 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXinbo Gao
SAR-to-Optical Image Translation via Thermodynamics-inspired Network
May 23, 2023
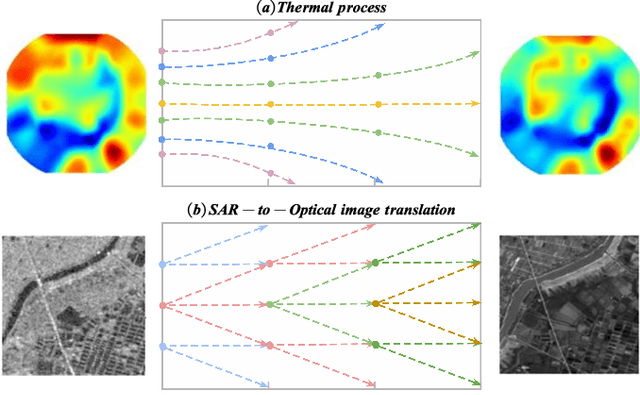
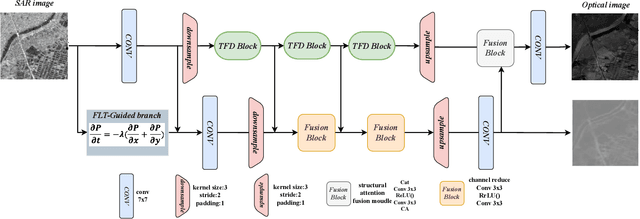
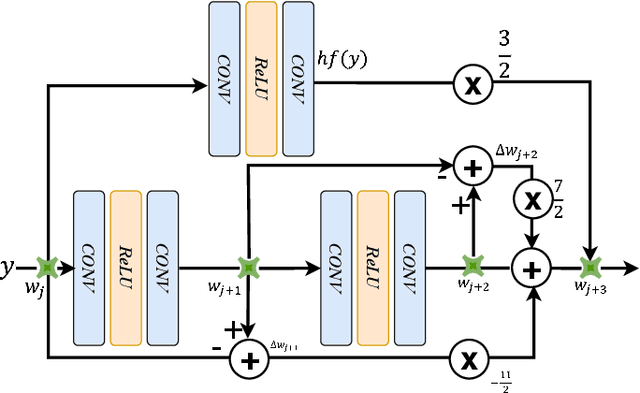
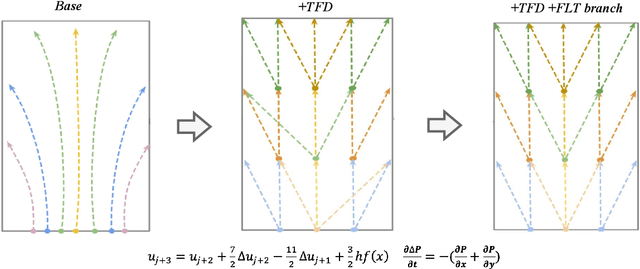
Synthetic aperture radar (SAR) is prevalent in the remote sensing field but is difficult to interpret in human visual perception. Recently, SAR-to-optical (S2O) image conversion methods have provided a prospective solution for interpretation. However, since there is a huge domain difference between optical and SAR images, they suffer from low image quality and geometric distortion in the produced optical images. Motivated by the analogy between pixels during the S2O image translation and molecules in a heat field, Thermodynamics-inspired Network for SAR-to-Optical Image Translation (S2O-TDN) is proposed in this paper. Specifically, we design a Third-order Finite Difference (TFD) residual structure in light of the TFD equation of thermodynamics, which allows us to efficiently extract inter-domain invariant features and facilitate the learning of the nonlinear translation mapping. In addition, we exploit the first law of thermodynamics (FLT) to devise an FLT-guided branch that promotes the state transition of the feature values from the unstable diffusion state to the stable one, aiming to regularize the feature diffusion and preserve image structures during S2O image translation. S2O-TDN follows an explicit design principle derived from thermodynamic theory and enjoys the advantage of explainability. Experiments on the public SEN1-2 dataset show the advantages of the proposed S2O-TDN over the current methods with more delicate textures and higher quantitative results.
Unsupervised Visible-Infrared Person ReID by Collaborative Learning with Neighbor-Guided Label Refinement
May 22, 2023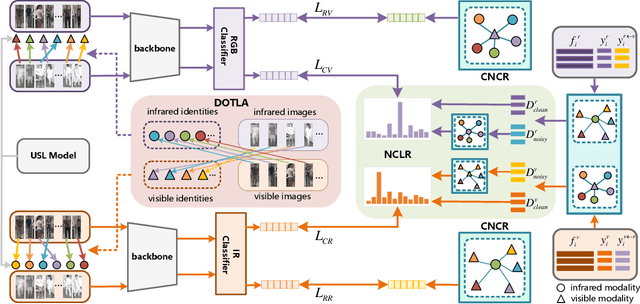
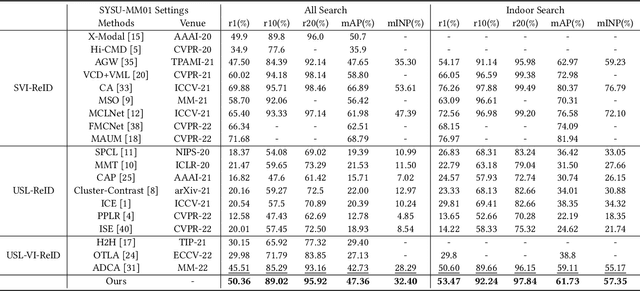
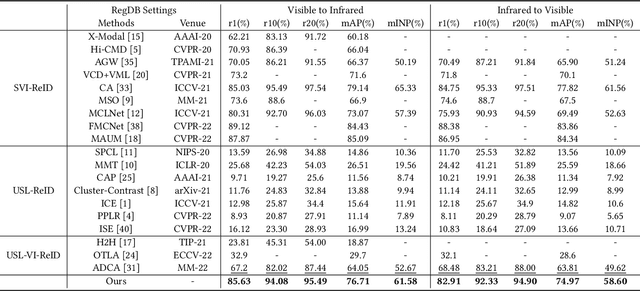
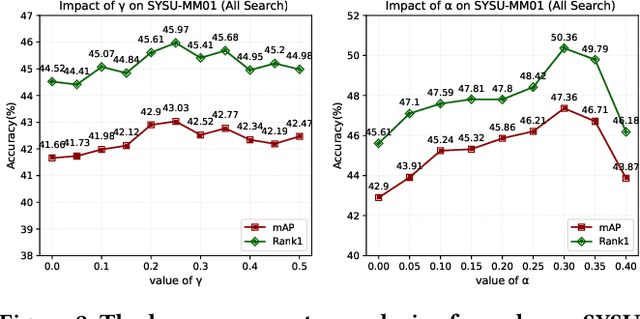
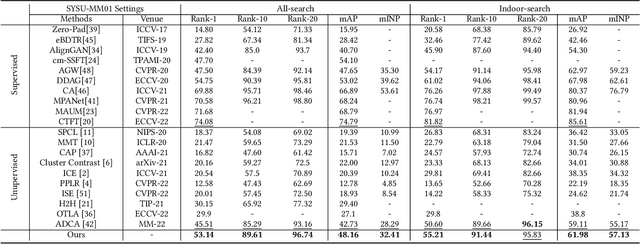
Unsupervised learning visible-infrared person re-identification (USL-VI-ReID) aims at learning modality-invariant features from unlabeled cross-modality dataset, which is crucial for practical applications in video surveillance systems. The key to essentially address the USL-VI-ReID task is to solve the cross-modality data association problem for further heterogeneous joint learning. To address this issue, we propose a Dual Optimal Transport Label Assignment (DOTLA) framework to simultaneously assign the generated labels from one modality to its counterpart modality. The proposed DOTLA mechanism formulates a mutual reinforcement and efficient solution to cross-modality data association, which could effectively reduce the side-effects of some insufficient and noisy label associations. Besides, we further propose a cross-modality neighbor consistency guided label refinement and regularization module, to eliminate the negative effects brought by the inaccurate supervised signals, under the assumption that the prediction or label distribution of each example should be similar to its nearest neighbors. Extensive experimental results on the public SYSU-MM01 and RegDB datasets demonstrate the effectiveness of the proposed method, surpassing existing state-of-the-art approach by a large margin of 7.76% mAP on average, which even surpasses some supervised VI-ReID methods.
Efficient Bilateral Cross-Modality Cluster Matching for Unsupervised Visible-Infrared Person ReID
May 22, 2023
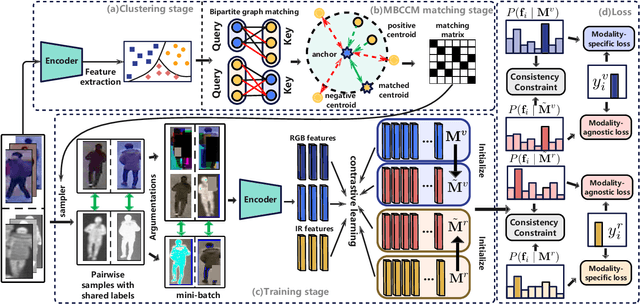
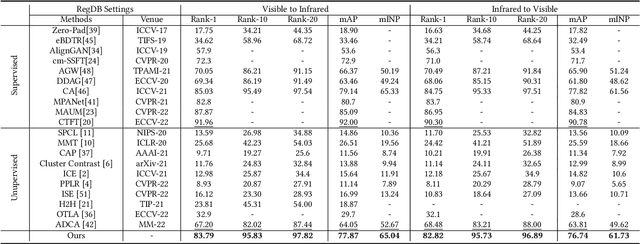
Unsupervised visible-infrared person re-identification (USL-VI-ReID) aims to match pedestrian images of the same identity from different modalities without annotations. Existing works mainly focus on alleviating the modality gap by aligning instance-level features of the unlabeled samples. However, the relationships between cross-modality clusters are not well explored. To this end, we propose a novel bilateral cluster matching-based learning framework to reduce the modality gap by matching cross-modality clusters. Specifically, we design a Many-to-many Bilateral Cross-Modality Cluster Matching (MBCCM) algorithm through optimizing the maximum matching problem in a bipartite graph. Then, the matched pairwise clusters utilize shared visible and infrared pseudo-labels during the model training. Under such a supervisory signal, a Modality-Specific and Modality-Agnostic (MSMA) contrastive learning framework is proposed to align features jointly at a cluster-level. Meanwhile, the cross-modality Consistency Constraint (CC) is proposed to explicitly reduce the large modality discrepancy. Extensive experiments on the public SYSU-MM01 and RegDB datasets demonstrate the effectiveness of the proposed method, surpassing state-of-the-art approaches by a large margin of 8.76% mAP on average.
Language Knowledge-Assisted Representation Learning for Skeleton-Based Action Recognition
May 21, 2023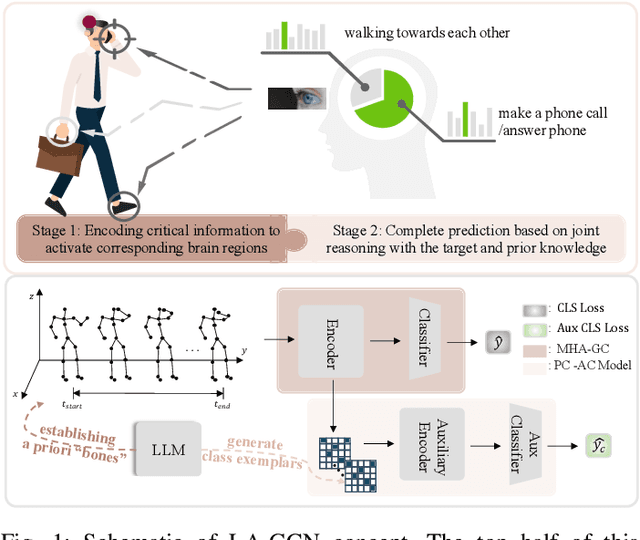
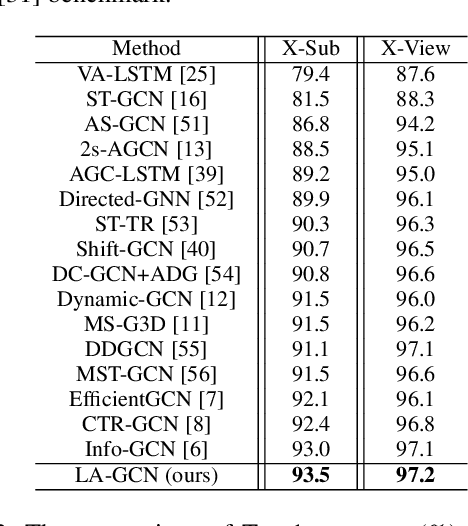
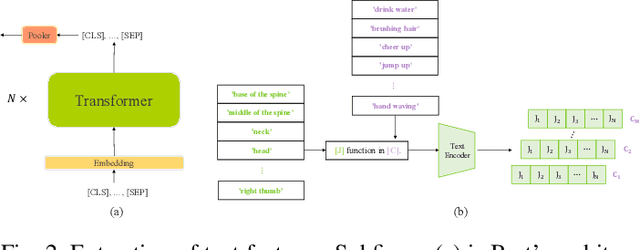

How humans understand and recognize the actions of others is a complex neuroscientific problem that involves a combination of cognitive mechanisms and neural networks. Research has shown that humans have brain areas that recognize actions that process top-down attentional information, such as the temporoparietal association area. Also, humans have brain regions dedicated to understanding the minds of others and analyzing their intentions, such as the medial prefrontal cortex of the temporal lobe. Skeleton-based action recognition creates mappings for the complex connections between the human skeleton movement patterns and behaviors. Although existing studies encoded meaningful node relationships and synthesized action representations for classification with good results, few of them considered incorporating a priori knowledge to aid potential representation learning for better performance. LA-GCN proposes a graph convolution network using large-scale language models (LLM) knowledge assistance. First, the LLM knowledge is mapped into a priori global relationship (GPR) topology and a priori category relationship (CPR) topology between nodes. The GPR guides the generation of new "bone" representations, aiming to emphasize essential node information from the data level. The CPR mapping simulates category prior knowledge in human brain regions, encoded by the PC-AC module and used to add additional supervision-forcing the model to learn class-distinguishable features. In addition, to improve information transfer efficiency in topology modeling, we propose multi-hop attention graph convolution. It aggregates each node's k-order neighbor simultaneously to speed up model convergence. LA-GCN reaches state-of-the-art on NTU RGB+D, NTU RGB+D 120, and NW-UCLA datasets.
Selecting Learnable Training Samples is All DETRs Need in Crowded Pedestrian Detection
May 18, 2023

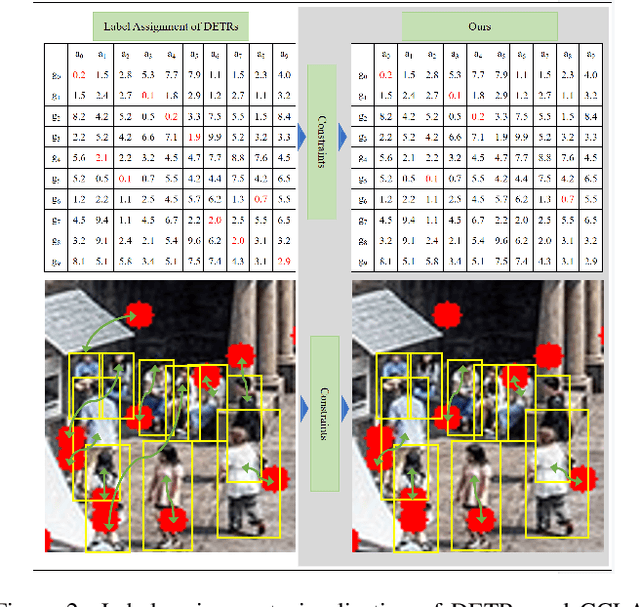
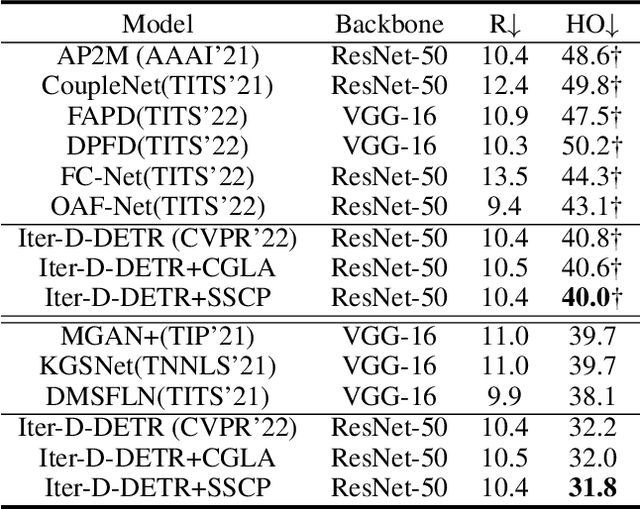
DEtection TRansformer (DETR) and its variants (DETRs) achieved impressive performance in general object detection. However, in crowded pedestrian detection, the performance of DETRs is still unsatisfactory due to the inappropriate sample selection method which results in more false positives. To settle the issue, we propose a simple but effective sample selection method for DETRs, Sample Selection for Crowded Pedestrians (SSCP), which consists of the constraint-guided label assignment scheme (CGLA) and the utilizability-aware focal loss (UAFL). Our core idea is to select learnable samples for DETRs and adaptively regulate the loss weights of samples based on their utilizability. Specifically, in CGLA, we proposed a new cost function to ensure that only learnable positive training samples are retained and the rest are negative training samples. Further, considering the utilizability of samples, we designed UAFL to adaptively assign different loss weights to learnable positive samples depending on their gradient ratio and IoU. Experimental results show that the proposed SSCP effectively improves the baselines without introducing any overhead in inference. Especially, Iter Deformable DETR is improved to 39.7(-2.0)% MR on Crowdhuman and 31.8(-0.4)% MR on Citypersons.
Adapt and Align to Improve Zero-Shot Sketch-Based Image Retrieval
May 18, 2023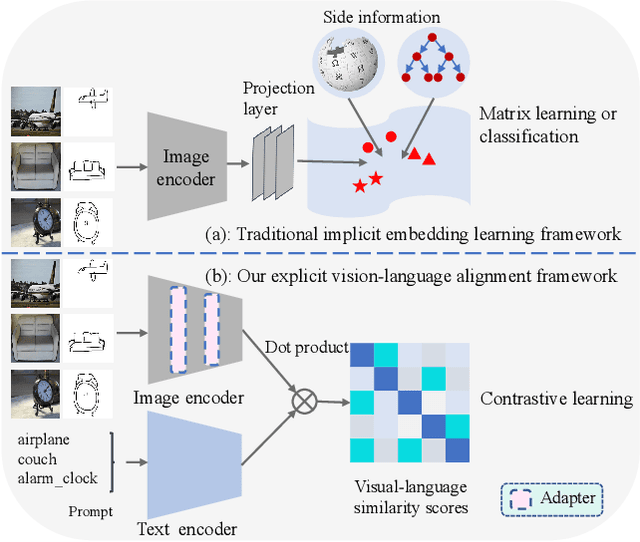
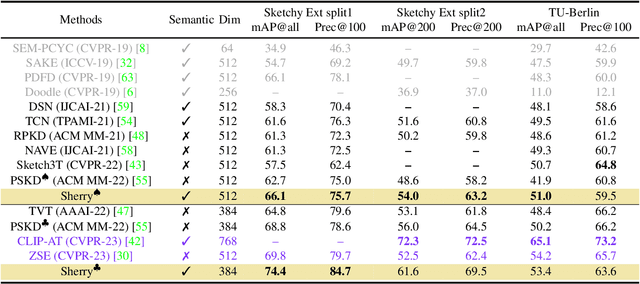
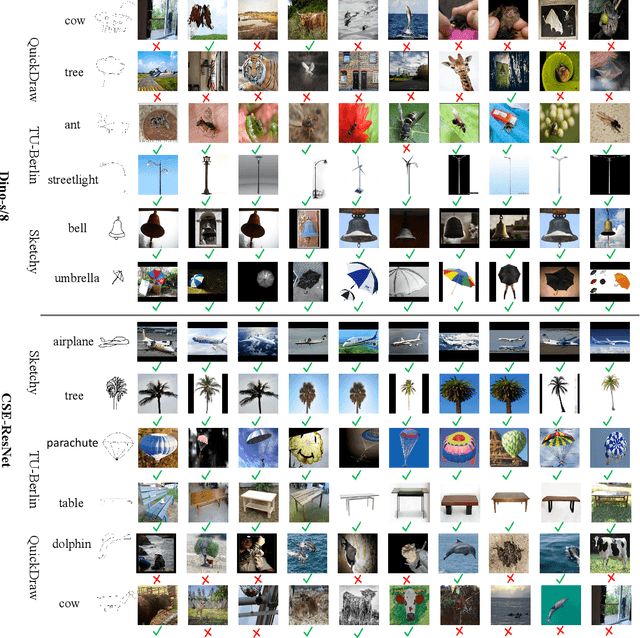
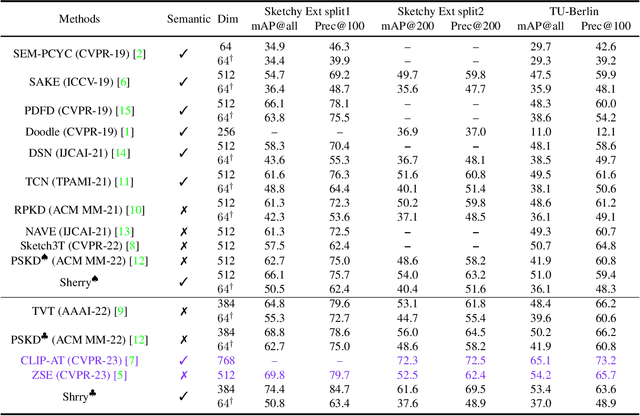
Zero-shot sketch-based image retrieval (ZS-SBIR) is challenging due to the cross-domain nature of sketches and photos, as well as the semantic gap between seen and unseen image distributions. Previous methods fine-tune pre-trained models with various side information and learning strategies to learn a compact feature space that is shared between the sketch and photo domains and bridges seen and unseen classes. However, these efforts are inadequate in adapting domains and transferring knowledge from seen to unseen classes. In this paper, we present an effective ``Adapt and Align'' approach to address the key challenges. Specifically, we insert simple and lightweight domain adapters to learn new abstract concepts of the sketch domain and improve cross-domain representation capabilities. Inspired by recent advances in image-text foundation models (e.g., CLIP) on zero-shot scenarios, we explicitly align the learned image embedding with a more semantic text embedding to achieve the desired knowledge transfer from seen to unseen classes. Extensive experiments on three benchmark datasets and two popular backbones demonstrate the superiority of our method in terms of retrieval accuracy and flexibility.
Rethinking k-means from manifold learning perspective
May 12, 2023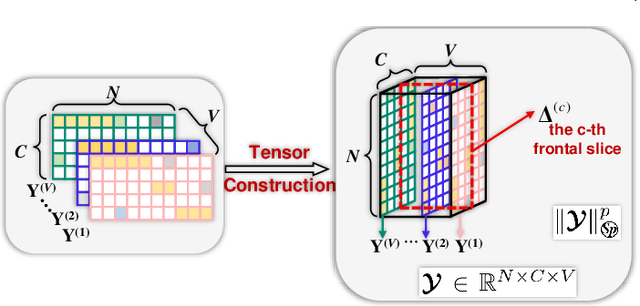

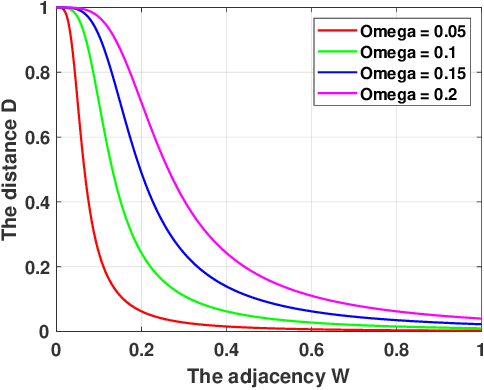
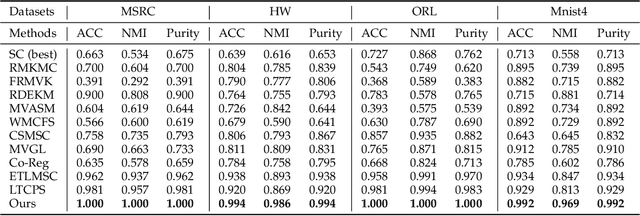
Although numerous clustering algorithms have been developed, many existing methods still leverage k-means technique to detect clusters of data points. However, the performance of k-means heavily depends on the estimation of centers of clusters, which is very difficult to achieve an optimal solution. Another major drawback is that it is sensitive to noise and outlier data. In this paper, from manifold learning perspective, we rethink k-means and present a new clustering algorithm which directly detects clusters of data without mean estimation. Specifically, we construct distance matrix between data points by Butterworth filter such that distance between any two data points in the same clusters equals to a small constant, while increasing the distance between other data pairs from different clusters. To well exploit the complementary information embedded in different views, we leverage the tensor Schatten p-norm regularization on the 3rd-order tensor which consists of indicator matrices of different views. Finally, an efficient alternating algorithm is derived to optimize our model. The constructed sequence was proved to converge to the stationary KKT point. Extensive experimental results indicate the superiority of our proposed method.
Boosting Weakly-Supervised Temporal Action Localization with Text Information
May 01, 2023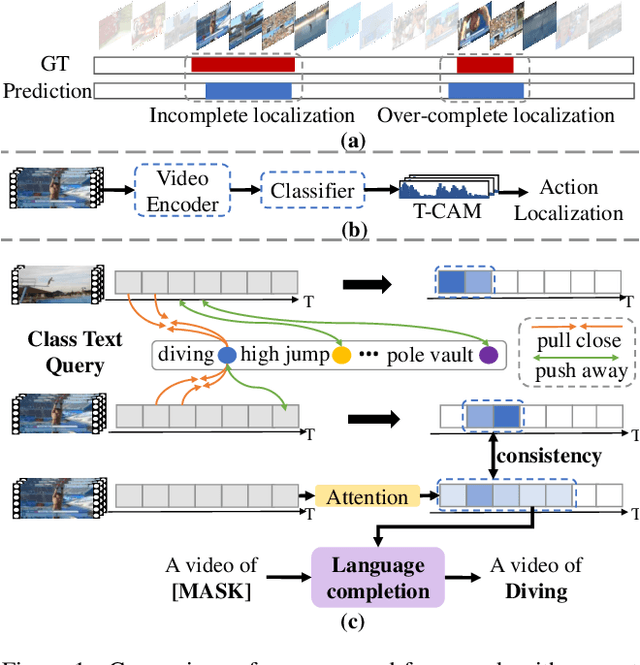
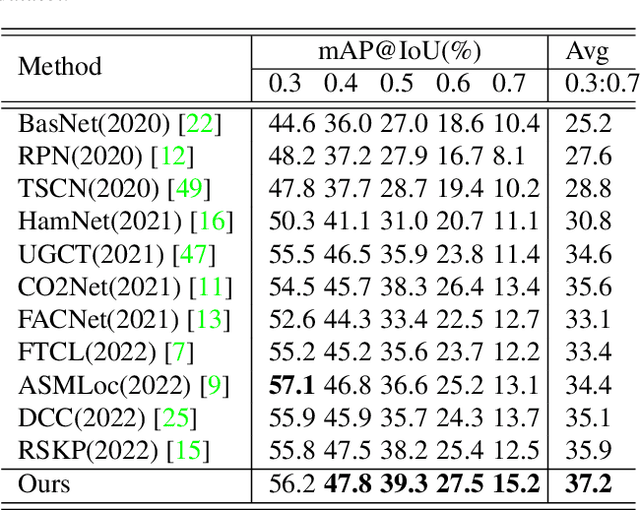
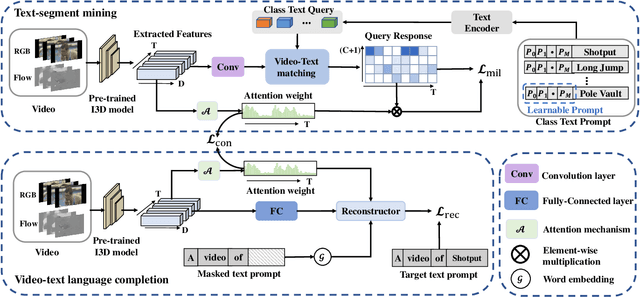
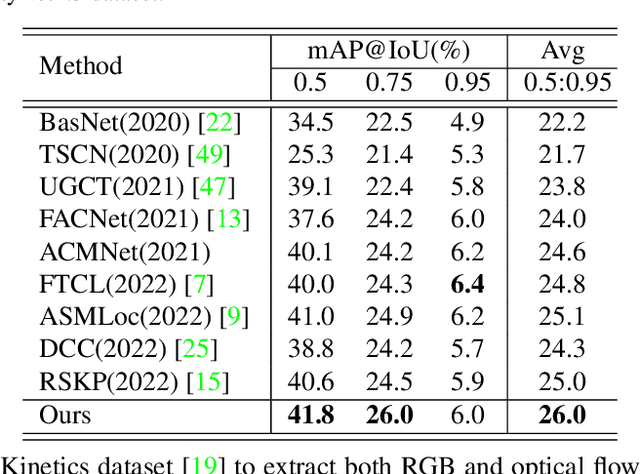
Due to the lack of temporal annotation, current Weakly-supervised Temporal Action Localization (WTAL) methods are generally stuck into over-complete or incomplete localization. In this paper, we aim to leverage the text information to boost WTAL from two aspects, i.e., (a) the discriminative objective to enlarge the inter-class difference, thus reducing the over-complete; (b) the generative objective to enhance the intra-class integrity, thus finding more complete temporal boundaries. For the discriminative objective, we propose a Text-Segment Mining (TSM) mechanism, which constructs a text description based on the action class label, and regards the text as the query to mine all class-related segments. Without the temporal annotation of actions, TSM compares the text query with the entire videos across the dataset to mine the best matching segments while ignoring irrelevant ones. Due to the shared sub-actions in different categories of videos, merely applying TSM is too strict to neglect the semantic-related segments, which results in incomplete localization. We further introduce a generative objective named Video-text Language Completion (VLC), which focuses on all semantic-related segments from videos to complete the text sentence. We achieve the state-of-the-art performance on THUMOS14 and ActivityNet1.3. Surprisingly, we also find our proposed method can be seamlessly applied to existing methods, and improve their performances with a clear margin. The code is available at https://github.com/lgzlIlIlI/Boosting-WTAL.
Granular-ball computing: an efficient, robust, and interpretable adaptive multi-granularity representation and computation method
Apr 25, 2023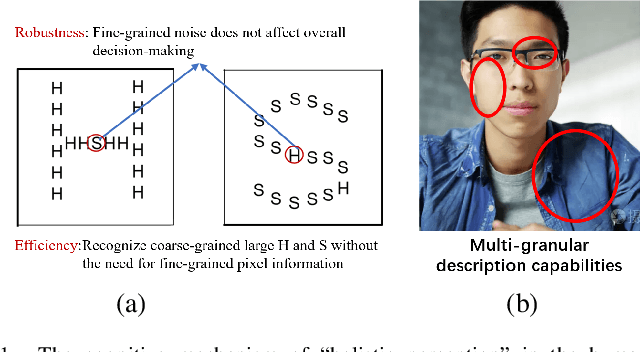

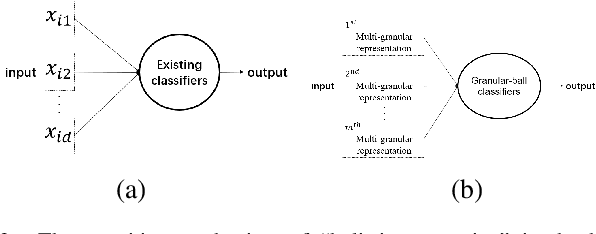
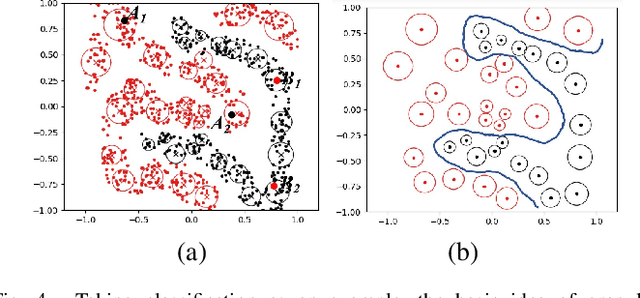
Human cognition has a ``large-scale first'' cognitive mechanism, therefore possesses adaptive multi-granularity description capabilities. This results in computational characteristics such as efficiency, robustness, and interpretability. Although most existing artificial intelligence learning methods have certain multi-granularity features, they do not fully align with the ``large-scale first'' cognitive mechanism. Multi-granularity granular-ball computing is an important model method developed in recent years. This method can use granular-balls of different sizes to adaptively represent and cover the sample space, and perform learning based on granular-balls. Since the number of coarse-grained "granular-ball" is smaller than the number of sample points, granular-ball computing is more efficient; the coarse-grained characteristics of granular-balls are less likely to be affected by fine-grained sample points, making them more robust; the multi-granularity structure of granular-balls can produce topological structures and coarse-grained descriptions, providing natural interpretability. Granular-ball computing has now been effectively extended to various fields of artificial intelligence, developing theoretical methods such as granular-ball classifiers, granular-ball clustering methods, granular-ball neural networks, granular-ball rough sets, and granular-ball evolutionary computation, significantly improving the efficiency, noise robustness, and interpretability of existing methods. It has good innovation, practicality, and development potential. This article provides a systematic introduction to these methods and analyzes the main problems currently faced by granular-ball computing, discussing both the primary applicable scenarios for granular-ball computing and offering references and suggestions for future researchers to improve this theory.