 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXingjia Pan
Unveiling the Potential of Structure-Preserving for Weakly Supervised Object Localization
Mar 08, 2021
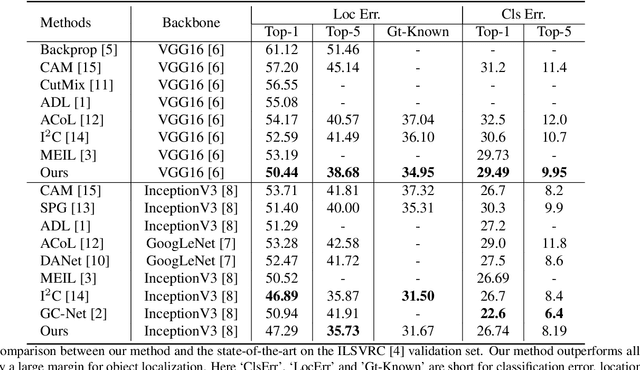

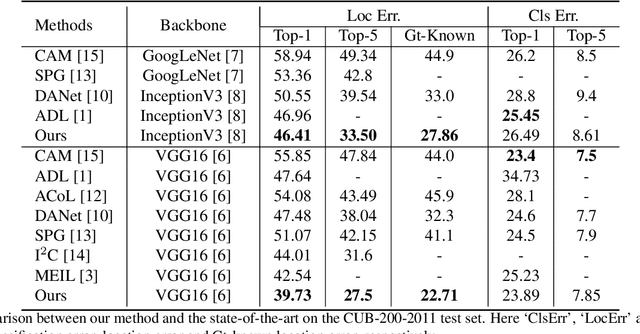
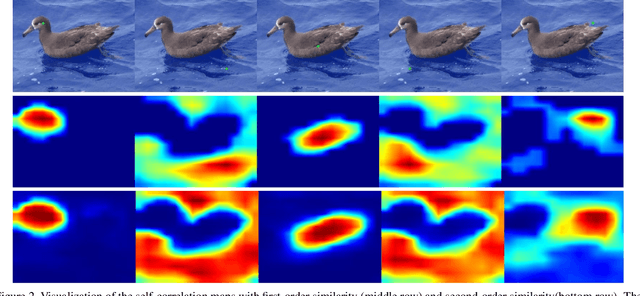
Weakly supervised object localization remains an open problem due to the deficiency of finding object extent information using a classification network. While prior works struggle to localize objects by various spatial regularization strategies, we argue that how to extract object structural information from the trained classification network is neglected. In this paper, we propose a two-stage approach, termed structure-preserving activation (SPA), towards fully leveraging the structure information incorporated in convolutional features for WSOL. In the first stage, a restricted activation module (RAM) is designed to alleviate the structure-missing issue caused by the classification network, based on the observation that the unbounded classification map and global average pooling layer drive the network to focus only on object parts. In the second stage, we propose a post-process approach, termed self-correlation map generating (SCG) module to obtain structure-preserving localization maps on the basis of the activation maps acquired from the first stage. Specifically, we utilize the high-order self-correlation (HSC) to extract the inherent structural information retained in the learned model and then aggregate HSC of multiple points for precise object localization. Extensive experiments on two publicly available benchmarks including CUB-200-2011 and ILSVRC show that the proposed SPA achieves substantial and consistent performance gains compared with baseline approaches.
Dynamic Refinement Network for Oriented and Densely Packed Object Detection
Jun 10, 2020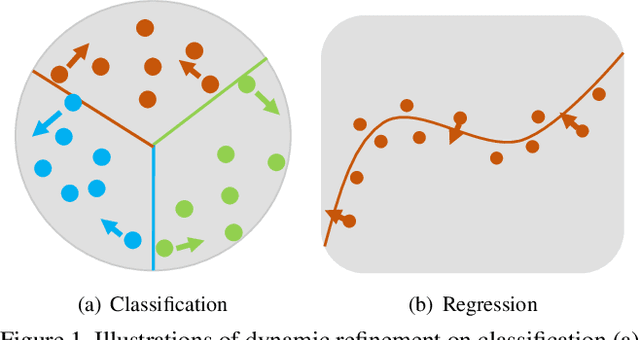
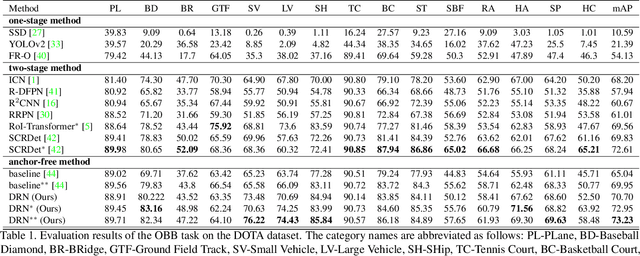
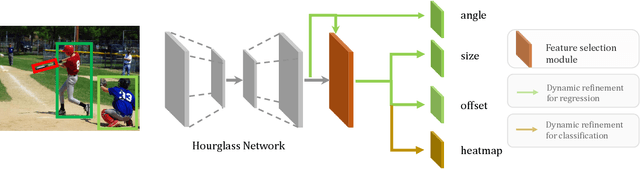

Object detection has achieved remarkable progress in the past decade. However, the detection of oriented and densely packed objects remains challenging because of following inherent reasons: (1) receptive fields of neurons are all axis-aligned and of the same shape, whereas objects are usually of diverse shapes and align along various directions; (2) detection models are typically trained with generic knowledge and may not generalize well to handle specific objects at test time; (3) the limited dataset hinders the development on this task. To resolve the first two issues, we present a dynamic refinement network that consists of two novel components, i.e., a feature selection module (FSM) and a dynamic refinement head (DRH). Our FSM enables neurons to adjust receptive fields in accordance with the shapes and orientations of target objects, whereas the DRH empowers our model to refine the prediction dynamically in an object-aware manner. To address the limited availability of related benchmarks, we collect an extensive and fully annotated dataset, namely, SKU110K-R, which is relabeled with oriented bounding boxes based on SKU110K. We perform quantitative evaluations on several publicly available benchmarks including DOTA, HRSC2016, SKU110K, and our own SKU110K-R dataset. Experimental results show that our method achieves consistent and substantial gains compared with baseline approaches. The code and dataset are available at https://github.com/Anymake/DRN_CVPR2020.