 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXuanjing Huang
COLO: A Contrastive Learning based Re-ranking Framework for One-Stage Summarization
Sep 29, 2022

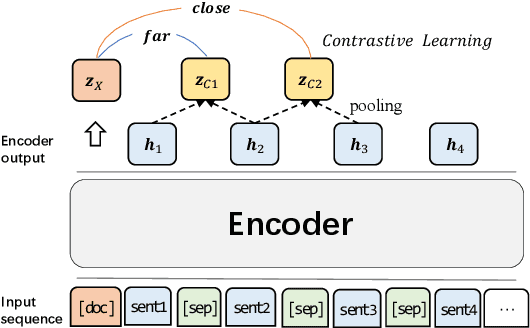
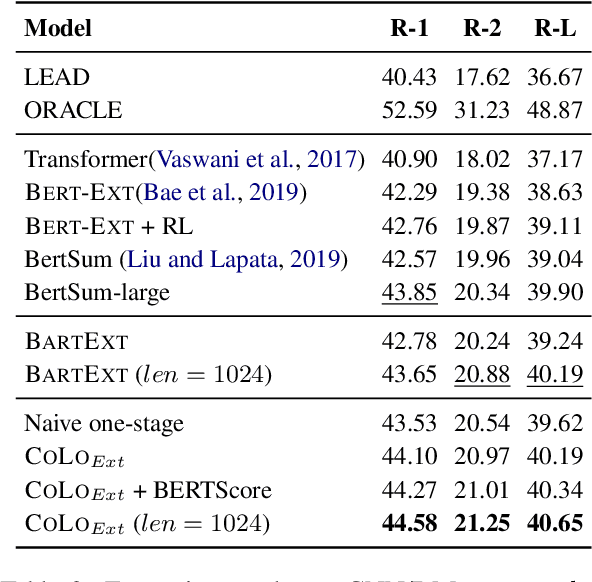
Traditional training paradigms for extractive and abstractive summarization systems always only use token-level or sentence-level training objectives. However, the output summary is always evaluated from summary-level which leads to the inconsistency in training and evaluation. In this paper, we propose a Contrastive Learning based re-ranking framework for one-stage summarization called COLO. By modeling a contrastive objective, we show that the summarization model is able to directly generate summaries according to the summary-level score without additional modules and parameters. Extensive experiments demonstrate that COLO boosts the extractive and abstractive results of one-stage systems on CNN/DailyMail benchmark to 44.58 and 46.33 ROUGE-1 score while preserving the parameter efficiency and inference efficiency. Compared with state-of-the-art multi-stage systems, we save more than 100 GPU training hours and obtaining 3~8 speed-up ratio during inference while maintaining comparable results.
A Multi-Format Transfer Learning Model for Event Argument Extraction via Variational Information Bottleneck
Aug 30, 2022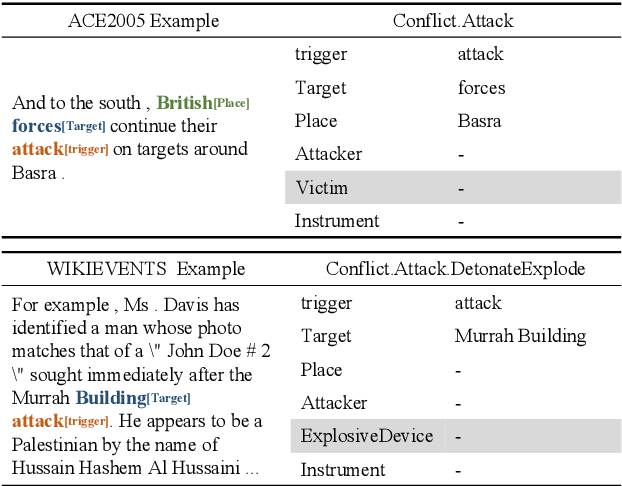
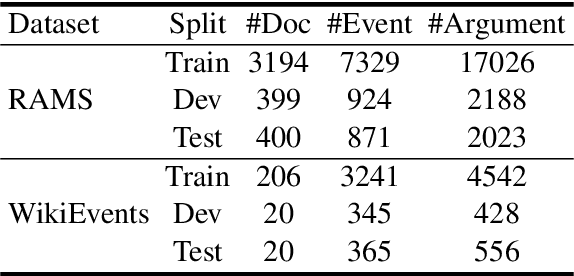
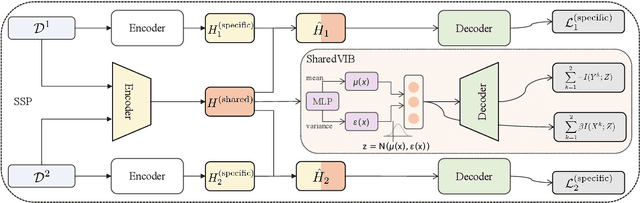
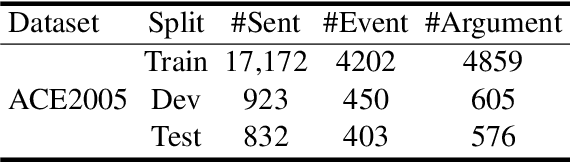
Event argument extraction (EAE) aims to extract arguments with given roles from texts, which have been widely studied in natural language processing. Most previous works have achieved good performance in specific EAE datasets with dedicated neural architectures. Whereas, these architectures are usually difficult to adapt to new datasets/scenarios with various annotation schemas or formats. Furthermore, they rely on large-scale labeled data for training, which is unavailable due to the high labelling cost in most cases. In this paper, we propose a multi-format transfer learning model with variational information bottleneck, which makes use of the information especially the common knowledge in existing datasets for EAE in new datasets. Specifically, we introduce a shared-specific prompt framework to learn both format-shared and format-specific knowledge from datasets with different formats. In order to further absorb the common knowledge for EAE and eliminate the irrelevant noise, we integrate variational information bottleneck into our architecture to refine the shared representation. We conduct extensive experiments on three benchmark datasets, and obtain new state-of-the-art performance on EAE.
Locate Then Ask: Interpretable Stepwise Reasoning for Multi-hop Question Answering
Aug 22, 2022
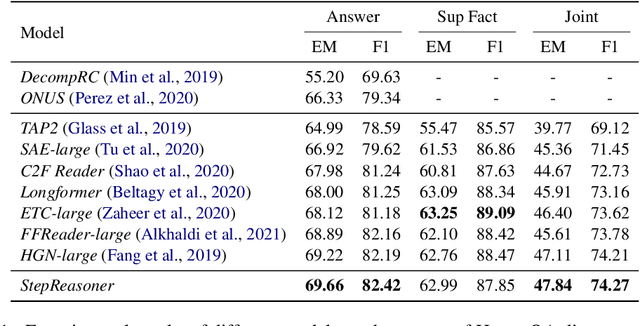
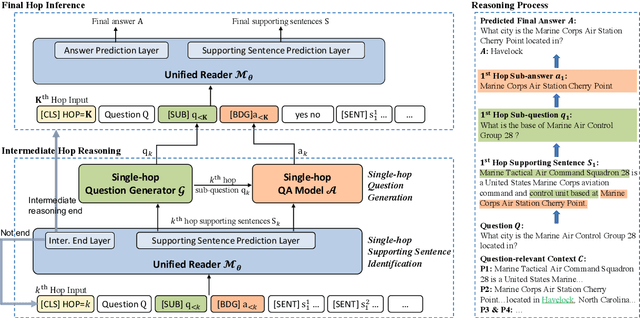
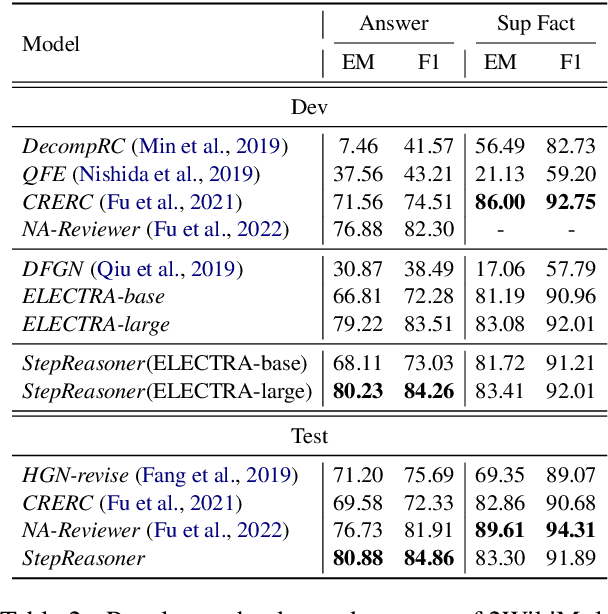
Multi-hop reasoning requires aggregating multiple documents to answer a complex question. Existing methods usually decompose the multi-hop question into simpler single-hop questions to solve the problem for illustrating the explainable reasoning process. However, they ignore grounding on the supporting facts of each reasoning step, which tends to generate inaccurate decompositions. In this paper, we propose an interpretable stepwise reasoning framework to incorporate both single-hop supporting sentence identification and single-hop question generation at each intermediate step, and utilize the inference of the current hop for the next until reasoning out the final result. We employ a unified reader model for both intermediate hop reasoning and final hop inference and adopt joint optimization for more accurate and robust multi-hop reasoning. We conduct experiments on two benchmark datasets HotpotQA and 2WikiMultiHopQA. The results show that our method can effectively boost performance and also yields a better interpretable reasoning process without decomposition supervision.
Causal Intervention Improves Implicit Sentiment Analysis
Aug 19, 2022

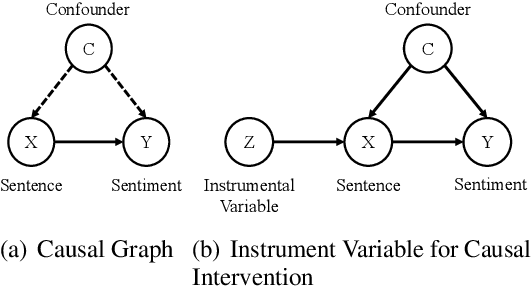
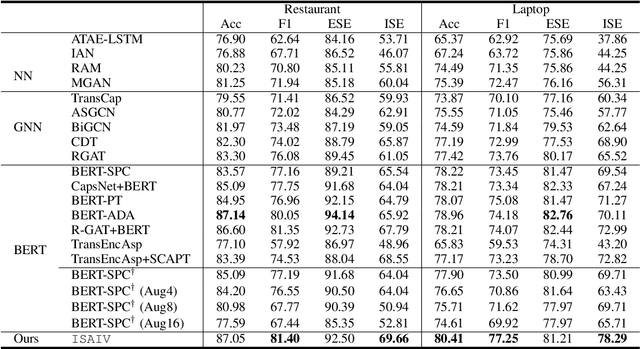
Despite having achieved great success for sentiment analysis, existing neural models struggle with implicit sentiment analysis. This may be due to the fact that they may latch onto spurious correlations ("shortcuts", e.g., focusing only on explicit sentiment words), resulting in undermining the effectiveness and robustness of the learned model. In this work, we propose a causal intervention model for Implicit Sentiment Analysis using Instrumental Variable (ISAIV). We first review sentiment analysis from a causal perspective and analyze the confounders existing in this task. Then, we introduce an instrumental variable to eliminate the confounding causal effects, thus extracting the pure causal effect between sentence and sentiment. We compare the proposed ISAIV model with several strong baselines on both the general implicit sentiment analysis and aspect-based implicit sentiment analysis tasks. The results indicate the great advantages of our model and the efficacy of implicit sentiment reasoning.
A Unified Continuous Learning Framework for Multi-modal Knowledge Discovery and Pre-training
Jun 11, 2022
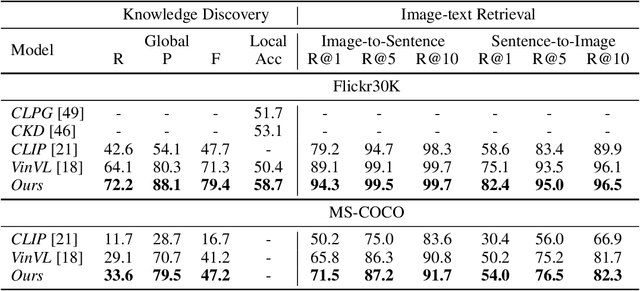
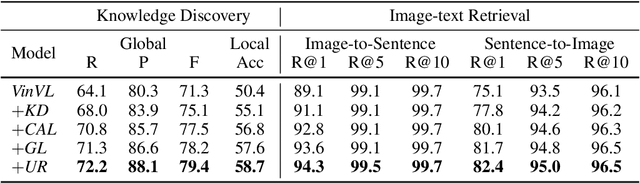
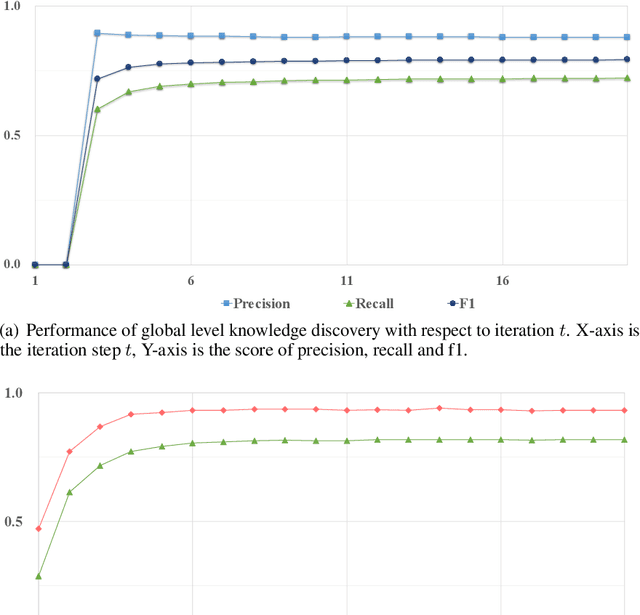
Multi-modal pre-training and knowledge discovery are two important research topics in multi-modal machine learning. Nevertheless, none of existing works make attempts to link knowledge discovery with knowledge guided multi-modal pre-training. In this paper, we propose to unify them into a continuous learning framework for mutual improvement. Taking the open-domain uni-modal datasets of images and texts as input, we maintain a knowledge graph as the foundation to support these two tasks. For knowledge discovery, a pre-trained model is used to identify cross-modal links on the graph. For model pre-training, the knowledge graph is used as the external knowledge to guide the model updating. These two steps are iteratively performed in our framework for continuous learning. The experimental results on MS-COCO and Flickr30K with respect to both knowledge discovery and the pre-trained model validate the effectiveness of our framework.
What Dense Graph Do You Need for Self-Attention?
Jun 09, 2022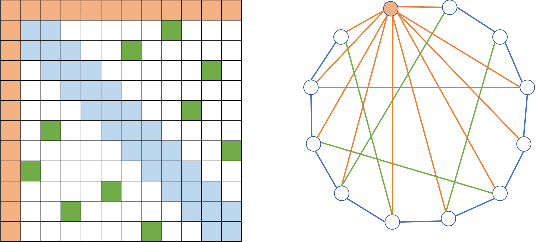

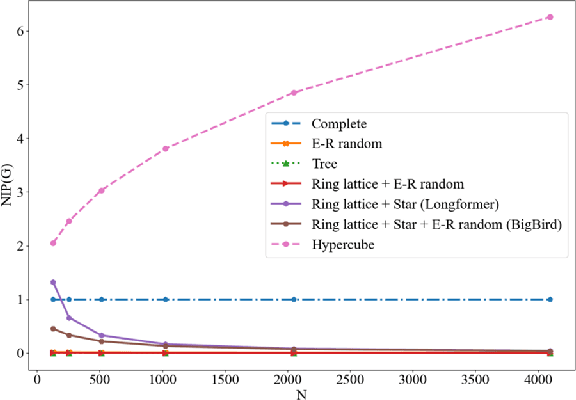
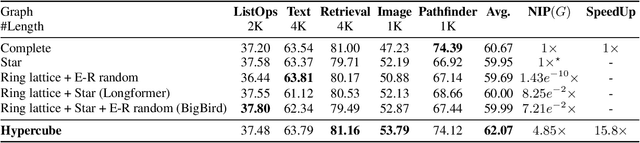
Transformers have made progress in miscellaneous tasks, but suffer from quadratic computational and memory complexities. Recent works propose sparse Transformers with attention on sparse graphs to reduce complexity and remain strong performance. While effective, the crucial parts of how dense a graph needs to be to perform well are not fully explored. In this paper, we propose Normalized Information Payload (NIP), a graph scoring function measuring information transfer on graph, which provides an analysis tool for trade-offs between performance and complexity. Guided by this theoretical analysis, we present Hypercube Transformer, a sparse Transformer that models token interactions in a hypercube and shows comparable or even better results with vanilla Transformer while yielding $O(N\log N)$ complexity with sequence length $N$. Experiments on tasks requiring various sequence lengths lay validation for our graph function well.
CoNT: Contrastive Neural Text Generation
May 29, 2022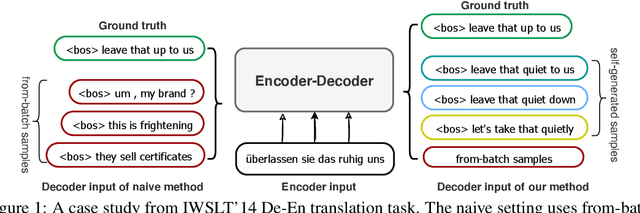
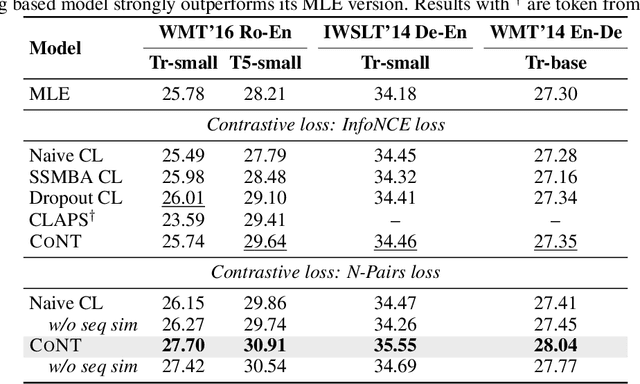
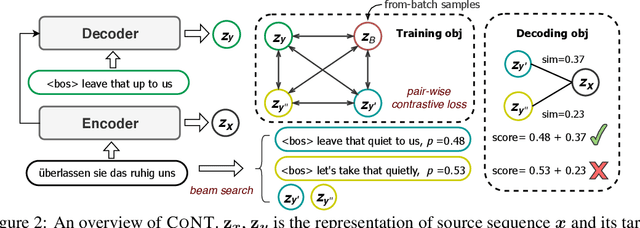
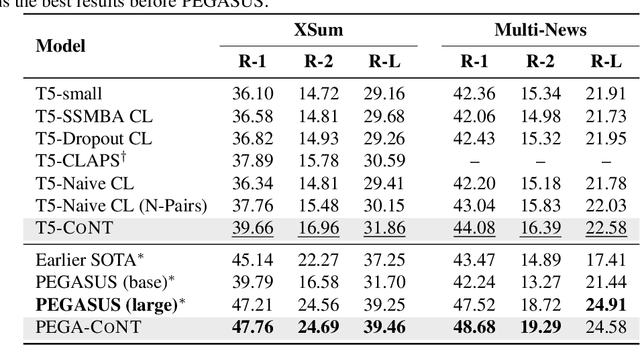
Recently, contrastive learning attracts increasing interests in neural text generation as a new solution to alleviate the exposure bias problem. It introduces a sequence-level training signal which is crucial to generation tasks that always rely on auto-regressive decoding. However, previous methods using contrastive learning in neural text generation usually lead to inferior performance. In this paper, we analyse the underlying reasons and propose a new Contrastive Neural Text generation framework, CoNT. CoNT addresses bottlenecks that prevent contrastive learning from being widely adopted in generation tasks from three aspects -- the construction of contrastive examples, the choice of the contrastive loss, and the strategy in decoding. We validate CoNT on five generation tasks with ten benchmarks, including machine translation, summarization, code comment generation, data-to-text generation and commonsense generation. Experimental results show that CoNT clearly outperforms the conventional training framework on all the ten benchmarks with a convincing margin. Especially, CoNT surpasses previous the most competitive contrastive learning method for text generation, by 1.50 BLEU on machine translation and 1.77 ROUGE-1 on summarization, respectively. It achieves new state-of-the-art on summarization, code comment generation (without external data) and data-to-text generation.
BBTv2: Pure Black-Box Optimization Can Be Comparable to Gradient Descent for Few-Shot Learning
May 23, 2022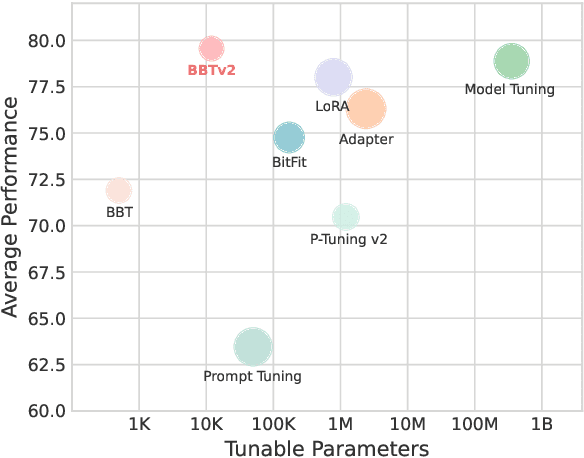
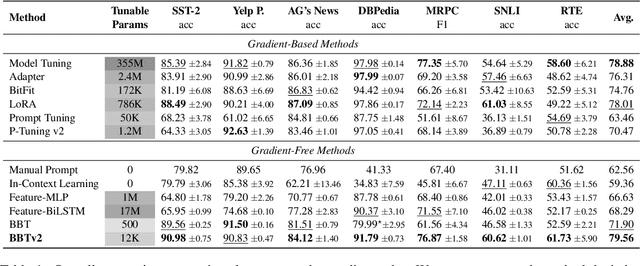
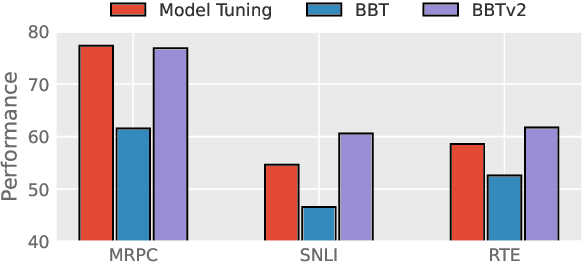
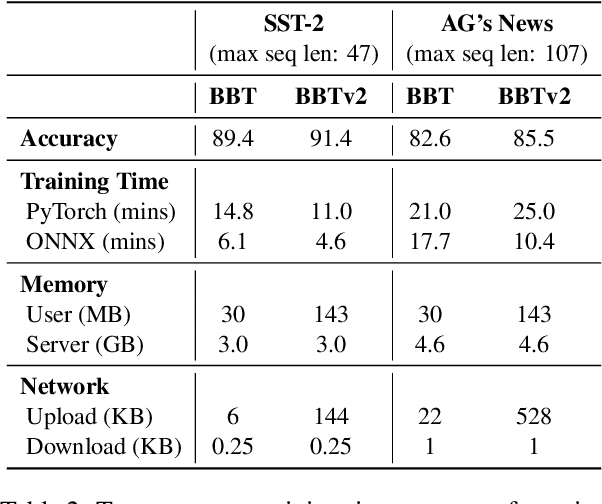
Black-Box Tuning (BBT) is a derivative-free approach to optimize continuous prompt tokens prepended to the input of language models. Although BBT has achieved comparable performance to full model tuning on simple classification tasks under few-shot settings, it requires pre-trained prompt embedding to match model tuning on hard tasks (e.g., entailment tasks), and therefore does not completely get rid of the dependence on gradients. In this paper we present BBTv2, a pure black-box optimization approach that can drive language models to achieve comparable results to gradient-based optimization. In particular, we prepend continuous prompt tokens to every layer of the language model and propose a divide-and-conquer algorithm to alternately optimize the prompt tokens at different layers. For the optimization at each layer, we perform derivative-free optimization in a low-dimensional subspace, which is then randomly projected to the original prompt parameter space. Experimental results show that BBTv2 not only outperforms BBT by a large margin, but also achieves comparable or even better performance than full model tuning and state-of-the-art parameter-efficient methods (e.g., Adapter, LoRA, BitFit, etc.) under few-shot learning settings, while maintaining much fewer tunable parameters.
A Benchmark for Automatic Medical Consultation System: Frameworks, Tasks and Datasets
Apr 27, 2022
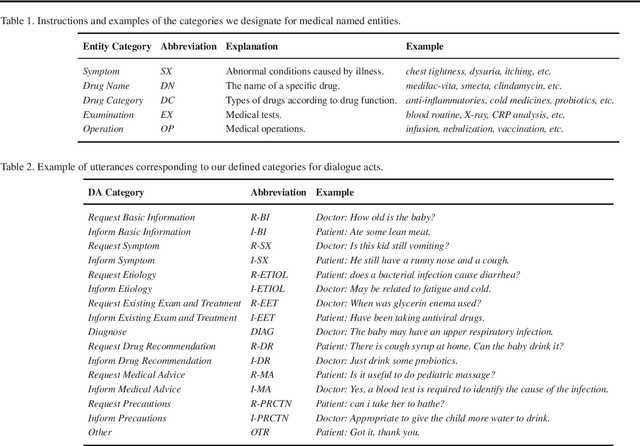
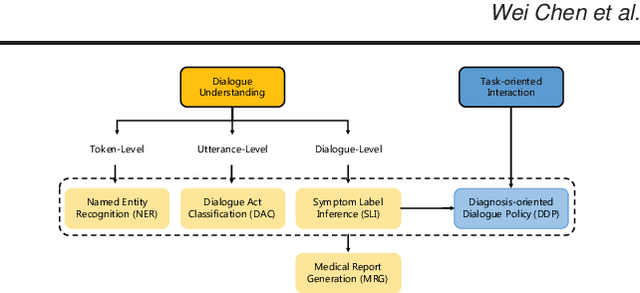
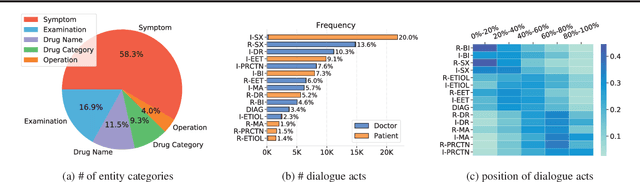
In recent years, interest has arisen in using machine learning to improve the efficiency of automatic medical consultation and enhance patient experience. In this paper, we propose two frameworks to support automatic medical consultation, namely doctor-patient dialogue understanding and task-oriented interaction. A new large medical dialogue dataset with multi-level fine-grained annotations is introduced and five independent tasks are established, including named entity recognition, dialogue act classification, symptom label inference, medical report generation and diagnosis-oriented dialogue policy. We report a set of benchmark results for each task, which shows the usability of the dataset and sets a baseline for future studies.