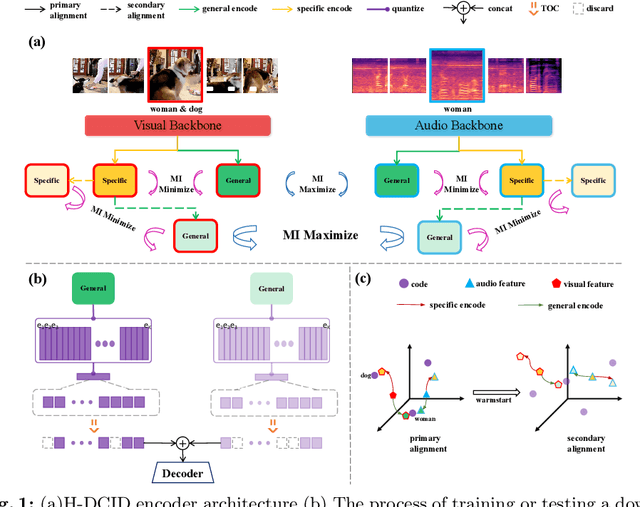
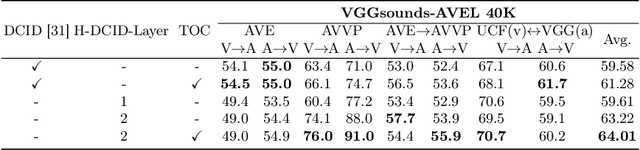
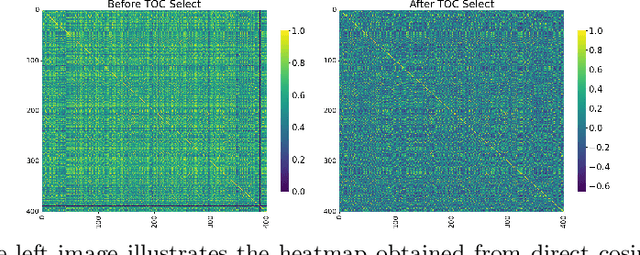
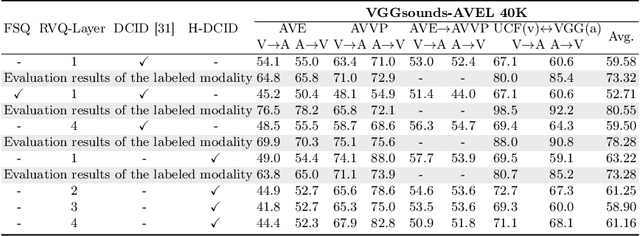
Recent advances in representation learning have demonstrated the significance of multimodal alignment. The Dual Cross-modal Information Disentanglement (DCID) model, utilizing a unified codebook, shows promising results in achieving fine-grained representation and cross-modal generalization. However, it is still hindered by equal treatment of all channels and neglect of minor event information, resulting in interference from irrelevant channels and limited performance in fine-grained tasks. Thus, in this work, We propose a Training-free Optimization of Codebook (TOC) method to enhance model performance by selecting important channels in the unified space without retraining. Additionally, we introduce the Hierarchical Dual Cross-modal Information Disentanglement (H-DCID) approach to extend information separation and alignment to two levels, capturing more cross-modal details. The experiment results demonstrate significant improvements across various downstream tasks, with TOC contributing to an average improvement of 1.70% for DCID on four tasks, and H-DCID surpassing DCID by an average of 3.64%. The combination of TOC and H-DCID further enhances performance, exceeding DCID by 4.43%. These findings highlight the effectiveness of our methods in facilitating robust and nuanced cross-modal learning, opening avenues for future enhancements. The source code and pre-trained models can be accessed at https://github.com/haihuangcode/TOC_H-DCID.
GS-EMA: Integrating Gradient Surgery Exponential Moving Average with Boundary-Aware Contrastive Learning for Enhanced Domain Generalization in Aneurysm Segmentation
Feb 23, 2024The automated segmentation of cerebral aneurysms is pivotal for accurate diagnosis and treatment planning. Confronted with significant domain shifts and class imbalance in 3D Rotational Angiography (3DRA) data from various medical institutions, the task becomes challenging. These shifts include differences in image appearance, intensity distribution, resolution, and aneurysm size, all of which complicate the segmentation process. To tackle these issues, we propose a novel domain generalization strategy that employs gradient surgery exponential moving average (GS-EMA) optimization technique coupled with boundary-aware contrastive learning (BACL). Our approach is distinct in its ability to adapt to new, unseen domains by learning domain-invariant features, thereby improving the robustness and accuracy of aneurysm segmentation across diverse clinical datasets. The results demonstrate that our proposed approach can extract more domain-invariant features, minimizing over-segmentation and capturing more complete aneurysm structures.
Unsupervised Domain Adaptation for Brain Vessel Segmentation through Transwarp Contrastive Learning
Feb 23, 2024Unsupervised domain adaptation (UDA) aims to align the labelled source distribution with the unlabelled target distribution to obtain domain-invariant predictive models. Since cross-modality medical data exhibit significant intra and inter-domain shifts and most are unlabelled, UDA is more important while challenging in medical image analysis. This paper proposes a simple yet potent contrastive learning framework for UDA to narrow the inter-domain gap between labelled source and unlabelled target distribution. Our method is validated on cerebral vessel datasets. Experimental results show that our approach can learn latent features from labelled 3DRA modality data and improve vessel segmentation performance in unlabelled MRA modality data.
K-Level Reasoning with Large Language Models
Feb 02, 2024While Large Language Models (LLMs) have demonstrated their proficiency in complex reasoning tasks, their performance in dynamic, interactive, and competitive scenarios - such as business strategy and stock market analysis - remains underexplored. To bridge this gap, we formally explore the dynamic reasoning capabilities of LLMs for decision-making in rapidly evolving environments. We introduce two game theory-based pilot challenges that mirror the complexities of real-world dynamic decision-making. These challenges are well-defined, enabling clear, controllable, and precise evaluation of LLMs' dynamic reasoning abilities. Through extensive experiments, we find that existing reasoning methods tend to falter in dynamic settings that require k-level thinking - a key concept not tackled by previous works. To address this, we propose a novel reasoning approach for LLMs, named "K-Level Reasoning". This approach adopts the perspective of rivals to recursively employ k-level thinking based on available historical information, which significantly improves the prediction accuracy of rivals' subsequent moves and informs more strategic decision-making. This research not only sets a robust quantitative benchmark for the assessment of dynamic reasoning but also markedly enhances the proficiency of LLMs in dynamic contexts.
StyleSinger: Style Transfer for Out-of-Domain Singing Voice Synthesis
Jan 02, 2024Style transfer for out-of-domain (OOD) singing voice synthesis (SVS) focuses on generating high-quality singing voices with unseen styles (such as timbre, emotion, pronunciation, and articulation skills) derived from reference singing voice samples. However, the endeavor to model the intricate nuances of singing voice styles is an arduous task, as singing voices possess a remarkable degree of expressiveness. Moreover, existing SVS methods encounter a decline in the quality of synthesized singing voices in OOD scenarios, as they rest upon the assumption that the target vocal attributes are discernible during the training phase. To overcome these challenges, we propose StyleSinger, the first singing voice synthesis model for zero-shot style transfer of out-of-domain reference singing voice samples. StyleSinger incorporates two critical approaches for enhanced effectiveness: 1) the Residual Style Adaptor (RSA) which employs a residual quantization module to capture diverse style characteristics in singing voices, and 2) the Uncertainty Modeling Layer Normalization (UMLN) to perturb the style attributes within the content representation during the training phase and thus improve the model generalization. Our extensive evaluations in zero-shot style transfer undeniably establish that StyleSinger outperforms baseline models in both audio quality and similarity to the reference singing voice samples. Access to singing voice samples can be found at https://stylesinger.github.io/.
Multi-Modal Domain Adaptation Across Video Scenes for Temporal Video Grounding
Dec 21, 2023Temporal Video Grounding (TVG) aims to localize the temporal boundary of a specific segment in an untrimmed video based on a given language query. Since datasets in this domain are often gathered from limited video scenes, models tend to overfit to scene-specific factors, which leads to suboptimal performance when encountering new scenes in real-world applications. In a new scene, the fine-grained annotations are often insufficient due to the expensive labor cost, while the coarse-grained video-query pairs are easier to obtain. Thus, to address this issue and enhance model performance on new scenes, we explore the TVG task in an unsupervised domain adaptation (UDA) setting across scenes for the first time, where the video-query pairs in the source scene (domain) are labeled with temporal boundaries, while those in the target scene are not. Under the UDA setting, we introduce a novel Adversarial Multi-modal Domain Adaptation (AMDA) method to adaptively adjust the model's scene-related knowledge by incorporating insights from the target data. Specifically, we tackle the domain gap by utilizing domain discriminators, which help identify valuable scene-related features effective across both domains. Concurrently, we mitigate the semantic gap between different modalities by aligning video-query pairs with related semantics. Furthermore, we employ a mask-reconstruction approach to enhance the understanding of temporal semantics within a scene. Extensive experiments on Charades-STA, ActivityNet Captions, and YouCook2 demonstrate the effectiveness of our proposed method.
StyleSinger: Style Transfer for Out-Of-Domain Singing Voice Synthesis
Dec 17, 2023Style transfer for out-of-domain (OOD) singing voice synthesis (SVS) focuses on generating high-quality singing voices with unseen styles (such as timbre, emotion, pronunciation, and articulation skills) derived from reference singing voice samples. However, the endeavor to model the intricate nuances of singing voice styles is an arduous task, as singing voices possess a remarkable degree of expressiveness. Moreover, existing SVS methods encounter a decline in the quality of synthesized singing voices in OOD scenarios, as they rest upon the assumption that the target vocal attributes are discernible during the training phase. To overcome these challenges, we propose StyleSinger, the first singing voice synthesis model for zero-shot style transfer of out-of-domain reference singing voice samples. StyleSinger incorporates two critical approaches for enhanced effectiveness: 1) the Residual Style Adaptor (RSA) which employs a residual quantization module to capture diverse style characteristics in singing voices, and 2) the Uncertainty Modeling Layer Normalization (UMLN) to perturb the style attributes within the content representation during the training phase and thus improve the model generalization. Our extensive evaluations in zero-shot style transfer undeniably establish that StyleSinger outperforms baseline models in both audio quality and similarity to the reference singing voice samples. Access to singing voice samples can be found at https://stylesinger.github.io/.