 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXu Tan
ContextSpeech: Expressive and Efficient Text-to-Speech for Paragraph Reading
Jul 03, 2023
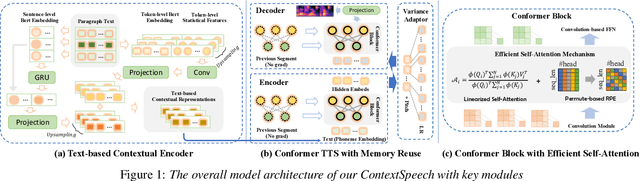

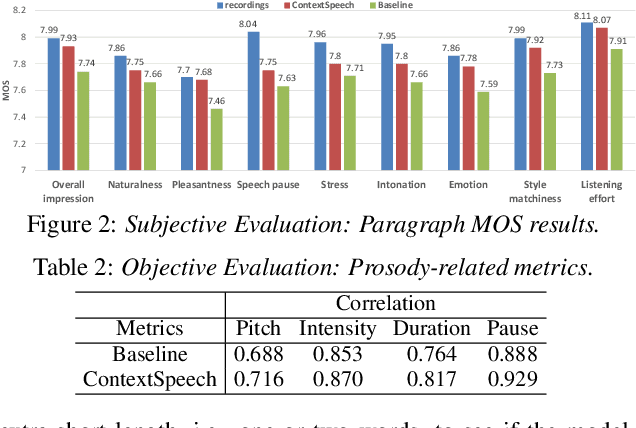
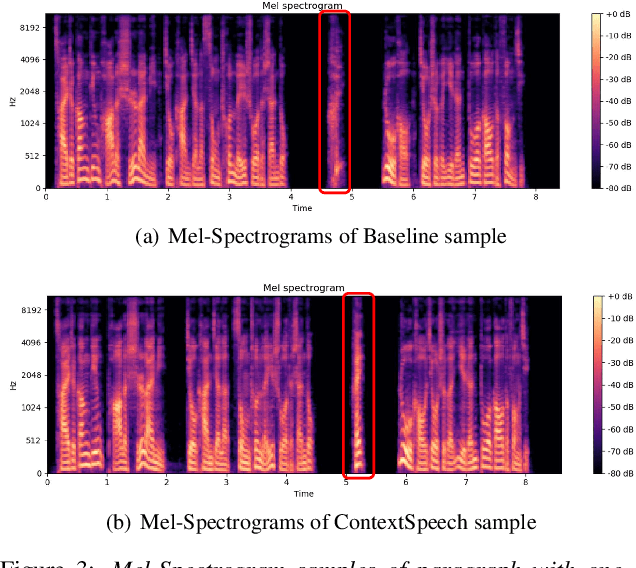
While state-of-the-art Text-to-Speech systems can generate natural speech of very high quality at sentence level, they still meet great challenges in speech generation for paragraph / long-form reading. Such deficiencies are due to i) ignorance of cross-sentence contextual information, and ii) high computation and memory cost for long-form synthesis. To address these issues, this work develops a lightweight yet effective TTS system, ContextSpeech. Specifically, we first design a memory-cached recurrence mechanism to incorporate global text and speech context into sentence encoding. Then we construct hierarchically-structured textual semantics to broaden the scope for global context enhancement. Additionally, we integrate linearized self-attention to improve model efficiency. Experiments show that ContextSpeech significantly improves the voice quality and prosody expressiveness in paragraph reading with competitive model efficiency. Audio samples are available at: https://contextspeech.github.io/demo/
EmoGen: Eliminating Subjective Bias in Emotional Music Generation
Jul 03, 2023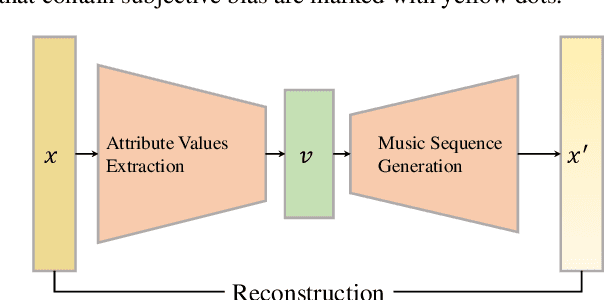

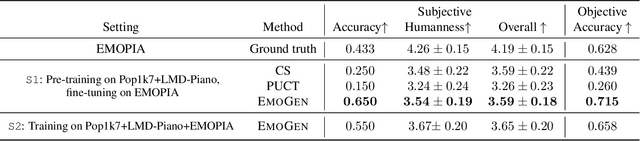
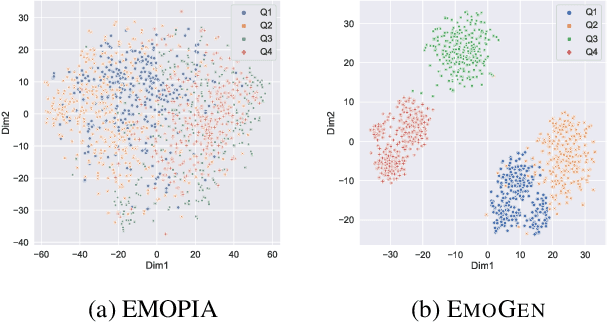
Music is used to convey emotions, and thus generating emotional music is important in automatic music generation. Previous work on emotional music generation directly uses annotated emotion labels as control signals, which suffers from subjective bias: different people may annotate different emotions on the same music, and one person may feel different emotions under different situations. Therefore, directly mapping emotion labels to music sequences in an end-to-end way would confuse the learning process and hinder the model from generating music with general emotions. In this paper, we propose EmoGen, an emotional music generation system that leverages a set of emotion-related music attributes as the bridge between emotion and music, and divides the generation into two stages: emotion-to-attribute mapping with supervised clustering, and attribute-to-music generation with self-supervised learning. Both stages are beneficial: in the first stage, the attribute values around the clustering center represent the general emotions of these samples, which help eliminate the impacts of the subjective bias of emotion labels; in the second stage, the generation is completely disentangled from emotion labels and thus free from the subjective bias. Both subjective and objective evaluations show that EmoGen outperforms previous methods on emotion control accuracy and music quality respectively, which demonstrate our superiority in generating emotional music. Music samples generated by EmoGen are available via this link:https://ai-muzic.github.io/emogen/, and the code is available at this link:https://github.com/microsoft/muzic/.
Extract and Attend: Improving Entity Translation in Neural Machine Translation
Jun 04, 2023
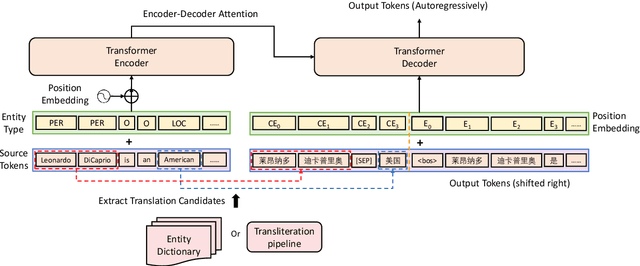
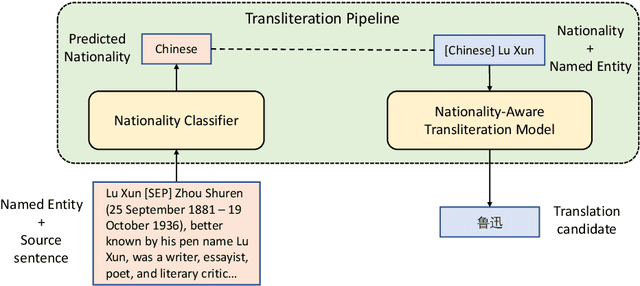

While Neural Machine Translation(NMT) has achieved great progress in recent years, it still suffers from inaccurate translation of entities (e.g., person/organization name, location), due to the lack of entity training instances. When we humans encounter an unknown entity during translation, we usually first look up in a dictionary and then organize the entity translation together with the translations of other parts to form a smooth target sentence. Inspired by this translation process, we propose an Extract-and-Attend approach to enhance entity translation in NMT, where the translation candidates of source entities are first extracted from a dictionary and then attended to by the NMT model to generate the target sentence. Specifically, the translation candidates are extracted by first detecting the entities in a source sentence and then translating the entities through looking up in a dictionary. Then, the extracted candidates are added as a prefix of the decoder input to be attended to by the decoder when generating the target sentence through self-attention. Experiments conducted on En-Zh and En-Ru demonstrate that the proposed method is effective on improving both the translation accuracy of entities and the overall translation quality, with up to 35% reduction on entity error rate and 0.85 gain on BLEU and 13.8 gain on COMET.
MuseCoco: Generating Symbolic Music from Text
May 31, 2023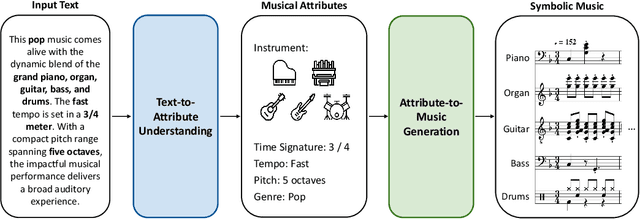

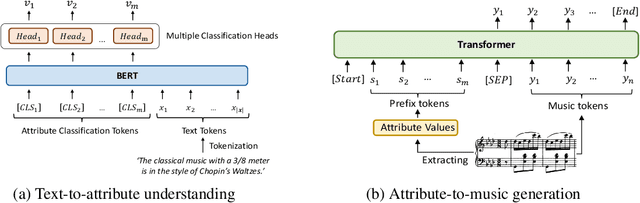

Generating music from text descriptions is a user-friendly mode since the text is a relatively easy interface for user engagement. While some approaches utilize texts to control music audio generation, editing musical elements in generated audio is challenging for users. In contrast, symbolic music offers ease of editing, making it more accessible for users to manipulate specific musical elements. In this paper, we propose MuseCoco, which generates symbolic music from text descriptions with musical attributes as the bridge to break down the task into text-to-attribute understanding and attribute-to-music generation stages. MuseCoCo stands for Music Composition Copilot that empowers musicians to generate music directly from given text descriptions, offering a significant improvement in efficiency compared to creating music entirely from scratch. The system has two main advantages: Firstly, it is data efficient. In the attribute-to-music generation stage, the attributes can be directly extracted from music sequences, making the model training self-supervised. In the text-to-attribute understanding stage, the text is synthesized and refined by ChatGPT based on the defined attribute templates. Secondly, the system can achieve precise control with specific attributes in text descriptions and offers multiple control options through attribute-conditioned or text-conditioned approaches. MuseCoco outperforms baseline systems in terms of musicality, controllability, and overall score by at least 1.27, 1.08, and 1.32 respectively. Besides, there is a notable enhancement of about 20% in objective control accuracy. In addition, we have developed a robust large-scale model with 1.2 billion parameters, showcasing exceptional controllability and musicality.
Deliberate then Generate: Enhanced Prompting Framework for Text Generation
May 31, 2023
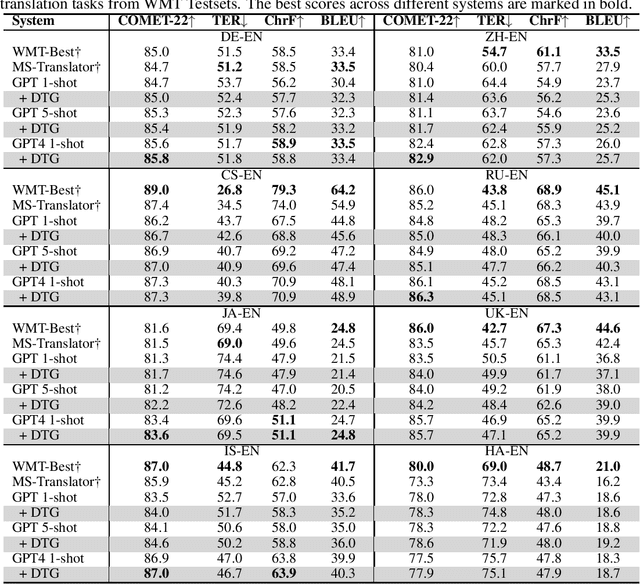

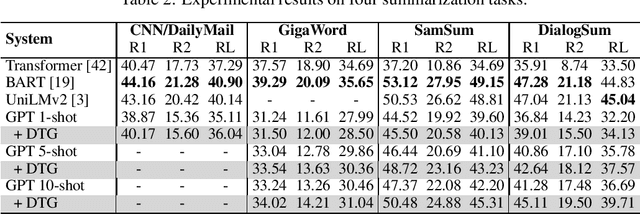
Large language models (LLMs) have shown remarkable success across a wide range of natural language generation tasks, where proper prompt designs make great impacts. While existing prompting methods are normally restricted to providing correct information, in this paper, we encourage the model to deliberate by proposing a novel Deliberate then Generate (DTG) prompting framework, which consists of error detection instructions and candidates that may contain errors. DTG is a simple yet effective technique that can be applied to various text generation tasks with minimal modifications. We conduct extensive experiments on 20+ datasets across 7 text generation tasks, including summarization, translation, dialogue, and more. We show that DTG consistently outperforms existing prompting methods and achieves state-of-the-art performance on multiple text generation tasks. We also provide in-depth analyses to reveal the underlying mechanisms of DTG, which may inspire future research on prompting for LLMs.
TranSFormer: Slow-Fast Transformer for Machine Translation
May 26, 2023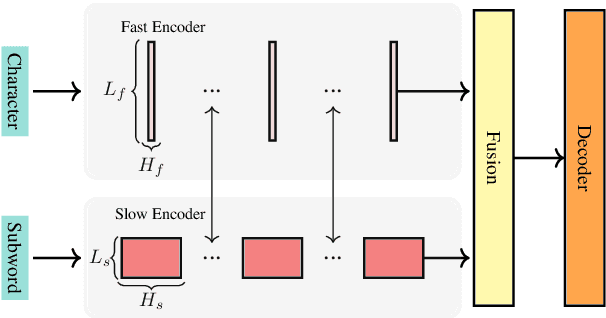
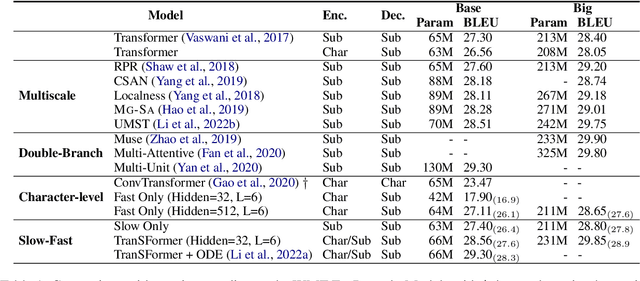
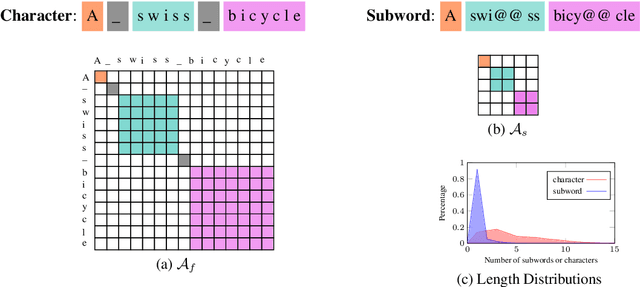
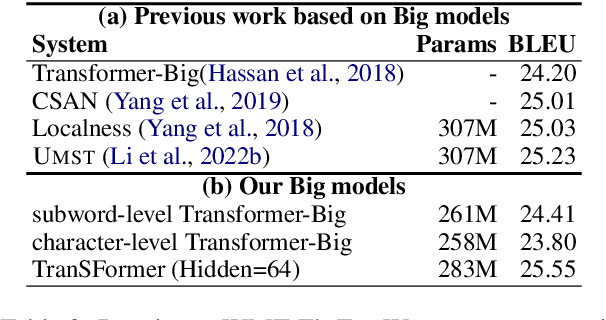
Learning multiscale Transformer models has been evidenced as a viable approach to augmenting machine translation systems. Prior research has primarily focused on treating subwords as basic units in developing such systems. However, the incorporation of fine-grained character-level features into multiscale Transformer has not yet been explored. In this work, we present a \textbf{S}low-\textbf{F}ast two-stream learning model, referred to as Tran\textbf{SF}ormer, which utilizes a ``slow'' branch to deal with subword sequences and a ``fast'' branch to deal with longer character sequences. This model is efficient since the fast branch is very lightweight by reducing the model width, and yet provides useful fine-grained features for the slow branch. Our TranSFormer shows consistent BLEU improvements (larger than 1 BLEU point) on several machine translation benchmarks.
DiffusionNER: Boundary Diffusion for Named Entity Recognition
May 22, 2023
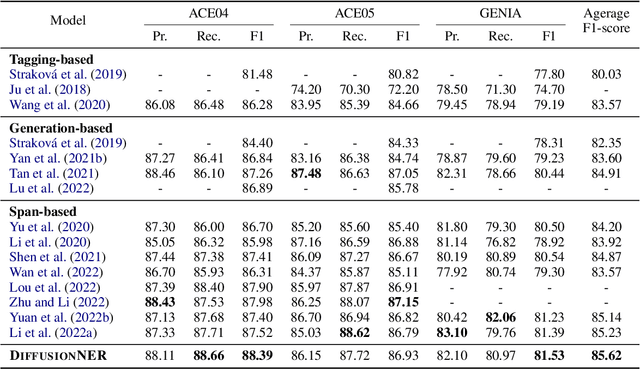
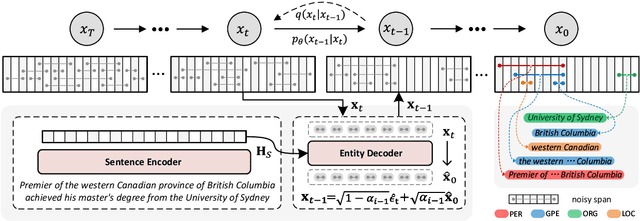
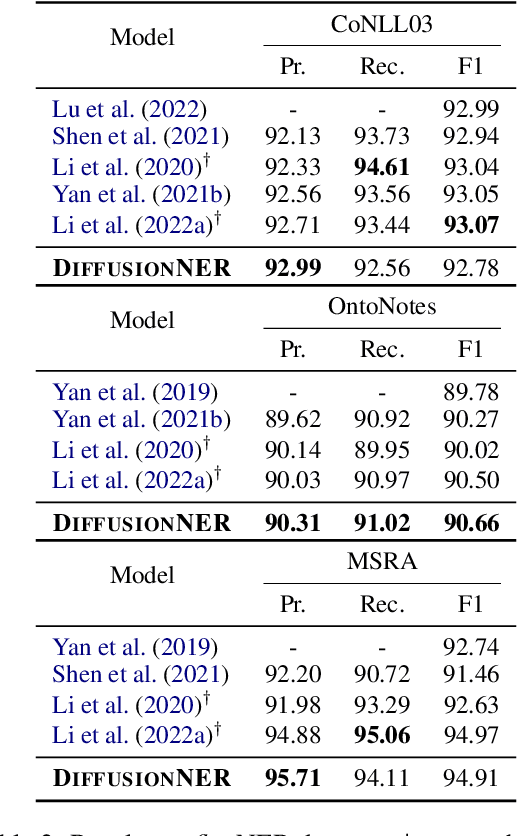
In this paper, we propose DiffusionNER, which formulates the named entity recognition task as a boundary-denoising diffusion process and thus generates named entities from noisy spans. During training, DiffusionNER gradually adds noises to the golden entity boundaries by a fixed forward diffusion process and learns a reverse diffusion process to recover the entity boundaries. In inference, DiffusionNER first randomly samples some noisy spans from a standard Gaussian distribution and then generates the named entities by denoising them with the learned reverse diffusion process. The proposed boundary-denoising diffusion process allows progressive refinement and dynamic sampling of entities, empowering DiffusionNER with efficient and flexible entity generation capability. Experiments on multiple flat and nested NER datasets demonstrate that DiffusionNER achieves comparable or even better performance than previous state-of-the-art models.
NAS-FM: Neural Architecture Search for Tunable and Interpretable Sound Synthesis based on Frequency Modulation
May 22, 2023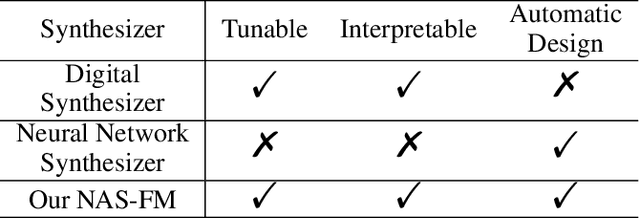
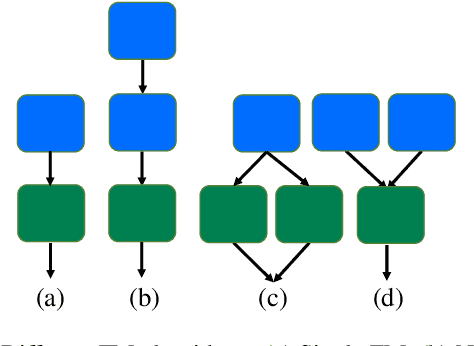
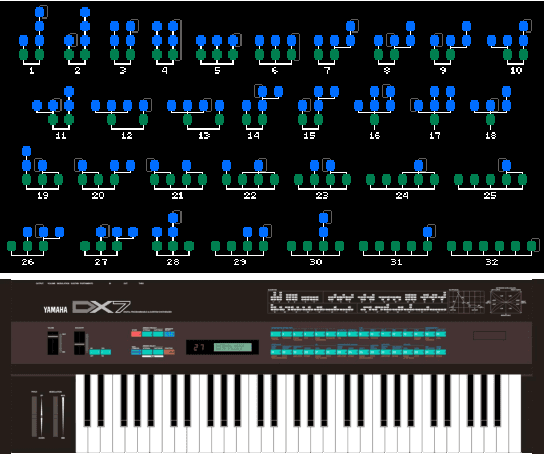
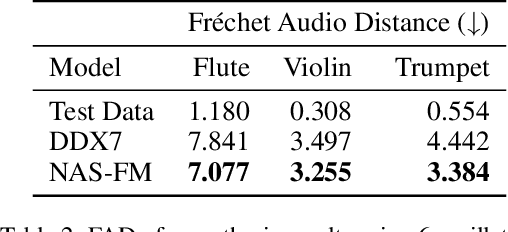
Developing digital sound synthesizers is crucial to the music industry as it provides a low-cost way to produce high-quality sounds with rich timbres. Existing traditional synthesizers often require substantial expertise to determine the overall framework of a synthesizer and the parameters of submodules. Since expert knowledge is hard to acquire, it hinders the flexibility to quickly design and tune digital synthesizers for diverse sounds. In this paper, we propose ``NAS-FM'', which adopts neural architecture search (NAS) to build a differentiable frequency modulation (FM) synthesizer. Tunable synthesizers with interpretable controls can be developed automatically from sounds without any prior expert knowledge and manual operating costs. In detail, we train a supernet with a specifically designed search space, including predicting the envelopes of carriers and modulators with different frequency ratios. An evolutionary search algorithm with adaptive oscillator size is then developed to find the optimal relationship between oscillators and the frequency ratio of FM. Extensive experiments on recordings of different instrument sounds show that our algorithm can build a synthesizer fully automatically, achieving better results than handcrafted synthesizers. Audio samples are available at https://nas-fm.github.io/.
GETMusic: Generating Any Music Tracks with a Unified Representation and Diffusion Framework
May 18, 2023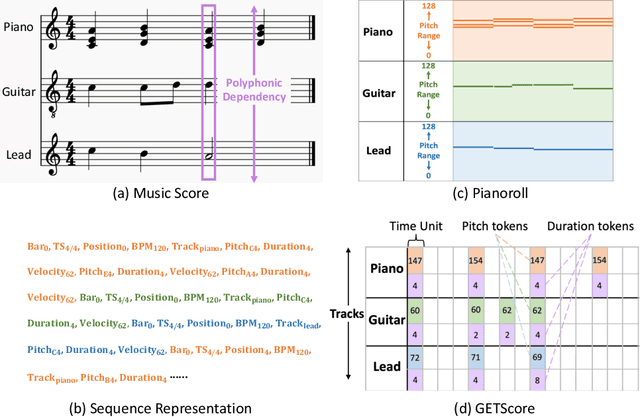
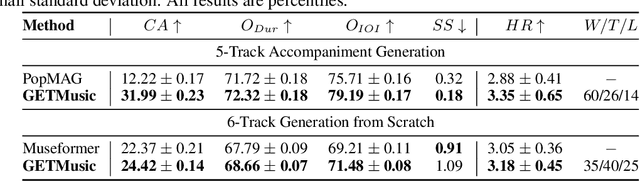
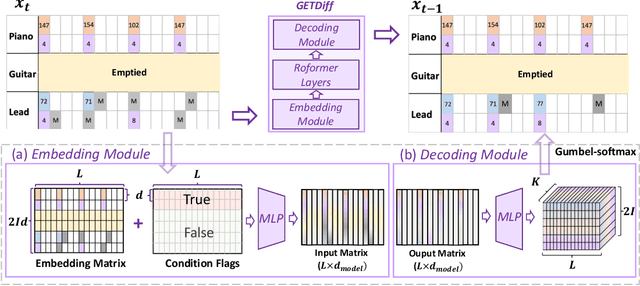
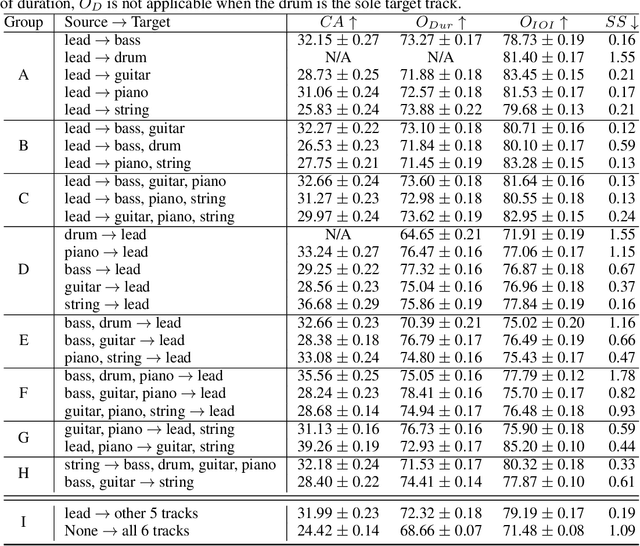
Symbolic music generation aims to create musical notes, which can help users compose music, such as generating target instrumental tracks from scratch, or based on user-provided source tracks. Considering the diverse and flexible combination between source and target tracks, a unified model capable of generating any arbitrary tracks is of crucial necessity. Previous works fail to address this need due to inherent constraints in music representations and model architectures. To address this need, we propose a unified representation and diffusion framework named GETMusic (`GET' stands for GEnerate music Tracks), which includes a novel music representation named GETScore, and a diffusion model named GETDiff. GETScore represents notes as tokens and organizes them in a 2D structure, with tracks stacked vertically and progressing horizontally over time. During training, tracks are randomly selected as either the target or source. In the forward process, target tracks are corrupted by masking their tokens, while source tracks remain as ground truth. In the denoising process, GETDiff learns to predict the masked target tokens, conditioning on the source tracks. With separate tracks in GETScore and the non-autoregressive behavior of the model, GETMusic can explicitly control the generation of any target tracks from scratch or conditioning on source tracks. We conduct experiments on music generation involving six instrumental tracks, resulting in a total of 665 combinations. GETMusic provides high-quality results across diverse combinations and surpasses prior works proposed for some specific combinations.
CoMoSpeech: One-Step Speech and Singing Voice Synthesis via Consistency Model
May 11, 2023
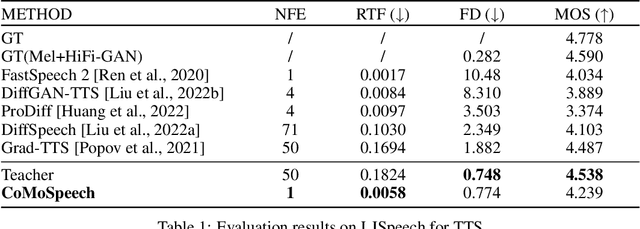
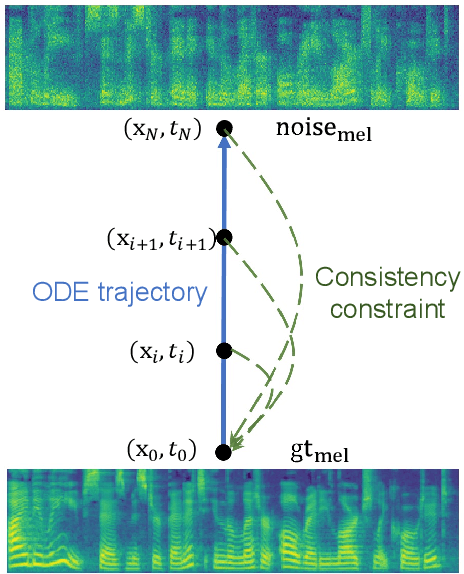
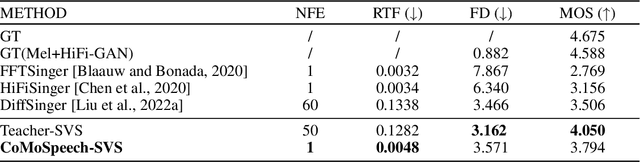
Denoising diffusion probabilistic models (DDPMs) have shown promising performance for speech synthesis. However, a large number of iterative steps are required to achieve high sample quality, which restricts the inference speed. Maintaining sample quality while increasing sampling speed has become a challenging task. In this paper, we propose a "Co"nsistency "Mo"del-based "Speech" synthesis method, CoMoSpeech, which achieve speech synthesis through a single diffusion sampling step while achieving high audio quality. The consistency constraint is applied to distill a consistency model from a well-designed diffusion-based teacher model, which ultimately yields superior performances in the distilled CoMoSpeech. Our experiments show that by generating audio recordings by a single sampling step, the CoMoSpeech achieves an inference speed more than 150 times faster than real-time on a single NVIDIA A100 GPU, which is comparable to FastSpeech2, making diffusion-sampling based speech synthesis truly practical. Meanwhile, objective and subjective evaluations on text-to-speech and singing voice synthesis show that the proposed teacher models yield the best audio quality, and the one-step sampling based CoMoSpeech achieves the best inference speed with better or comparable audio quality to other conventional multi-step diffusion model baselines. Audio samples are available at https://comospeech.github.io/.