 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXueqian Wang
The Road to On-board Change Detection: A Lightweight Patch-Level Change Detection Network via Exploring the Potential of Pruning and Pooling
Oct 16, 2023
Existing satellite remote sensing change detection (CD) methods often crop original large-scale bi-temporal image pairs into small patch pairs and then use pixel-level CD methods to fairly process all the patch pairs. However, due to the sparsity of change in large-scale satellite remote sensing images, existing pixel-level CD methods suffer from a waste of computational cost and memory resources on lots of unchanged areas, which reduces the processing efficiency of on-board platform with extremely limited computation and memory resources. To address this issue, we propose a lightweight patch-level CD network (LPCDNet) to rapidly remove lots of unchanged patch pairs in large-scale bi-temporal image pairs. This is helpful to accelerate the subsequent pixel-level CD processing stage and reduce its memory costs. In our LPCDNet, a sensitivity-guided channel pruning method is proposed to remove unimportant channels and construct the lightweight backbone network on basis of ResNet18 network. Then, the multi-layer feature compression (MLFC) module is designed to compress and fuse the multi-level feature information of bi-temporal image patch. The output of MLFC module is fed into the fully-connected decision network to generate the predicted binary label. Finally, a weighted cross-entropy loss is utilized in the training process of network to tackle the change/unchange class imbalance problem. Experiments on two CD datasets demonstrate that our LPCDNet achieves more than 1000 frames per second on an edge computation platform, i.e., NVIDIA Jetson AGX Orin, which is more than 3 times that of the existing methods without noticeable CD performance loss. In addition, our method reduces more than 60% memory costs of the subsequent pixel-level CD processing stage.
Revisiting Plasticity in Visual Reinforcement Learning: Data, Modules and Training Stages
Oct 11, 2023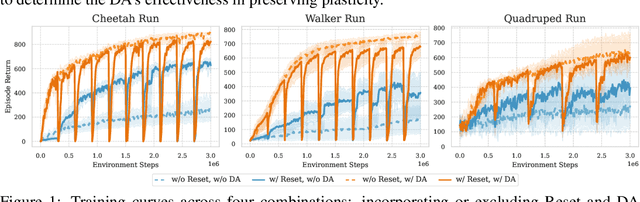
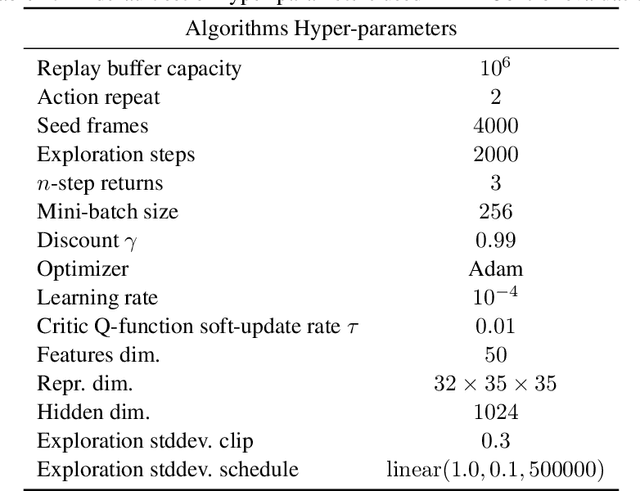
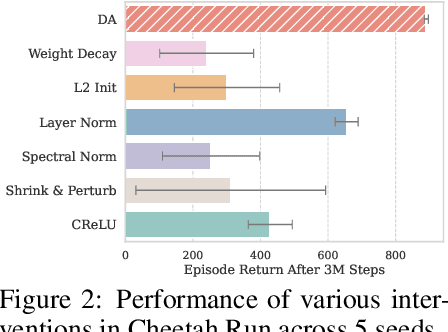
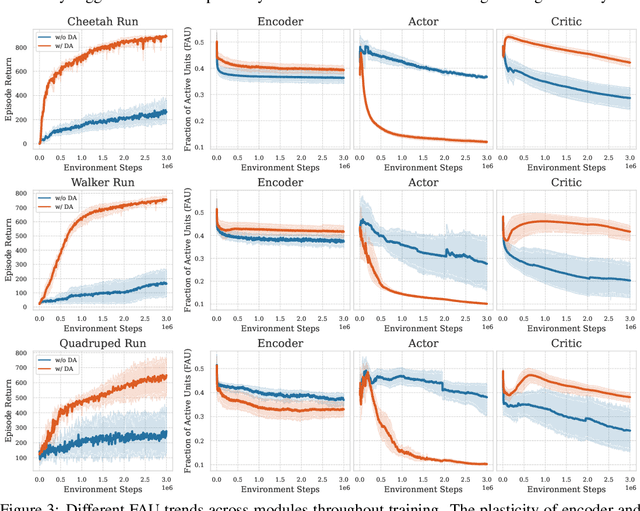
Plasticity, the ability of a neural network to evolve with new data, is crucial for high-performance and sample-efficient visual reinforcement learning (VRL). Although methods like resetting and regularization can potentially mitigate plasticity loss, the influences of various components within the VRL framework on the agent's plasticity are still poorly understood. In this work, we conduct a systematic empirical exploration focusing on three primary underexplored facets and derive the following insightful conclusions: (1) data augmentation is essential in maintaining plasticity; (2) the critic's plasticity loss serves as the principal bottleneck impeding efficient training; and (3) without timely intervention to recover critic's plasticity in the early stages, its loss becomes catastrophic. These insights suggest a novel strategy to address the high replay ratio (RR) dilemma, where exacerbated plasticity loss hinders the potential improvements of sample efficiency brought by increased reuse frequency. Rather than setting a static RR for the entire training process, we propose Adaptive RR, which dynamically adjusts the RR based on the critic's plasticity level. Extensive evaluations indicate that Adaptive RR not only avoids catastrophic plasticity loss in the early stages but also benefits from more frequent reuse in later phases, resulting in superior sample efficiency.
DiffCPS: Diffusion Model based Constrained Policy Search for Offline Reinforcement Learning
Oct 09, 2023Constrained policy search (CPS) is a fundamental problem in offline reinforcement learning, which is generally solved by advantage weighted regression (AWR). However, previous methods may still encounter out-of-distribution actions due to the limited expressivity of Gaussian-based policies. On the other hand, directly applying the state-of-the-art models with distribution expression capabilities (i.e., diffusion models) in the AWR framework is insufficient since AWR requires exact policy probability densities, which is intractable in diffusion models. In this paper, we propose a novel approach called $\textbf{Diffusion Model based Constrained Policy Search (DiffCPS)}$, which tackles the diffusion-based constrained policy search without resorting to AWR. The theoretical analysis reveals our key insights by leveraging the action distribution of the diffusion model to eliminate the policy distribution constraint in the CPS and then utilizing the Evidence Lower Bound (ELBO) of diffusion-based policy to approximate the KL constraint. Consequently, DiffCPS admits the high expressivity of diffusion models while circumventing the cumbersome density calculation brought by AWR. Extensive experimental results based on the D4RL benchmark demonstrate the efficacy of our approach. We empirically show that DiffCPS achieves better or at least competitive performance compared to traditional AWR-based baselines as well as recent diffusion-based offline RL methods. The code is now available at $\href{https://github.com/felix-thu/DiffCPS}{https://github.com/felix-thu/DiffCPS}$.
Efficient Federated Prompt Tuning for Black-box Large Pre-trained Models
Oct 04, 2023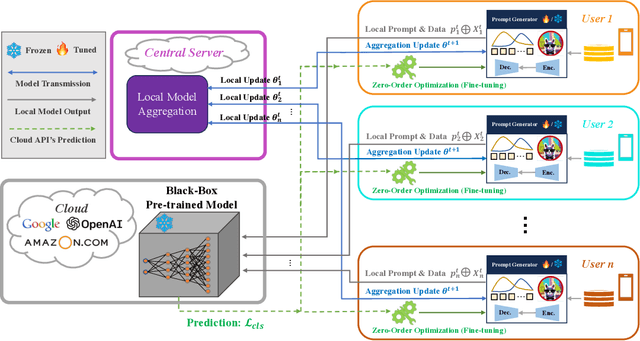

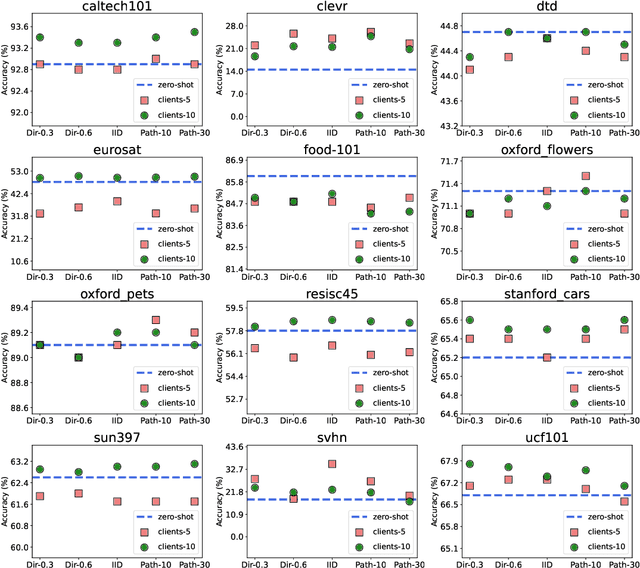
With the blowout development of pre-trained models (PTMs), the efficient tuning of these models for diverse downstream applications has emerged as a pivotal research concern. Although recent investigations into prompt tuning have provided promising avenues, three salient challenges persist: (1) memory constraint: the continuous growth in the size of open-source PTMs renders fine-tuning, even a fraction of their parameters, challenging for many practitioners. (2) model privacy: existing PTMs often function as public API services, with their parameters inaccessible for effective or tailored fine-tuning. (3) data privacy: the fine-tuning of PTMs necessitates high-quality datasets, which are typically localized and not shared to public. To optimally harness each local dataset while navigating memory constraints and preserving privacy, we propose Federated Black-Box Prompt Tuning (Fed-BBPT). This innovative approach eschews reliance on parameter architectures and private dataset access, instead capitalizing on a central server that aids local users in collaboratively training a prompt generator through regular aggregation. Local users leverage API-driven learning via a zero-order optimizer, obviating the need for PTM deployment. Relative to extensive fine-tuning, Fed-BBPT proficiently sidesteps memory challenges tied to PTM storage and fine-tuning on local machines, tapping into comprehensive, high-quality, yet private training datasets. A thorough evaluation across 40 datasets spanning CV and NLP tasks underscores the robustness of our proposed model.
Are Large Language Models Really Robust to Word-Level Perturbations?
Sep 27, 2023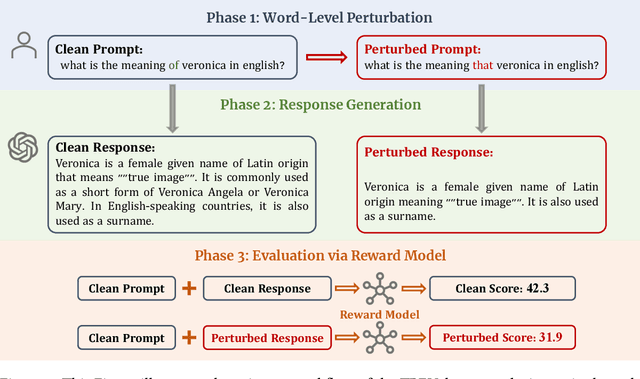


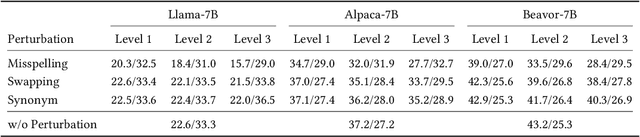
The swift advancement in the scales and capabilities of Large Language Models (LLMs) positions them as promising tools for a variety of downstream tasks. In addition to the pursuit of better performance and the avoidance of violent feedback on a certain prompt, to ensure the responsibility of the LLM, much attention is drawn to the robustness of LLMs. However, existing evaluation methods mostly rely on traditional question answering datasets with predefined supervised labels, which do not align with the superior generation capabilities of contemporary LLMs. To address this issue, we propose a novel rational evaluation approach that leverages pre-trained reward models as diagnostic tools to evaluate the longer conversation generated from more challenging open questions by LLMs, which we refer to as the Reward Model for Reasonable Robustness Evaluation (TREvaL). Longer conversations manifest the comprehensive grasp of language models in terms of their proficiency in understanding questions, a capability not entirely encompassed by individual words or letters, which may exhibit oversimplification and inherent biases. Our extensive empirical experiments demonstrate that TREvaL provides an innovative method for evaluating the robustness of an LLM. Furthermore, our results demonstrate that LLMs frequently exhibit vulnerability to word-level perturbations that are commonplace in daily language usage. Notably, we are surprised to discover that robustness tends to decrease as fine-tuning (SFT and RLHF) is conducted. The code of TREval is available in https://github.com/Harry-mic/TREvaL.
Differentiable Frank-Wolfe Optimization Layer
Aug 21, 2023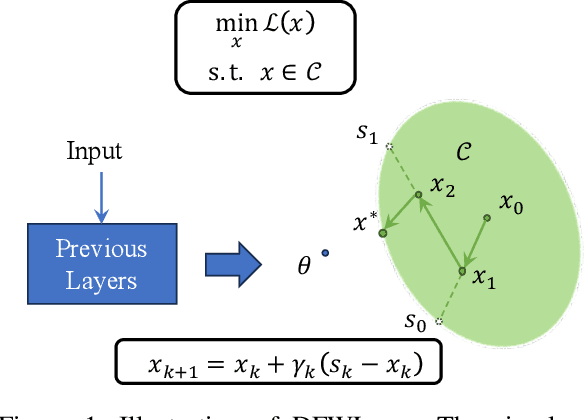
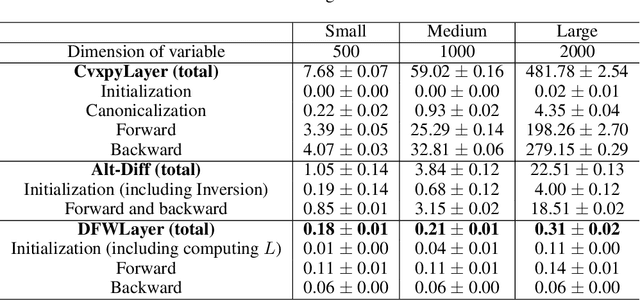

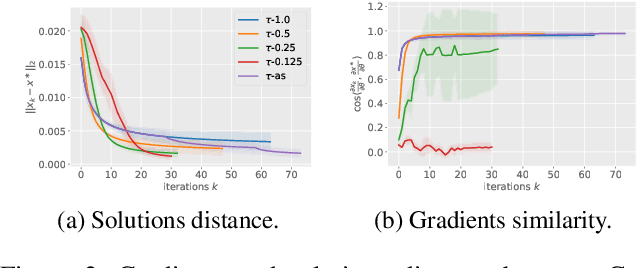
Differentiable optimization has received a significant amount of attention due to its foundational role in the domain of machine learning based on neural networks. The existing methods leverages the optimality conditions and implicit function theorem to obtain the Jacobian matrix of the output, which increases the computational cost and limits the application of differentiable optimization. In addition, some non-differentiable constraints lead to more challenges when using prior differentiable optimization layers. This paper proposes a differentiable layer, named Differentiable Frank-Wolfe Layer (DFWLayer), by rolling out the Frank-Wolfe method, a well-known optimization algorithm which can solve constrained optimization problems without projections and Hessian matrix computations, thus leading to a efficient way of dealing with large-scale problems. Theoretically, we establish a bound on the suboptimality gap of the DFWLayer in the context of l1-norm constraints. Experimental assessments demonstrate that the DFWLayer not only attains competitive accuracy in solutions and gradients but also consistently adheres to constraints. Moreover, it surpasses the baselines in both forward and backward computational speeds.
Path Generation for Wheeled Robots Autonomous Navigation on Vegetated Terrain
Jun 15, 2023
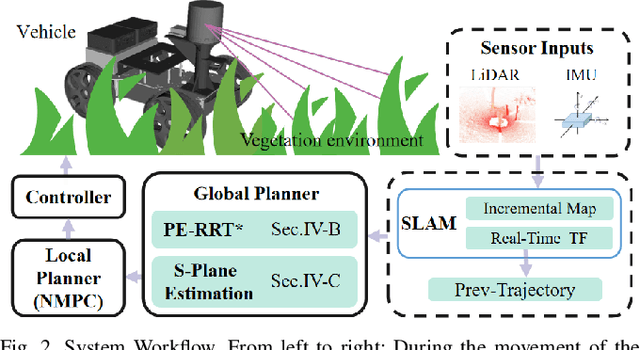
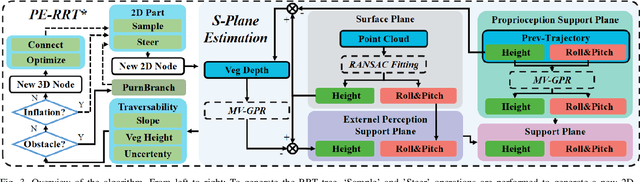
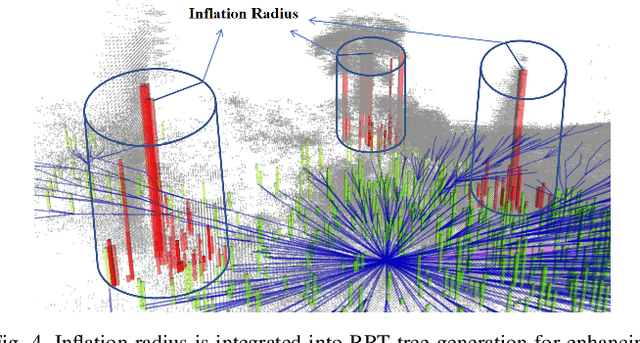
Wheeled robot navigation has been widely used in urban environments, but little research has been conducted on its navigation in wild vegetation. External sensors (LiDAR, camera etc.) are often used to construct point cloud map of the surrounding environment, however, the supporting rigid ground used for travelling cannot be detected due to the occlusion of vegetation. This often causes unsafe or not smooth path during planning process. To address the drawback, we propose the PE-RRT* algorithm, which effectively combines a novel support plane estimation method and sampling algorithm to generate real-time feasible and safe path in vegetation environments. In order to accurately estimate the support plane, we combine external perception and proprioception, and use Multivariate Gaussian Processe Regression (MV-GPR) to estimate the terrain at the sampling nodes. We build a physical experimental platform and conduct experiments in different outdoor environments. Experimental results show that our method has high safety, robustness and generalization.
Hybrid Trajectory Optimization for Autonomous Terrain Traversal of Articulated Tracked Robots
Jun 05, 2023

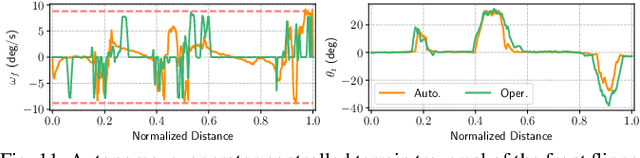
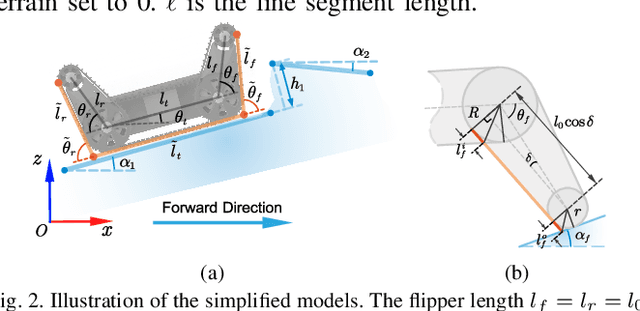
Autonomous terrain traversal of articulated tracked robots can reduce operator cognitive load to enhance task efficiency and facilitate extensive deployment. We present a novel hybrid trajectory optimization method aimed at generating smooth, stable, and efficient traversal motions. To achieve this, we develop a planar robot-terrain interaction model and partition the robot's motion into hybrid modes of driving and traversing. By using a generalized coordinate description, the configuration space dimension is reduced, which provides real-time planning capability. The hybrid trajectory optimization is transcribed into a nonlinear programming problem and solved in a receding-horizon planning fashion. Mode switching is facilitated by associating optimized motion durations with a predefined traversal sequence. A multi-objective cost function is formulated to further improve the traversal performance. Additionally, map sampling, terrain simplification, and tracking controller modules are integrated into the autonomous terrain traversal system. Our approach is validated in simulation and real-world experiments with the Searcher robotic platform, effectively achieving smooth and stable motion with high time and energy efficiency compared to expert operator control.
Learning Better with Less: Effective Augmentation for Sample-Efficient Visual Reinforcement Learning
May 25, 2023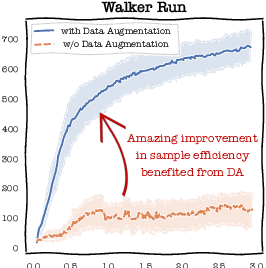
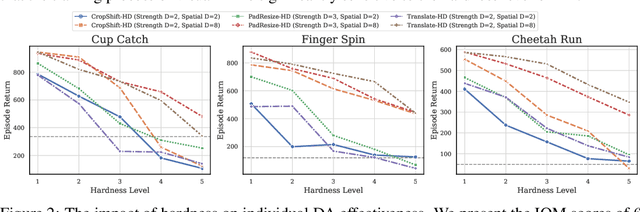
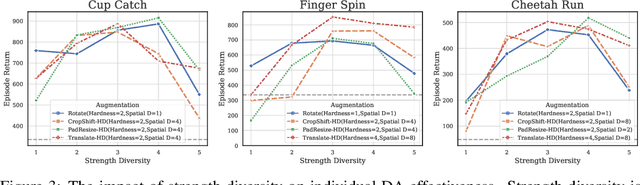
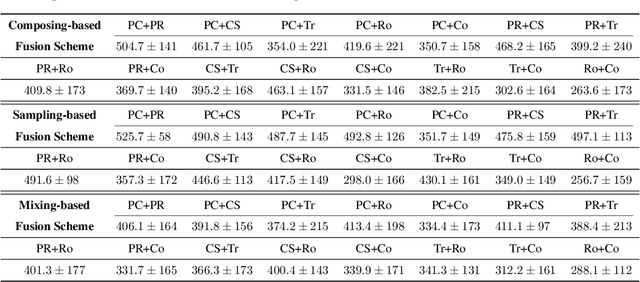
Data augmentation (DA) is a crucial technique for enhancing the sample efficiency of visual reinforcement learning (RL) algorithms. Notably, employing simple observation transformations alone can yield outstanding performance without extra auxiliary representation tasks or pre-trained encoders. However, it remains unclear which attributes of DA account for its effectiveness in achieving sample-efficient visual RL. To investigate this issue and further explore the potential of DA, this work conducts comprehensive experiments to assess the impact of DA's attributes on its efficacy and provides the following insights and improvements: (1) For individual DA operations, we reveal that both ample spatial diversity and slight hardness are indispensable. Building on this finding, we introduce Random PadResize (Rand PR), a new DA operation that offers abundant spatial diversity with minimal hardness. (2) For multi-type DA fusion schemes, the increased DA hardness and unstable data distribution result in the current fusion schemes being unable to achieve higher sample efficiency than their corresponding individual operations. Taking the non-stationary nature of RL into account, we propose a RL-tailored multi-type DA fusion scheme called Cycling Augmentation (CycAug), which performs periodic cycles of different DA operations to increase type diversity while maintaining data distribution consistency. Extensive evaluations on the DeepMind Control suite and CARLA driving simulator demonstrate that our methods achieve superior sample efficiency compared with the prior state-of-the-art methods.